
- 1【Python】pip 使用方法详解_pythonpip怎么用
- 2Ubuntu22.04 lgh Ethercat master安装笔记_ubuntu igh
- 3MATLAB1:运行基础与入门练习
- 4深入了解SSM框架(案例(SSM+Jsp) + 详细分析 + 思维导图)
- 5基于Java+Vue+uniapp微信小程序火锅店点餐系统设计和实现_排队点餐系统设计
- 6指代消解or共指消解任务主要论文_bert-ner 指代消解
- 7FPGA应用实验设计(一)_四舍五入判别电路 fpga
- 8gitlab 吃内存。调整gitlab配置_gitlab 内存
- 9使用 YOLO 进行对象检测:保姆级动手教程_yolo怎么进行检测
- 10UI自动化控制微信发送文件【解决了一个无人回答的难题,Pywin32设置文件到剪切板】_flaui微信自动化demo_python flaui
使用Go从零实现一个Redis_go实现redis
赞
踩

最近翻阅了几本跟Redis相关的书籍,比如《Redis设计与实现 第二版》和钱老师的《Redis深度历险:核心原理与应用实践》,想着Redis的核心功能无非就是操作数据嘛,就像做一个Go语言版的Redis,不仅提升了对Redis源码的了解,也提高了Go语言的编码能力,说干就干。
代码地址:JaricY/miniRedis (github.com)
选用Go的原因是因为Go相对于C语言提供了更多的高级特性,例如并发编程和内存管理。由于Go语言具有良好的并发特性,可以方便的实现单线程的多协程操作,提高miniRedis的性能,并且Go语言提供了内存安全保障,可以有效避免内存溢出和数组越界等常见问题。
这个手写的Redis是基于Redis6.0.18版本进行实现的,我将其称为miniRedis。
此代码参考了大佬的godis。godis是一个非常值得学习的项目!!!
大佬的博客 :Finley (cnblogs.com)
大佬的源码 :github.com/hdt3213/god…
预计实现的功能包括:
- 支持String、List、Hash、Set、Sorted Set数据结构
- 支持AOF持久化
- 支持过期策略
- 支持Mult命令开启事务机制
数据结构
截至这篇文章发布时已完成和未完成的基本数据结构:
- sds数据类型
- dict字典
- list链表结构
- skiplist跳表
- sorted set和set类型
这些数据类型由于篇幅原因只放上结构体,具体绑定的方法请自行查看源码
1.sds数据类型
SDS(Simple Dynamic Strings)可谓是Redis中最为重要的数据结构之一了。Redis是一个内存数据库,因此它的数据存储方式对于性能和内存使用情况有着至关重要的影响。
SDS是一个高效的字符串存储数据结构,它在Redis中被广泛使用,可以作为键和值存储在内存中。SDS在存储字符串时具有良好的内存利用率,并且可以方便地实现字符串的拼接、分割等操作,进一步提高Redis的性能。
在Redis源码中,SDS的相关结构体定义在sds.c和sds.h。
(下图是sds.h文件中与sds相关的部分代码)
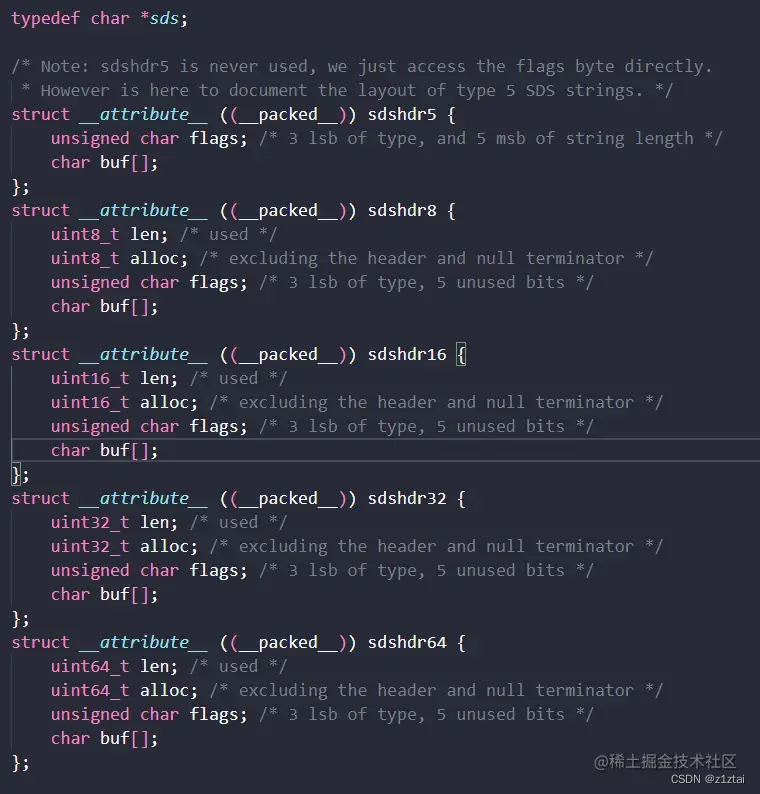
sdshdr是sds字符串对象的头部结构体,用于记录 sds 的长度和空余空间等信息
unsigned int len; 记录 buf 数组中已使用字节的数量
unsigned int free; 记录 buf 数组中未使用字节的数量
char buf[];字节数组,用于保存字符串值
