
- 1【云原生 • DevOps】devOps 入门、Maven 插件自动部署微服务_devops maven配置
- 2团员分享_AI产品脑洞系列001:Google Duplex分析
- 3【Git入门和实战】第3课:git从下载到安装再到配置全过程超详细步骤演示的保姆级教程(文末附练习题,可验证学习效果)_windows 配置git
- 4Python零基础入门篇㉖〗- 数据类型与布尔值的关系_布尔常量与数值型常量的关系
- 5Vyos防火墙功能配置
- 6(2-2)基于内容的推荐:TF-IDF(词频-逆文档频率)
- 7MBTI测试指南:如何在职场中运用你的直觉和情感智慧(包含开源免费的API)
- 8集成算法实验(Bagging策略)
- 9spring eureka漏洞_Spring boot相关漏洞利用(1)
- 10机器学习损失函数 / 激活函数 / 优化算法 总览_调用relu损失函数
【论文解读】大模型的有效探索
赞
踩
一、简要介绍

论文提出的证据表明,通过有效地探索收集人类反馈以改进大型语言模型有实质性的好处。在论文的实验中,一个代理依次生成查询,同时拟合一个奖励模型的反馈收到。论文的最佳性能代理使用双汤普森抽样生成查询,其不确定性由一个认知神经网络表示。论文的结果表明,有效的探索可以用更少的查询实现高水平的性能。此外,不确定性估计和探索方案的选择都起着关键作用。
二、背景
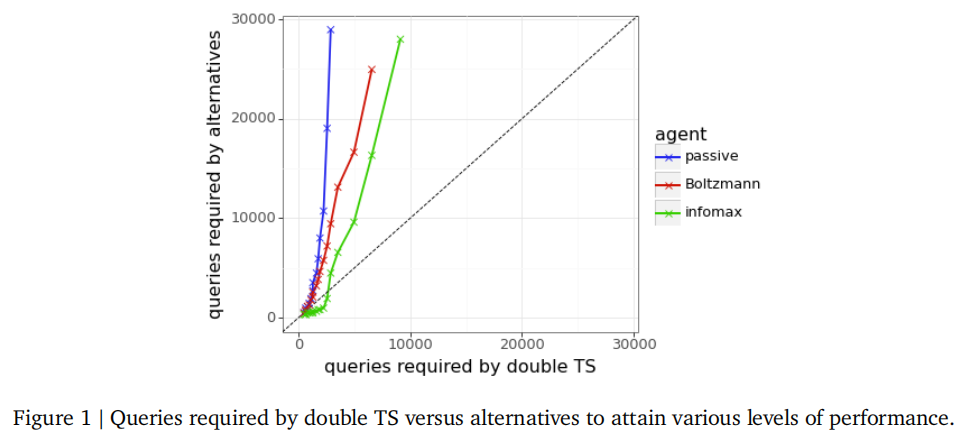
大型语言模型在从大量的文本数据中学习后显示出显著的能力,来自人类反馈的强化学习(RLHF)也极大地改善了他们的行为。聊天机器人的使用提供了收集越来越多的人类反馈的机会。人们很自然地想知道,这种不断增长的数据来源会出现什么新功能。超越人类的创造力仍然是一种诱人的可能性。 随着数量的增加,可以从人类的反馈中推断出更多。这就提供了进一步超越预先训练过的模型的信心。但是考虑到这个过程只能从人类学习,论文怎么能指望超越人类的聪明才智出现呢?也许这样的结果是合理的,因为评估比综合新的内容更容易。这类似于,对于一个NP-complete的问题,虽然解决方案很困难,但验证所提出的解决方案却很容易。 例如,假设一个预先训练过的模型从它的训练数据中推断出大量的——也许是数百万或数十亿——的想法,其中一个是巧妙的。虽然人类可能还没有提出这个想法,但从足够多的人类反馈中学习,可以从模型产生的大量想法中识别出它。而且,在这一创新的基础上,进一步的外推可以继续扩大创造力的前沿。这样,有了足够的人类反馈,一个模型就应该能够生成人类无法生成的内容。但是,收集所需的反馈是否需要数月、数年或几十年呢? 作者在这篇论文中提出了对积极探索有巨大好处的证据。通过积极的探索,论文指的是量身定制的互动,以引出有用的反馈。特别是,论文的研究结果表明,通过更少的反馈,可以获得高水平的性能。这种加速可能会使超越人类的聪明才智更快,甚至几十年。 从人类反馈(RLHF)中强化学习的一种常见做法是向人类评分者发送查询,每个查询由一个提示和一对不同的回答组成。每个评分者都表达对其中一种反应的偏好。提示从语料库中提取,而回答则由大型语言模型生成。随着这一过程的进展,奖励模型拟合于数据,并引导随后的反应与收到的反馈相一致。 在本文中,论文将注意力限制在上述类型的交互上,其中每个查询都包含一个提示的和一对不同的回答。论文将使用语言模型对每对回答进行抽样的标准实践称为被动探索。论文比较了被动探索与几种主动探索算法的性能。一个是Boltzmann探索,它倾向于选择具有更高预测奖励的反应。论文还尝试了两种利用认知神经网络(ENN)提供的不确定性估计方法。