
- 1云原生DevOps篇:使用Pipeline流水线项目构建Docker镜像实战_pipeline 构建镜像containerd
- 2机器学习:手撕 EM 算法_手撕em算法
- 3基于Python的定制化图书借阅推荐引擎_图书馆书籍借阅推荐系统技术指标
- 4基于SpringBoot+Vue的大学生志愿者管理系统(源码+文档+部署+讲解_vue志愿者系统数据库设计
- 5Python安全脚本 ---- Linux主机基线查询
- 6python最简单的游戏代码_python小游戏代码
- 7实用脚本:Linux安全基线检查_linux安全基线检查脚本
- 8Linux设置Huggingface镜像代理_linux配置代理访问huggingface
- 9命名实体识别(NER)学习笔记
- 10mysql中DATE_FORMAT() 函数详解_mysql dateformat
自然语言处理课程论文:《Attention is all you need》复现与解读
赞
踩
目录
1.3.2 attention机制与self-attention机制
3.1 Positional Embedding
3.2 Multi-Head Attention
3.2.1 Scaled Dot-Product Attention
3.2.2 multi-head attention
3.2.3 transformer使用的3种attention
3.3 Feed Forward Network
4.2.1 multi-head attention实现
1.背景介绍
1.1 文献介绍
论文《Attention is All You Need》由 Vaswani 等人于 2017 年在顶级会议上发表。这篇论文引入了 Transformer 模型,该模型在解决机器翻译等自然语言处理任务方面取得了巨大成功。Transformer 模型通过引入自注意力机制,摒弃了传统的循环神经网络和卷积神经网络结构,在处理长距离依赖关系和语义理解方面表现出色。该论文在学术界引起了广泛的关注和讨论,成为了自然语言处理领域的重要里程碑之一。
1.2 研究背景
在神经网络模型中,尤其是在处理机器翻译等自然语言处理任务时,传统的循环神经网络(RNN)和卷积神经网络(CNN)结构存在一些局限性。除了难以处理长距离的依赖关系之外,RNN 还存在着信息丢失的问题。由于 RNN 的循环结构,模型在处理长序列时容易出现梯度消失或梯度爆炸的问题,导致模型难以捕捉长距离依赖关系。
为了解决这些问题,研究者提出了一系列模型,如 Extended Neural GPU、ByteNet 和 ConvS2S,这些模型尝试通过使用并行计算来减少顺序计算的复杂性,但在处理远距离依赖关系时仍然存在挑战,因为处理距离较远的信号所需的操作数会增加。
相比之下,Transformer 模型通过引入自注意力机制,将处理长距离依赖关系的操作次数减少到一个固定数量,从而在理论上更有效地处理了这个问题。这种优势使得 Transformer 模型成为了自然语言处理领域的重要突破之一。
1.3 知识概述
1.3.1 机器翻译
机器翻译是指利用计算机技术将一种语言的文本转换为另一种语言的文本。常见的机器翻译方法包括基于规则的方法、基于统计的方法和基于神经网络的方法。基于规则的方法依赖于语言学规则和词典,而基于统计的方法则通过学习源语言和目标语言之间的对应关系来进行翻译。近年来,基于神经网络的端到端机器翻译方法由于其优秀的性能和灵活性而备受关注。Transformer 模型作为一种
基于注意力机制的神经网络结构,已经成为了机器翻译领域的主流方法之一,取得了令人瞩目的翻译效果。然而,机器翻译仍面临着诸多挑战,如处理低资源语言、处理多模态文本等问题,这需要进一步的研究和探索。
1.3.2 attention机制与self-attention机制
attention几乎已经是sequence modeling and transduction models不可或缺的一部分了,attention的引入允许模型对长距离依赖建模,不需要考虑他们在输入或输出中的距离。但其问题是:大多数场景下,只能与递归网络(recurrent network)一起使用。
self-attention,有时称为intra-attention,是一种涉及单个序列的不同位置以计算序列表示的attention机制( an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence)。 self-attention已成功地应用于阅读理解、抽象概括、语篇蕴涵等多种任务中。transformer的核心也是self-attention的堆叠。