char *sds 是一个指向buf首地址的指针
之所以使用SDS结构是因为SDS具有以下的优点:
- 动态分配:SDS可以动态分配内存,且能够根据字符串的长度实时调整所占用的内存,避免了固定大小的内存分配和浪费。
- 二进制安全:SDS采用类似于C字符串的方式保存数据,但与C字符串不同的是,它对二进制数据也具有良好的支持,避免了C字符串在处理二进制数据时出现的问题。
- 优化字符串操作:SDS的实现对字符串的操作进行了优化,如长度计算、字符串拼接、截取等操作都是O(1)复杂度,这些操作在C字符串中通常都是O(n)复杂度。
- 兼容C字符串:SDS的实现与C字符串的使用方式非常类似,这使得Redis可以在不影响现有C字符串操作的前提下,逐步替换C字符串为SDS。
在MiniRedis中,使用字符切片代替SDS的数据类型,因为切片类型同样可以动态的调整长度大小,同时也是二进制安全的。但是只能在切片末尾追加或者删除元素。
2.dict字典
在Redis中dict字典也非常重要,用于实现 Redis 的键值对存储以及实现 Redis 的哈希表数据结构。在 Redis 内部,大量使用了 dict 来支持诸如键值对存储、快速查找等功能。具体来说,dict 是一个基于哈希表实现的字典,用于存储键值对,可以支持 O(1) 的键值对查找和插入操作。
在Redis源码中,dict字典的内容主要在dict.c和dict.h中
(下图是dict.h中与dict相关的内容)
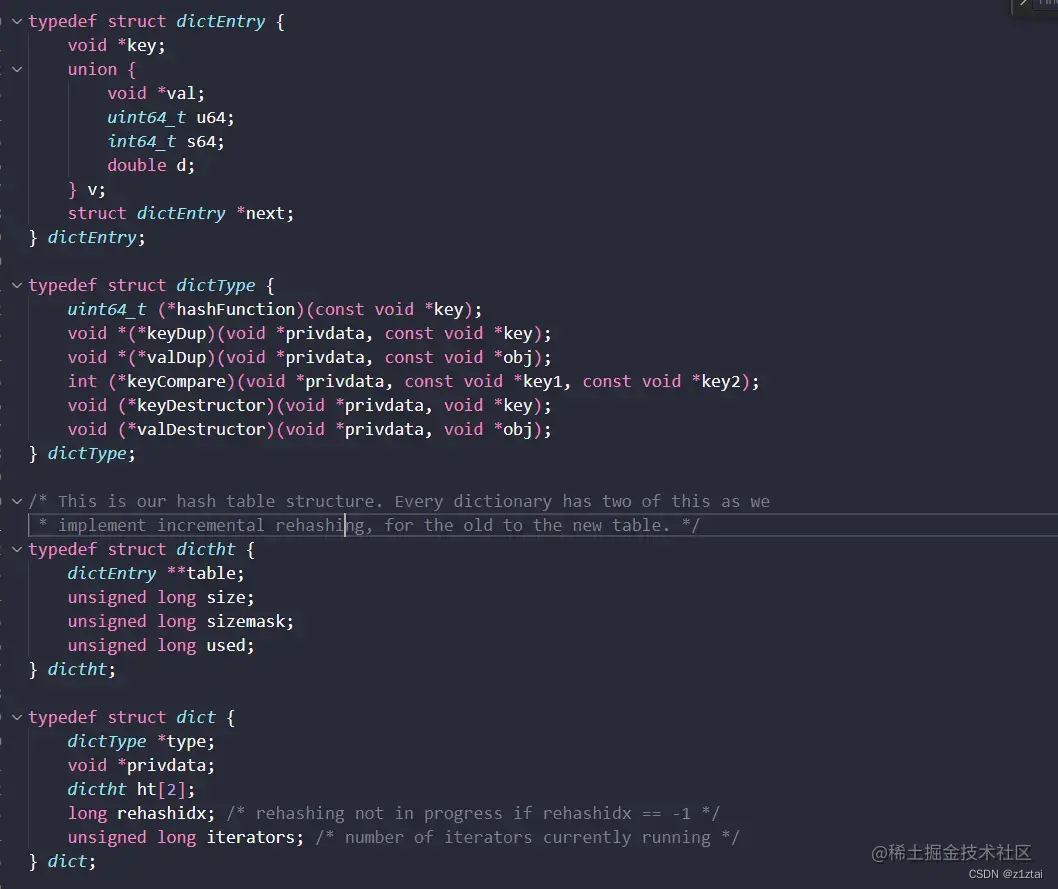
其中:
dictEntry: 表示字典中的一个键值对,包含 key 和 value 以及下一个键值对的指针。
dictType: 表示字典类型的一些方法,包括 hash 函数、键复制函数、值复制函数、键比较函数、键释放函数、值释放函数。
dict: 表示字典的结构体,包含字典类型、私有数据、两个哈希表(一个旧的哈希表,一个新的哈希表,用于 rehash 操作)、rehashidx(表示当前是否在进行 rehash 操作)、iterators(表示当前正在遍历的迭代器数量)等字段。
为什么要有两个HT?什么是Rehash?
当添加一个元素时,如果当前哈希表已经达到了负载因子 load_factor,就会触发扩容操作,即会新建一个大小是原来的两倍的哈希表,然后将原哈希表中的所有元素重新散列到新哈希表中,完成后将新哈希表作为原哈希表继续使用。这个过程称为 rehash。
在rehash的过程中,系统会逐步迁移元素,每次迁移一个元素,直到全部迁移完成。在 rehash 过程中,dict 结构体会同时持有两个哈希表,一个是正在被使用的哈希表,一个是正在 rehash 的哈希表,新的元素会被添加到正在被使用的哈希表中,而已存在于原哈希表中的元素则会被逐步地从原哈希表迁移到新哈希表中。迁移完成后,原哈希表被释放,新哈希表成为正在使用的哈希表。
Rehash会很消耗redis服务器的性能吗
如果每次都是需要等rehash完毕再进行操作的话肯定会很消耗服务器的性能。但是Redis采用了一种渐进式rehash。渐进式 rehash 操作通过将一次性执行的 rehash 操作分解成多个小步骤执行,每次有访问字典的时候就执行一次rehash的小步骤,这样就可以分散每个步骤对 Redis 服务器的影响,默认情况下每个小步骤是处理500个哈希槽
在进行渐进式rehash的过程中,新添加的键值对会同时存在于两个哈希表中。对于查询操作,会先在第一个哈希表中进行查找,如果没找到就会在第二个哈希表中查找。对于新增、修改、删除操作,会在两个哈希表中同时进行操作,以保证数据的一致性。
