
- 1已解决:pycharm上传代码更新到GitHub的时候怎么更新到对应的 Releases 中_github 发布release
- 2【虚拟化】虚拟机xml文件解析_虚拟机xml文件配置
- 3Spring Cloud Zuul-“网关“灰度发布S_灰度发布如何处理新旧流量切换时未处理完的请求
- 4基于k8s实现算法训练系统(架构思路+落地方案)_算法训练管理
- 5postgresql【数据库管理】用户权限、更改密码、数据备份、启动、停止、重启动数据库_postgres本地账户和密码
- 6基于ChatGPT API的PC端软件开发过程遇到的问题的分析_chatgpt api 开发
- 7Scrapy 爬取旅游景点相关数据( 二 )
- 8使用香橙派Kunpeng Pro自建网站服务器_香橙派可以制作为服务器吗
- 9BadDet: Backdoor Attacks on Object Detection——面向目标检测的后门攻击_attack object detection
- 10从0到1搭建文档库——sphinx + git + read the docs_readthedocs搭建
BloombergGPT: 首个金融垂直领域大语言模型_垂直领域的自然语言
赞
踩
BloombergGPT: 首个金融垂直领域大语言模型
Bloomberg 刚刚发布了一篇研究论文,详细介绍了他们最新的突破性技术 BloombergGPT。BloombergGPT是一个大型生成式人工智能模型,专门使用大量金融数据进行了训练,以支持金融行业自然语言处理 (NLP) 任务。
随着ChatGPT的发布,人工智能取得了长足进步。但金融领域相当复杂且独特的领域,它往往受着严厉的合规监管,对事实正确性要求极高。