
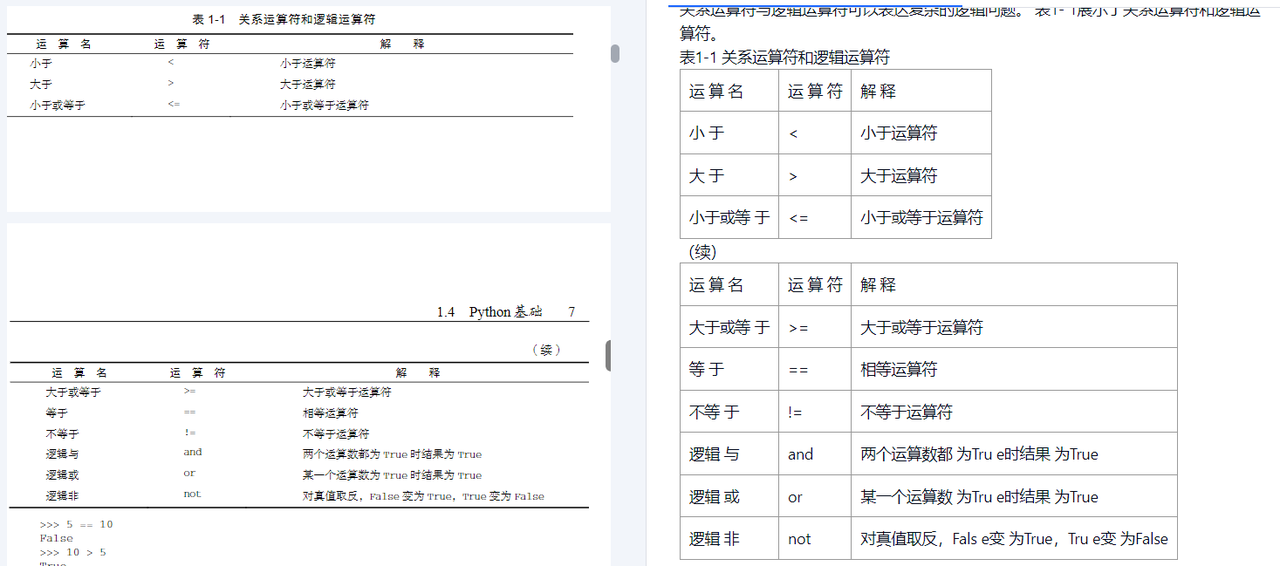
- 1Java 使用 JDBC 连接mysql
- 2计算机毕业设计---基于Vue、SpringBoot(Java)、Uniapp实现的校园失物招领小程序(源码含参考论文,答辩ppt、包运行,含技术答疑)_综合项目——小程序校园失物招领系统ppt
- 3西电软工计网实验3:VLAN设置和静态路由设置_西电计网实验
- 4【论文阅读】-- 时间空间化:用于深度分类器训练的可扩展且可靠的时间旅行可视化
- 5最小二乘法解线性回归_最小二乘法求线性回归方程
- 6鸿蒙微内核属于Linux吗,华为鸿蒙系统刷屏,但你知道什么是微内核操作系统么?...
- 7sourcetree 或 git配置的一些问题_sourcetree的user.config没有怎么办
- 8我在亚马逊云平台的学习成长之路_亚马逊云大数据技术学习
- 9【JS】前端文件读取FileReader操作总结_js filereader
- 10Tomcat任意文件上传漏洞(CVE-2017-12615)_cve-2017-12615 payload
大模型训练语料质量差文档解析不精准,看CCIG上的专家怎么说
赞
踩
最近遇到了一个问题。上传的文档文件给ChatGPT,但因为它识别解析文档不准确导致回答错误的情况,影响了工作效率,让我很是困扰。
很有幸今年参加了在西安举办的中国图象图形大会(简称:CCIG),解决了我的困扰。
可能很多小伙伴不知道CCIG是什么?