在miniRedis中,是使用了如下的结构体实现dict
(datastruct/dict/dict.go)
package dict // Consumer 是用于遍历Dict的函数,具体的由用户传入。如果返回了false则说明遍历中断 type Consumer func(key string, val interface{}) bool // Dict 这里定义的Dict是一个接口,定义了Dict需要实现的方法 type Dict interface { Get(key string) (val interface{}, exists bool) Len() int Put(key string, val interface{}) (result int) PutIfAbsent(key string, val interface{}) (result int) PutIfExists(key string, val interface{}) (result int) Remove(key string) (result int) ForEach(consumer Consumer) Keys() []string RandomKeys(limit int) []string RandomDistinctKeys(limit int) []string Clear() }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
(datastruct/dict/simple.go)
// SimpleDict 包装了一个map映射,不是线程安全的
type SimpleDict struct {
m map[string]interface{}
}
func MakeSimple() *SimpleDict {
return &SimpleDict{
m: make(map[string]interface{}),
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
(datastruct/dict/simple.go)
// ConcurrentDict 使用读写锁保证每个分片的安全
type ConcurrentDict struct {
table []*shard // 相当于是一个哈希表
count int32 // 表示一共有的键值对
shardCount int //字典分片的长度
}
type shard struct { // 字典分片,相当于是DictEntry
m map[string]interface{}
mutex sync.RWMutex // 保证了m的读写操作的并发性
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.List链表
List是一个有序的字符串链表,链表可以存储一个有序的字符串列表。它支持在链表的两端进行插入、删除、查找等操作,因此可以实现队列(先进先出)、栈(后进先出)等数据结构。在Redis中,list可以存储的数据类型不仅仅是字符串,还可以是数字、JSON等等。
在Redis源码中,List结构主要存储在adlist.h中
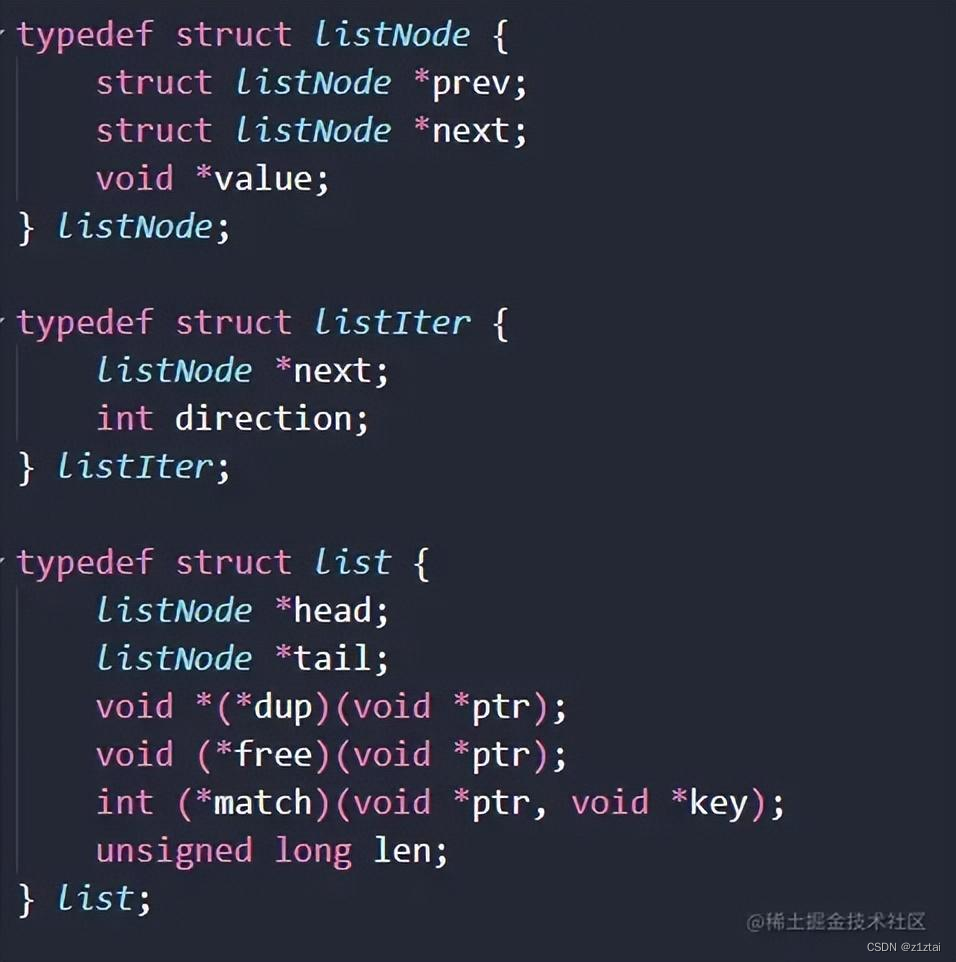
listNode:链表节点,包含指向前驱和后继节点的指针,以及存储值的指针。 listIter:链表迭代器,包含指向下一个节点的指针以及遍历方向(正向或反向)。 list:链表结构体,包含指向头节点和尾节点的指针、链表长度、复制、释放和匹配值的函数指针。