第一个,论文称之为infomax,它选择了一对回答,目的是最大化反馈所揭示的信息。这属于广泛使用的旨在最大化信息获取的算法集合。第二种方法被称为双汤普森抽样,根据它们是最优的概率对回答进行抽样。 图1比较了使用不同探索算法产生的经验结果。产生这些结果的实验在第5节中有所描述。每个绘制的点都对应于所达到的一个性能水平。水平坐标标识双TS为达到该性能级别所需的查询数量,而垂直坐标标识替代方案所需的查询数量。被动探索的图线清楚地表明,使用双TS的主动探索极大地减少了达到高性能水平所需的查询数量。在论文尝试过的算法中,论文只使用了一个点估计奖励模型,而不使用不确定性估计,Boltzmann探索表现最好。Boltzmann的图线表明,不确定性估计,如使用双TS,可取得显著的改进。最后,infomax的图线显示,即使在利用不确定性估计的尝试和测试算法中,探索算法的选择如何导致巨大的性能差异。
虽然,据论文所知,这些是证明调优大型语言模型的积极探索的第一个结果,但它们建立在与探索算法相关的长期工作历史上。特别是,论文的问题是Contextual Dueling Bandit (CDB)的一个实例,论文的算法建立在信息搜索策略和汤普森抽样。此外,论文继续了一系列工作,利用神经网络将有效的探索算法扩展到越来越复杂的环境
三、实验pipeline
论文首先介绍了论文用于研究探索算法的实验pipeline。该pipeline建立在现有工具的基础上,包括Anthropic数据集和Gemini Nano和 Gemini Pro预训练语言模型。它利用了一个人类反馈模拟器,该模拟器生成对每个查询回答之间偏好的二进制表达式。该pipeline由两部分组成:学习pipeline和评估pipeline。前者在顺序查询和学习过程中控制代理和人工反馈模拟器之间的接口。后者控制了评估相对性能的语言预训练模型、新的回答生成模型和人工反馈模拟器之间的接口。 代理从反馈到查询依次学习,每个查询由一个提示回答和两个替代回答组成。如图2所示,每个查询都由代理精心制作,并呈现给一个人类偏好模拟器,这表明了两者之间偏好。在交互的每个阶段,代理传输一批B查询并接收B比特的反馈。每个提示都从人人类帮助基训练数据集中均匀采样。论文研究的每个代理,当出现一个提示时,首先使用Gemini Nano模型生成N个候选对象,然后应用一个探索算法,从这N个中选择两个。探索方案访问一个奖励模型,该模型根据迄今为止观察到的查询和反馈进行训练。论文所考虑的每个代理都通过其探索算法和产生其奖励模型的架构和训练算法来区分。在论文所考虑的一些代理中,奖励模型采取了认知神经网络的形式,它除了点估计外,还提供了探索算法对不确定性估计的访问。每个奖励模型都建立在Gemini Nano模型的主干之上。论文的意思是,奖励模型首先计算预先训练过的transformer模型的最后一层嵌入,然后应用一个多层感知器(MLP)头部。
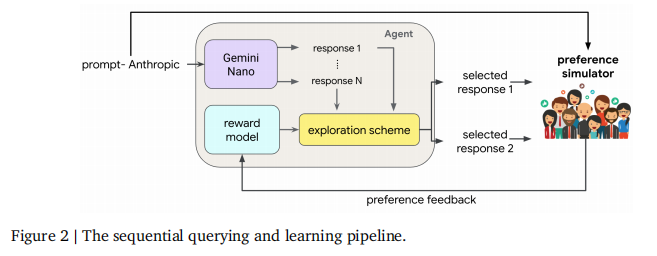
为了模拟人类如何在回答之间做出选择,论文使用了一个奖励模型,对每个提示-回答对进行评分。对于每个查询,根据Bradley-Terry选择模型,根据分配给两个提示回答配对的分数,抽样一个偏好。这个模拟器使用的奖励模型适合于人类主义的数据集,其架构重用了Gemini Pro语言模型的主干。进一步的细节在附录a中提供。请注意,由于Gemini Pro比Gemini Nano大得多,选择是由一个比代理可用的模型复杂得多的模型做出的。这种规模上的差异旨在反映这样一个事实,即人类可能表现出比主体所模拟的更复杂的行为。算法1提供了在论文的学习pipeline中对交互的简明演示——特别是向代理和模拟器传输和接收的东西。