2.数据来源与处理
2.1 数据集描述
本次复现实验中,数据集和论文中一致,都采用WMT 2014 英语-法语数据集。该数据集由 36M 个句子和将 tokens 拆分成 32000 个词条的词汇表组成。序列长度相近的句子一起进行批处理。每个训练批次包含一系列句子对,其中包含大约 25000 个源词符和 25000 个目标词符。下面是该数据集的部分信息展示:
表1:数据集部分信息
| English | French |
| Hug me. | Serre-moi dans tes bras ! |
| I fell. | Je suis tombée. |
| I know. | Je sais. |
| I left. | Je suis parti. |
| I lost. | J'ai perdu. |
| I'm 19. | J'ai 19 ans. |
| I'm OK. | Ça va. |
| Listen. | Écoutez ! |
| No way! | Impossible ! |
2.2 数据处理
数据预处理的过程包括将原始文本转换为模型可处理的格式,并将数据集划分为训练集和验证集。
首先,通过unicodeToAscii函数将Unicode字符串转换为ASCII码,并使用normalizeString函数对字符串进行规范化处理,包括转换为小写、去除标点符号、非字母字符和多余空格等。
然后,根据指定的最大句子长度和英语前缀,过滤出长度小于MAX_LENGTH且以指定前缀开头的句子对。
最后,由于文件是英译法,我们实现的是法译英,因此对过滤后的句子交换顺序,得到法语到英语的句子对,并使用train_test_split函数将数据集划分为训练集和验证集,其中80%的数据用于训练,20%用于验证。这些步骤共同构成了数据预处理的过程,为后续模型训练和评估提供了准备。
3. 模型架构
论文中提出的模型即transformer,我们将在该部分对transformer的架构进行详细的介绍。从整体上来说,Transformer模型的整体架构可以分为编码器和解码器、输入、输出四部分,如下图所示:
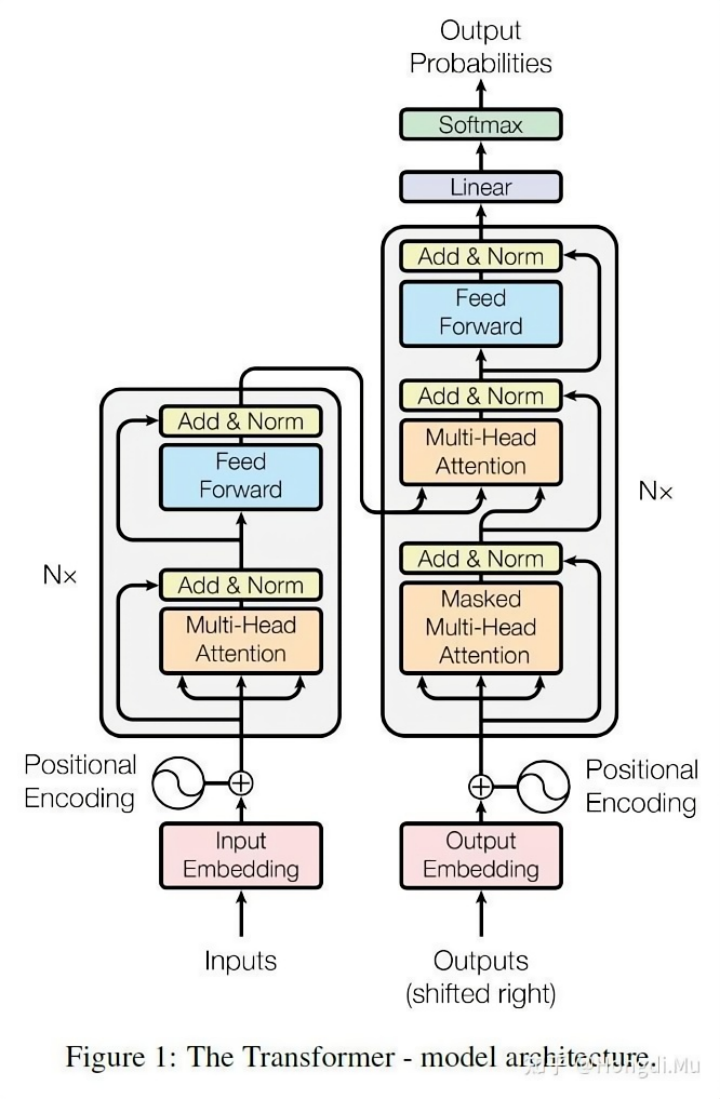
图1:模型整体架构
由于编码器和解码器中出现了一些重复的模块如多头注意力机制和前馈网络。因此本部分将主要对上图中的各个模块进行分析。
3.1 Positional Embedding
PE模块的主要做用是把位置信息加入到输入向量中,使模型知道每个字的位置信息。对于每个位置的PE是固定的,不会因为输入的句子不同而不同,且每个位置的PE大小为1 *n。(n为word embedding 的dim size),transformer中使用正余弦波来计算 PE,具体如下:

·pos代表的是一个字在句子中的位置,从0到名字长度减1,是下图中红色的序号。
·i代表的是dim 的序号,是下图中蓝色的序号:
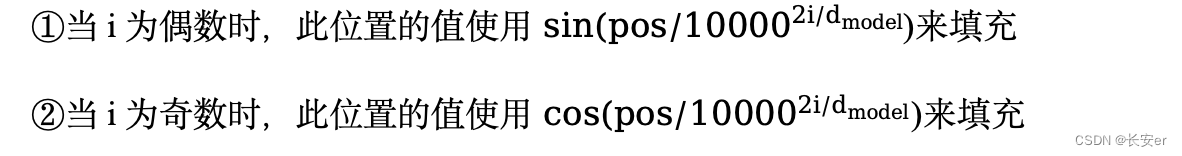
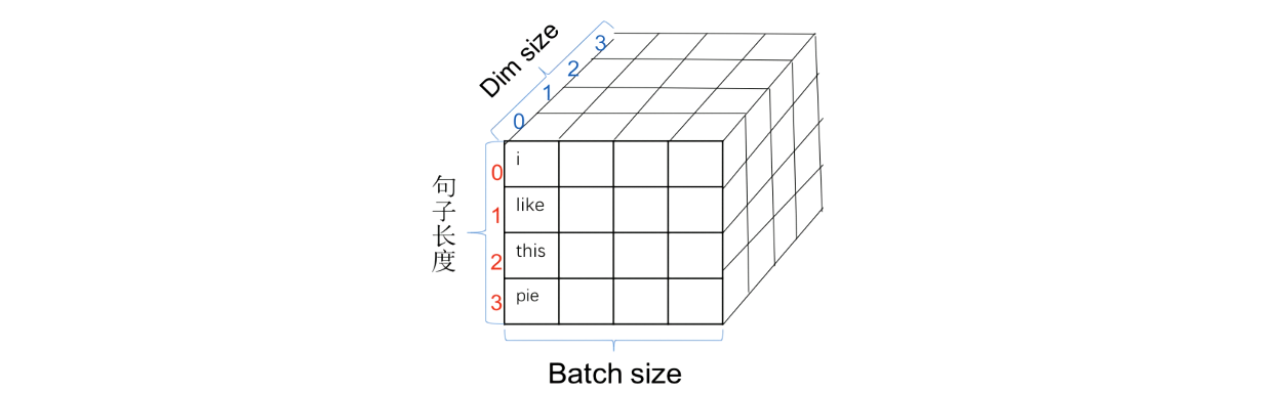
图2:位置编码示意图
3.2 Multi-Head Attention
这个模块是transformer的核心,我们把这块拆成两部分来理解,先分析其中的Scaled Dot-Product Attention(缩放点积注意力机制),再对Multi-Head Attention进行分析。最后对论文中介绍的三种使用multi-head attention的3种不同的方式进行比较分析。
3.2.1 Scaled Dot-Product Attention
论文中的Scaled Dot-Product Attention步骤如下所示:
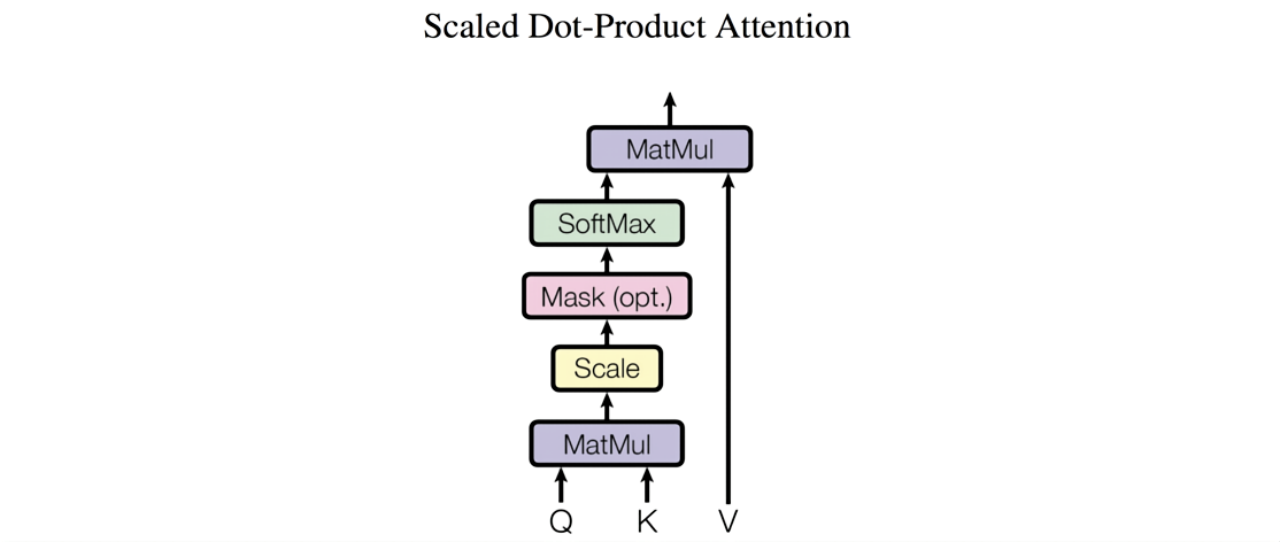
图3: Scaled Dot-Product Attention
Attention函数的本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射(mapping a query and set of key-value pairs to an output)。下面的公式可以泛化的表示这种关系:
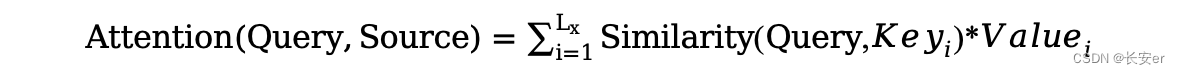
其中Source的构成元素可以想象成是由一系列<key,value>pairs组成的。那么attention机制可以看作就是query与source中的各个key计算相似性或相关性,作为一种权重系数(一般使用softmax对权重进行归一化),最后对source中与key对应的value进行加权求和,通常key=value。计算attention时,query和每个key的相似度函数常用的有:
