
- 1创建和使用DirectX接口(并再次理解COM对象)_c#使用 com directx2d
- 2数据库之事务隔离级别详解_事务的隔离级别
- 3基于二阶锥优化电气综合能源系统优化调度研究 考虑气电联合需求响应的气电综合能源配网系统协调优化运行_考虑气网管存的电-气联合优化调度研究
- 4一文搞懂LLM大模型!LLM从入门到精通万字长文(2024.7月最新)_llm入门
- 5盘点目前有关数字人的开源项目_数字人开源项目
- 6Transformer模型代码(详细注释,适合新手)_transformers建模代码
- 7Git入门(一)之Windows系统下gitee仓库--本地仓库--修改仓库--gitee仓库?_gitee将本地仓库和远程仓库地址修改
- 8Hadoop2.7.6在Windows7单机部署_hadoop2.7.7gitub补丁下载windows
- 9You are applying Flutter‘s app_plugin_loader Gradle plugin imperatively using the apply script metho_you are applying flutter's main gradle plugin impe
- 10推荐开源项目:YOLO_SlowFast — 实时视频对象检测的新里程碑
PS与PL互联与SCU以及PG082_ps和pl
赞
踩
参考(照抄+自己加点):
ZYNQ PS-PL数据交互方式总结(好文)_axi emc-CSDN博客
zynq_process是一个用于方便操作PS和PL通信的GUI。
整体框图
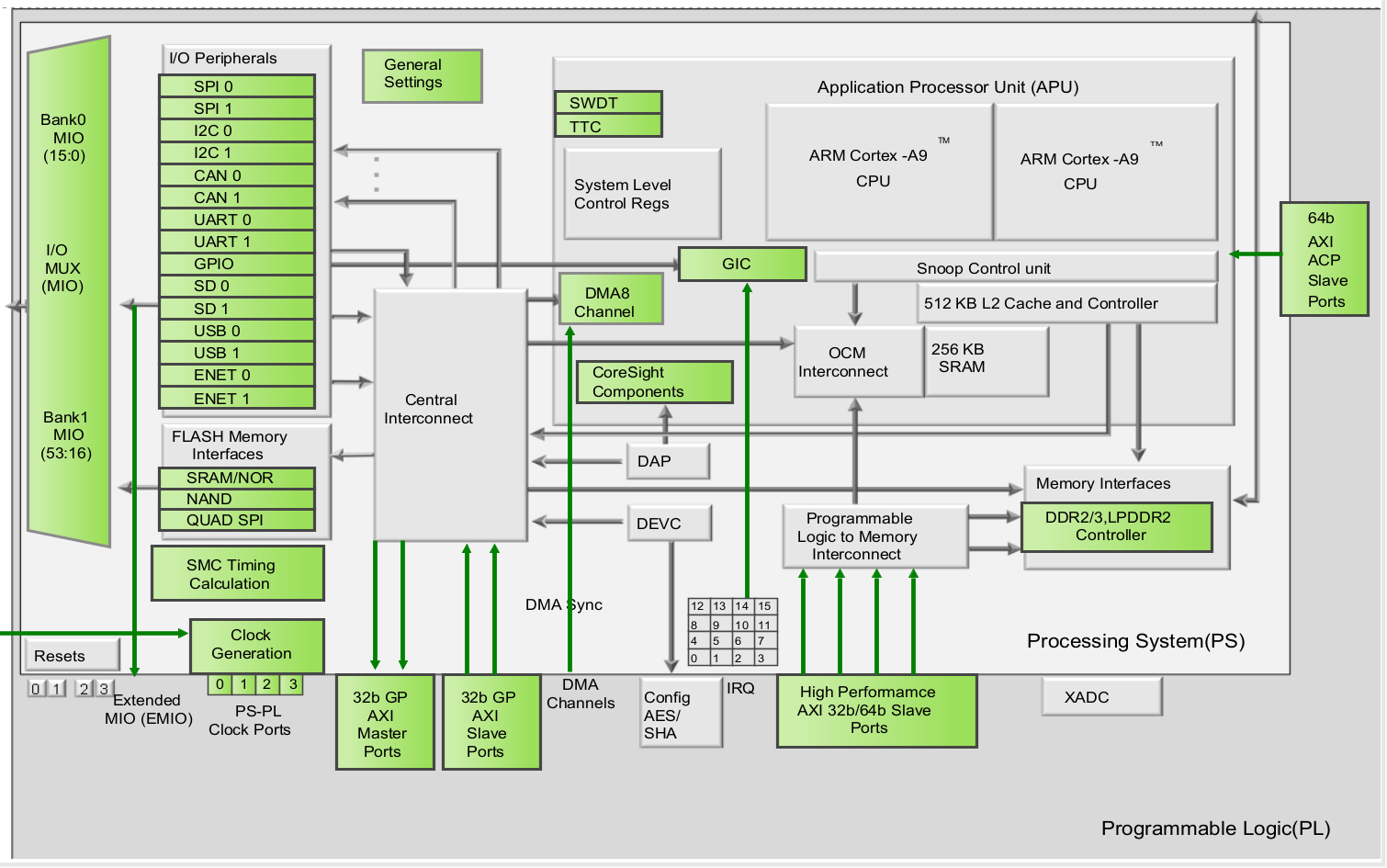