图3说明了论文用于评估代理性能的pipeline。从Anthropic Helpfulness Base eval数据集中采样一系列提示。对于每一个提示,将采样两个回答。一个是Gemini Nano,另一个是一个新的使用学习奖励模型的回答生成模型。这个新模型通过使用Gemini Nano对N个回答进行采样,然后根据代理的奖励模型选择得分最高的模型。人类偏好模拟器输出其选择代理回答的概率,而不是由Gemini Nano生成的替代方案。这些概率在提示上被平均,这个平均值被称为代理的获胜率。请注意,获胜率也可以通过平均模拟选择的二进制指示来估计,尽管以这种方式产生的估计将需要大量的查询来收敛。算法2提供了在评估阶段的交互作用的简明表示。
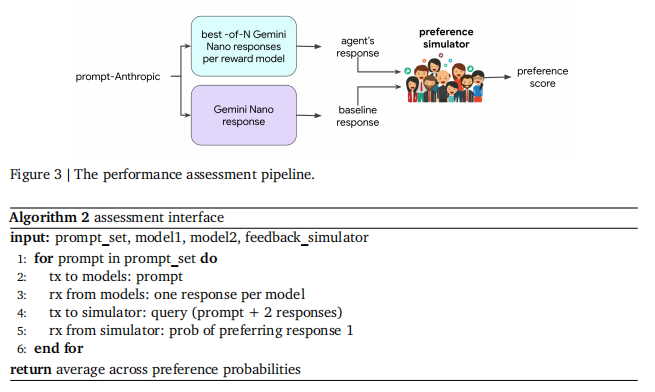
请注意,论文的实验pipeline避开了通常用于优化奖励的策略梯度方法。相反,论文的代理从基础语言模型(Gemini Nano)中抽取N个回答,并从那些最大化奖励的反应中选择。Best-of-N过程用于近似的基于策略梯度的优化,但没有其繁琐的计算要求。Best-of-N过程也培养了更透明的分析,因为它避免了从策略梯度方法中经常需要的超参数修补的依赖。一个典型的策略梯度方法最小化了一个平衡两个目标之间的损失函数:与基本语言模型的相似性和与奖励的对齐。一个标量超参数乘相似度度量,在这些目标之间取得平衡。参数N在Best-of-N方法中也起着类似的作用。随着N的增加,最大化过度的反应更接近于代理与奖励。调节N会激励更类似于基本语言模型的代理行为。
四、奖励模型架构和训练
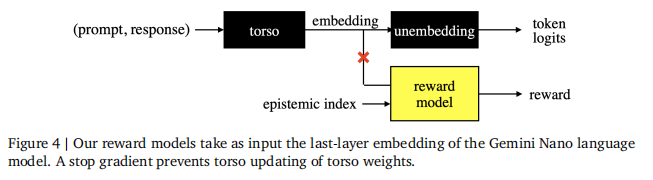
奖励模型在论文的实验pipeline的学习和评估阶段指导回答选择。论文考虑了两种类型的奖励模型,每种都符合观察到的偏好数据。第一种是一个点估计,它为每个提示-回答对分配一个奖励。第二种方法还依赖于一个认知指数。从参考分布中抽样一个认知指数会导致奖励的随机性,这模拟了关于奖励的认知不确定性。在本节中,论文将描述在实验中使用的神经网络结构和训练算法。 论文训练奖励模型,每个模型都以GeminiNano语言模型的最后一层嵌入作为输入。如图4所示,一个奖励被分配给一个提示-回答对,它首先通过语言模型的主干,然后通过一个奖励模型。
3.1.点估计