CCIG即中国图象图形大会(Chinese Congress on Image and Graphics)是为贯彻落实国家“十四五”规划,强化国家战略科技力量,瞄准人工智能产业发展中的核心科技领域——图像图形领域而成立的会议。
由中国图象图形学学会创办,中国图象图形学学会也是经国家民政部批准成立的国家一级学会,由中国从事图像图形学基础理论与应用研究,软、硬件技术开发及应用推广的专家学者和相关科技工作者组成,经过30余年的发展,团结了一大批图像图形领域优秀人才,拥有29个专业委员会和14个工作委员会,涵盖了图像图形的各个领域,是图像图形学术界、产业界群贤毕至的年度盛会。
本届大会以“图象图形·向未来”为主题,由中国科学技术协会指导,中国图象图形学学会主办,苏州科技大学承办,特邀谭铁牛院士、赵沁平院士、吴一戎院士等百余位国内外知名学者,来自代表企业的技术专家,共话图像图形学术研究与技术创新趋势,共谋行业新发展。
通过参与此次大会,让我长了不少见识和学到了很多知识。尤其是对合合信息他们在智能文档处理解析上的研究和成功颇为惊喜和印象深刻,因为他们推出的TextIn成功解决了我的开头提到的困扰。借此机会给小伙伴们分享一下,也聊聊我的一些感悟和想法。
文档解析技术加速大模型训练与应用
大模型训练和应用关键环境面临的问题
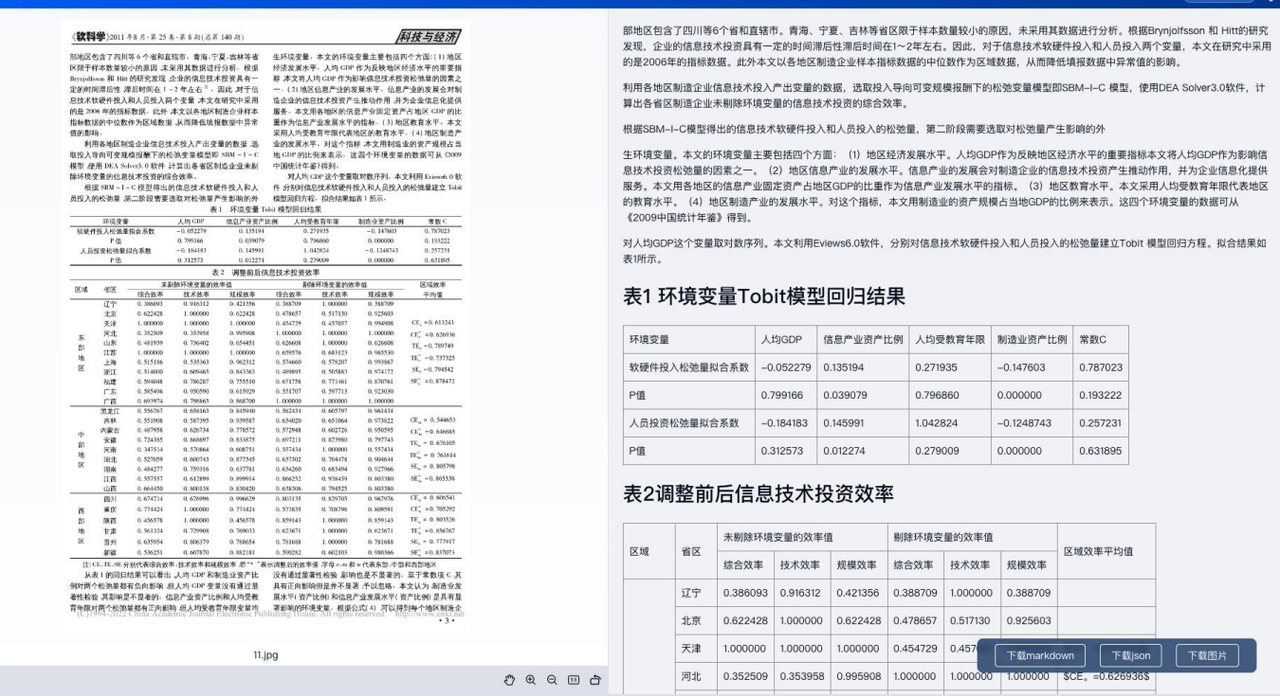
在大会上,来自合合信息智能创新事业部研发总监常扬指出了目前大模型训练和应用过程的关键环节面临的问题:训练Token耗尽、训练语料质量要求高、LLM文档问答应用中文档解析不精准的情况:

针对训练语料质量不高及文档解析不精准的问题,常扬举了很典型的例子:
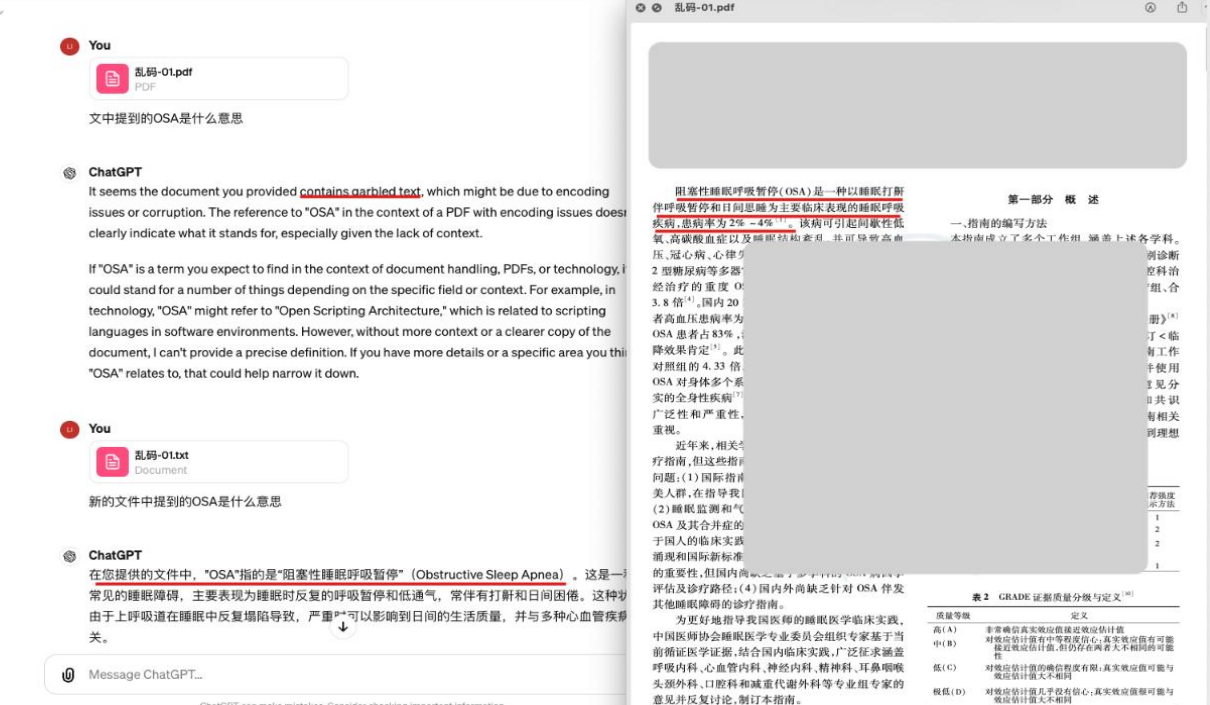
它给ChatGPT4一个pdf文件,由于解析不精准的问题导致ChatGPT识别错误,导致回答出错的情况:
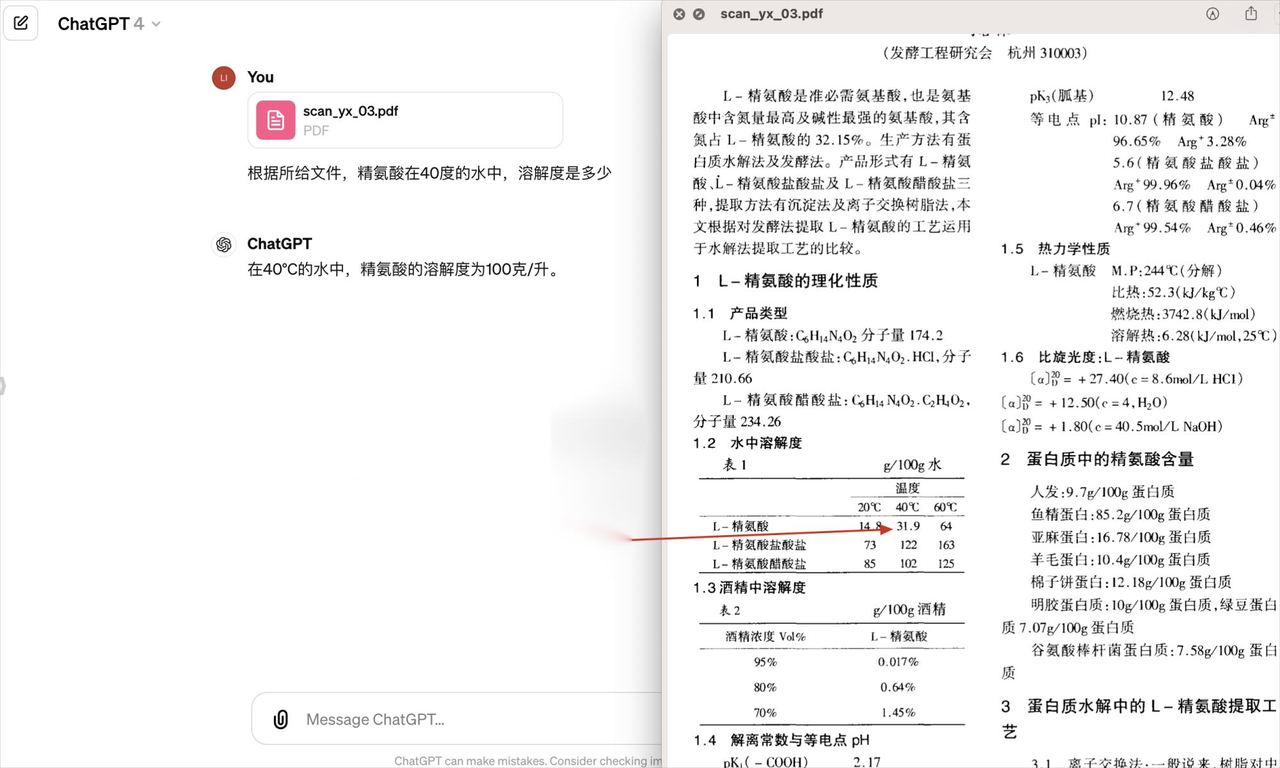