这就是 BloombergGPT 诞生的原因——它是第一个专门为金融行业设计的大型语言模型。该模型将帮助Bloomberg在内的众多金融企业改进现有的金融 NLP 任务,如情绪分析、命名实体识别、新闻分类和问答等。 此外,Bloomberg计划将来将BloombergGPT嵌入自家终端中,以利用Bloomberg终端上可用的大量数据更好地为客户服务。
本文将对BloombergGPT做一个摘要性解读

论文摘要
NLP 在金融技术领域的应用广泛且复杂,主要应用场景包括情感分析、命名实体识别到问答等。 大语言模型 (LLM) 已被证明可以有效处理上述任务;但是,鲜少没有报道过有专门针对金融领域的文献。本作中,我们展示了 BloombergGPT 这个拥有 500 亿参数的语言模型,它采用大量金融数据训练而来。我们基于 Bloomberg 大量的数据源构建了一个 3630 亿个token数据集,这可能是迄今为止最大的特定领域数据集,并增加了来自通用数据集的 3450 亿个token。我们在标准 LLM 基准、开放金融基准和一套最能准确反映我们预期用途的内部基准上验证了 BloombergGPT。我们的混合数据集训练得到的模型表现出在不牺牲一般 LLM 基准测试性能的情况下,在金融任务上的性能明显优于现有模型。此外,我们还解释了我们的建模选择、训练过程和评估方法。 下一步,我们计划发布训练日志,详细说明我们在训练 BloombergGPT 方面的经验。
数据来源
**十多年来,Bloomberg一直是人工智能、机器学习和金融 NLP 领域的领导者。**他们开发了一种混合方法,将金融数据与通用数据集相结合,从而训练出一个既能在通用 LLM 基准测试中表现出色,同时又能输出一流的金融相关结果的模型。