论文根据偏好数据来训练奖励模型。每个数据点由一个查询组成,包括一个提示和一对回答,以及回答之间偏好。给定这些数据点的集合D,为了计算MLP参数,论文优化了损失函数
![]()

3.2.认知神经网络
论文使用认知神经网络(enn)来模拟关于奖励的认知不确定性。给定数据集D,通过最小化损失函数得到ENN参数。
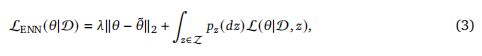

3.3.训练
为了训练每个奖励模型,论文维护了一个replay buffer,并对前文中描述的损失函数应用了一个随机梯度下降(SGD)算法。特别地,在每个交互阶段的结束时,代理在此阶段传输B个查询并接收B位反馈,代理将生成的B数据点插入容量为C的FIFO replay buffer中。然后,从replay buffer中随机的小批应用SGD步骤,步长由ADAM调整。已经训练过的奖励模型被用来确定在随后的epoch中制定的查询。
五、探索算法
论文现在描述了在论文的实证研究中使用的探索算法集.
4.1.被动探索


4.2.主动探索与一个点估计




4.3.主动探索

Infomax(算法5)以一个ENN奖励模型作为输入。与Boltzmann探索(算法4)一样,infomax从生成N个回答的语言模型开始。然后,从p中抽取M个认知指数。对于每一对回答和每个认知指数,ENN分配了一个概率给一个随机的人类评分者更喜欢第一个回答而不是第二个回答的事件。Infomax评估关于这个概率的不确定性是计算M个认知指数的样本方差。然后,该算法选择这对回答来最大化不确定性。直观地说,这可以被认为是对反馈信息量的最大化测量。 infomax的一个可能的限制是,该算法致力于寻找关于奖励的信息,无论这些信息是否对选择最佳回答有用。例如,infomax致力于细化奖励的估计,根据之前的反馈确定这是一个糟糕的选择。另一方面,双汤普森抽样更倾向于更多地关注有助于确定最佳回答的查询。正如论文看到的,双TS提高了infomax以及Boltzmann探索的性能。

直观地说,双TS(算法6)的目标是选择两个回答,每个回答都有机会成为最优的。就像算法4和算法5一样,论文首先采样N个回答。然后,在N个回答中选择两个,这两个是通过从p中抽取两个认知指数,并最大化每个指数规定的奖励。如果样本是相同的,第二个回答被重新采样,直到它不同。如果在K次迭代后没有差异,则对第二个回答进行均匀采样。