在miniRedis中链表的实现是这样的:
(datastruct/list/interface.go,定义了List接口)
package list // Expected 检查给定项是否与期望值一致 type Expected func(a interface{}) bool // Consumer 遍历链表. type Consumer func(i int, v interface{}) bool type List interface { Add(val interface{}) Get(index int) (val interface{}) Set(index int, val interface{}) Insert(index int, val interface{}) Remove(index int) (val interface{}) RemoveLast() (val interface{}) RemoveAllByVal(expected Expected) int RemoveByVal(expected Expected, count int) int ReverseRemoveByVal(expected Expected, count int) int Len() int ForEach(consumer Consumer) Contains(expected Expected) bool Range(start int, stop int) []interface{} }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
(datastruct/list/linked.go,实现了list的interface接口)
type LinkedList struct { first *node last *node size int } type node struct { val interface{} prev *node next *node } func Make(vals ...interface{}) *LinkedList { list := LinkedList{} for _, v := range vals { list.Add(v) } return &list }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
4.Set集合
在Redis中,Set集合是由一个无序的字符串元素组成的集合,它的底层实现使用了两种数据结构:哈希表和整数集合。当集合的元素较少或者全部都是整数时,会使用整数集合作为底层实现,而当集合的元素较多或者有一些元素是字符串时,会使用哈希表作为底层实现。
这是在server.h的源码中查看到的Set迭代器的定义:
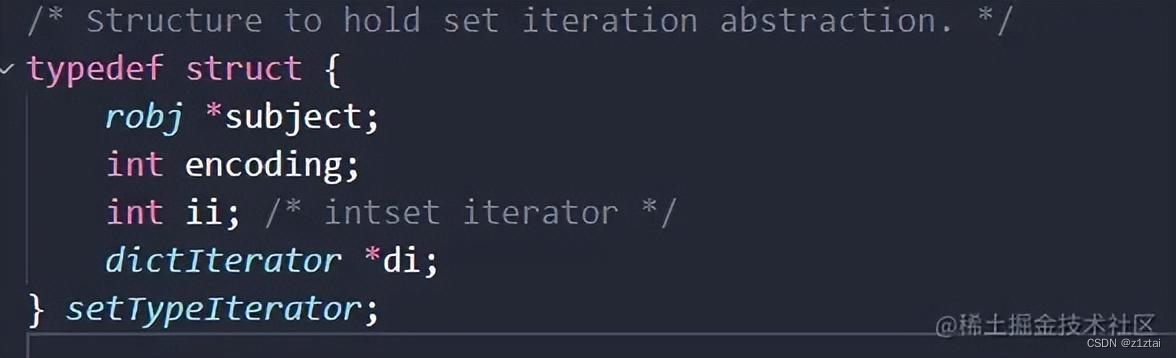
subject: 指向被迭代的 set 集合对象的指针 encoding: 表示被迭代的集合对象的编码方式,可以是 REDIS_ENCODING_INTSET 或 REDIS_ENCODING_HT,分别表示使用整数集合和哈希表两种数据结构来实现 set 集合。 ii: 表示整数集合迭代器的当前索引位置,当 encoding 为 REDIS_ENCODING_INTSET 时有效。 di: 指向哈希表迭代器的指针,当 encoding 为 REDIS_ENCODING_HT 时有效。
