
- 1重温CLR(十二) 委托
- 2LLM大模型实战项目--基于Stable Diffusion的电商平台虚拟试衣
- 3GPT-4o mini 比gpt-3.5更便宜(2024年7月18日推出)
- 4Git实战攻略:分支、合并与提交技巧_git合并分支提交分支
- 5银河麒麟V10桌面操作系统安装教程_银河麒麟操作系统v10
- 6tensorflow 车牌识别项目(一)_车牌定位的标签文件时json吗
- 7单链表(二)_建立一个非递减有序单链表(不少于5个元素结点),输出该链表中重复的元素以及重复次
- 8在安卓手机上用termux安装完整kali linux的办法_安卓完整linux
- 9 [推荐]dotNET中进程间同步/通信的经典框架_christoph ruegg
- 10平衡二叉树与java实现_java实现平衡二叉树
网络爬虫:爬取网页数据
赞
踩
目录
4.urllib.robotparser: robots.txt 解析模块
概述
基于爬虫的实现原理,进入爬虫的第一阶段:爬取网页数据,即下载包含目标数据的网页。爬取网页需要通过爬虫向服务器发送一个HTTP请求,然后接收服务器返回的响应内容中的整个网页源代码。
利用Python 完成这个过程,既可以使用内置的urllib库,也可以使用第三方库requests。使用这两个库,在爬取网页数据时,只需要关心请求的URL格式,要传递什么参数,要设置什么样的请求头,而不需要关心它们的底层是怎样实现的。
一.使用urllib爬取网页
urllib库是python内置的请求库,可以处理RL的组件集合。 爬取网页其实就是通过URL获取网页信息,这段网页信息的实质就是一段附加 了JavaScript 和CSS的HTML代码。如果把网页比作-一个人, 那么HTML就是他的骨架,JawaScript 是他的肌肉,CSS是他的衣服。由此看来,网页最重要的数据部分是存在于HTML中的。
1.urllib.request:请求模块
urllib.request 是一个 Python 标准库模块,用于发送 HTTP 请求。它提供了构建和发送 HTTP 请求的功能,以及处理响应的功能。该模块是 Python 中用于网络通信的重要组成部分,使开发人员能够轻松地发送 HTTP 请求并获取响应。
示例代码:首先导入了 urllib.request 模块,然后指定了要请求的 URL。接着,我们使用 urlopen() 函数发送 GET 请求,并将响应对象存储在 response 变量中。最后,我们读取响应内容并打印输出。
- import urllib.request
-
- url = "http://example.com"
- response = urllib.request.urlopen(url)