为了开发 BloombergGPT,机器学习产品和研究小组与 AI 工程团队合作创建了(可能是)迄今为止最大的特定领域数据集。 他们利用Bloomberg现有的数据创建、收集和资源工具,利用其海量的金融数据文档创建了一个由英文金融文件组成的 3630 亿token的综合数据集。 然后,他们使用 3450 亿个token的公共数据集扩充此数据,创建了一个包含超过 7000 亿个token的训练语料库。
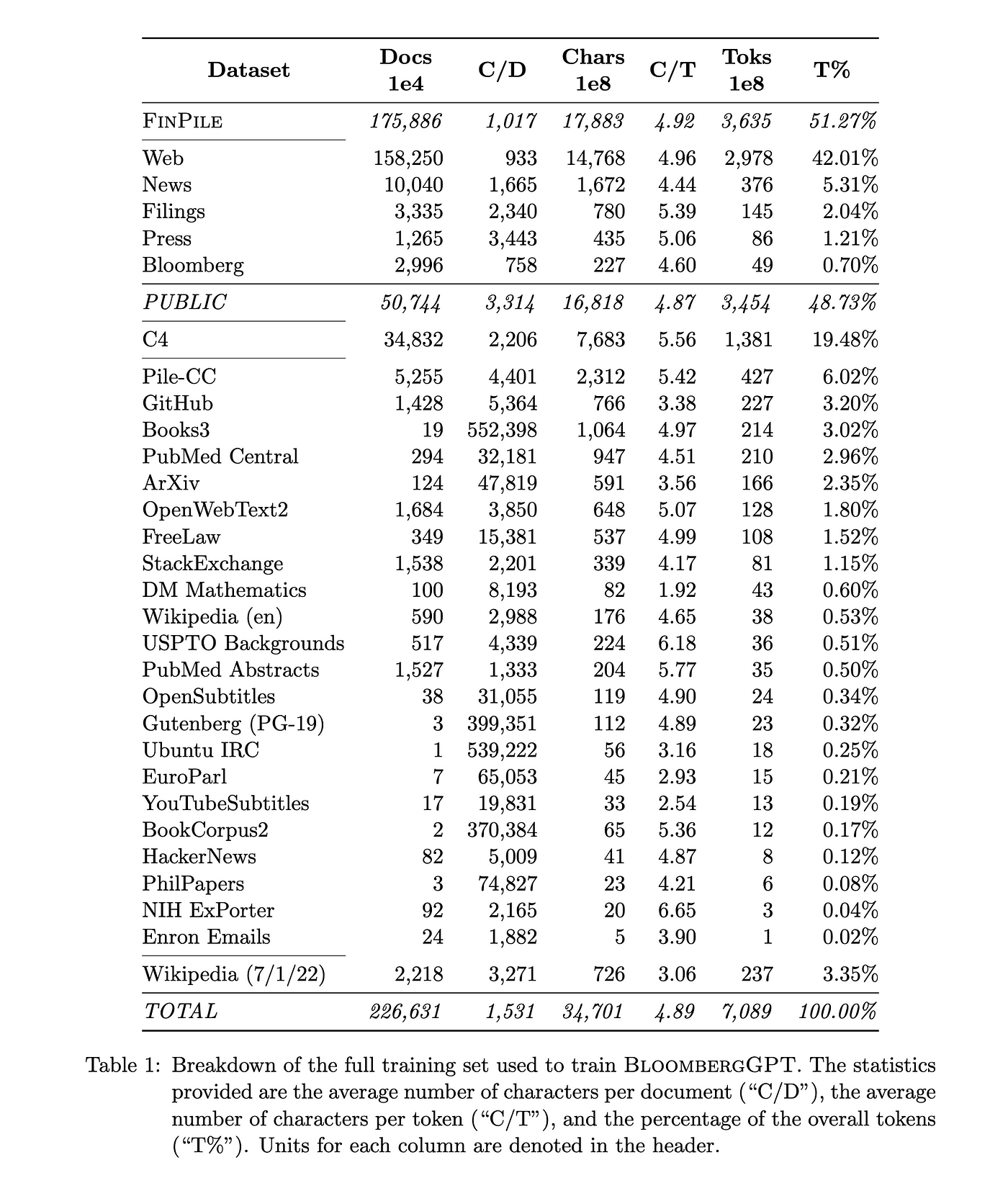
数据的年代分布
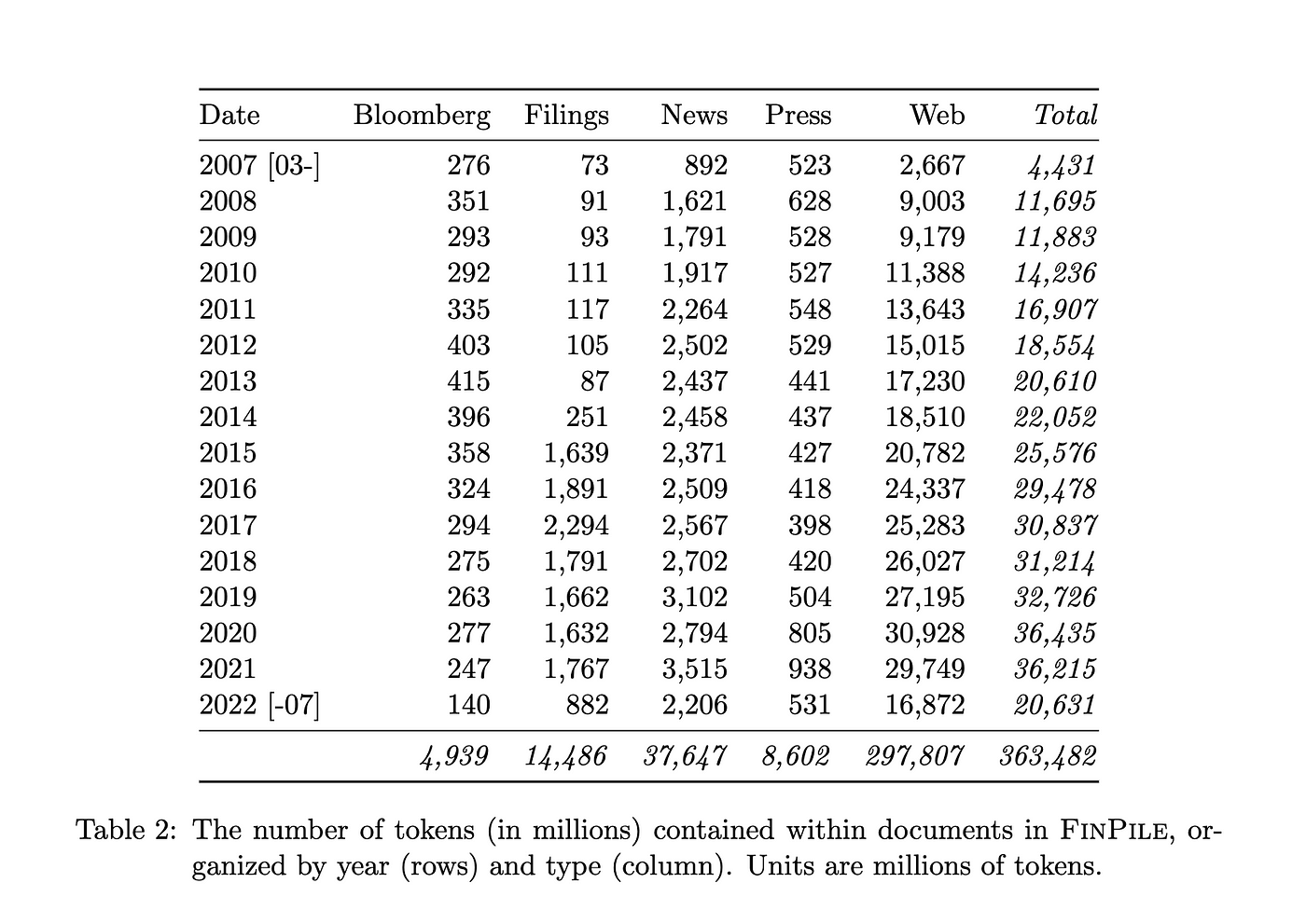
模型效果
使用上述语料库的一部分,Bloomberg团队训练了一个 500 亿参数的仅包含解码器的因果语言模型。由此产生的模型在现有的特定金融领域 NLP 基准、Bloomberg内部基准以及大量流行通用 NLP 任务基准上得到了验证。