在MiniRedis中就只使用dict字典作为set集合的底层实现:
(datastruct/set/set.go)
// Set 是一组基于哈希表的元素
type Set struct {
dict dict.Dict
}
func Make(members ...string) *Set {
set := &Set{
dict: dict.MakeSimple(),
}
for _, member := range members {
set.Add(member)
}
return set
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5.skipList跳表
Redis中的跳表(Skip List)是一种基于有序链表的数据结构,它利用概率的思想在有序链表的基础上增加多级索引,以达到快速查找的目的。跳表可以用于实现有序集合,当集合中的元素比较多时,跳表的性能优于红黑树,但对于少量元素的情况,红黑树更加高效。
跳表由多层结构组成,每一层都是一个有序的链表,最底层的链表包含所有元素。每一层的链表都是前一层链表的一个子集,即一层链表中的元素在下一层链表中必定出现。
跳表中每个节点包含一个元素和若干个指向其他节点的指针,这些指针称为跳表的“跳跃指针”。节点的跳跃指针可以指向当前节点下面的节点,也可以指向下一层中对应的节点,这样可以在多层链表中快速地查找元素。
跳表通过随机化的方式建立索引,不仅可以保证查询效率,还能保证插入和删除操作的效率。在插入和删除元素时,跳表通过调整节点的跳跃指针来维护跳表的结构,使其保持有序性和平衡性。
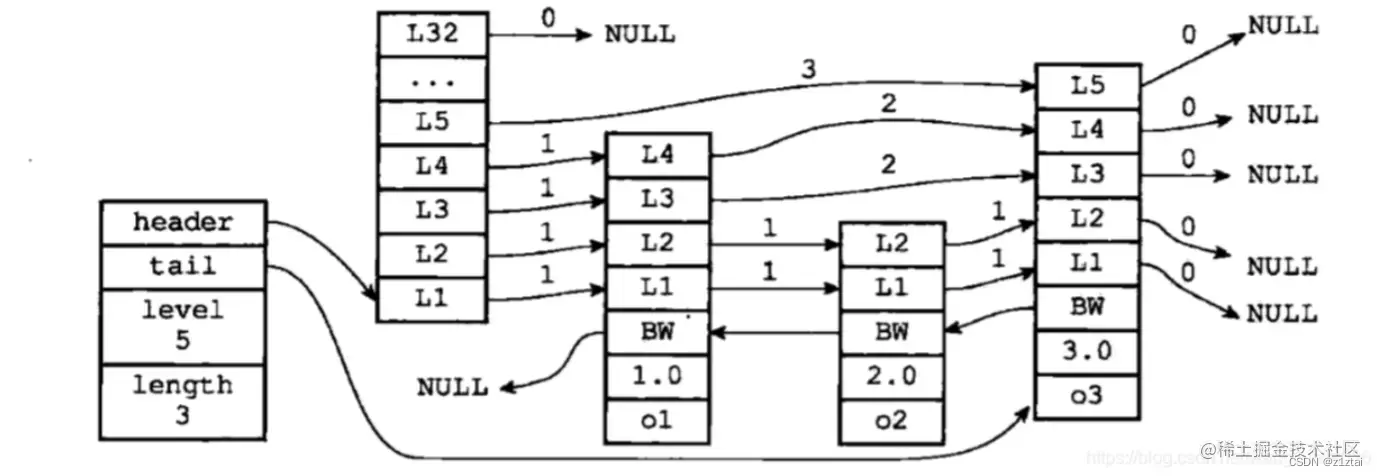
跳表通过在底层链表的基础上增加多级索引,可以提高查找的效率,实现快速查询。跳表中,每一层都是一个有序的链表,每个节点保存了指向下一层的指针。由于每一层都是有序的,因此可以通过比较当前节点的值与目标值的大小,来确定在哪一层继续查找。
通过在跳表中增加多级索引,可以避免遍历整个链表查找目标节点的情况,从而提高查找的效率。当需要查找一个节点时,可以从最高层开始查找,直到找到对应的节点为止。如果当前层的下一个节点大于目标值,就切换到下一层继续查找;如果当前层的下一个节点小于目标值,就继续向当前层的下一个节点查找,直到找到对应的节点。
通过跳表,可以实现快速查找、插入和删除,时间复杂度均为 O(log n)。这使得跳表成为了一种高效的数据结构,被广泛应用于各种领域,如:
- Redis中的有序集合zset
- LevelDB、RocksDB、HBase中Memtable
- ApacheLucene中的TermDictionary、Posting List
在Redis的源码中,skipList的相关信息在server.h中有提及
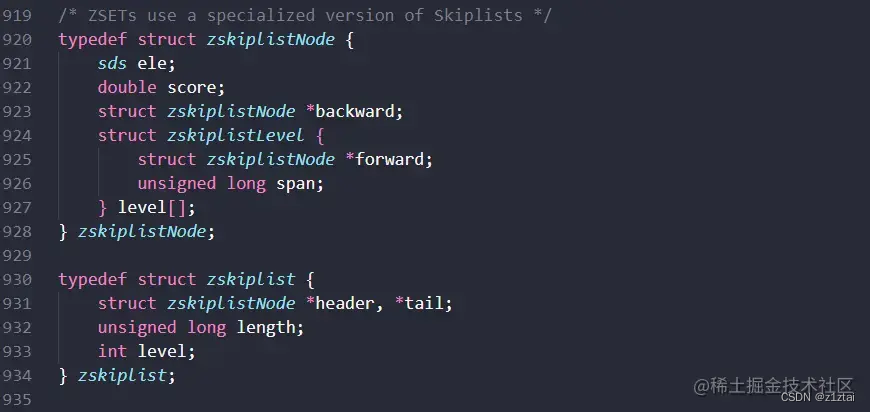
其中 zskiplistNode 表示跳表中的节点,包括了成员(ele)和分值(score)两个字段,还包括了一个 backward 指针和一个 level 数组,level 数组是一个伸缩性的数组,表示了每个节点在不同层级上的情况,这个 level 数组是根据概率分布函数随机生成的。
zskiplist 则是跳表的主体结构,包括了 header 和 tail 两个指针,表示跳表的头尾节点,length 表示跳表的长度,level 表示当前跳表中节点的最大层级。
在miniRedis中,是使用了如下的结构体来实现跳表结构:
(datastruct/sortedset/skiplist.go)