MIO分配在bank0和bank1直接与PS部分相连,EMIO分配在bank2直接和PL部分相连。除了bank1是22-bit之外,其他的bank都是32-bit。所以MIO有53个引脚可供我们使用,而EMIO有64个引脚可供我们使用。
使用EMIO的好处就,当MIO不够用时,PS可以通过驱动EMIO控制PL部分的引脚,接下来就来详细介绍下EMIO的使用。
EMIO的使用和MIO的使用其实是非常相似的。区别在于,EMIO的使用相当于,是一个PS + PL的结合使用的例子。所以,EMIO需要分配引脚,以及编译综合生成bit文件。
MIO与EMIO概念
MIO:多功能IO接口,属于Zynq的PS部分,在芯片外部有54个引脚。这些引脚可以用在GPIO、SPI、UART、TIMER、Ethernet、USB等功能上,每个引脚都同时具有多种功能,故叫多功能。
EMIO:扩展MIO,依然属于Zynq的PS部分,只是连接到了PL上,再从PL的引脚连到芯片外面实现数据输入输出。
PS 和外部设备之间的连接主要是通过复用的输入/输出(Multiplexed Input/Output,MIO)来实现的。 PS的54个MIO引脚可以用于连接不同的外设接口,如图 1.3.13中的MIO14和MIO15,既可以配置成UART0 的引脚接口,也可以配置成 I2C0 或 CAN0 的引脚接口。最终所选择的配置需要与开发板的原理图相 对应。
zynq_process预设配置:
PS复位一个,GP0配置一个,输出时钟一个。
编辑好硬件设备以后~:
参考:
Vivado IP核Global 和 out of context per IP两种综合方式区别-CSDN博客
在用vivado 生成IP核时,有两种综合方式:Global和out of context per IP。Global模式可以理解为全局综合,当整个工程中的某个文件修改综合时,之前生成的IP核将被重新综合,而out of context per IP模式被称为OOC模式,在生成综合IP核时,已经将IP核综合为网表文件和IP调用文件,在后续整个工程实现时,不再对IP核的源文件进行综合实现,而是直接将网表与其他模块一起实现。个人理解有些像软件工程编译时的增量编译,因此IP采用OOC模式可以大大解决整个工程的综合时间,毕竟FPGA目前的综合时间还是太漫长了。
我的话:Global模式在自己写IP加入BD设计的时候用,因为对接的时候Global相比out of context per IP不会自行优化,不会自动删去接口。
生成的文件:
Create a HDL wrapper-生成HDL顶层文件
Xilinx Bit文件格式详解-腾讯云开发者社区-腾讯云 (tencent.com)
FPGA中可执行文件:bit/bin/mcs/elf-腾讯云开发者社区-腾讯云 (tencent.com)
XSA文件和HDF文件:
hdf: Hardware Description File,Vivado 2019.1及更早版本导出的硬件描述文件,给xilinx sdk使用。(在 Export Hardware 的过程中,工具会将硬件以一个 ZIP 压缩文件的形式导出到该工作空间中。该文件包含了我们前面所搭建的硬件平台的配置信息,其后缀名.hdf 的含义为 ―Hardware Definition File‖,即硬件定义文件)
xsa: Xilinx Shell Archive,Vivado 2019.2及后续版本导出的硬件文件,.xsa=.bit+hdf.
vitis与SDK
Vitis平台使用从这六点变化开始 (e-elements.com)
一致性控制单元 (Snoop Control Unit,SCU)
APU 主要是由两个 ARM 处理核组成的,每个都 关联了一些可计算的单元:
一个 NEONTM 媒体处理引擎(Media Processing Engine, MPE)
和浮点单元 (Floating Point Unit,FPU);
一个内存管理单元 (Memory Management Unit,MMU);
和一个一级 cache 存储器(分为指令和数据两个部分)。
APU 里还有一个二级 cache 存储器,
再往下还有片上存储器 (On Chip Memory,OCM)。
最后,由一个一致性控制单元 (Snoop Control Unit,SCU)
在 ARM 核和二 级 cache 及 OCM 存储器之间形成了桥连接,
这个单元还部分负责与 PL 对接,图中没有标出这个接口。
一致性 (窥视)控制单元 (SCU)从事的是一些和两个处理器与一二级 cache 存储器之间的接口相关的任务 (“ 窥视 ” 是保证 cache 一致性的几种机制之一, 也就是管理在共享的 cache 资源上的数据的一致性 [13])。SCU 负责维持两个处理 器的数据 cache 存储器 —— 就是图 2.3 上标着 L1(D) 的 —— 和共享的二级 cache存储器之间的存储一致性。它还初始化并控制对二级 cache 的访问,在必要的时候 仲裁从两个核来的访问请求 [8][33]。SCU 还要通过加速器一致端口(Accelerator Coherency Port,ACP)来管理在 PS 和 PL 之间的访问会话。
为了保证实时性,中断的数据便是由SCU来访问GIC得到的。