BloombergGPT 在金融任务上的表现明显优于现有的类似规模的开放模型,同时在一般 NLP 基准测试中的表现与其他模型持平或更好。
Bloomberg-GPT 的性能指标
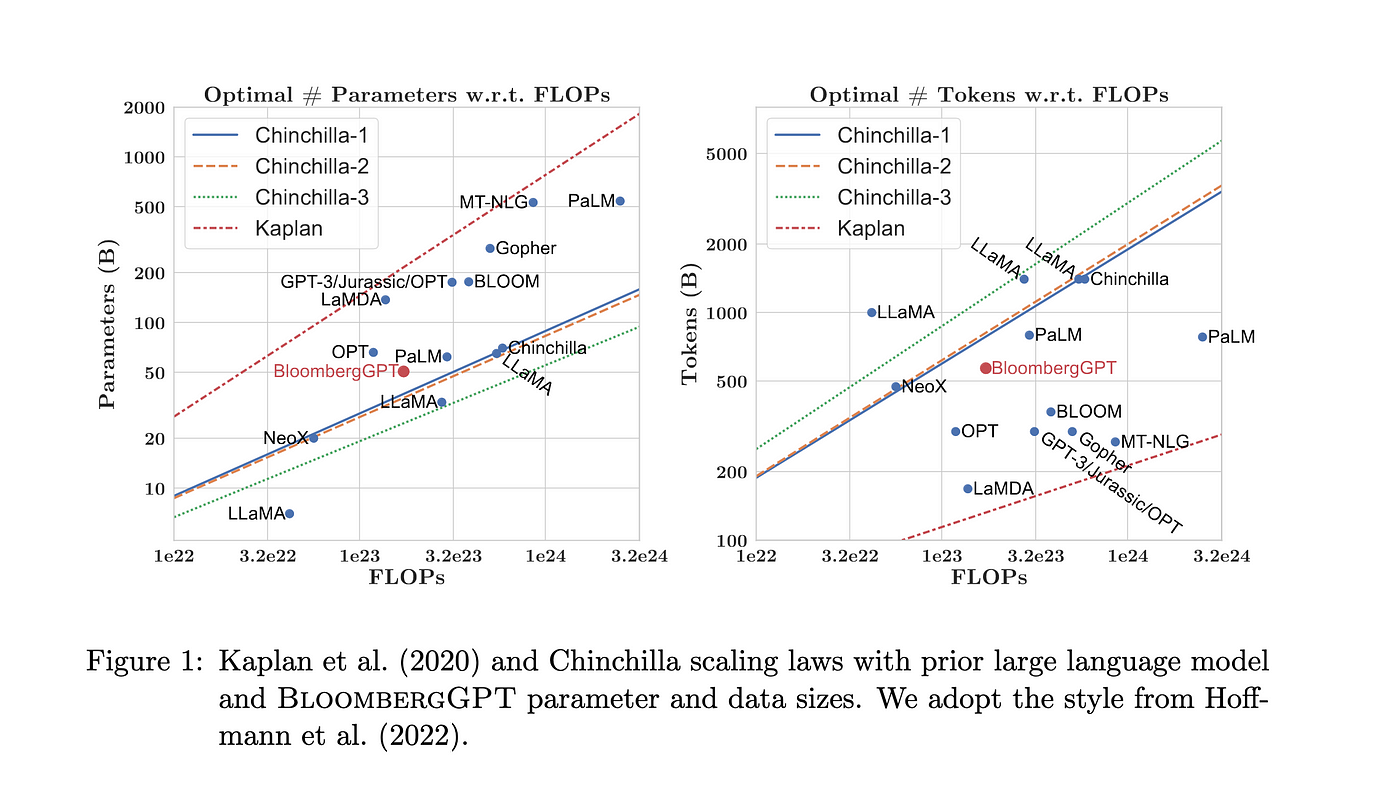
使用的评估基准
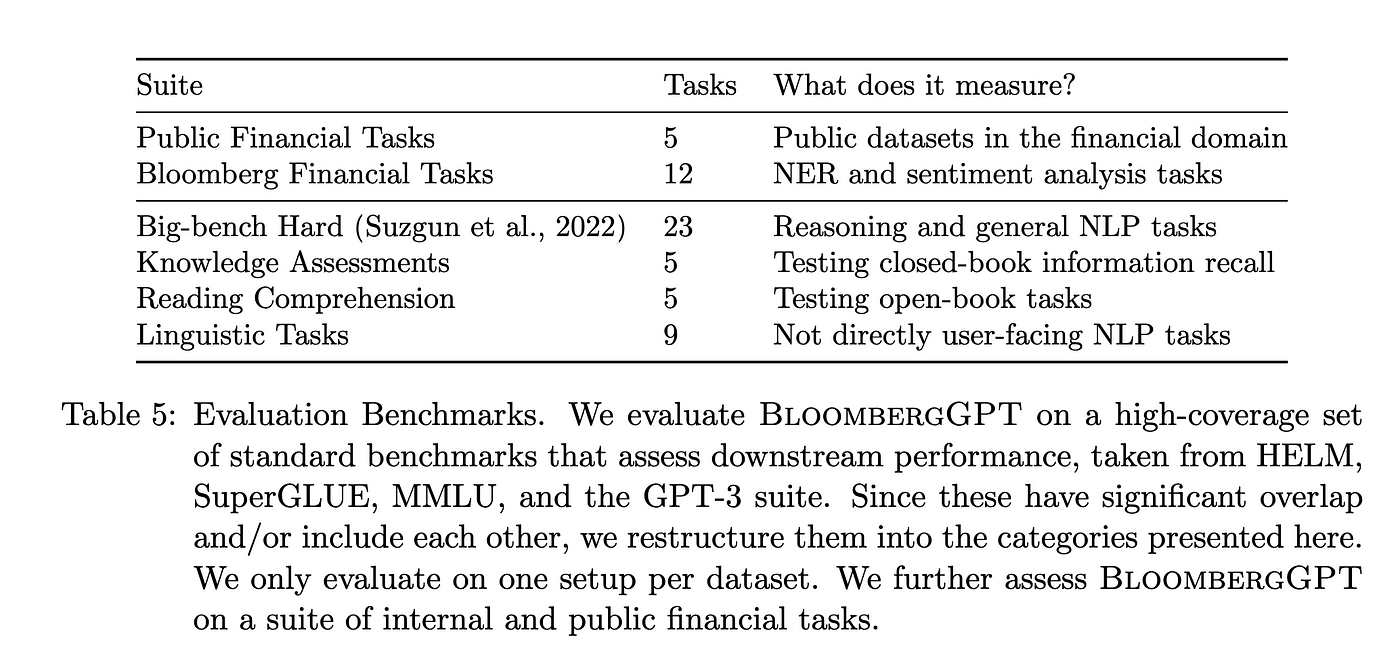
用于评估金融任务的模板
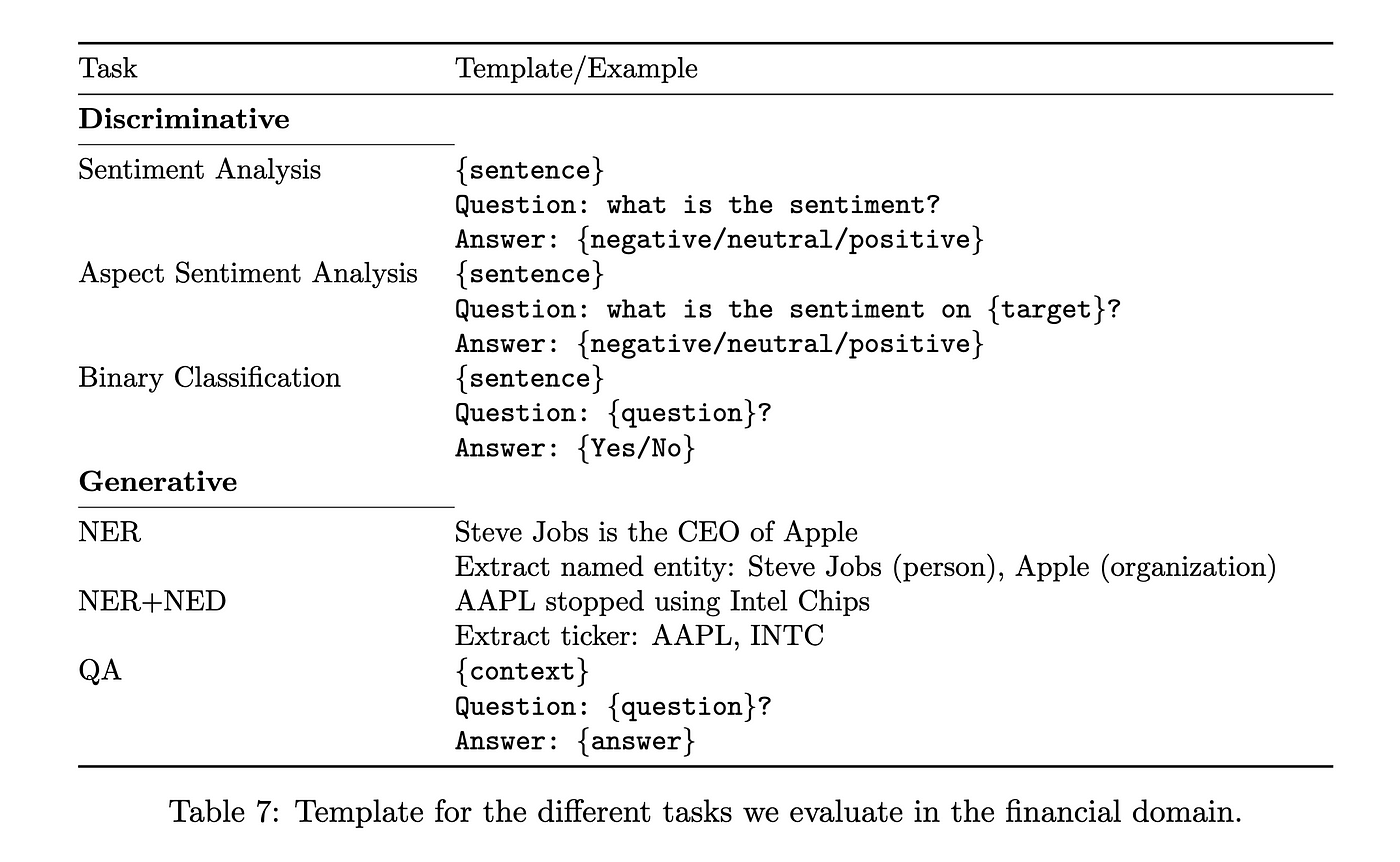
金融领域任务的表现(通用任务、NER 和情绪分析)
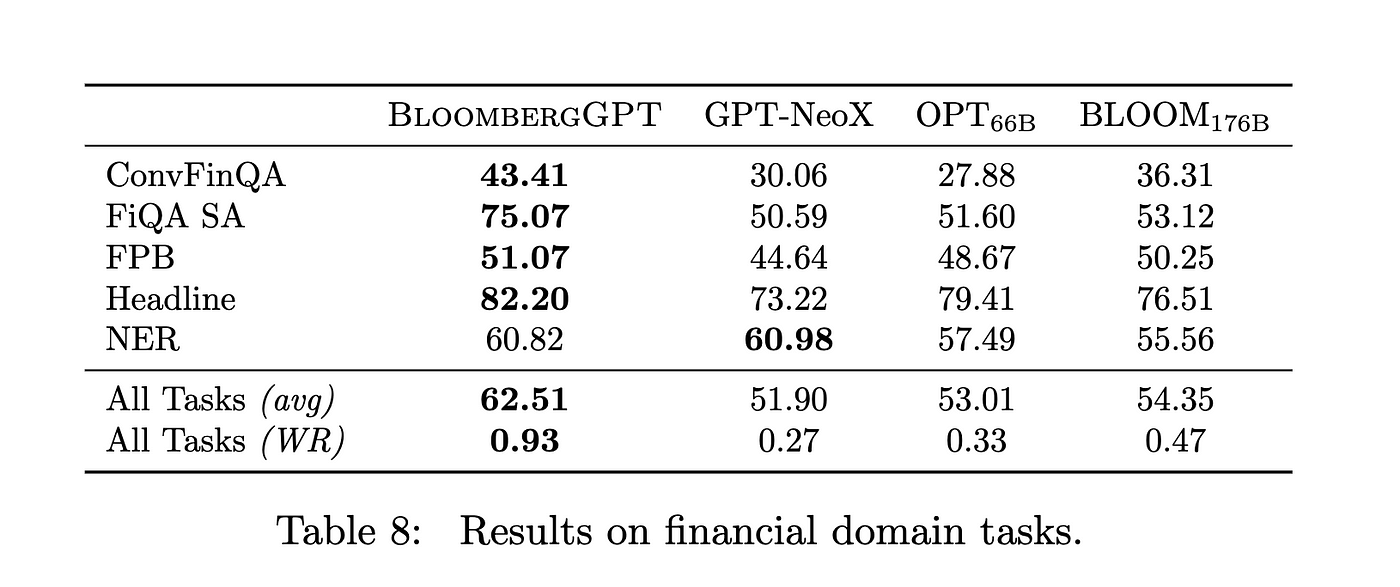
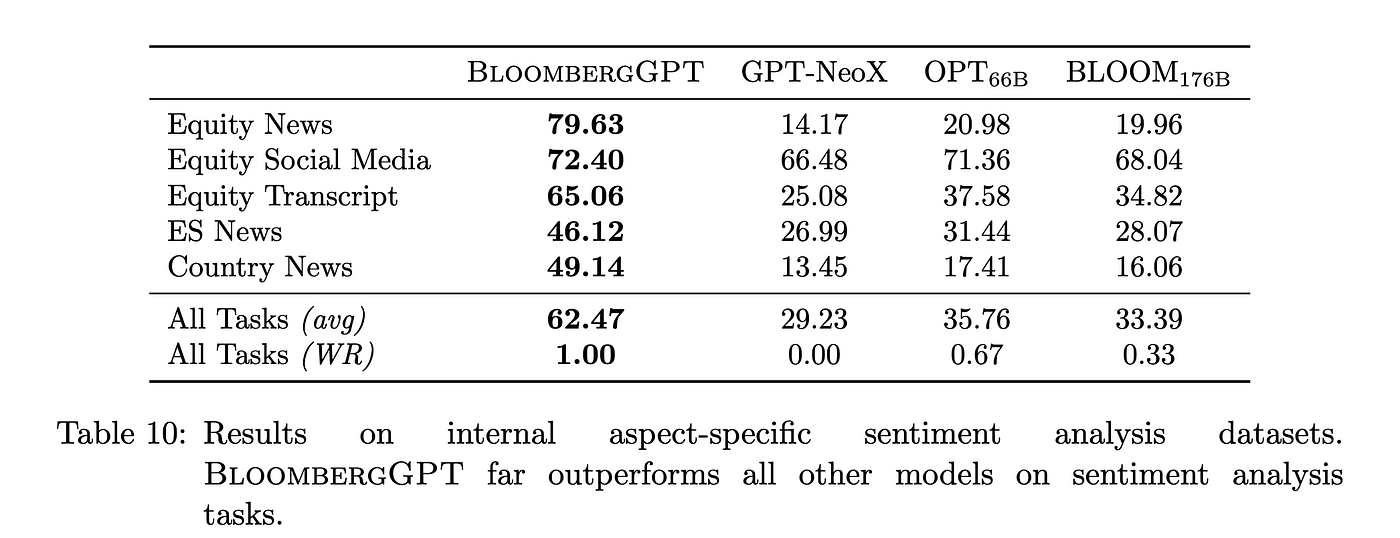
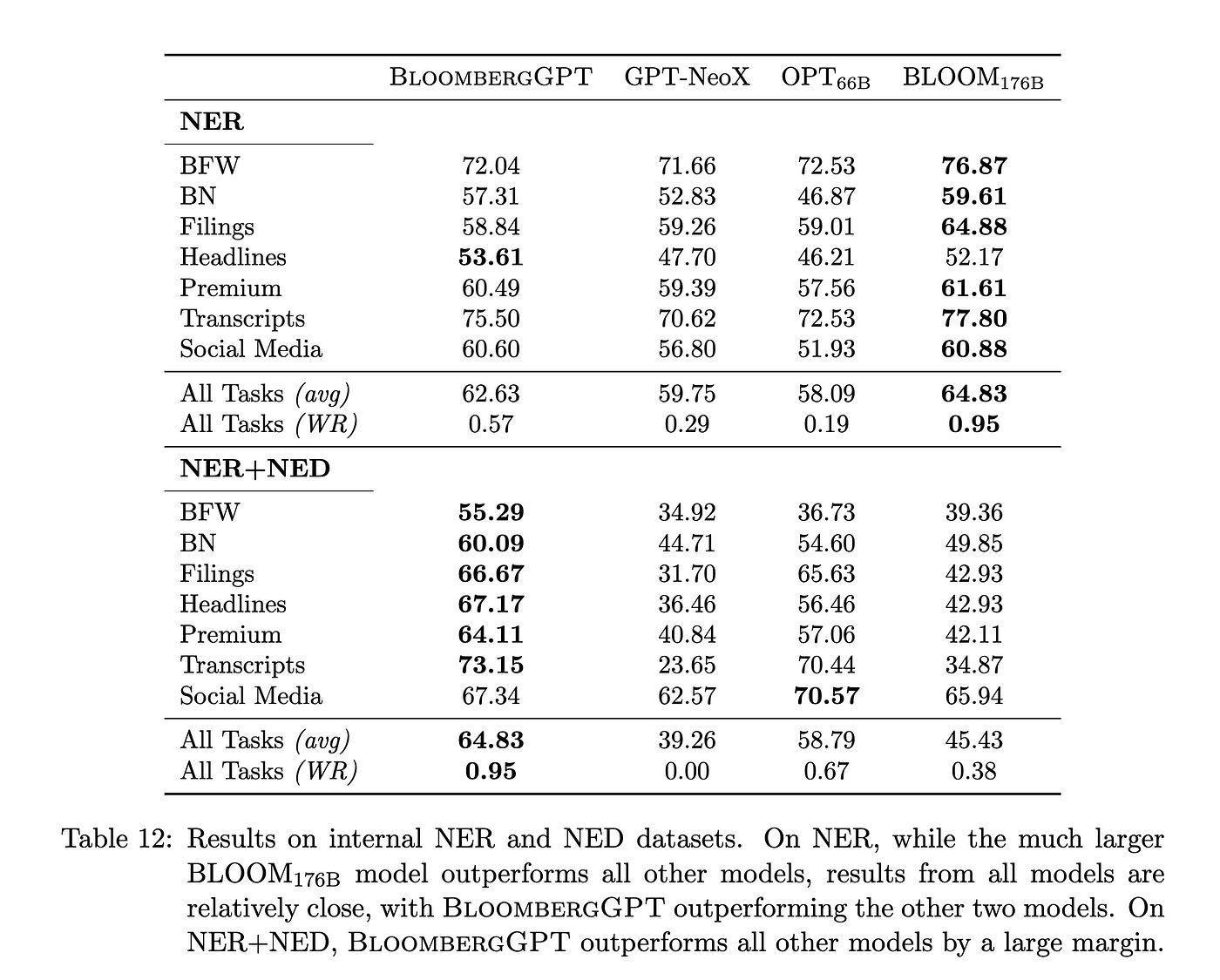