// Element 保存了元素的内容和分值 type Element struct { Member string Score float64 } // Level 表示层级 ,相当于是zskiplistLevel结构体 type Level struct { // 前驱指针 forward *node // 与前一个点的跨度 span int64 } // 表示一个结点,相当于是zskiplistNode type node struct { // 元素值和分数 Element // 后驱指针 backward *node level []*Level // level[0] 是最底层 } // 跳表结构 type skiplist struct { header *node tail *node // 具有的元素个数 length int64 // 最高层级 level int16 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
6.sorted set 有序集合
Redis中的Sorted Set(有序集合)是一个非常有用的数据结构,它类似于Set(集合),但是每个元素都会关联一个分数(score),根据这个分数对元素进行排序,使得集合中的元素是有序的。Sorted Set中每个元素的值是唯一的,但分数可以重复。
Sorted Set支持多种操作,包括添加、删除、查找、遍历和范围查询等。使用Sorted Set可以轻松地实现一些常见的问题,比如排行榜、计数器、最高分查询等。内部实现是基于跳跃表(Skip List)的数据结构,这种数据结构可以快速地查找、插入和删除元素,同时也能够维护元素的顺序。
Redis的有序集合是通过跳跃表(skiplist)和哈希表两种数据结构实现的。
在Redis源码中,sorted set是使用zset结构体表示的,定义在server.h中

在MiniRedis中使用如下的结构体来表示sorted set
(datastruct/sortedset/sortedset.go)
type SortedSet struct {
dict map[string]*Element
skiplist *skiplist
}
func Make() *SortedSet {
return &SortedSet{
dict: make(map[string]*Element),
skiplist: makeSkiplist(),
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在Redis6中,网络模型从单线程优化成了多线程。
多线程的网络模型是指在处理客户端请求时,使用多个线程来并发地处理多个连接,从而提高系统的并发处理能力。相比于单线程模型,多线程模型可以同时处理多个请求,提高了并发处理能力。
在单线程模型中,所有的请求都必须在同一个线程中处理,一个连接上的请求必须等待前一个请求处理完成后才能处理,无法并行处理多个连接上的请求,因此在高并发的场景下容易出现性能瓶颈。而在多线程模型中,每个线程都可以独立处理一个连接上的请求,不会因为前一个请求的处理时间过长而影响其他连接的处理,因此可以有效提高系统的并发处理能力。但是多线程模型也存在一些问题,比如线程切换开销、线程安全问题等,需要通过一些技术手段来解决。
请注意,redis6的多线程是指网络多线程,也就是可以同时处理多个请求,但是命令在执行的时候仍然是单线程执行的。Redis6的网络模型主要在ae.h,ae.c,networking.c文件中