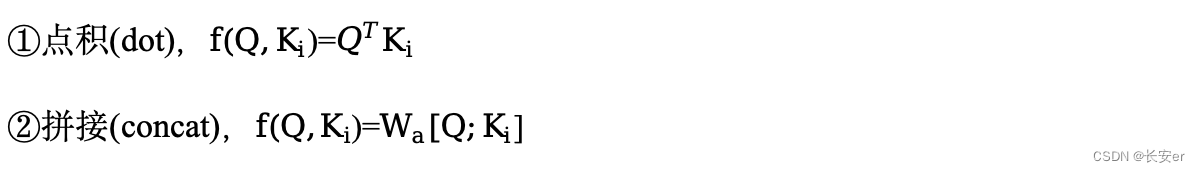
transformer中的scaled dot-product attention就是使用点积进行相似度计算的一种特殊方式,它的特殊在于它使用了一个缩放因子(scaled factor): ,其计算公式如下:)
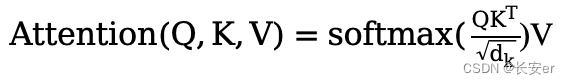
其中queries和keys的纬度是,values的纬度是。
需要注意此处使用进行scale的原因。论文中提到越大的会使得点积的数量级越大,容易造成softmax的值陷入到梯度极小的区域内。因此为了抵消这个影响,需要对点积乘于进行scale。而对于softmax操作,则是将得到的权重矩阵转化为概率值矩阵,与V(values)矩阵进行乘积,得到最后的attention的值,因此我们也可以认为求Attention是加权求和的过程。
3.2.2 multi-head attention
multi-head attention就是上面的scaled dot-product attention做多次计算,论文中是h=8,做8次计算,即8个头,其模型结构如下:
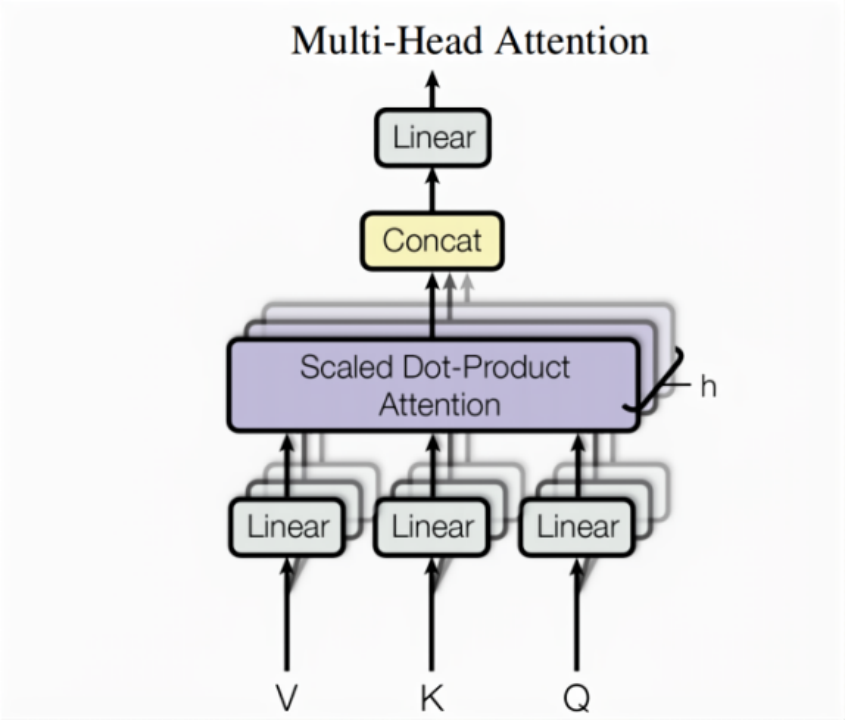
图4: multi-head attention
具体的Query,Key,Value先经过线性变换,然后计算scaled dot-product attention,这个过程做h次(包括线性变换),每次线性变换的参数也是不一样的。然后对h次的scaled dot-product attention做拼接concat,最后再经过一次线性变换层得到最终整个multi-head attention的结果,其计算过程可用如下公式表示:

需要思考的是,为什么需要使用“多头”?论文中表示:多头注意允许模型在不同的位置联合处理来自不同表示子空间的信息。 (Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions)。为了验证此,论文还对不同头的attention weights进行了可视化展示,以说明不同头的注意力分布,表现出与句子的句法和语义结构有关的行为,具体的Attention Visualizations如下表所示:
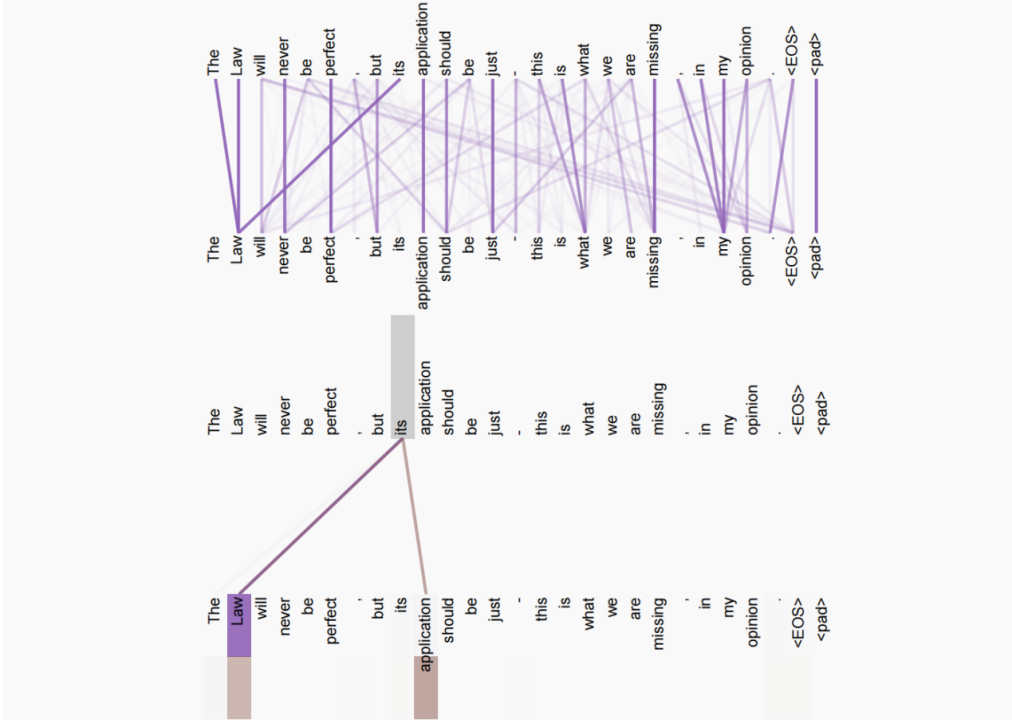
图5: Attention Visualizations
上图中,第一个是一个单头的attention,可以看到单头attention中"its"这个词只能学习到与"law"的依赖关系,而下面的“双头”attention中,"its"不仅学习到了与"law"关系, 还学习到了与单词"application"的依赖关系。由此可以看出,多头能够从不同的表示子空间里学习到相关信息。
3.2.3 transformer使用的3种attention
Transformer中使用multi-head attention的3种不同的方式:
①在encoder和decoder之间的attention layer:query来自于前一个decoder layer,而key和value来自于encoder的输出,这使得decoder能注意到/关注到input sequence的所有位置。
此时有Y=MultiHead(Q,K,V)=MultiHead(X_d,X_e,X_e),即K=V
②在encoder中的self-attention layer,所有的k,v,q来自于encoder的的前一个layer的output。
此时有Y=MultiHead(Q,K,V)=MultiHead(X_e,X_e,X_e),即Q=K=V
③在decoder中的self-attention layer,为了保持自回归(auto regressive)的特征,阻值了左向信息流,这通过在Scaled Dot-Product Attention中加入掩码机制来实现,mask掉softmax的input中属于非法连接的值。
3.3 Feed Forward Network
Feed Forward NetWork 翻译成中文为前馈网络。论文中是point-wise feed-forward network,其含有2个线性变换和一个ReLU激活:具体实现时,就是使用两个linear层,第一个linear的输入是512维,输出是2048维,第二个linear的输入是2048,输出是512。公式如下:
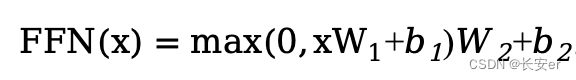
