
- 1前端框架Vue、angular、React的优点和缺点
- 2《昇思25天学习打卡营第6天|函数式自动微分》
- 3自学安装Ubuntu16.04和ROS等问题_没有gpu安装ros操作系统么
- 4在线工具网址(eda/画图[visio替代]/公式编辑/公式识别/时序图)_公式识别网站
- 5Python数据分析 2-4 DataFrame索引和切片 介绍DataFrame对象的索引和切片操作。_dataframe数据能用切片吗
- 6让人费解的Error:No such property: GradleVersion for class: JetGradlePlugin
- 7分享200+个关于AI的网站_ai网站
- 8如何流畅访问github_高速hosts github
- 9Qt自定义虚拟键盘,模拟Qt插件虚拟键盘(数字键盘+全键盘),支持大小写,中英文,适用Windows Linux。_使用qt的虚拟键盘插件: qt提供了虚拟键盘插件,允许你自定义键盘的样式和行为。你
- 10【Hadoop】四、Hadoop生态综合案例 ——陌陌聊天数据分析_hadoop陌陌聊天
基于Spark3.3.4版本,实现Spark On Yarn 模式部署
赞
踩

目录
一、环境描述
系统环境描述:本教程基于CentOS 8.0版本虚拟机
Hadoop ha 集群环境说明:
机器节点信息:

Spark 集群环境说明:
机器节点信息:

注意: Spark On Yarn 需要基于 Hadoop 体系的 Yarn 调度框架,所以需要先启动Yarn 调度框架(不一定需要启动Hadoop)
二、部署Spark 节点
2.1 下载资源包
Spark 包下载地址:
Index of /dist/spark/spark-3.3.4 (apache.org)

注意:需要和Hadoop体系的版本要保持一致,我这里的Hadoop是3.3.4版本,所以,我的Spark 版本也需要是3.3.4版本。(关于hadoop部署,这里不作过多介绍,可以查看我的博文:一篇文章带你学会Hadoop-3.3.4集群部署_hdoop jdk3.3.4-CSDN博客)
2.2 解压
tar -zxvf spark-3.3.4-bin-hadoop3.tgz
2.3 配置
2.3.1 配置hadoop信息
2.3.1.1 修改yarn-site.xml
- <property>
- <name>yarn.nodemanager.resource.memory-mb</name>
- <value>4096</value>
- </property>
- <property>
- <name>yarn.nodemanager.resource.cpu-vcores</name>
- <value>4</value>
- </property>
- <property>
- <name>yarn.nodemanager.vmem-check-enabled</name>
- <value>false</value>
- </property>
-

