
热门标签
热门文章
- 1解决文件传输难题:如何绕过Gitee的100MB上传限制_gitee远程上传文件限制
- 2ASIC 数字设计:概述和开发流程
- 3python计算机毕设(附源码)校园二手货物交易平台(django+mysql5.7+文档)_python django 二手交易 开源代码 下载
- 4偏微分方程数值解—ADI格式求解二维抛物型方程
- 5NEO4J节点及节点间关系显示不完整的解决方法_neo4j节点文字显示不完整
- 6代码随想录第四十二天 | 62.不同路径,63.不同路径Ⅱ
- 7Python报错:UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xXX in position Y: invalid start byte_python unicodedecodeerror: 'utf-8' codec can't dec
- 8Windows 键盘 F1~F12 功能键使用指南:快速掌握各功能键的作用_键盘有f7是播放键 怎么按
- 9基于python绘制热力图_python绘制热力图 csdn
- 10VMware虚拟机中Ubuntu16.04系统下通过MVS运行海康威视工业相机_workstation连接海康威视机器人
当前位置: article > 正文
知识图谱学习笔记(七)——关系抽取_知识图谱种的关系抽取是意图识别么
作者:喵喵爱编程 | 2024-06-29 04:23:36
赞
踩
知识图谱种的关系抽取是意图识别么
关系抽取
1. 关系抽取任务定义
-
定义:Alexander Schutz等人认为关系抽取是自动识别由一对概念和联系这对概念的关系构成的相关三元组。
- eg. 特朗普是美国的总统。 总统(特朗普,美国)
-
网络文本信息结构
- 结构化数据(infobox):置信度高,规模小,缺乏个性化的属性信息
- 半结构化数据:置信度较高,规模较大,个性化的信息,形式多样,含有噪声
- 纯文本:置信度低,复杂多样,规模大。
-
结构化与半结构化文本信息(利用网页结构)
- 信息块的识别
- 模板的学习
- 属性值的抽取
-
非结构化文本的关系抽取分类
- 传统关系抽取
- 评测语料
- 专家制订类别,人工标注语料
- 开放域关系抽取
- 类别自动获取
- 语料自动生成
- 语言证据清晰表达的关系
- 传统关系抽取
2. 传统关系抽取
-
任务:给定实体关系类别,给定语料,抽取目标关系对
-
评测语料(MUC, ACE, KBP, SemEval)
- 专家标注语料,语料质量高
- 抽取的目标类别已经定义好
- 有公认的评价方式
-
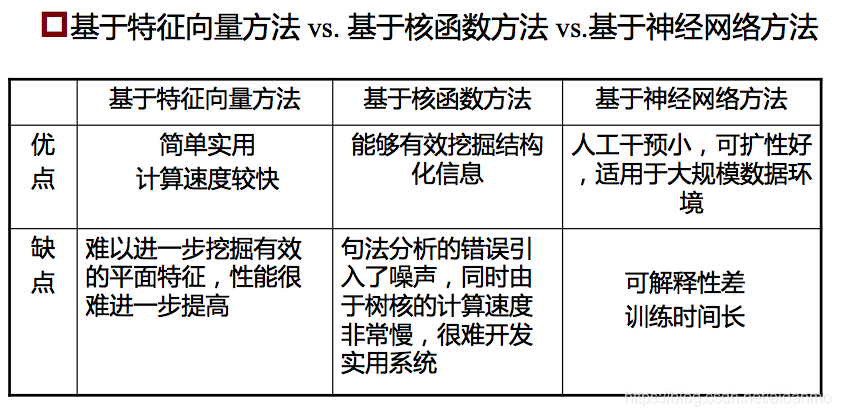
目前主要采用统计机器学习的方法,将关系实例转换成高维空间中的特征向量或直接用离散结构来表示,在标注语料库上训练生成分类模型,然后再识别实体间关系。