下图展示了前馈网络中的维度变化情况,可以看出,处理前后,维度不变。
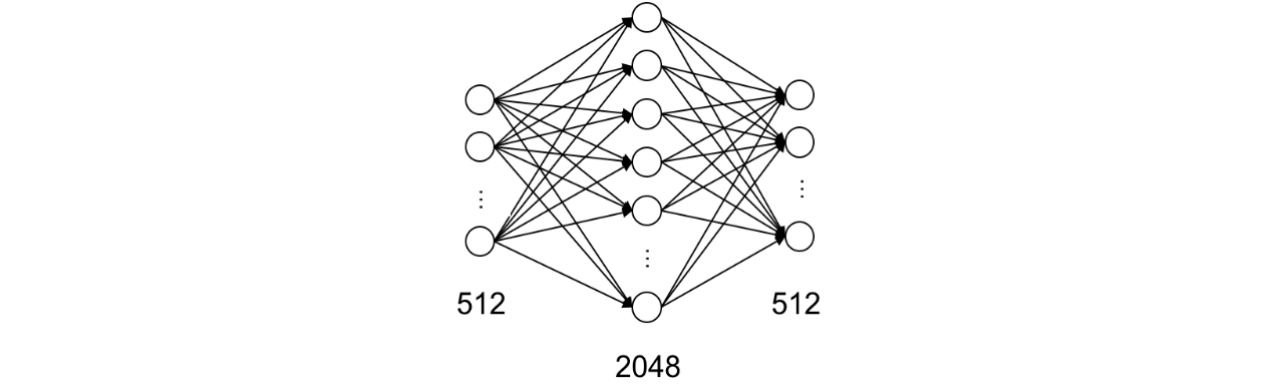
图6: Feed Forward NetWork维度变化图
3.4 ADD & Norm
3.4.1 ADD 残差连接
Add,就是在Z的基础上加了一个残差块X,加入残差块X的目的是为了防止在深度神经网络训练中发生退化问题,退化的意思就是深度神经网络通过增加网络的层数,Loss逐渐减小,然后趋于稳定达到饱和,然后再继续增加网络层数,Loss反而增大。
3.4.2 Norm 层归一化
在神经网络进行训练之前,都需要对于输入数据进行Normalize归一化,目的有二:1,能够加快训练的速度。2.提高训练的稳定性。
论文中使用的是layer normalization,不论是layer normalization 还是batch normalization,其实都是根据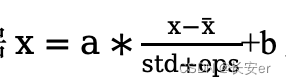 对x的分布进行调整。不同的是和std的计算方式不同,如下图,batch normalization的和std是延粉色方向计算的,而layer normalization是延蓝色方向计算的。
对x的分布进行调整。不同的是和std的计算方式不同,如下图,batch normalization的和std是延粉色方向计算的,而layer normalization是延蓝色方向计算的。
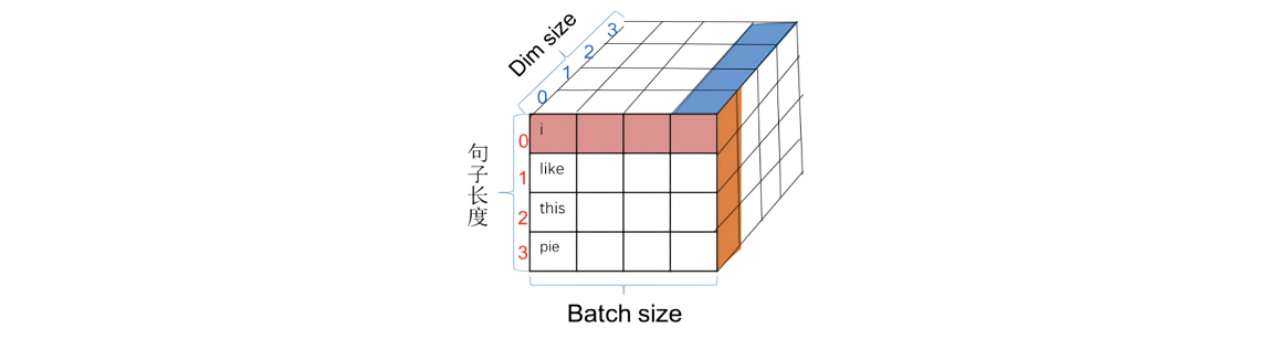
图7: layer normalization
3.5 Linear & Mask
3.5.1 Linear层
此模块的目的是把模型中transformer decoder的输出从维度映射到词表大小的维度。
3.5.2 Mask
模型中用到的mask有2种:
①padding mask :mask pad,即句子中为pad的位置处其mask值为1。
②look-ahead mask:mask future token,将当前token后面的词mask掉,只让看到前面的词,即future token位置的mask值为1。
其中在encoder-layer中只使用到padding mask,用于遮挡input中的pad。而在decoder-layer的第一个self multi-head attention中需要同时使用padding mask和look-ahead mask,在decoder-layer的第二个encoder-decoder multi-head attention中仅使用padding mask,用于遮挡 encoder douput中的pad。
4. 程序与实验说明
在本节中,将对论文对应的复现源码进行解读和分析。由于篇幅限制,只选其中相对重要的能够展现模型功能的程序进行分析,其余诸如实现文件提取、配置设置、驱动运行等功能的代码段将不再赘述。除了解读程序外,还会对实验环境和模型训练部分进行介绍。
4.1 实验环境
表2:复现环境要求
| 环境 | 版本/型号 |
| python | 3.6.9 |
| pytorch | 1.7.0 |
| cuda | 10.2 |
| gpu | NVIDIA V100 (32G) x 4张 |
4.2 论文关键复现程序解读
4.2.1 multi-head attention实现
这段代码定义了一个多头注意力(MultiHeadAttention)的PyTorch模块,用于实现注意力机制。
- class MultiHeadAttention(torch.nn.Module):
- def __init__(self, d_model, num_heads):
- super(MultiHeadAttention, self).__init__()
- self.num_heads = num_heads
- self.d_model = d_model
- assert d_model % self.num_heads == 0
- self.depth = d_model // self.num_heads
- self.wq = torch.nn.Linear(d_model, d_model)
- self.wk = torch.nn.Linear(d_model, d_model)
- self.wv = torch.nn.Linear(d_model, d_model)
- self.final_linear = torch.nn.Linear(d_model, d_model)
-