2.3.1.2 mapred-site.xml
- <property>
- <name>mapred.job.history.server.embedded</name>
- <value>true</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>node3:10020</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>node3:50060</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.intermediate-done-dir</name>
- <value>/work/mr_history_tmp</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.done-dir</name>
- <value>/work/mr-history_done</value>
- </property>
-
2.3.2 配置spark-env.sh
- # 进入config目录
- cd spark-3.3.4-bin-hadoop3/conf
- # 重命名配置文件
- mv spark-env.sh.template spark-env.sh
- # 修改配置信息
- vim spark-env.sh
- #配置在首行即可,配置完这个spark就能知道rm,nm,以及hdfs等节点的地址
- export JAVA_HOME=/usr/local/jdk1.8.0_211
- export HADOOP_CONF_DIR=/usr/local/hadoop-3.3.4/etc/hadoop
- export YARN_CONF_DIR=/usr/local/hadoop-3.3.4/etc/hadoop
-
- #配置历史服务器,切记端口是内部端口
- export SPARK_HISTORY_OPTS="
- -Dspark.history.ui.port=18080
- -Dspark.history.fs.logDirectory=hdfs://mycluster/spark-logs
- -Dspark.history.retainedApplications=30"
-
2.3.3 配置spark-defaults.conf
- # 进入config目录
- cd spark-3.3.4-bin-hadoop3/conf
- # 重命名配置文件
- mv spark-defaults.conf.template spark-defaults.conf
- # 修改配置信息
- vim spark-defaults.conf
- # 开启spark的日期记录功能
- spark.eventLog.enabled true
- #创建spark日志路径,待会儿要创建
- spark.eventLog.dir hdfs://mycluster/spark-logs
-
- spark.history.fs.logDirectory hdfs://mycluster/spark-logs
- spark.yarn.jars hdfs://mycluster/work/spark_lib/jars/*
2.4 分发
将配置好的spark-3.3.4-bin-hadoop3 分发到其他服务器
- # 分发spark 包
- scp -r /usr/local/spark-3.3.4-bin-hadoop3/ node3:/usr/local/
- scp -r /usr/local/spark-3.3.4-bin-hadoop3/ node4:/usr/local/
- # 分发修改的hadoop的yarn-site.xml 和 mapred-site.xml
- scp -r yarn-site.xml node1:/usr/local/hadoop-3.3.4/etc/hadoop/
- scp -r mapred-site.xml node1:/usr/local/hadoop-3.3.4/etc/hadoop/
-
- scp -r yarn-site.xml node2:/usr/local/hadoop-3.3.4/etc/hadoop/
- scp -r mapred-site.xml node2:/usr/local/hadoop-3.3.4/etc/hadoop/
-
- scp -r yarn-site.xml node3:/usr/local/hadoop-3.3.4/etc/hadoop/
- scp -r mapred-site.xml node3:/usr/local/hadoop-3.3.4/etc/hadoop/
-
- scp -r yarn-site.xml node4:/usr/local/hadoop-3.3.4/etc/hadoop/
- scp -r mapred-site.xml node4:/usr/local/hadoop-3.3.4/etc/hadoop/
2.5 启动服务
2.5.1 启动hadoop集群
- # 进去hadoop目录
- cd /usr/local/hadoop-3.3.4/sbin
- # 启动hadoop集群
- start-all.sh start
-
2.5.2 启动hadoop 的historyserver
- # 启动historyserver
- mr-jobhistory-daemon.sh start historyserver
提示:如果执行mr-jobhistory-daemon.sh start historyserver 命令报如下错:
- WARNING: Use of this script to start the MR JobHistory daemon is deprecated.
- WARNING: Attempting to execute replacement "mapred --daemon start" instead.
则可以换一个执行命令执行:
mapred --daemon start historyserver

验证history 服务:
执行hadoop 自带的workcount 测试代码,首先先准备需要统计的文件内容:

然后上传到hdfs中:
hdfs dfs -put data3.txt /input/

执行提交命令,执行:
- # 进入hadoop 样例代码目录
- cd /usr/local/hadoop-3.3.4/share/hadoop/mapreduce
- # 提交样例代码执行
- hadoop jar hadoop-mapreduce-examples-3.3.4.jar workCount /input/data3.txt /output/


查看统计结果:
hdfs dfs -cat /output/result/part-r-00000

ok,执行成功了,我们看下yanr调度面板,看下history 历史服务数据,看能否查看,如果能查看,证明historyserver 服务没有问题:



我们发现,可以进入History查看里面执行情况了,那证明historyserver 服务部署成功。
注意:但是这只是hadoop体系的历史服务器,我们这里是部署spark,spark有自己的历史服务器,不是hadoop的历史服务器
2.5.2 启动spark 服务
2.5.2.1 新建目录
- # 新建 spark-logs 日志文件
- hadoop fs -mkdir /spark-logs
- # 文件授权
- hadoop fs -chmod 777 /spark-logs
-
- # 新建spark jar 包文件
- hadoop fs -mkdir -p /work/spark_lib/jars
- # 上传spark jars文件包
- hadoop fs -put /usr/local/spark-3.3.4-bin-hadoop3/jars/* /work/spark_lib/jars
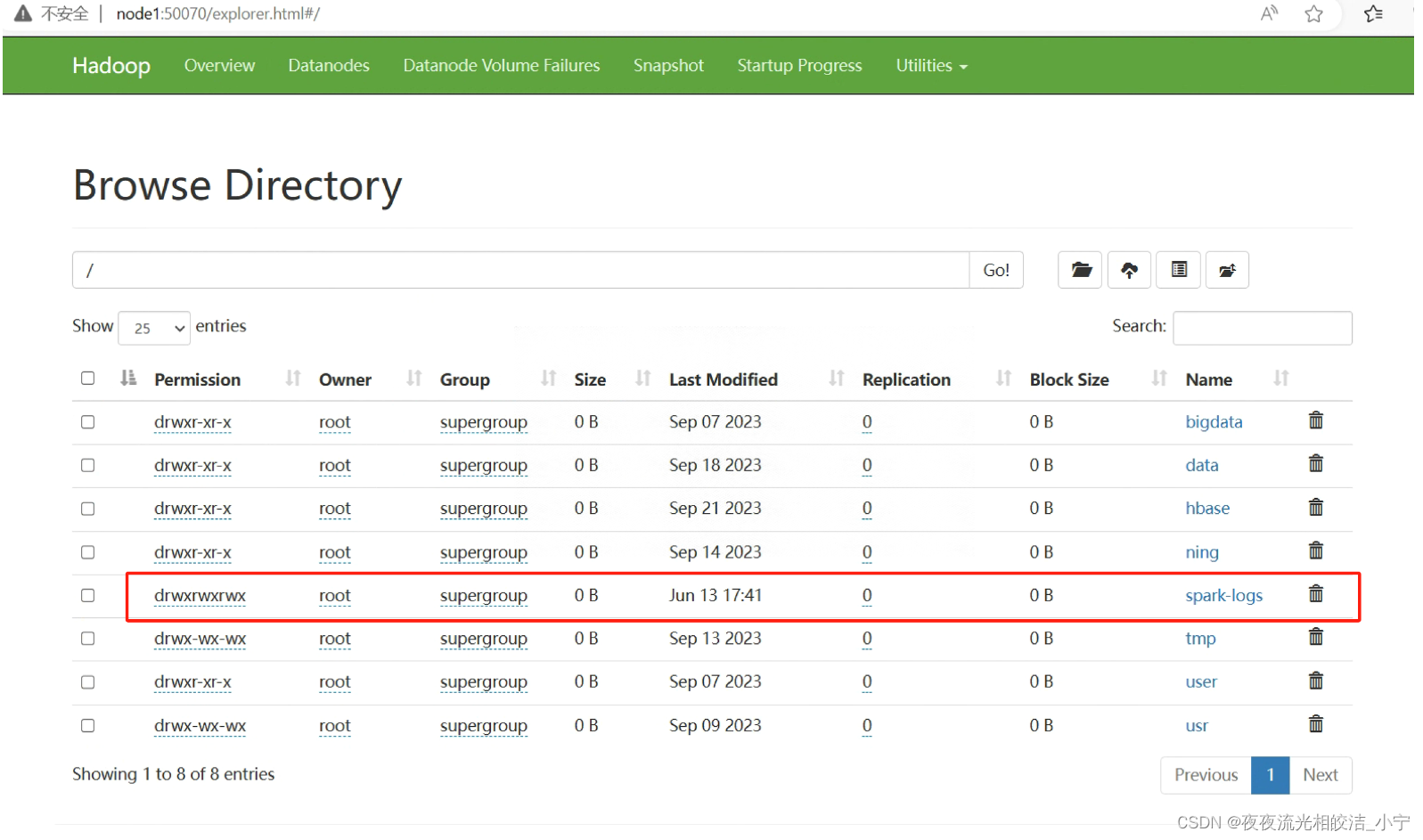

由图可见,目录创建成功了,相关文件也上传成功,接下来启动spark 服务
2.5.2.2 启动spark
- # 启动spak-shell 分别在master、node3、node4中启动
- bin/spark-shell --master yarn
- # 启动 spark 历史服务器 在master、node3、node4中启动(看你在哪个节点执行测试就在哪个节点起吧,但是cluster模式下,都要起,主要作用是当执行节点关闭后,需要通过历史服务器查看执行记录和日志)
- ./sbin/start-history-server.sh start


2.6 测试
2.6.1 测试spark-shell
- # 执行统计指令 在master中启动
- sc.textFile("hdfs://mycluster/input/data3.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
-
运行情况:
- (golang,1)
- (hello,4)
- (java,1)
- (c++,1)
- (pytion,1)

登录http://master:4040 查看





2.6.2 测试historyserver 服务
关闭node3节点的spak-shell进程,测试历史服务器:

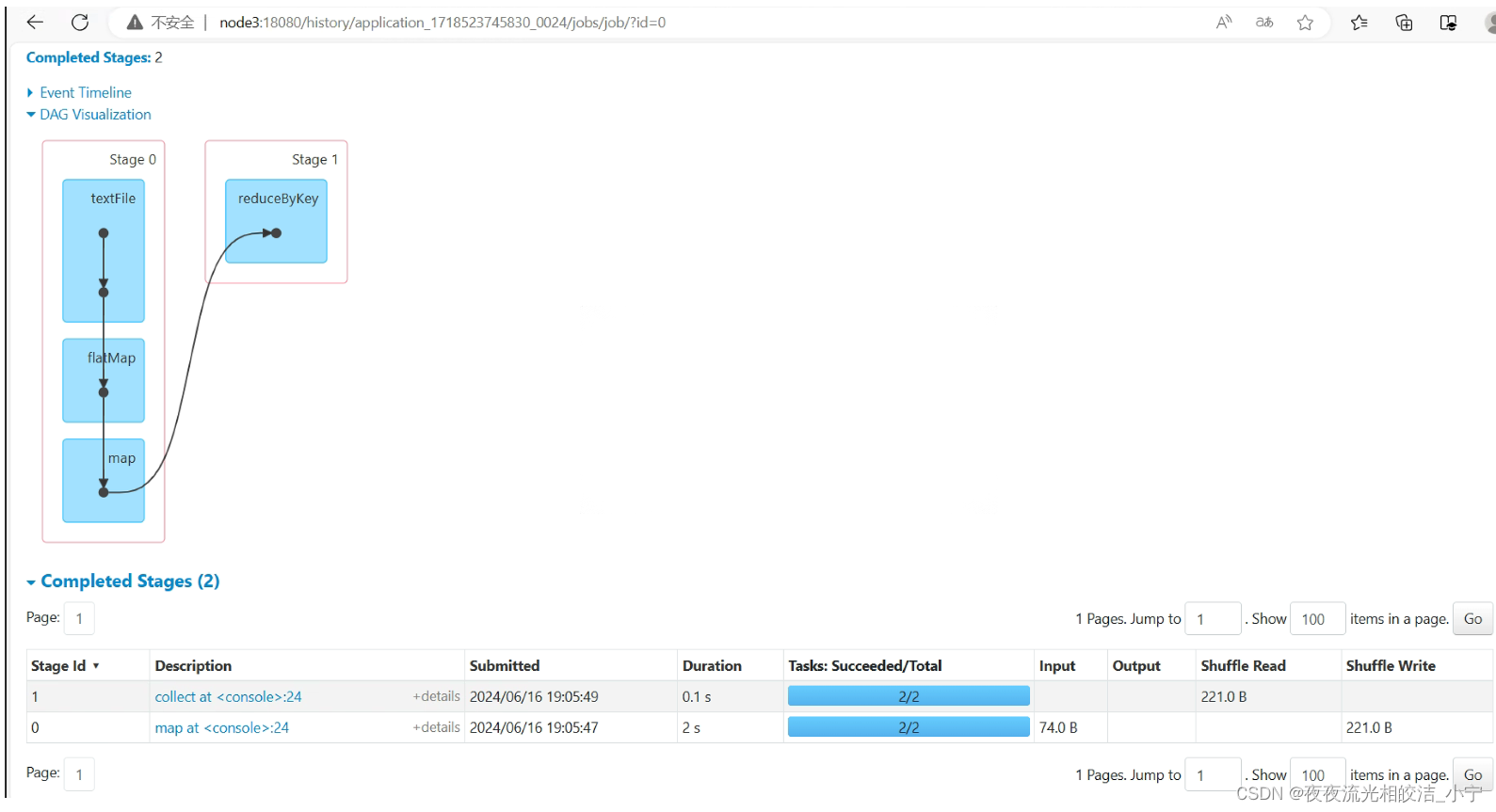
我们可以看到,关闭node3节点的spak-shell进程后,我们发现刚才的调度记录,变成了History状态,点击History,发现也点击不进去,那么我们该如何查看到历史直接记录呢?我们可以通过历史服务器查看:
访问历史服务器:http://node3:18080/

点击上图中标注出来的记录,进去就能看到和之前一样的执行记录了:

今天Spark-3.3.4 On Yarn模式部署的相关内容就分享到这里,可以关注Spark专栏《Spark》,后续不定期分享相关技术文章。如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!

