
- 1RayLink远程控制软件【文件传输】功能正式上线!!!_raylink连接同一网络中的电脑
- 2《机器学习》读书笔记:总结“第3章线性模型”中的概念
- 3腾讯云 Web 超级播放器开发实战_腾讯视频播放器开发
- 4准备提交到 App Store_app 内购买项目准备提交
- 5IntelliJ IDEA 控制台中文乱码,统一设置 UTF-8,解决方案都在这里了,完美解决乱码_控制台乱码
- 6Flink集群运行模式
- 7基于python实现去除视频的水印_python 视频去水印
- 8VTK_3D坐标系(vtkAxesActor/vtkCubeAxesActor)_vtk绘制背景刻度
- 9从头搭建pytorch Docker镜像_docker pytorch镜像
- 10一篇了解NLP中的注意力机制_注意力nlp
图文实录|多模态自然语言处理最新进展_多模态自然语言处理的最新进展,澜舟科技
赞
踩
作者介绍
段楠,微软亚洲研究院自然语言计算组高级研究经理,中国科学技术大学兼职博导,天津大学兼职教授,主要从事自然语言处理、编程语言处理、多模态人工智能、机器推理等研究,多次担任NLP/AI/ML相关国际会议评测主席、高级领域主席和领域主席,发表学术论文100余篇。
本文根据段楠老师在「澜舟NLP分享会」上的演讲整理。文内梳理了视觉语言预训练近期工作,并分享了微软亚洲研究院在视觉语言预训练模型和视觉合成方面的研究。
目录
桥塔架构(Bridge-Tower Architecture)
背景
近三年来,基于 Transformer 和自监督预训练的语言模型取得了非常瞩目的成绩。这些模型通过自回归、降噪自编码器、对比学习等自监督学习任务,能够从海量的单语或者多语语料中学习到语言的通用表示,然后通过微调等方式适配到各种各样的下游任务上去,例如问答、文本生成、机器翻译等。
与此同时,随着视觉领域 VQVAE、一些聚类算法等的发展,以及语音领域上一些离散化方法的发展,我们实际上可以将视觉数据和语音数据也转换成类似语言序列的离散符号的序列表示。由于这种底层数据表示的一致性,多模态任务的建模方法也非常快速地趋同,这也是多模态能够成为人工智能领域一个非常前沿的研究的原因。
在这样的背景下,本文将深入介绍微软亚洲研究院最近在两个多模态相关的工作,一个是视觉语言预训练模型,另一个是视觉合成方面的研究。
视觉语言预训练
相关工作梳理
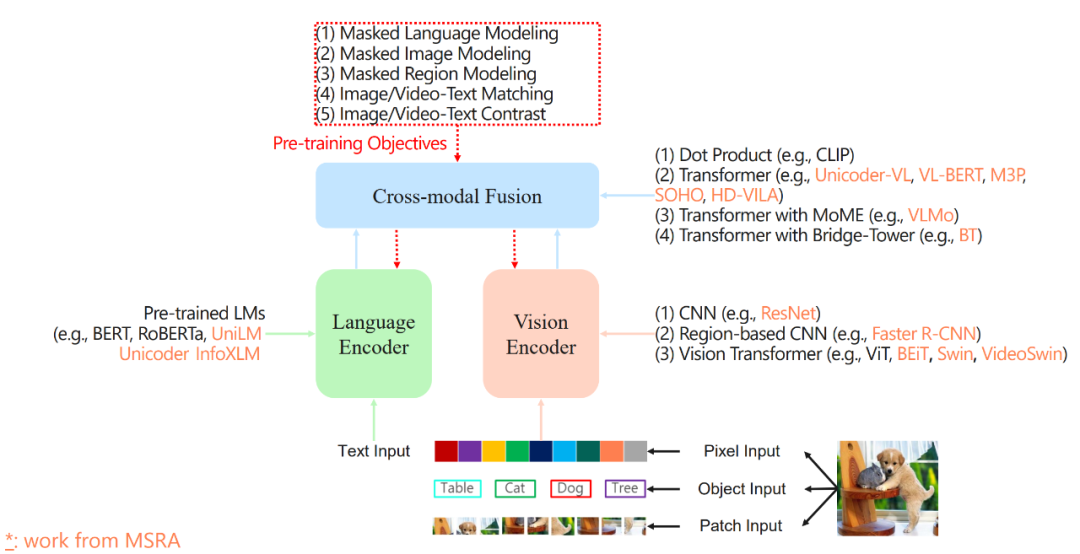
图 1
首先回顾下视觉语言预训练的一些相关工作,如图 1 所示
首先,对视觉内容的离散化是第一步,一般有三种常见的离散化方式:
-
pixel input: 以像素为单位将图像转换为序列
-
object input: 先从图像中抽取若干对象(object)以及对应的特征,然后将其转换为序列,这是 Faster RCNN 所采用的方式。
-
patch input: 以图像块为单位将图像转换为序列
然后,对序列化后的视觉内容进行编码,常用的方式有:
-
卷积神经网络:属于比较早期的方式,比如 MSRA 之前提出的 ResNet。
-
基于区域的卷积神经网络:将图像中的对象抽取出来作为整体的表示,例如 Faster RCNN 等。
-
视觉 Transformer: 使用 Transformer 对图像进行编码,例如 MSRA 的 BEiT, Swin, VideoSwin 等。
接着,进行两个模态的信息融合与交互:
-
点积:例如 CLIP 等,将编码后的视觉和语言表示通过点积计算相似度等,这是最简单的一种 V-L 交互方式。
-
使用 Transformer 进行交互:将视觉、语言表示输入到 Transformer 中,使用 Transformer 的自注意力等模块进行跨模态交互。早期视觉-语言预训练技术常采用这种方式。
-
混合专家(Mixture-of-Experts, MoE):MoE 最开始主要用于大模型的稀疏化,这里用于多模态场景,例如 MSRA 的 VLMo 主要的思想是:通过切换特定输入下的不同的专家(experts),