- def split_heads(self, x, batch_size):
- x = x.view(batch_size, -1, self.num_heads,self.depth)
- return x.transpose(1, 2)
-
- def forward(self, q, k, v, mask):
- batch_size = q.shape[0]
- q = self.wq(q)
- k = self.w(k)
- v = self.wq(v)
- q = self.split_heads(q, batch_size)
- k = self.split_heads(k, batch_size)
- v = self.split_heads(v, batch_size)
- scaled_attention, attention_weights = scaled_dot_product_attention(q, k, v, mask)
- scaled_attention = scaled_attention.transpose(1, 2)
- concat_attention = scaled_attention.reshape(batch_size, -1, self.d_model)
- output = self.final_linear(concat_attention)
- return output, attention_weights

首先,在初始化方法中,定义了多头注意力所需的参数和线性变换层。其中,通过线性变换层(torch.nn.Linear)将输入的d_model维度的向量映射到不同的子空间,以便后续的多头划分。
在split_heads方法中,对输入的张量进行reshape操作,将其转换为适合进行多头划分的形状,以便后续的并行计算。
在forward方法中,首先对输入的q、k、v分别进行线性变换和多头划分操作,然后调用scaled_dot_product_attention函数计算多头注意力结果和注意力权重。最后,将多头注意力的结果进行拼接和线性变换,得到最终的输出结果和注意力权重。
4.2.2 Encoder layer的实现
Transformer 中有 N 个编码器层(论文中N=6)。下面这段代码定义了一个编码器层(EncoderLayer)模块,用于在Transformer结构中实现编码器的功能。
- class EncoderLayer(torch.nn.Module):
- def __init__(self, d_model, num_heads, dff, rate=0.1):
- super(EncoderLayer, self).__init__()
- self.mha = MultiHeadAttention(d_model, num_heads)
- self.ffn = point_wise_feed_forward_network(d_model, dff)
- self.layernorm1=torch.nn.LayerNorm(normalized_shape=d_model, eps=1e-6)
- self.layernorm2=torch.nn.LayerNorm(normalized_shape=d_model, eps=1e-6)
- self.dropout1 = torch.nn.Dropout(rate)
- self.dropout2 = torch.nn.Dropout(rate)
在 init 方法中,定义了编码器层中的多头注意力模块、点积前馈神经网络、LayerNorm 层和 Dropout 层等子模块,用于对输入特征进行处理和归一化处理,以及防止过拟合。
- def forward(self, x, mask):
- attn_output, _ = self.mha(x, x, x, mask)
- attn_output = self.dropout1(attn_output)
- out1 = self.layernorm1(x + attn_output)
- ffn_output = self.ffn(out1)
- ffn_output = self.dropout2(ffn_output)
- out2 = self.layernorm2(out1 + ffn_output)
- return out2
在 forward 方法中,定义了编码器层的前向传播函数,接受输入张量 x 和掩码,并通过多头注意力模块对输入进行自注意力计算,得到注意力输出。随后进行 dropout 操作和 LayerNorm 归一化操作,并将其与原始输入张量 x 相加,得到 out1。接下来将 out1 作为输入,并通过点积前馈神经网络进行非线性变换和映射,得到 ffn_output。最后进行 dropout 操作和 LayerNorm 归一化操作,并将其与 out1 相加,得到最终输出 out2。