- data = response.read()
- print(data)
2.urllib.error: 异常处理模块
urllib.error 是 Python 的标准库之一,用于处理与 urllib.request 相关的异常。
主要异常类:URLError、HTTPError、ContentTooShortError
示例代码:使用 urllib.error 异常处理模块来捕获和处理异常:
- import urllib.request #: 导入模块,该模块用于发送HTTP请求。
- import urllib.error # 导入模块,该模块包含处理HTTP错误时的异常类。
-
-
- try:
- url = "http://example.com"
- response = urllib.request.urlopen(url)
- data = response.read()
- print(data) #打印从URL获取的数据
- except urllib.error.URLError as e: # 捕获由urllib.request模块抛出的URLError异常
- print("URL Error:", e.reason)
- except urllib.error.HTTPError as e:
- print("HTTP Error:", e.code, e.reason) # 如果发生HTTPError异常,则打印出错误消息、HTTP状态码和相关的reason属性。
3.urllib.parse: URL解析模块
使用 urlparse 函数解析给定的 URL,然后分别输出其各个组件。接着,使用 urlunparse 函数将解析后的组件重新构建成一个完整的 URL。
- from urllib.parse import urlparse, urlunparse
-
- # 定义一个示例 URL
- url = "https://www.example.com/path/to/page?param1=value1¶m2=value2#fragment"
-
- # 使用 urlparse 函数解析 URL
- parsed_url = urlparse(url)
-
- # 输出解析后的 URL 组件
- print("Scheme:", parsed_url.scheme)
- print("Netloc:", parsed_url.netloc)
- print("Path:", parsed_url.path)
- print("Parameters:", parsed_url.params)
- print("Query:", parsed_url.query)
- print("Fragment:", parsed_url.fragment)