甚至问一个很简单的问题:致谢环节提到了什么,ChatGPT还是解析定位不对,导致回答错误:
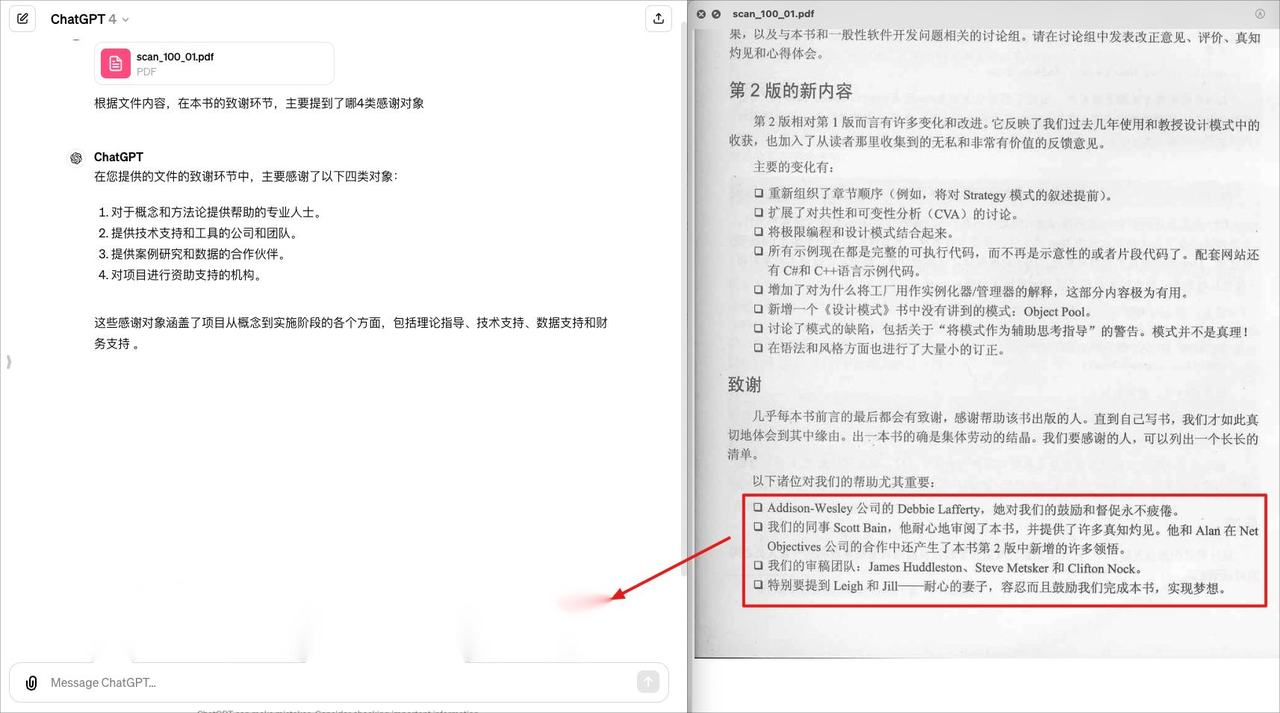
因此他们团队希望研究具备多文档元素识别、版面分析、高性能的文档解析技术。
当然这里面存在很多难点:元素遮盖重叠,元素本身的多样性和复杂的版式等:

尤其是像下面这种具有阅读(按序号阅读)顺序的文章,如果送给大模型的顺序错误那就会导致训练结果和识别回答结果与预期不符的情况:
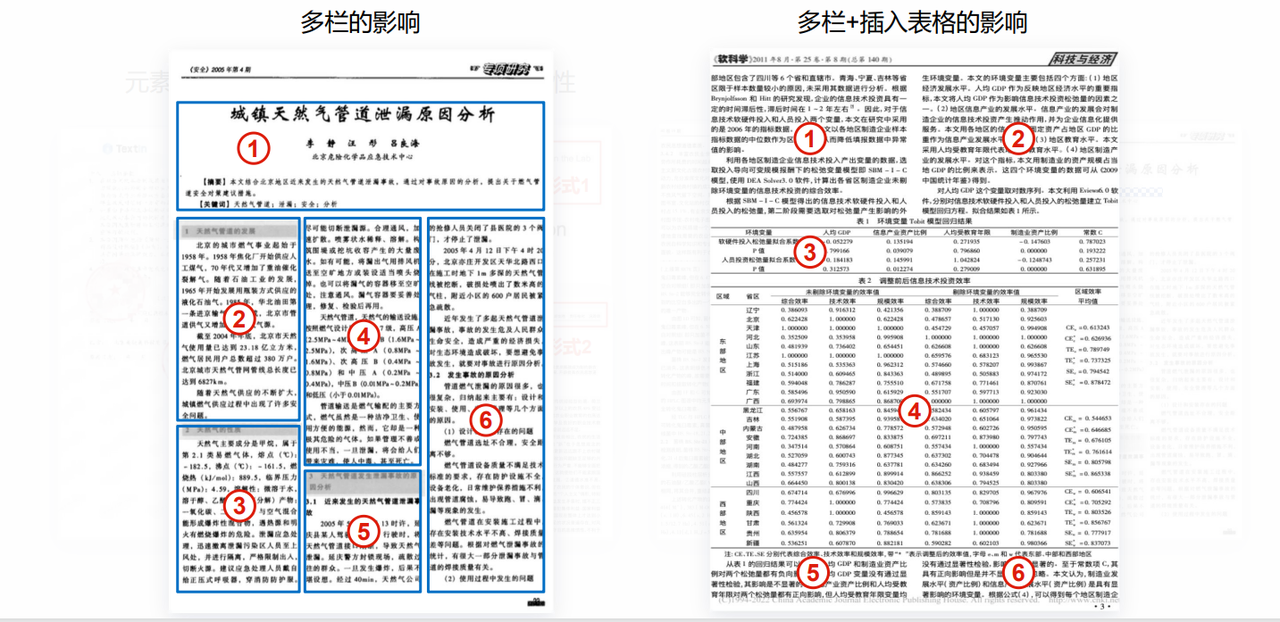
以及无线表格和合并单元格的识别:
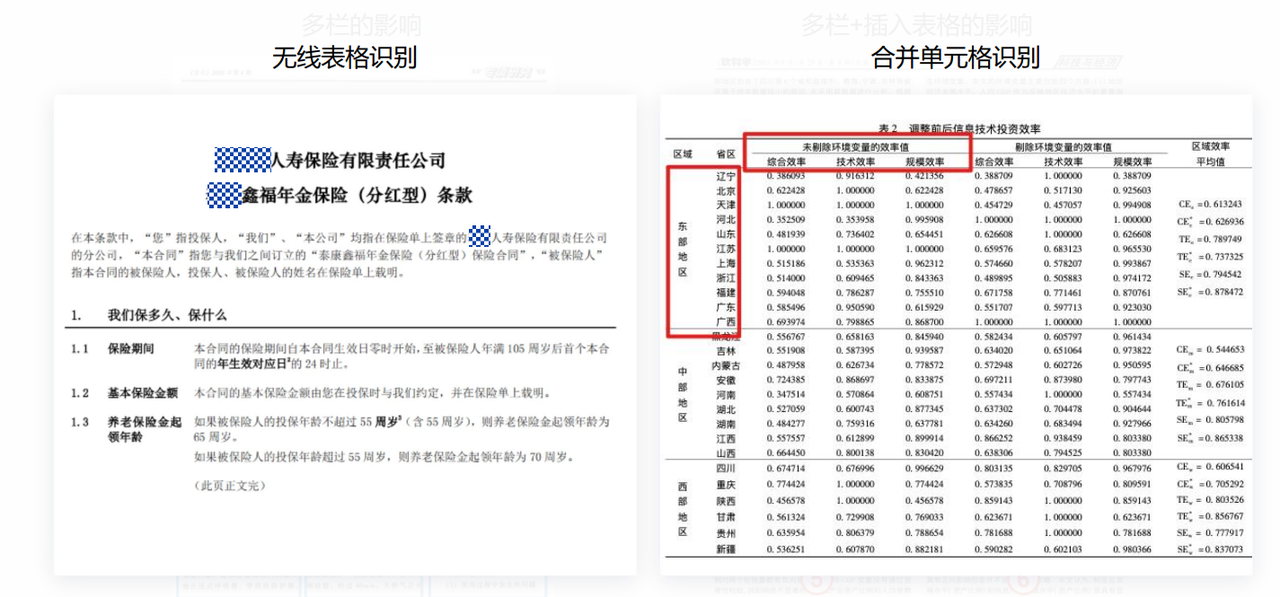
还有单行、行内公式及表格内公式的识别:

上述问题都是解析识别中非常常见且典型的问题。
合合信息推出的TextIn文档解析是如何解决这些问题的
针对这些问题他们团队推出了TextIn文档解析技术,针对电子档、扫描件文档进行预处理、识别和分析来提高大模型训练语料质量和更精准的文档解析:

弯曲矫正技术
合合信息的 "弯曲矫正技术" 创新性地采用基于位移场网络学习方法的系统构架,可对弯曲地文档进行曲面、透视矫正,同时智能定位文档边缘,能够切除多余背景:

图像文档干扰去除算法
他们团队通过提取U2net卷积提取整个背景,然后去除模块、摩尔纹以及光照影响后形成CAB结构,在进行信息融合生产更高质量的图像:

下图是整个图像处理的一个演示示例:

版面分析
经过上面操作提取出文字后,TextIn会对其进行版面分析,通过下图所示的框架对文档进行输出,如图右侧所示: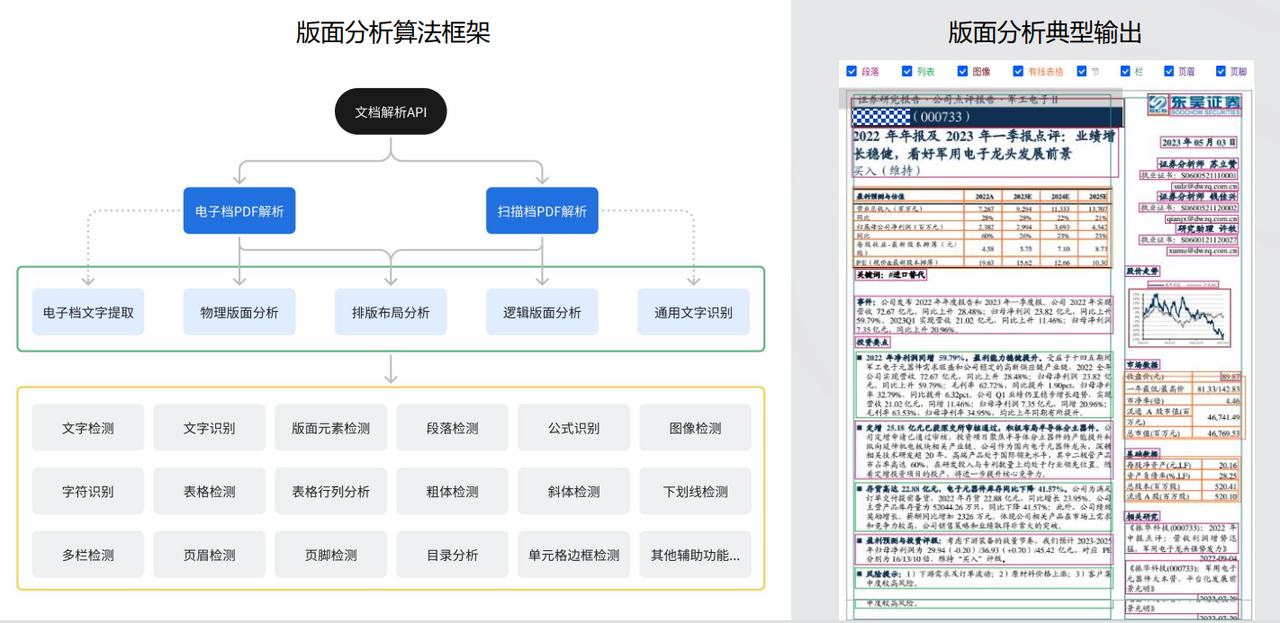
正常的阅读顺序及布局应该如下图所示:
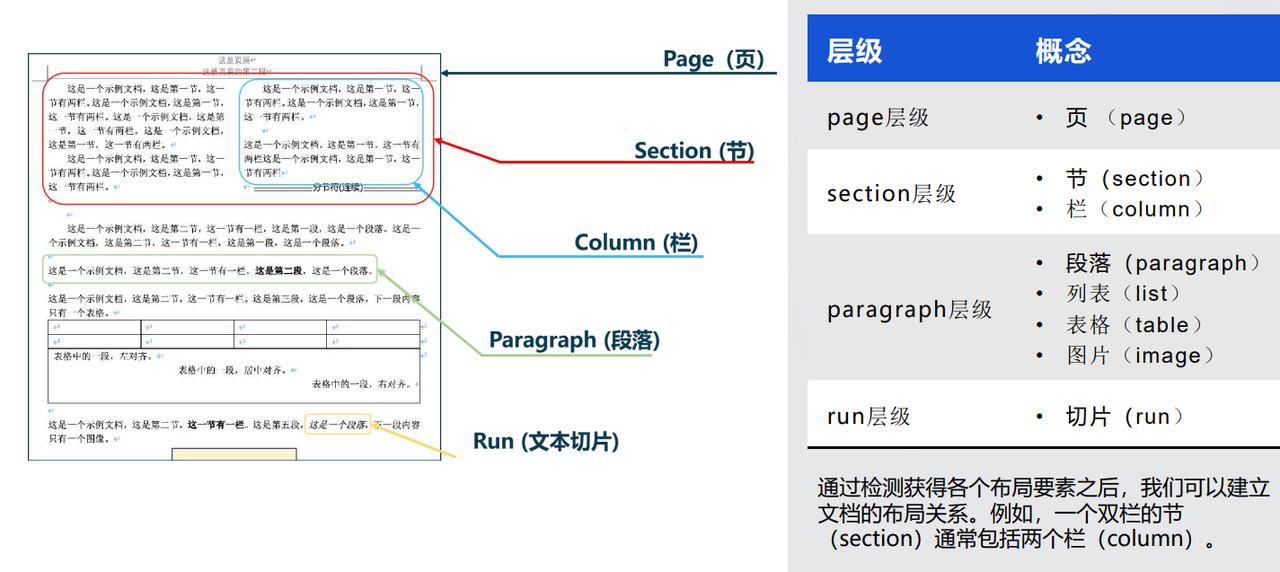 但他们团队在研究过程中发现真实世界的文档布局类型是非常丰富的,并不能以一种结构来表示:
但他们团队在研究过程中发现真实世界的文档布局类型是非常丰富的,并不能以一种结构来表示:
 他们通过逻辑版面分析算法,通过Transformer架构,预测旁系类型与父子类型来还原正确的阅读顺序:
他们通过逻辑版面分析算法,通过Transformer架构,预测旁系类型与父子类型来还原正确的阅读顺序: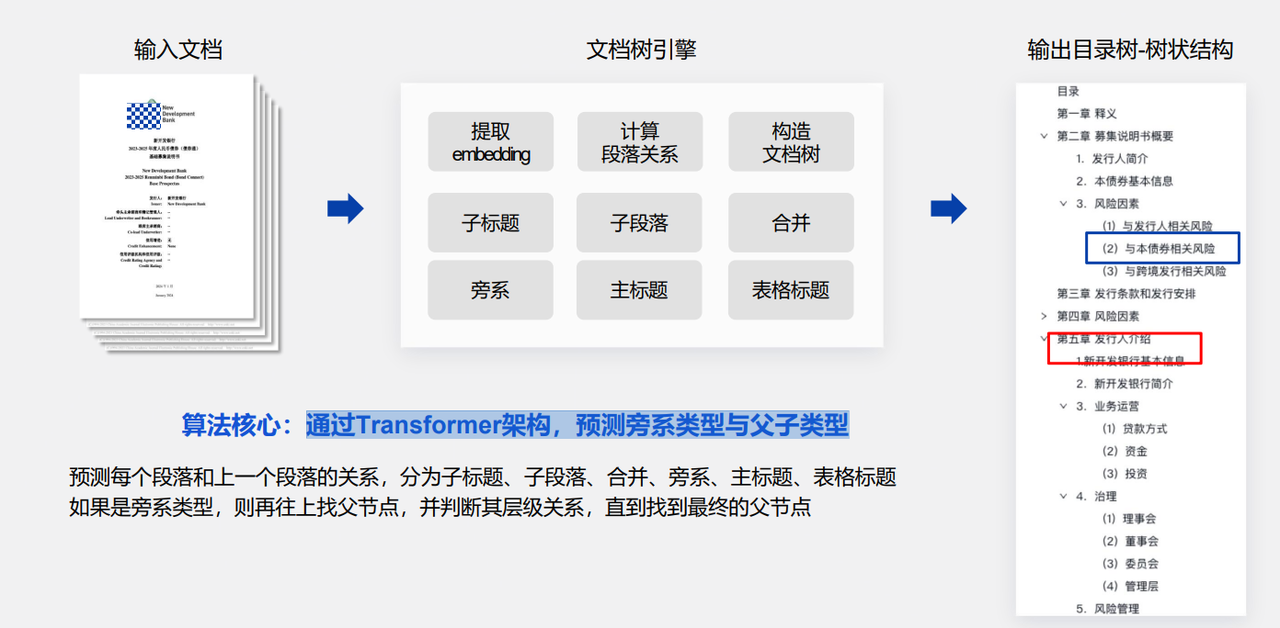
分析后得到的结果如下图所示
自上而下的双栏文档能够正确的识别顺序:
单栏双栏复合型文档同样能准确的识别顺序:

不规则双栏加图表、表格同样能准确的识别,甚至绘制出表格:

将TextIn解析技术+大模型结合后就能得到更高的文档问答精度:
刚好合合信息提供了免费使用TextIn文档解析的福利,大家访问它们的官网https://www.textin.com/即可进行体验。我也在会后体验了他们的产品,效果还是很不错的。
体验分享
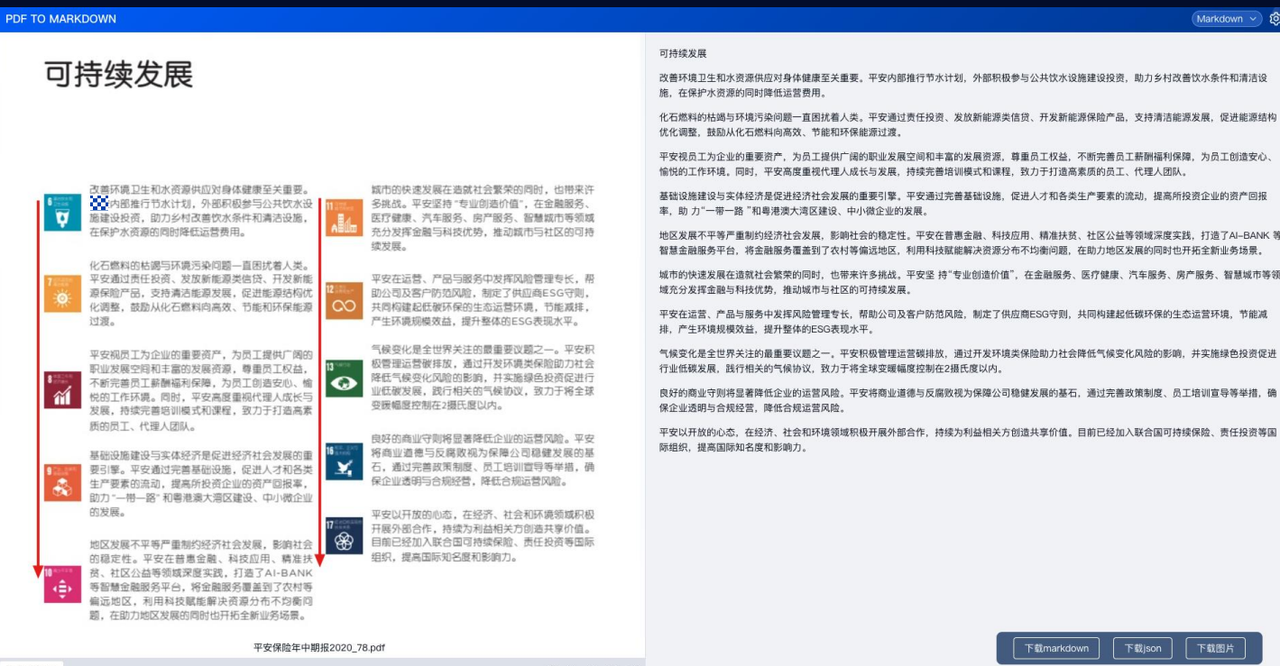