Cache
Cache 是一小块位于 CPU 和主存储器之间的存储器。它具有比主存储器低的访 问时间,而且不能通过系统总线访问。cache 用来保存被处理器从主存储器中频繁 访问的数据。因此使用在 cache 中的数据就比只在主存储器中的数据快很多。
通常一个处理器读数据的速度比系统的主存储器要快很多,因此处理器的速度 是受到存储器的速度的制约的。通过在系统中引入 cache 存储器 —— cache 中存 放了频繁访问的数据,能以比主存储器更高的速率读取 —— 处理器就不再受到主 存储器速度的限制了。这导致了数据访问效率的提升。不过,在 cache 失配时,处 理器的速度还是受限的 —— 这个时候,处理器要读写的数据不在 cache 中。这样 就要读写主存储器中的数据,从而提高了访问延迟。

可编程IO
管理存储控制器和其他外设之间的数据移动的手段之一,是让所有的数据传输 都通过处理器。这样的存储传输叫做可编程 I/O,它让系统能以最少的资源来处理 存储传输。这个方法需要外设和处理器位于同一个总线上,处理器成为所有外设和 存储器通信的中心点。如果外设和存储器之间的存储传输请求的数量很大,处理器 就会花费大量时间来做存储传输,那么做其他计算的时间就少了 [2]。
如果系统在可编程逻辑中实现大多数功能,那么可编程 I/O 是能用最少的资源 管理存储事务的有效方法。不过,如果处理器需要从事大量其他计算,其他的方法 也许更好 [2]。
DMA直接存储器访问
降低处理器负担的一种办法是用直接存储器访问 (Direct Memory Access, DMA)来做存储传输。用了这个方法,处理器向 DMA 控制器发出一个存储传输请求, 然后 DMA 控制器将来做这个存储事务。这样当 DMA 控制器在做传输的时候,处理器 就可以从事其他任务了。在这种情况下,DMA 控制器既是总线主机也是总线从机。 作为主机,DMA 控制器要和存储控制器通信,也会要请求总线仲裁。作为从机,DMA 控制器回应从总线主机 (大多数时候就是处理器)而来的请求,建立起存储传输。 为了发起传输事务,DMA 控制器必须得到以下数据 [2]:


DMA 存储传输的过程是:
1. 为了配置想要用 DMA 来传输数据到存储器的那个设备,处理器发出一个 DMA 命令然后禁止所有的 DMA 中断。
2. DMA 控制器把数据从外设传输到存储器,而让 CPU 腾出手来做其他计算。
3. 数据传输完成后,向 CPU 发出一个中断来通知它 DMA 传输可以关闭了。
总线带宽
总线带宽是总线上一定的单位时间内可以传输的总的数据量。
总线带宽的值取 决于两个因素:
• 总线数据宽度 — 这是总线同时传输数据的物理的线路的数量。32 位独立数 据线的总线可以同时传输 32 位的数据。
• 总线频率 — 这是总线操作的速度。这指的是每秒总线可以发送 / 接收的数据 位的数量,是以赫兹 (Hz)为单位的。