4.2.3 transformer的搭建
这段程序定义了一个基于 Transformer 的序列到序列模型,用于机器翻译等自然语言处理任务。该模型包含编码器和解码器两个部分,并通过最终的线性层将解码器的输出映射到目标语言的词汇表维度上。
- class Transformer(torch.nn.Module):
- def __init__(self,num_layers,d_model,num_heads,dff,input_vocab_size, target_vocab_size, pe_input,pe_target,rate=0.1):
- super(Transformer, self).__init__()
- self.encoder = Encoder(num_layers,d_model,num_heads,dff,
- input_vocab_size, pe_input,rate)
- self.decoder = Decoder(num_layers,d_model, num_heads,dff,
- target_vocab_size,pe_target,rate)
- self.final_layer = torch.nn.Linear(d_model, target_vocab_size)
在该init 方法中,定义了模型的基本参数,包括编码器和解码器层数、模型维度、注意力头数、点式前馈网络内层维度、输入和输出词汇表大小、输入和输出位置编码的最大长度以及 dropout 比率等。在初始化方法中,还创建了编码器、解码器和最终的线性层的实例对象。
- def forward(self,inp,targ,enc_padding_mask,look_ahead_mask, dec_padding_mask):
- enc_output = self.encoder(inp, enc_padding_mask)
- dec_output,attention_weights=self.decoder(targ,enc_output, look_ahead_mask, dec_padding_mask)
- final_output = self.final_layer(dec_output)
- return final_output, attention_weights
在该forward 方法中,通过调用编码器对源语言输入序列进行编码,得到编码器的输出。随后,将编码器的输出作为解码器的输入,同时传入目标语言输入序列,以及前瞻掩码和填充掩码等参数,得到解码器的输出和注意力权重。最后,将解码器的输出通过最终的线性层进行映射,得到目标语言的预测输出。
4.2.4 优化器的设置
根据论文中的公式,将 Adam 优化器与自定义的学习速率调度程序(scheduler)配合使用。公式及代码如下:
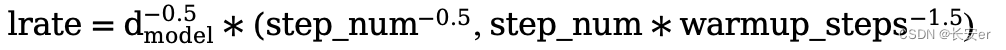
- class CustomSchedule(torch.optim.lr_scheduler._LRScheduler):
- def __init__(self, optimizer, d_model, warm_steps=4):
- self.optimizer = optimizer
- self.d_model = d_model
- self.warmup_steps = warm_steps
- super(CustomSchedule, self).__init__(optimizer)
-
- def get_lr(self):
- arg1 = self._step_count ** (-0.5)
- arg2 = self._step_count * (self.warmup_steps ** -1.5)
- dynamic_lr = (self.d_model ** (-0.5)) * min(arg1, arg2)
- # print('dynamic_lr:', dynamic_lr)
- return [dynamic_lr for group in self.optimizer.param_groups]
CustomSchedule 类中的 get_lr 方法,它被调用来获取当前的学习率。该方法根据当前的训练步数和预设的参数计算出动态的学习率,并返回一个列表,其中每个元素对应一个优化器的参数组。
