
热门标签
热门文章
- 1国外计算机科学的 lab,真滴牛逼!_计算机lab是什么意思
- 2用Python求数学题中阴影部分面积_python编写程序,求出图5_编写程序求出阴影面积
- 3JavaWeb期末大作业——图书管理系统
- 4Unity 点乘(Dot)、叉乘(Cross)判断移动方向、朝向等向量问题_unity3d c# 2个向量方向
- 5alibaba实习生代码大赛_阿里巴巴实习生代码赛
- 6今天来聊一聊GPU在人工智能应用上的优势_计算机基础 ai人工智能 gpu 知乎
- 7通信原理课设(gec6818) 001:环境配置+文件操作_gec6818能否支持c++
- 8Spring cloud入门-OAuth 2.0(四)授权之基于JWT完成单点登录_oauth2.0 jwt单点登录
- 9Nginx 配置特定IP访问_nginx只允许指定ip访问
- 10Python+Django毕业设计校园易购二手交易平台(程序+LW+部署)_用python写一个交易平台
当前位置: article > 正文
gan处理自己的数据集_movielens数据集介绍及使用python简单处理
作者:喵喵爱编程 | 2024-06-24 11:20:37
赞
踩
用gat算法应用在movielens数据集上
csdn原文blog.csdn.net

0 前言
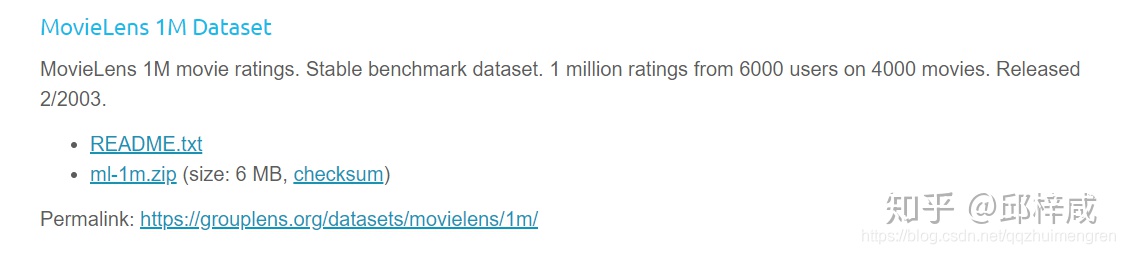
个性化推荐中,电影推荐研究时常使用movielens上的数据集。该网站的数据集主要分两部分,
一是用于推进最新研究进展的数据集。当前最新的是发布于2019年12月份的25M数据集。
二是用于高校、组织科研的数据集。该类数据集按其是否带有标签、时间先后、数据集大小分成6种数据集。
想当时(17年)那会学术论文常见的都是使用1M数据集(2003年发布的)以及10M数据集(2009年发布的),如果是做带标签标记的电影推荐一般是tag-genome数据集(2014年发布的)。数据集中的命名ml为movielens缩写。
1 数据集解读-举例
每个数据集除了大致介绍外,其对应位置还有有一个readme文件,是该数据集的详细介绍。
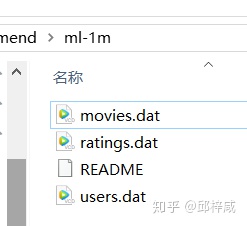
1.1 1M数据集
1M数据集有rating.dat、movies.dat、users.data三份数据集。ratings是6040位用户对3900部电影的评分数据(共计1,000,209)。
1.1.1 rating文件
rating.dat文件存放的是用户对电影的评分信息,改文件中每条记录形式:UserID::MovieID::Rating::Timestamp,即用户id、电影id、该用户对此电影的评分值、时间戳。
- - 用户id:从1到6040
- - 电影id: 从1到3952
- - rating: 从1-5的整数
readme文档中介绍该文件中的每个用户至少都有20个评分(即每个用户至少对20部不同电影进行了打分)。但当时,我做的分析,好像并不像官方文档说的这样,并且,数据都有缺失部分。
1.1.2 users.dat文件
users.dat文件存放的是用户的相关信息,包括性别、年龄、职业,该文件中每条记录形式:UserID::Gender::Age::Occupation::Zip-code。
- - 性别(gend
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/喵喵爱编程/article/detail/752641
推荐阅读

相关标签