互联
在 PS 里的互联提供了主机和从机之间读、写和响应事务的通信,它由多个开关 用 AXI 点对点通道来连接系统资源。作为 ARM AMBA 总线系列的一部分,这个互联实 现了大阵列的互联通信容量,以及在之上的服务质量 (Quality-of-Service, QoS)、调试和测试监视。多种重要的事务由这个互联所 . 管理,而它就是被设计用 来为 ARM CPU 提供低延迟链路的。从 PL 主机控制的角度来说,这个互联能实现高吞 吐率和 cache 一致性数据通路 [4]。

PS-PL AXI 接口
• AXI_ACP,用于 PL 的一个 cache 一致性主机端口
• AXI_HP,用于 PL 的四个高性能 / 大带宽主机端口
• AXI_GP,四个通用端口,两个主机端口和两个从机端口
Zynq 里的 PS 和 PL 部分之间的主要连接形式是 AXI 接口,它在芯片的这两个部 分之间实现了高带宽、低延迟的连接。在 PS 侧的每个 AXI 接口包括多个 AXI 通道, 九个 PL 接口是用了上千个信号来实现的。

AXI_HP 接口:
遵循Axi3协议,但通过转接连接
Axi3只支持突发程度16
有四个 AXI_HP 接口来实现从 PL 总线主机到 OCM 和 DDR 存储器的高带宽数据通路。每个接口里有两个做读写通信的 FIFO 缓冲器。连接 PL 到存储器的互联把高速 AXI_HP 端口连接到两个 DDR 存储器端口或 OCM 上。在某些 Xilinx 文档中,AXI_HP 接口也被叫做 AXI FIFO 接口 (AFI),来表明它们的缓冲能力。
AXI_HP 接口的特性包括 [4]:
• 32 或 64 位数据主机接口,每个端口可以独立编程。
• 对于未对齐的 32 位传输,可以自动扩展传输尺寸从 32 位到 64 位。
• 写命令的可编程的阈值。
• 对于所有的 PL-PS 接口的异步时钟频率跨域。
• 读写 FIFO。
• 命令和通信数据 FIFO 填充程度计数是 PL 可见的。
内存一致性的相关问题:
使用HP口写入数据时,ARM核并不知道你写入(因为没有经由Cache),需要做一个通知CPU刷新Cache数据,令其访问数据时直接到内存中取数。
ACP接口接口不需要在 PL 部件 中加入额外的一致性操作
其将数据先先到缓存,再通过缓存把数据搬移到内存中。

ACP接口
ACP 是 SCU 上的一个 64 位从机接口,实现从 PL 到 PS 的异步 cache 一致性接入 点。
ACP 实现了 PS 和 PL 之间的低延迟连接,而且对于 L1 和 L2 cache 带有可选的 一致性操作能力 [4]。这是一个 64 位的接口,使得 PL 可以实现一个能访问 OCM 和 L2 cache 的 AXI 主机。 从系统的角度看,ACP 接口具有可与 APU 中的 CPU 相比较的连接性。由于这个 原因,ACP 是和 APU 的 CPU 直接竞争 APU 之外的资源 [4]。
这意味着当 ACP 接口在使 用的时候,cache 空间的段将会被协处理器任务所占据。因此,依赖 CPU cache 来 实现高性能或甚至是实时性能的 CPU 进程,也许不能满足所需的时间期限。如果这 样的话,最好还是使用 AXI_HP 接口来在 OCM 中存储任务的数据
ACP 是可以被很多 PL 主机所访问的,用以实现和 APU 处理器相同的方式访问存 储子系统。这能达到提升整体性能、改善功耗和简化软件的效果。ACP 接口的表现 和标准的 AXI 从机接口是一样的,支持大多数标准读和写的操作而不需要在 PL 部件 中加入额外的一致性操作。因此,当 PL 上的任一本地存储器都不是与 CPU 保持一致 的时候,ACP 实现了从 PL 到 CPU 的 cache 的 cache 一致性访问 [2]。
通过 ACP 到存储器的一个一致性部分的任何读取的操作都要经过 SCU 来检查所 需的数据当前是否在 CPU 的 L1 cache 中。如果数据在 L1 cache 中,所需的数据就会直接返回给请求的部件。如果数据不在 L1 cache 中,就会先检查 L2 cache 然后 才能向主存储器发出数据请求 [2]。 写入到一致性存储区域的过程,在写入到主存储器之前,由 SCU 实现了一致性 强化。可选的是,写入的过程也可以在 L2 cache 上进行,这样就消除了写入到片外 存储器时的性能和功耗的影响 [2]。
写入到一致性存储区域的过程,在写入到主存储器之前,由 SCU 实现了一致性 强化。可选的是,写入的过程也可以在 L2 cache 上进行,这样就消除了写入到片外 存储器时的性能和功耗的影响 [2]。
ACP 的使用
ACP 提供了 PL 中所实现的加速器和 PS 之间的低延迟的链路。在 PS 和 PL 加速 器之间的通信所需的步骤总结如下 [2]:
1. 给加速器的输入数据是在 CPU 的本地 cache 空间内准备的。
2. 一条从 CPU 发送给加速器的信息,通过一个到 PL 的 AXI 通用主机接口 (AXI_GP)实现。
3. PL 加速器通过 ACP 获取数据。数据被处理后,结果通过 ACP 返回。
4. 加速器通过在一个已知的地方写入来设置一个标志,表明数据处理已经完成 了。这个标志的状态可以被 PS 轮询,或产生一个中断。
与紧密耦合的协处理器相比较的话,ACP 具有相对较高的访问延迟。因此,ACP 不被建议用做细粒度的指令级别的加速。由于和会话时间相比,ACP 的额外开销相 对较小,所以 ACP 与传统的用于粗粒度 (比如视频帧级别的处理)的存储映射 PL 加速方式相比也不具有明显的优势。因此 ACP 用于中等粒度的加速是最好的,
比如 块级别的加密算法的加速 .
表 10.2 详细列出了基于当前 cache 状态的 ACP 读写表现。表中可以清楚看出, 当 cache 的命中发生的时候,访问延迟是低的 [2]。