为了便于分析模型训练过程中学习率的变化规律,以及对模型训练的影响,我们还绘制了学习率的变化曲线

图8: 学习率变化曲线
可以看出学习率随着训练step的增加呈现先增后减的变化,是为了在训练初期快速收敛,然后在接近最优解时进行精细调整,从而提高模型的性能和稳定性。
4.3 模型训练介绍
下面是模型训练函数train_model的部分代码,该部分代码完成了一个epoch的训练和验证,并实时记录和打印训练过程中的损失和指标信息,同时根据验证集的表现保存最佳模型。
- # 打印epoch级别的日志
- print('EPOCH = {} loss: {:.3f}, {}: {:.3f}, val_loss: {:.3f}, val_{}: {:.3f}'.format(
- record[0], record[1], metric_name, record[2], record[3], metric_name, record[4]))
- printbar()
- current_acc_avg = val_metric_sum / val_step # 看验证集指标
- if current_acc_avg > best_acc: # 保存更好的模型
- best_acc = current_acc_avg
- checkpoint = save_dir + '{:03d}_{:.2f}_ckpt.tar'.format(epoch, current_acc_avg)
- if device.type == 'cuda' and ngpu > 1:
- model_sd = copy.deepcopy(model.module.state_dict())
- else:
- model_sd=copy.deepcopy(model.state_dict())
- torch.save({
- 'loss': loss_sum / step,
- 'epoch': epoch,
- 'net': model_sd,
- 'opt':optimizer.state_dict(),
- 'lr_scheduler': lr_scheduler.state_dict()
- }, checkpoint)
在模型保存部分,我们根据验证指标的表现,如果当前模型在验证集上的指标优于之前的最佳指标(best_acc),则保存当前模型,具体如下:
①首先,判断当前设备是否为GPU并且是否使用多个GPU进行训练,如果是,则使用copy.deepcopy()函数复制模型的状态字典(model.module.state_dict()),否则直接复制模型的状态字典(model.state_dict())。
②然后,使用torch.save()函数保存模型的相关信息,包括训练损失、当前epoch、模型的状态字典、优化器的状态字典和学习率调度器的状态字典。
5.实验结果与分析
在该模块我们复现的是论文中的机器翻译部分,即法语->英语的翻译;我们将对模型的训练结果和评估结果进行展示,并作出分析。
5.1 模型训练结果及分析
代码设置的epoch=40,受篇幅限制,我们仅展示部分训练过程:
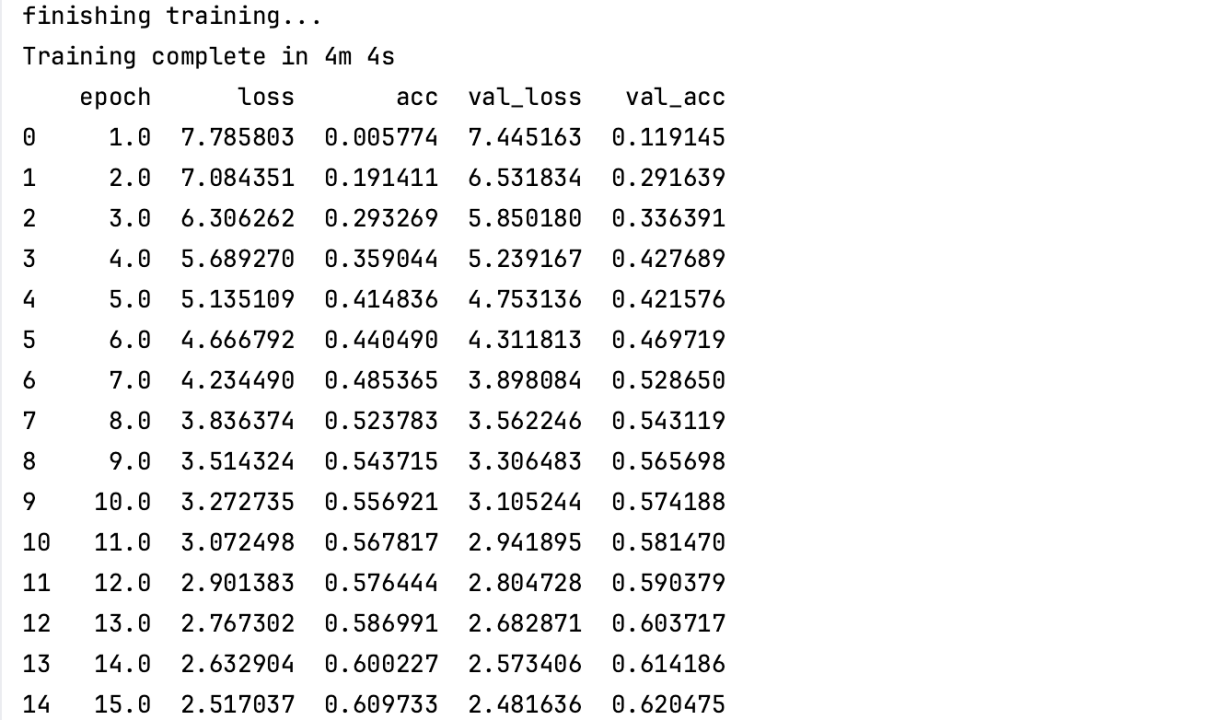
图8: 部分训练内容
代码中还绘制了如下训练曲线:
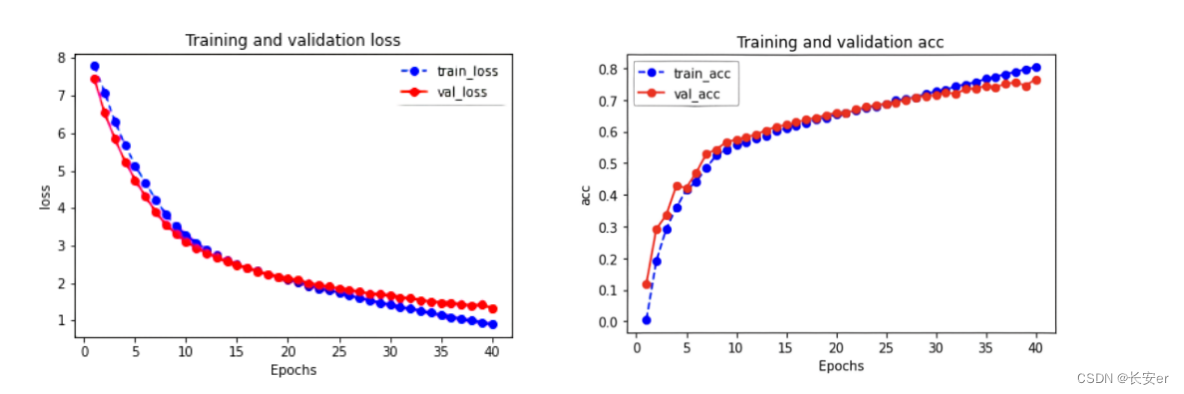
图9: 训练曲线
从上图中可以看出,随着epoch的增加,模型的损失呈现逐步下降的趋势,同时分类准确率不断提高,最终达到80%左右。这表明模型在相对较短的训练时间内就已经学习到了有效的特征表示,能够对样本进行准确分类,并取得了不错的性能表现。尽管训练epoch比较少,但结果仍然证明了该模型的鲁棒性和泛化能力,能够在实际应用中发挥一定的作用。
5.2 模型评估结果及分析
本次复现过程没有额外的使用测试集测评,依旧拿验证集进行测试。
以下步骤用于评估:
·用法语分词器(tokenizer_pt)编码输入语句。此外,添加和标记,这样输入就与模型训练的内容相同。这是编码器输入。
·解码器输入为 token id
·计算padding mask 和 look ahead mask
·解码器通过查看编码器输出和它自身的输出(自注意力)给出预测。
·选择最后一个词并计算它的 argmax。
·将预测的词concat到解码器输入,然后传递给解码器。
·在这种方法中,解码器根据它之前预测的words预测下一个。
首先拿验证集作为测试集作测试,代码输出如下所示:

图10: 测试结果
下面进行模型的批量翻译,待翻译的法语句子如下:
"je pars en vacances pour quelques jours ."