-
基于特征向量方法:
- 主要问题:如何获取各种有效的词法、句法、语义等特征,并把它们有效地集成起来,从而产生描述实体语义关系的各种局部特征和简单的全局特征。
- 特征选取:从自由文本及其句法结构中抽取出各种词汇特征以及结构化特征
- 实体词汇及其上下文特征
- 实体类型及其组合特征
- 交叠特征(两个实体或词组块是否在同一个名词短语、动词短语或者介词短语之中、两个实体或者词组块之间单词的个数等)
- 句法树特征(连接两个实体的语法路径)
-
基于核函数方法:
- 主要问题:如何有效挖掘反映语义关系的结构化信息及如何有效计算结构化信息之间的相似度
- 卷积树核:用两个句法树之间的公共子树的数目来衡量它们之间的相似度
- 标准的卷积树核(CTK):在计算两棵子树的相似度时,只考虑子树本身,不考虑子树的上下文信息。
- 上下文卷积树核函数(CS-CTK):在计算子树相似度时,同时考虑子树的祖先信息,如子树跟结点的父节点、祖父结点信息,并对不同祖先的子树相似度加权平均。
-
基于神经网络的方法:
- 主要问题:如何设计合理的网络结构,从而捕捉更多的信息,进而更准确地完成关系的抽取
- 网络结构:不同的网络结构捕捉文本中不同的信息
- 递归神经网络:网络的构建过程更多的考虑句子的句法结构,但是需要依赖复杂的句法分析工具
- 卷积神经网络:通过卷积操作完成句子级信息的捕获,不需要复杂的NLP工具
- 循环神经网络:通过循环神经网络建模词语之间的依赖关系,自动捕获句子级信息。
3. 开放域关系抽取
-
特点:
- 不限定关系类别
- 不限定目标文本:Web Page, Wikipedia, Query Log
- 难点问题:如何获取训练语料;如何获取实体关系类别;如何针对不同类型目标文本抽取关系
- 需要研究新的抽取方法:按需抽取——Bootstrapping,模板;开放抽取——Open IE;知识监督抽取——Distant Supervision
-
按需抽取 Bootstrapping
- Bootstrapping算法:指的就是利用有限的样本资料经由多次重复抽样,重新建立起足以代表母体样本分布的新样本。
模板生成->实例抽取->迭代直至收敛 - 语义漂移问题:迭代会引入噪音实例和噪音模板(在迭代过程中产生一些与种子不相关的实例,这些不相关的实例进入迭代过程,将会继续产生不相关的实例)
- 可以通过引入负实例来限制语义漂移。
- Bootstrapping算法:指的就是利用有限的样本资料经由多次重复抽样,重新建立起足以代表母体样本分布的新样本。
-
开放抽取
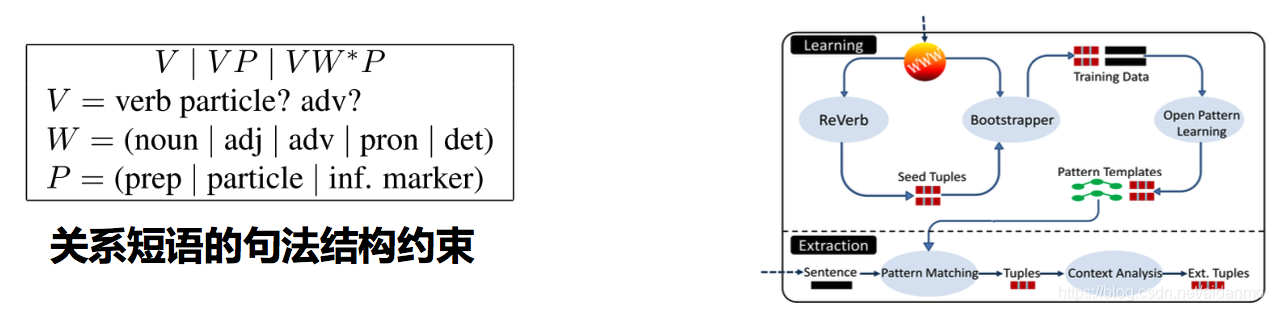
- 通过识别表达语义关系的短语来抽取实体之间的关系
- eg.(华为,总部位于,深圳),(华为,总部设置于,深圳),(华为,将其总部建于,深圳)