由于篇幅原因,这里就不贴源码了,有兴趣的小伙伴可以直接查看Redis源码中对应的文件。
在ae.c文件中,主要实现了多线程的事件循环和事件处理机制:
- aeCreateEventLoop:创建事件循环。
- aeCreateFileEvent:创建文件事件。
- aeDeleteFileEvent:删除文件事件。
- aeGetFileEvents:获取文件事件。
- aeCreateTimeEvent:创建时间事件。
- aeDeleteTimeEvent:删除时间事件。
- aeProcessEvents:处理事件。
- aeWait:等待事件。
- aeCreateThread:创建线程。
- aeGetApiName:获取事件处理器的名字。
在networking.c文件中主要实现了多线程的网络处理:
- createClient:创建客户端连接。
- freeClient:释放客户端连接。
- acceptTcpHandler:处理新的 TCP 连接。
- readQueryFromClient:从客户端读取请求。
- addReply:向客户端发送响应。
- sendReplyToClient:向客户端发送响应。
在MiniRedis中使用如下方式实现TCP服务器
Handler
Handler用于处理TCP服务,其中包括了Handle方法和Close方法。
(interface/tcp/handler.go)
// HandleFunc 代表处理方法,ctx表示请求携带的相关数据,conn表示一个网络连接,用于客户端和服务端之间传递数据
type HandleFunc func(ctx context.Context, conn net.Conn)
// Handler 用于处理tcp的服务
type Handler interface {
Handle(ctx context.Context, conn net.Conn)
Close() error
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
ListenAndServe
- 在Go语言中,可以使用net.Listen创建一个监听器,并且使用监听器接收连接对象
- 使用开销更小的协程处理客户端的连接,实现了Redis6中的多线程并发执行,但只是异步处理连接,在操作数据库的时候仍然是同步进行的,保证了Redis命令执行的原子性。
- 如果在执行请求的时候出现了错误,需要对错误进行记录,并且执行关闭监听器、连接等收尾工作,这称之为优雅关闭,在Go中使用channel实现了主线程和协程之间的信息交互从而记录了错误信息并且可以进行处理
(tcp/server.go)
// Config 保存了创建TCP连接的配置信息
type Config struct {
Address string `yaml:"address"`
MaxConnect uint32 `yaml:"max-connect"`
Timeout time.Duration `yaml:"timeout"`
}
// ClientCounter 用于记录连接到miniRedis的客户端数量
var ClientCounter int
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