"je ne me panique pas ."
"je recherche un assistant ."
"je suis loin de chez moi ."
"vous etes en retard ."
"j ai soif ."
"je suis fou de vous ."
模型翻译结果如下:

图10: 模型批量翻译结果
其中input是源语言输入,target是对应的真实翻译,pred是模型的翻译。首先,从这些输入和输出结果中可以看出,该模型能够正确地翻译大部分简单的句子。例如,在第一句输入“je pars en vacances pour quelques jours”,模型的翻译结果“我休假几天”与真实翻译基本一致。这表明该模型在一定程度上能够理解源语言和目标语言之间的语义对应关系。
然而,在处理复杂的句子时,该模型可能会存在一些问题。例如在第三个输入中,“je recherche un assistant”,真实翻译为“我正在寻找一个助手”,但模型输出为“我正在寻找很多”。这表明该模型在处理“assistant”(助手)这个特殊的词汇时遇到了困难,可能需要更多的训练数据或者改进模型结构来提高性能。
此外,在第四个输入中,“je suis loin de chez moi”,真实翻译为“我离家很远”,但模型输出为“我在家”。这表明该模型在处理某些短语时可能存在一些偏差,导致输出与真实翻译不符。这也进一步证明了该模型需要更加复杂和全面的训练数据来支持其翻译性能。
因此,我们可以分析出,该模型在处理简单短句时表现较好,但在处理复杂句子或特殊短语时存在一定的限制。需要进一步的研究和优化来提高其性能和表现,但整体的准确度较高。
6. 总结与思考
6.1 论文复现总结
本文对首先对论文《Attention Is All You Need》进行了简单的介绍,并指出了其研究背景。Transformer 模型作为一个能够很好的处理长距离依赖关系和语义理解方面问题的全新模型,成为了自然语言处理领域的重要里程碑之一。随后对本文的实验方向——机器翻译进行了简单的介绍,机器翻译是指利用计算机技术将一种语言的文本转换为另一种语言的文本。论文提出的模型即Transformer,该模型的整体架构可以分为编码器和解码器、输入、输出四部分,我们按照顺序对各个子模块进行了详细的分析,包括位置编码、多头自注意力机制、掩码机制等。
在实验部分,我们参考论文提供的源码同时结合一些博主的复现代码对机器翻译任务进行了复现,包括环境配置、数据处理、模型训练与评估等步骤,最后得到了一个准确度较高的结果,但仍需要进行进一步的研究和优化来提高其性能和表现。
复现过程中也遇到了不少问题,如环境配置屡次失败、论文提供的源码部分库缺失等,不过经过了多次尝试和资料的查询,这些都得到了很好的解决。
通过本次论文复现历程,我对transformer这一模型架构变得更加熟悉,对其中的一些实现细节也理解的更加深入。整个复现过程也让我对NLP这一领域有了更深的兴趣!
6.2 论文复现思考
在对《Attention Is All You Need》这篇论文进行复现的过程中,我产生了一些思考,其中有些思考涉及到了attention机制。
首先,我注意到论文的标题为“Attention is All You Need”,因此刻意避免了使用RNN和CNN等名词。然而,我认为这种做法过于刻意。虽然论文中命名了一种Position-wise Feed-Forward Networks,但实际上它就是窗口大小为1的一维卷积。此外,attention机制虽然与CNN没有直接联系,但实际上借鉴了CNN的思想。例如,Multi-Head Attention就是将多个attention拼接起来,这与CNN中的多卷积核的思想一致。此外,论文还使用了残差结构,其灵感也来自CNN网络。
其次,针对Attention层,其优势在于能够一步到位捕捉全局联系,因为它直接比较序列中的所有元素;相比之下,RNN需要一步步递推才能捕捉到,而CNN则需要通过层叠来扩大感受野。然而,并非所有问题都需要长程的全局依赖,许多问题只依赖于局部结构。因此,在这些情况下,使用纯Attention可能并不是最佳选择。Google的研究者也意识到了这一点,论文中提到了一个restricted版本的Self-Attention。该版本假设当前词只与前后r个词相关,因此仅在这2r+1个词之间计算注意力,从而捕捉序列的局部结构。这种方法的计算量是O(nr),但很明显这类似于卷积核中的卷积窗口的概念。
最后,我认为attention机制仍无法很好地对位置信息进行建模,这仍然是一个瓶颈。尽管可以引入Position Embedding,但我认为这只是一个缓解方案,没有根本解决问题。当然,这些问题是由于论文发表年份早于后续研究和开发,已经产生了更加优秀的模型(以上内容均个人看法)。
经过查阅资料,我发现在《Attention Is All You Need》这篇论文发表后,许多学者和研究团队在该领域进行了深入的研究,提出了一些更加优秀的模型,解决了一些问题。
例如,针对位置信息建模问题,谷歌于2019年提出了Transformer-XL模型,在其基础上引入了Relative Positional Encoding,从而更好地对位置信息进行建模。此外,Facebook AI Research也在同年提出了BERT模型,其中包含Position Embedding和Segment Embedding,有效地解决了位置信息建模的问题。
除此之外,Google还在2019年提出了Reformer模型,它改进了传统Transformer中的Self-Attention机制,采用了LSH(Locality-Sensitive Hashing)算法,使得模型能够处理更长的序列,并且在保持准确性的同时减少计算量。此外,2019年还有许多其他与Transformer相关的模型被提出,如Sparse Transformer、Performer等等,它们在不同的领域和任务中表现出了很好的效果。
总之,尽管《Attention Is All You Need》这篇论文中的Transformer模型在当时取得了巨大的成功,但随着人工智能领域的不断发展,许多新的模型被提出,解决了一些问题,并且在更广泛的应用场景中表现出了出色的性能。
END~