六、实证结果
在论文的实验中,在每个交互阶段的开始时,每个代理都会收到B= 32提示,然后,为每个提示生成一对回答以形成一个查询。每个代理的B= 32查询都被提交到首选项模拟器,从而产生B= 32 bits的反馈。每个代理将批B= 32数据点插入其replay buffer。replay buffer是FIFO缓冲区,最大容量为C= 3200数据点。换句话说,replay buffer保存了来自最多100个最近batch的偏好数据。在每个batch结束时,每个代理都会更新其奖励模型。 回想一下,每个探索算法从Gemini Nano采样的N个候选对象中选择每一对回答。在论文的实验中,论文设置了N = 100。在本次评估中选择的每个回答都是得分最高的 N= 100候选,由Gemini Nano根据代理的奖励模型进行抽样。请注意,论文在训练和评估pipeline中都使用了N = 100个回答。

Boltzmann探索计划,论文试过了几个温度,发现较小的温度产生了最好的结果。通过Boltzmann方案的一个变体,实现了类似的性能水平,该方案贪婪地选择其中一个回答,并使用Boltzmann选择第二个回答。更多细节见附录C。 在infomax的情况下,论文使用了30个认知指数来计算均值和方差。对于双TS代理,论文设置了对K = 30产生明显的第二回答的最大尝试次数。附录B提供了关于论文的超参数选择过程的进一步细节。 5.1.探索算法的评估 图5绘制了每个代理在不同数量的交互时期中的速率。通过5个随机种子平均得到的结果清楚地表明,主动探索加速学习,并导致更高的胜率。值得注意的是,双TS代理成为了表现最好的代理。 论文观察到,infomax在早期表现非常好,但后来远远低于双TS。这种差异可能是由于infomax倾向于寻求信息,而不管这些信息是否有助于理想的反应。 图5中的每条性能曲线似乎都收敛,而人们希望随着人际互动的增加而继续改进。奖励模型的能力——可以认为是从反馈中学习到的有效参数的数量——反映了改进的程度。对于任何容量,人们都会期望随着查询数量的增长而收敛。增加容量可以以增加计算为代价进一步改进。这与Arumugam & Van Roy所解释的概念有关,即基于代理期望探索的持续时间来调节学习目标的复杂性是有益的。
5.2.按反馈量进行调整
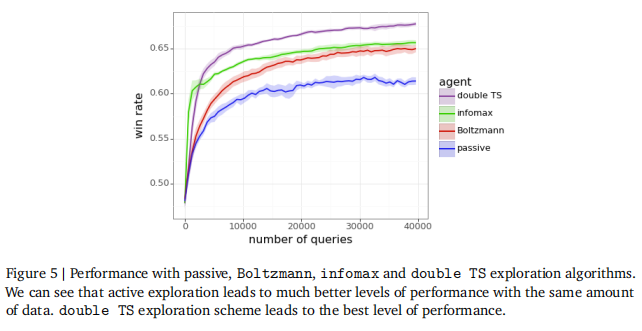
图1,绘制了替代方案所需的匹配双TS性能的查询数量,论文发现这在论文考虑的探索算法中是最有效的。虽然这些曲线不是决定性的,但论文发现它们是凹形的。假设论文根据达到任何给定性能水平所需的数据减少百分比来衡量有效探索的优势。图1中的曲线的一致性意味着,随着人类反馈数据规模的增长,有效探索所带来的优势也在增长。对于30,000个被动查询所达到的性能水平,双TS将数据需求降低了一个数量级。一种可能性是,随着相互作用的数量增加到数十亿次,有效的探索可能会提供一个达到几个数量级的乘数效应。这有可能加速几十年来实现超越人类的创造力。 5.3.不确定性估计的质量 Boltzmann探索在论文尝试的基于点估计奖励模型选择查询的算法中表现最好。论文的ENN奖励模型提供的不确定性估计使双TS所证明的巨大改进成为可能。 