
热门标签
热门文章
- 1Go 语言中的数组:声明、初始化与应用_go 定义方法数组并初始化 数组成员为对象方法
- 2轻松AI绘画!本地一键部署Stable Diffusion,5秒打造个性龙年吉祥物_sd启动器
- 3【网络安全---漏洞复现】Tomcat CVE-2020-1938 漏洞复现和利用过程(特详细)
- 4【MySQL】库的操作+表的操作_数据库的创建命令
- 5程序员的专属节日~定制礼包疯狂送,独宠你一人!
- 6接口测试:使用 curl 发送请求!
- 7http请求方法安全性:GET、POST、PUT、PATCH、DELETE、OPTIONS、HEAD、TRACE_get delte put post哪些可能被识别为安全风险
- 8回归预测 | MATLAB实现2-DCNN卷积神经网络多输入单输出回归预测_2d-cnn matlab
- 9同网段ARP过程和跨网段ARP过程_跨网络的arp协议执行过程
- 10open-messaging使用实例
当前位置: article > 正文
STORM论文阅读笔记
作者:喵喵爱编程 | 2024-06-24 22:02:18
赞
踩
STORM论文阅读笔记

- 这是篇NIPS2023的 world model 论文
- 文章提出,WM的误差会在训练过程中积累从而影响policy的训练,向WM中加噪声可以改善这一点。
- 其他的流程和IRIS差不多,差别在以下几点:
- image encoder,IRIS用的VQVAE, 本文用的是VAE,用VAE的采样方式来生成zt,从而为zt加噪声。
- sequence model,IRIS用GPT循环输出image的每个token,本文直接用MLP把生成的 z t z_t zt 和动作 a t a_t at 输出成一个token,这样GPT只需要在时序上循环而不需要在同一个 t 内的不同 token 上循环。换句话说,IRIS的一个图片是GPT中的16个token,而STORM的一个图片是GPT中的一个token。
- hidden state,IRIS直接从 z 1 : t z_{1:t} z1:t 预测 z t + 1 z_{t+1} zt+1,相当于RNN,而 STORM先从 z 1 : t z_{1:t} z1:t 预测 h t h_{t} ht,也就是说上面的sequence model输出的不是 z ,而是hidden state h,再用一个MLP从 h t h_t ht来预测 z t + 1 z_{t+1} zt+1,这点是用了Dreamerv3的思路
- loss function,用的也是dreamerv3的loss function
- 完整公式和损失函数如下:

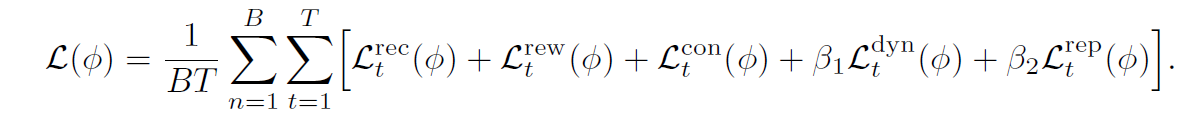
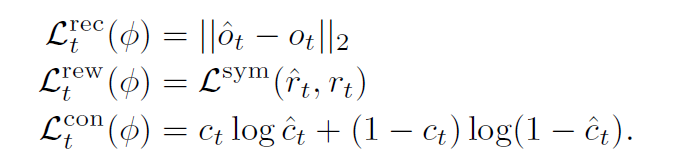
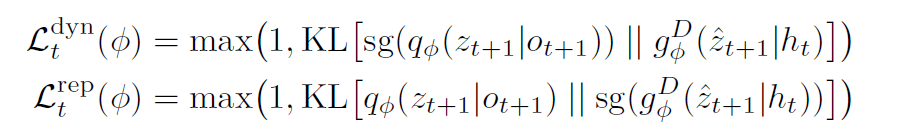
Agent learning
- 强化学习的部分和dreamerv3一样,不过强调了下value函数用的是移动平均:

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/喵喵爱编程/article/detail/754114
推荐阅读
相关标签