ACP 的局限性 ACP 存在着一些局限性 [2]:
• 一致性存储器不允许做访问加锁。
• 一致性存储器不允许做独占访问。
• 从其他 AXI 主机来的访问会由于通过 ACP 来的对 OCM 的持续访问(用完了 ACP 带宽)而无法进行。ACP 的带宽应该降低到小于 OCM 峰值带宽的程度,以允许其他主机的访问。这可以通过调整数据包大小为小于八个 64 位的字而实现。
• AWLEN=3、AWSIZE=3 和 WSTRB 不等于 11111111 的写入操作会导致 CPU 中的 cache 线崩溃。
• 让写入请求比读取请求优先的模块,比如 PCI Express(PCIe),不应该被接 入到 ACP 上,因为它们会产生死锁。它们应该被接到 AXI GP 或 HP 端口来避免 死锁。
AXI_GP 接口
AXI_GP 接口是直接连接主机互联和从机互联的端口的。
AXI_HP 接口具有一个 1kB 的数据 FIFO 来做缓冲 [4],但是 AXI_GP 接口与它不同,没有额外的缓冲。因此 性能就受到主机端口和从机互联的制约。
这些接口仅用于通用的目的,而且不应该 被用于高性能的任务。
AXI_GP 接口的特性包括 [4]:
• 32 位数据总线宽度。
• 12 位总线端口 ID 宽度。
• 6 位从机端口 ID 宽度。
• 主机和从机端口接受一次 8 个读取和 8 个写入。
AXI_GP 接口的每个端口能支持多个外设。
中断接口
PS 和 PL 之间的中断是由通用中断控制器 (Generic Interrupt Controller, GIC)所控制的,它支持 64 条中断线。

六个中断是从 APU 内产生的,包括 L1 校验失败、L2 中断和性能监视单元 (Performance Monitor Unit,PMU)中断。
从 GIC 输出的中断,驱动 IRQ 或快速中断请求 (Fast Interrupt ReQuest, FIQ)作为 CPU 输入信号。对于中断的处理器目标的选择是由 APU 里的 SCU 寄存器实 现的。表 10.3 详细列出了中断指标 [2]。

通用中断控制器 (GIC) 是一个集中资源,用于管理从 PS 和 PL 发送到 CPU 的中断。当CPU接口接受下一个中断时,控制器启用、禁用、屏蔽中断源并确定中断源的优先级,并以编程方式将它们发送到选定的CPU(或多个CPU)。
此外,控制器还支持安全扩展,以实现安全感知系统。该控制器基于 ARM 通用中断控制器架构版本 1.0 (GIC v1),非矢量化。
通过 CPU 专用总线访问寄存器,通过避免互连中的临时阻塞或其他瓶颈来实现快速读/写响应。


中断分配器会集中所有中断源,然后将具有最高优先级的中断源分派给各个 CPU。 GIC 确保针对多个 CPU 的中断一次只能由一个 CPU 处理。所有中断源均由唯一的中断 ID 号标识。
所有中断源都有自己的可配置优先级和目标 CPU 列表。
中断:PL硬中断,基地址,优先级。_NoNoUnknow的博客-CSDN博客
存储器映射