不确定性估计的质量可以通过二元联合负对数损失(NLL)来评估。图6和图7绘制了论文的点估计和ENN奖励模型的边缘和二元联合NLL,每个模型都训练了40,000个查询。这些图表明,虽然两种奖励模型都呈现了相似的边缘NLL,但ENN奖励模型提供了高度有利的二元联合NLL。这是为了论文的ENN奖励模型确实产生了有意义的不确定性估计。 论文还使用二元联合NLL来指导论文的点估计的超参数选择和ENN奖励模型。特别地,论文横扫了学习率的候选对象,训练代理在多个epoch进行训练,以识别最小二元联合NLL。
5.4.提示的生命
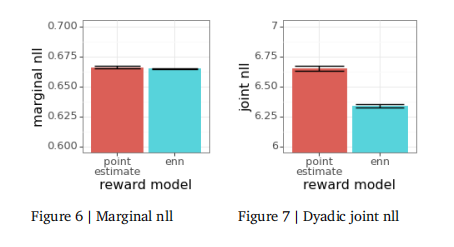
论文的结果表明,双TS倾向于收敛于更好的回答。为了更具体地理解这是如何发生的,让论文研究模型对特定提示的反应。为了简化这个调查,论文将只比较双TS和Boltzmann探索。 回想一下,论文发现Boltzmann探索是基于点估计奖励模型的算法中表现最好的。另一方面,双TS利用了ENN奖励模型提供的不确定性估计。论文将检查从eval数据集中选择的与单个提示和两个回答相关的估计值。第一个是双TS得到的回答,而第二个是Boltzmann探索得到的回答。人类反馈模拟器显示了57.5%的情况偏好第一个提示。 图8绘制了每个奖励模型提供的对第一个回答是首选的概率的预测。水平虚线表示反馈模拟器表示对第一回答的偏好的概率为0.575。随着奖励模型从查询中学习到的信息,预测也会不断演变。在40,000个查询之后,双倍TS得到的预测值大于一半,表示对第一个回答的偏好。另一方面,Boltzmann探索表达了对第二个的偏好,预测小于一半。
图中还显示了基于ENN奖励模型所表示的不确定性的双标准差置信区间。虽然在某些时候双TS点预测小于一半,但其置信区间的上限仍然大于一半。因此,它仍然不确定哪一种是更好的回答。在解决这种不确定性时,它会恢复并得出超过一半的预测。另一方面,Boltzmann探索不受不确定性估计的指导,因此不能从错误的预测中恢复。
七、结论
据论文所知,论文所展示的结果首次证明了在调优大型语言模型时进行主动探索的实质性好处。话虽如此,在这一领域还有很大的进一步工作的空间。最后,论文讨论了几个重要的研究方向。
论文的实验使用了一个特别简单的ENN架构,由一个MLP的集合组成。替代体系结构在计算需求和不确定性估计的质量之间进行了更有效的权衡。此外,除了基于MLP设计ENN之外,还可以通过基于transformer架构的ENN设计来提高性能,特别是随着人类反馈数据数量的增长。
论文的奖励模型架构的另一个限制是,每个架构都只是一个“头”,它将LLM的最后一层嵌入作为输入。同时,还可以通过调整LLM的主干来提高性能。虽然高效探索所带来的优势应该得到扩展,但在调整更多的LLM的同时,确定更有效的探索架构和算法仍有待于未来的工作。
最后,对多回合对话的有效探索为未来的研究提供了一个有趣而重要的方向。在本文中,论文将探索视为一种快速识别被认为可取的回答的方法。在多回合对话框中,可以选择回答,因为它们如何塑造后续的交互。深入探索的主题是解决一个代理如何有效地识别构成顺序交互的有效回答。利用深度探索算法来改进对话仍然是一个挑战。