首先我使用TextIn提供的办公文档识别功能,可以看到能够准确识别出我上传的文档内容的段落和表格: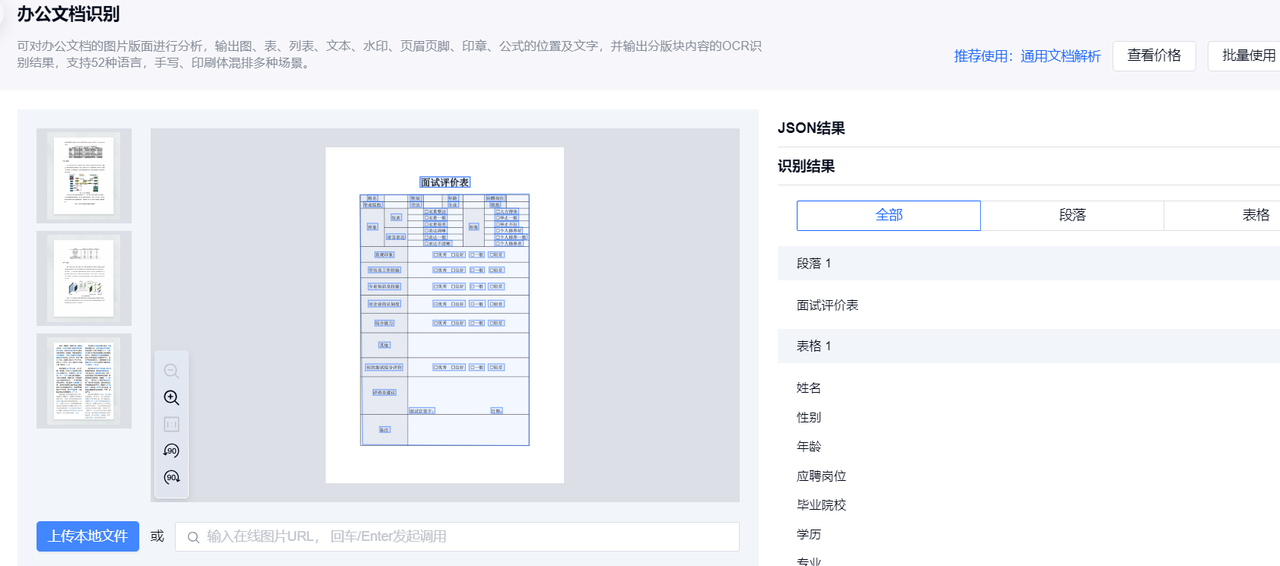
更为复杂的版式内容:图片、段落、小节等相结合的文档也难不倒它:
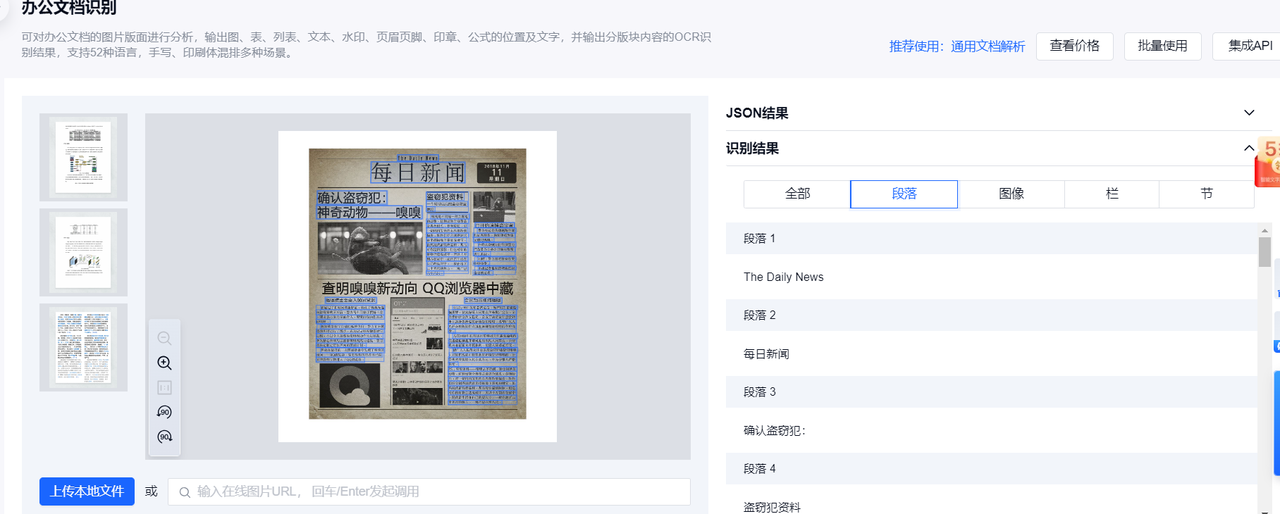
哪怕包含数学公式计算的文档也能准确识别:

随后我尝试了TextIn的通用文档解析,除了准确的文字识别外,可以看到能将我上传pdf中的无框表格内容绘制成有框表格:
这对我来说是非常有帮助的一个小功能点。
合合TextIn提供的产品远不止上面分享的这些内容,还有票据和卡证识别、图像篡改检测功能产品的提供,感兴趣以及有需求的小伙伴可以访问https://www.textin.com/进行体验:
感悟总结
现在是数字化的时代,越来越多的企业都在走向数字化的转型,现实场景中有8成的数据都是非结构化的,比如邮件、书籍、图片、和各种企业文档等都是没有固定结构。优秀的文档解析技术能够从大量文档中提取关键信息,使这些非结构化数据变得可结构化、可搜索、可分析,从而提升信息的利用率和工作效率。通过自动化解析后,办公自动化才能更好的开展,比如自动处理发票、合同、报告等文档,可以减少人工审核的工作量,降低错误率,提高业务流程的效率和准确性,这是非常有价值的事情。
对于需要遵守严格法规的企业,文档解析技术也能帮助进行自动审查文档是否符合规定格式和内容要求,支持审计跟踪和合规性检查。
除了企业外,对于视障人群也是能提供帮助的,文档解析结合OCR(光学字符识别)技术,可以将纸质文档或图像形式的文本转换为可读性强的电子文本,提升信息的可访问性。
文档解析识别是数字化时代信息处理的基础能力,对促进信息的有效利用、提升工作效率、增强合规性和推动技术创新等方面发挥着不可替代的作用。
虽然现在仍存在一些挑战和困难,好在越来越多的人加入到文档解析、图像处理的研究中。当我看到CCIG上的专家分享他们的成果以及合合信息TextIn的强大后,我相信随着科技不断的发展,大家不断的努力再多的困难都会在不久的将来迎刃而解。