// ListenAndServeWithSignal 用于监听和处理请求,并且携带信号量用于处理异常,例如请求关闭等情况 func ListenAndServeWithSignal(cfg *Config, handler tcp.Handler) error { // 创建一个管道,记录请求关闭信号 closeChan := make(chan struct{}) // 创建一个管道,接受操作系统发送的信号 sigCh := make(chan os.Signal) signal.Notify(sigCh, syscall.SIGHUP, syscall.SIGQUIT, syscall.SIGTERM, syscall.SIGINT) // 开启一个新的协程等待操作系统的信号 go func() { sig := <-sigCh switch sig { case syscall.SIGHUP, syscall.SIGQUIT, syscall.SIGTERM, syscall.SIGINT: closeChan <- struct{}{} } }() //开始监听,返回一个TCP监听器 listener, err := net.Listen("tcp", cfg.Address) if err != nil { return err } logger.Info(fmt.Sprintf("bind: %s, start listening...", cfg.Address)) ListenAndServe(listener, handler, closeChan) return nil }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
// ListenAndServe 绑定端口并处理请求,持续阻塞直到关闭 func ListenAndServe(listener net.Listener, handler tcp.Handler, closeChan <-chan struct{}) { errCh := make(chan error, 1) defer close(errCh) // 开启一个协程处理关闭和错误信息 go func() { select { // 阻塞接受 case <-closeChan: logger.Info("get exit signal") case er := <-errCh: logger.Info(fmt.Sprintf("accept error: %s", er.Error())) } logger.Info("shutting down...") _ = listener.Close() // 关闭监听器 _ = handler.Close() // 关闭连接 }() ctx := context.Background() // 获取请求上下文 var waitDone sync.WaitGroup // 用于等待所有的协程执行结束后才执行 listener.Close() 和 handler.Close() for { // 如果接受错误则写入到管道中 conn, err := listener.Accept() if err != nil { errCh <- err break } logger.Info("accept link") ClientCounter++ waitDone.Add(1) //异步执行 go func() { defer func() { waitDone.Done() ClientCounter-- }() //handle是对整个连接的 handler.Handle(ctx, conn) }() } waitDone.Wait() }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44