- 同时使用句法和统计数据来过滤抽取出来的三元组
- 关系短语应当是一个以动词为核心的短语
- 关系短语应当匹配多个不同实体对
- 优点:无需预先定义关系类别
- 缺点:语义没有归一化,同一关系有不同表示
- 通过识别表达语义关系的短语来抽取实体之间的关系
-
开放域关系抽取:Web Page(TextRunner)
- 步骤:
- 离线的训练集产生:利用简单的启发式规则,产生训练语料
- 离线的分类器训练:提取一些浅层句法特征,训练分类器,用来判断一个元组是否构成关系
- 在线关系抽取:在网络语料上,找到候选句子,提取浅层句法特征,利用分类器,判断抽取的关系对是否可信
- 在线的关系可信度评估:利用网络海量语料的冗余信息,对可信的关系对,进行评估
- 出发点:
- 关系类别的产生:动词作为关系类别
- 训练语料的产生:通过句法关系引出语义关系
- 步骤:
-
开放域关系抽取:WikiPedia
- 任务:在Wikipedia文本中抽取关系(属性)信息
- 难点:无法确定关系类别;无法获取训练语料
- 方法:在Infobox抽取关系信息;在Wikipedia条目文本中进行回标,产生训练语料
-
知识监督开放抽取:Distant Supervision
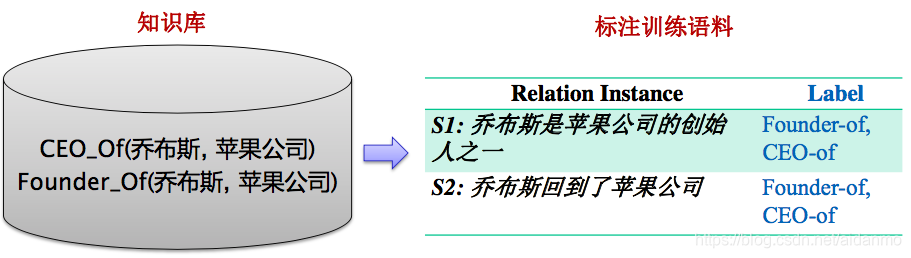
- 开放域信息抽取的一个主要问题是缺乏标注语料
- Distant Supervision:使用知识库中的关系启发式的标注训练语料
-
开放域关系抽取:从NYT(纽约时报)中抽取Freebase的关系类别(Zeng EMNLP 2015)
- Freebase包含4000多万实体,上万个属性关系,24多亿个事实三元组
- 人工标注训练集不可行,需要寻找无指导或弱指导的关系抽取方法
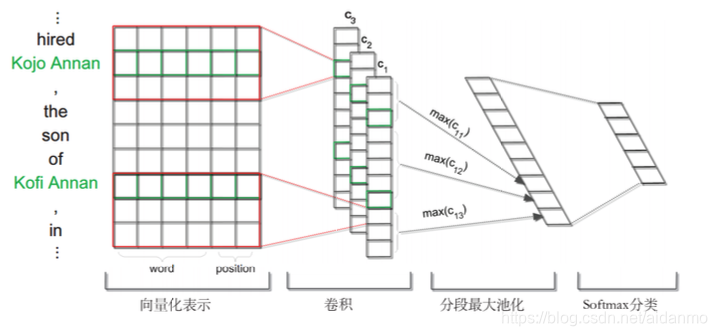
- 将弱监督关系抽取看作是多示例问题,每次选择回标的包中分类概率最大的那个示例更新参数
- 利用分类卷积网络自动学习特征:设计分段最大池化层,根据两个实体把句子分成三段,在每段里利用最大池化技术,更好地保留句子的结构化信息
- 评价方法:
- Held-out评价(留出法,直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S, 另一个作为测试集T):以Freebase中存在关系的三元组作为标准
- 人工评价:去掉已经在Freebase中存在的实体对,人工标注top N结果
-
开放域关系抽取:从NYT(纽约时报)中抽取Freebase的关系类别(Ji AAAI 2017)
- 动机:
- 传统方法:NLP工具抽取句子特征,概率图模型选择多个有效的句子,然后分类。
- 神经网络方法:卷积神经网络抽取特征效果最好,但是Zeng的方法智能选择一个有效句子,不能充分利用监督信息。
- 将两种方法的优点结合,既能选择多个有效的句子,又使用卷积神经网络抽取特征。