使用 BIG-Bench(3 shot)标准进行知识评估
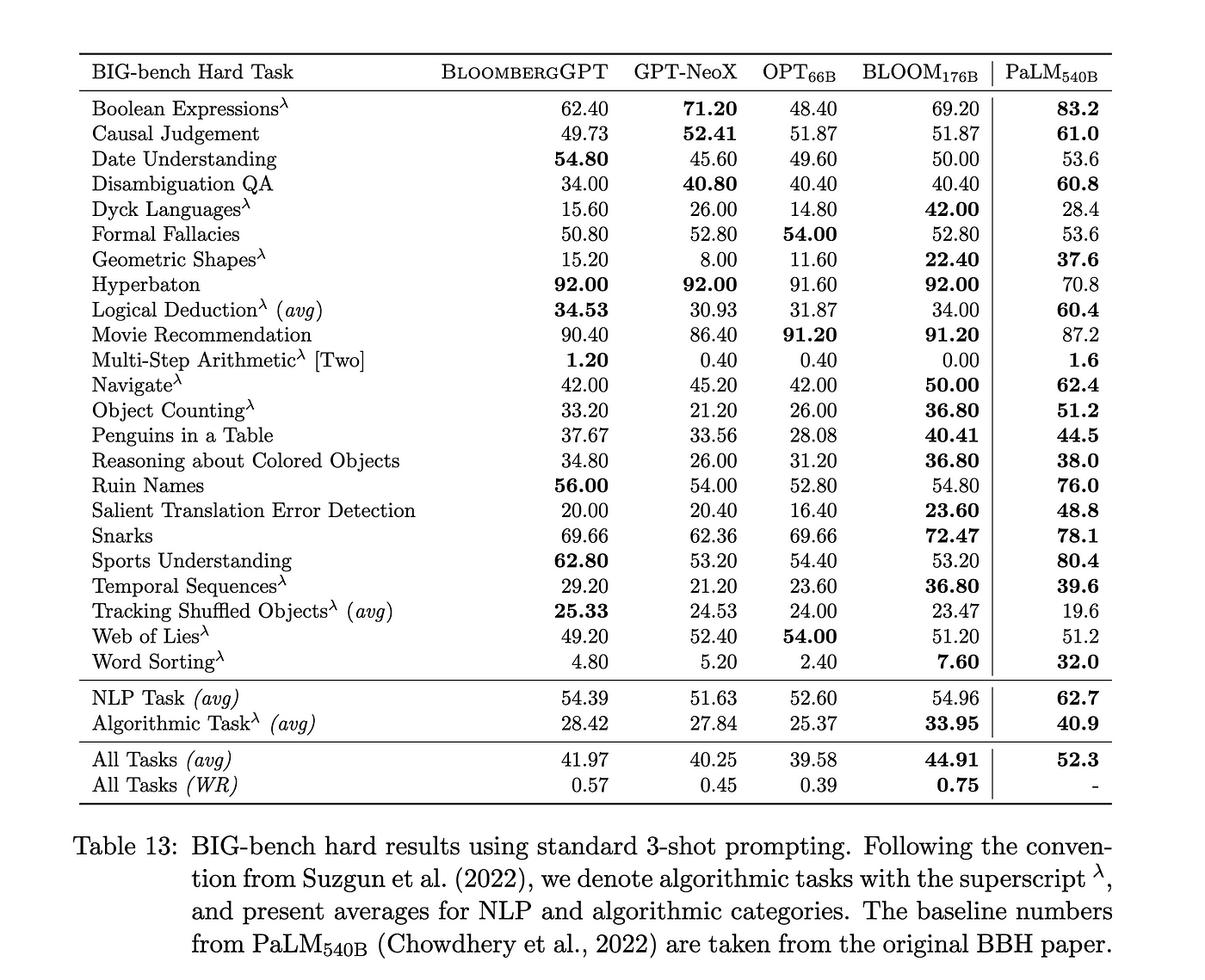
知识评估(1 shot 和 5 shot)
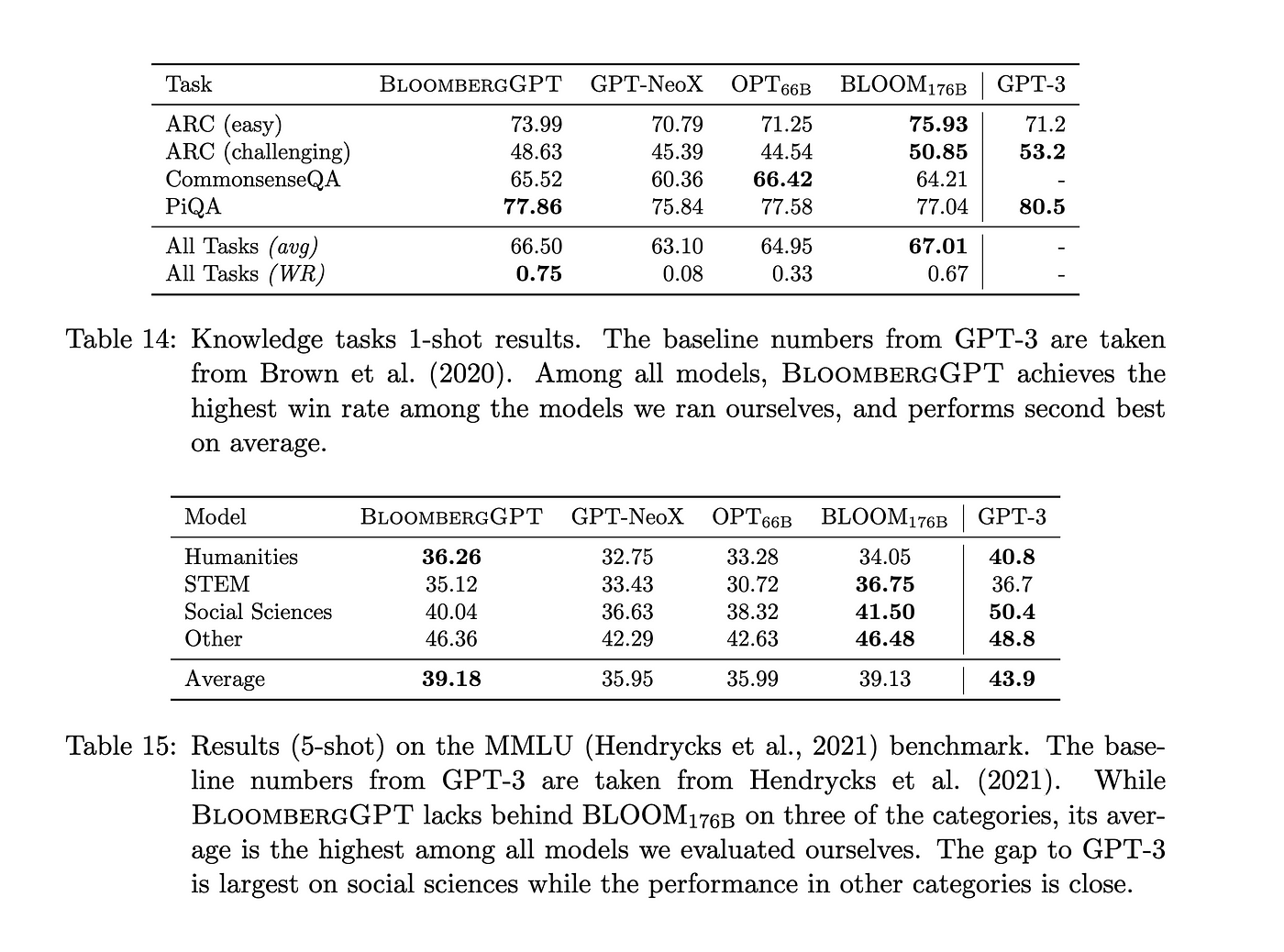
效果总结
在许多基准测试的数十项任务中,与其他数百亿参数的模型相比,BloombergGPT的表现是最好。此外,在某些情况下,BloombergGPT的性能可以媲美甚至超越更大规模(数千亿参数)的模型。虽然 BloombergGPT 的目标是成为金融领域的一流模型,并且包含了通用训练数据以支持特定领域的训练,但该模型在通用数据上的能力仍然超过类似规模的模型,并且在某些情况下,媲美甚至优于更大规模的模型。
总结
Bloomberg 的首席技术官 Shawn Edwards 看到了新模型的很多价值:“BloombergGPT 将使我们能够处理许多新型应用,同时它为每个应用提供了比自定义模型更高的开箱即用性能 ,从而换取更快的上市时间。”
Bloomberg 机器学习产品和研究团队负责人 Gideon Mann 解释说,机器学习和 NLP 模型的质量取决于你输入的数据。 得益于 Bloomberg 四十多年来精心策划收集的金融数据,他们能够精心创建一个庞大而干净的特定领域数据集,以训练最适合金融用例的 LLM。 他们很高兴使用 BloombergGPT 来改进现有的 NLP 工作流程,同时也想出新的方法来使用这种模型来服务他们的客户。
我个人认为这种模式可能会增加金融 LLM 的价值。 但是,必须注意到这只是同类领域中的第一个模型。 随着我们对金融数据的训练和调优,预计会有更多进步。 所以,我们可以把它看成是第一代硬件,用欣赏和测试的眼光去看待它,用于商用可能还为时过早。