- 利用实体描述补充背景知识
- 基于句子级关注机制和实体描述的弱监督关系模型
- 利用背景知识库信息得到两个实体的关系,再利用这个关系向量和每个句子计算相似度,归一化后作为句子的关注度。
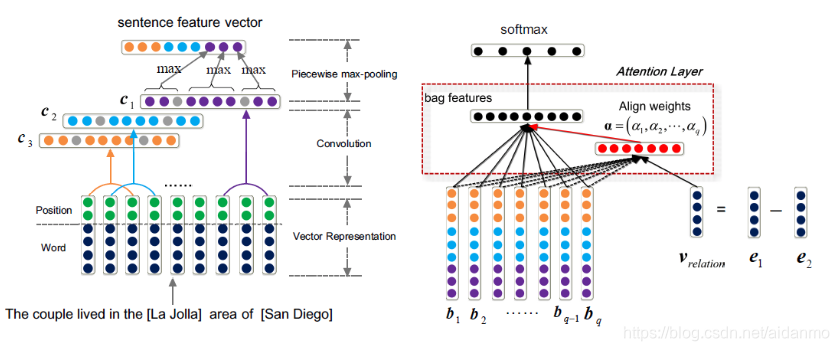
- 利用背景知识库信息得到两个实体的关系,再利用这个关系向量和每个句子计算相似度,归一化后作为句子的关注度。
- 数据集:
- 由(Riedel, Yao, and McCallum 2010)发布的数据集,通过对齐Freebase和NYT的语料形成,共包含52种关系。

- 训练和预测的对象均是多示例包,包中的句子均没有标签。新版本的数据统计:

- 由(Riedel, Yao, and McCallum 2010)发布的数据集,通过对齐Freebase和NYT的语料形成,共包含52种关系。
- 动机:
-
开放域关系抽取:从NYT(纽约时报)中抽取Freebase的关系类别(Lin ACL 2016)
- 动机:弱监督数据中包含了误标记的数据,为了减轻误标记句子对分类结果的影响,引入了关注机制(Attention),每个包中可以选多个示例。
- 方法:
- 给定一个句子集合 S = x 1 , x 2 , . . . , x n S = {x_1, x_2, ..., x_n} S=x1,x2,...,xn
- 将每个句子通过CNN表示成一个向量 X i = C N N ( x i ) X_i = CNN(x_i) Xi=CNN(xi)
- 句子集合表示为句子表示的加权和 S = ∑ i α i X i S = \sum_i \alpha_i X_i S=∑iαiXi
- 最后通过softmax分类器对句子集合进行分类
- 关注机制
α
i
=
e
x
p
(
e
i
)
∑
k
e
x
p
(
e
k
)
\alpha_i = \frac{exp(e_i)}{\sum_k exp(e_k)}
αi=∑kexp(ek)exp(ei),其中
e
i
=
x
i
A
r
e_i = x_i Ar
ei=xiAr,A是权重对角矩阵,r是关系r的向量表示。

-
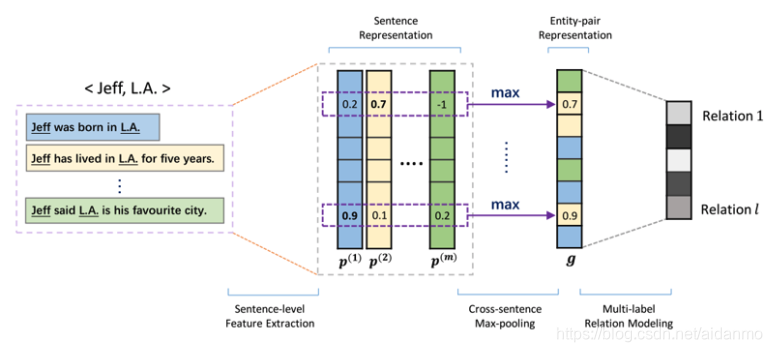
开放域关系抽取:从NYT(纽约时报)中抽取Freebase的关系类别(Jiang COLING 2016)
- 动机:有些隐含的关系需要从多句话中抽取证据才能确定;同一个实体可以对应多个关系
- 方法:
- 通过跨句子的pooling实现多句话语义的联合考虑
- 通过多目标的损失函数实现一个实体对多关系的发现
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/喵喵爱编程/article/detail/768247
推荐阅读
相关标签