-
- # 使用 urlunparse 函数重新构建 URL
- reconstructed_url = urlunparse((parsed_url.scheme, parsed_url.netloc, parsed_url.path, parsed_url.params, parsed_url.query, parsed_url.fragment))
- print("Reconstructed URL:", reconstructed_url)

4.urllib.robotparser: robots.txt 解析模块
urllib.robotparser 是 Python 的标准库中的一个模块,用于解析 robots.txt 文件。robots.txt 文件是一个用于指导网络爬虫如何爬取一个网站内容的标准。它告诉爬虫哪些页面可以爬取,哪些页面不能爬取,以及爬取的频率限制。
要使用 urllib.robotparser,首先需要导入 RobotFileParser 类,然后创建一个实例,并调用其 read() 方法来读取 robots.txt 文件的内容。之后,可以使用 can_fetch() 方法检查特定爬虫是否被允许访问某个 URL。
二.使用 PyCharm 编译器爬取网络数据
1.配置PyCharm安装解释器
- 打开IDE,进入你想要安装pandas的Python项目。
- 在菜单栏上找到并点击【文件】(File)。
- 在下拉菜单中选择【设置】(Settings)。
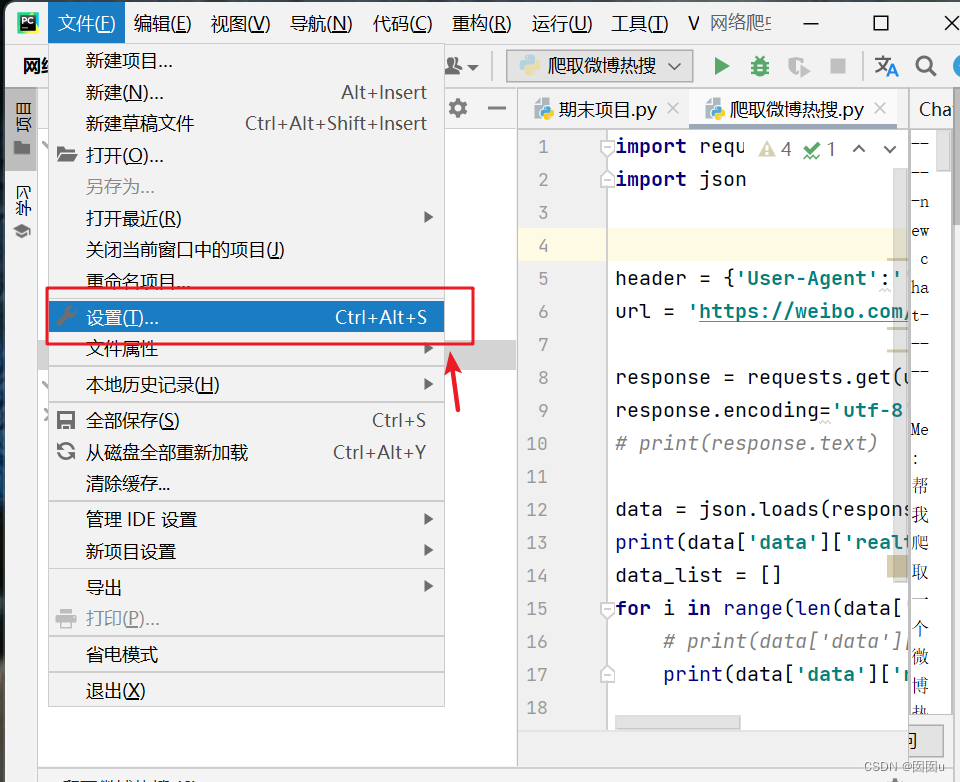
- 在设置对话框中,找到并点击【项目】(project)
- 在项目设置页面中,找到并点击【项目解释器】(Python Interpreter)。
- 在项目解释器页面,你会看到一个列表,列出了当前项目中已经安装的所有Python库。
- 点击列表下方的+号,准备添加新的Python库。
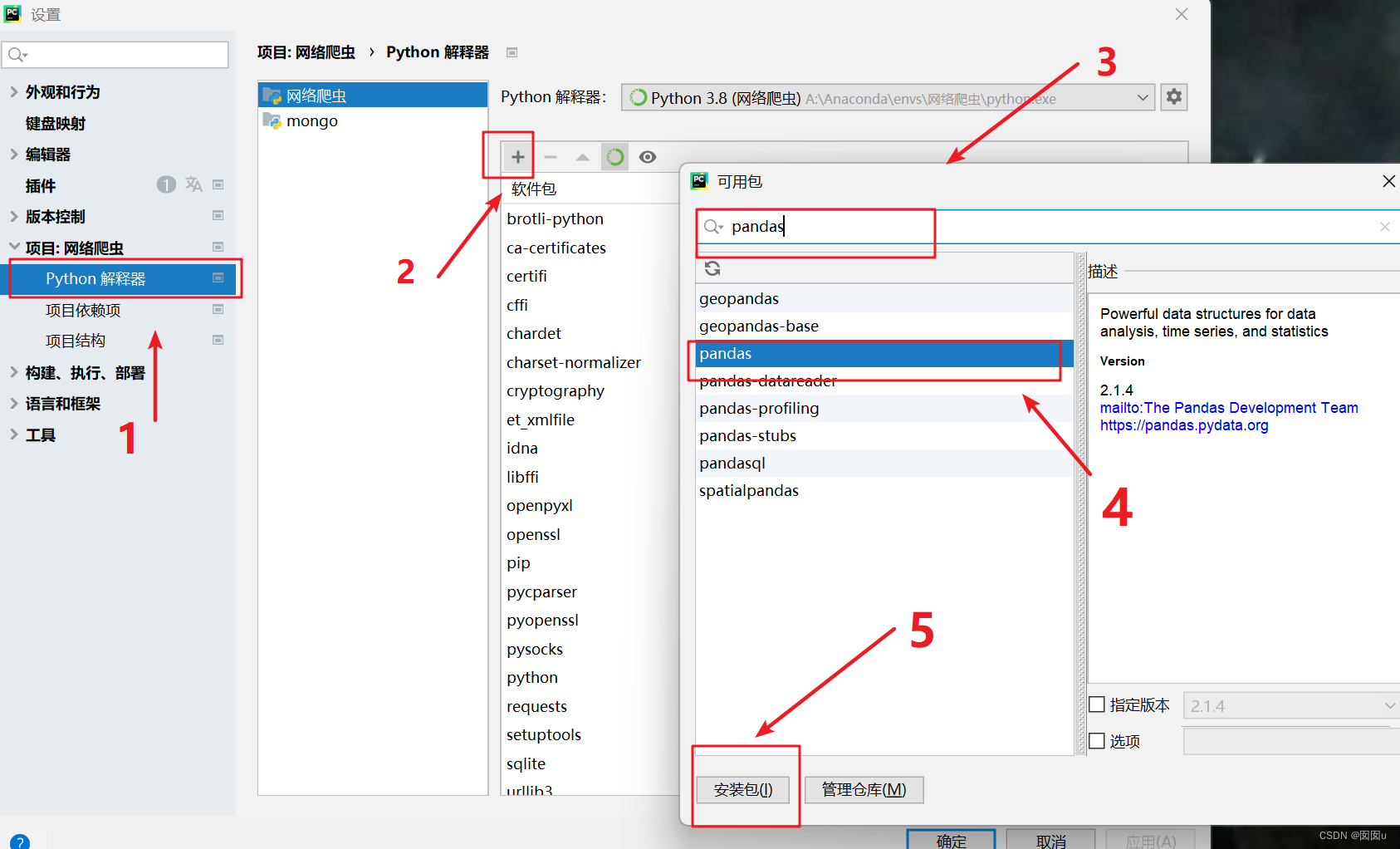
- 在弹出的搜索框中输入“pandas”。
- 在搜索结果列表中找到“pandas”,选中它。
- 点击安装按钮,开始安装pandas库。
- 等待安装完成,当出现提示时,表示pandas库已经成功安装
2.快速爬取一个urllib的网页
首先,确保我们已经安装了Python。然后,可以通过运行以下命令来安装urllib库:
pip install urllib使用以下代码来爬取一个网页:
- import urllib. request
-
- #调用urllib. request库的urlopen()方法,并传入一个url
-
- response=urll ib. request. urlopen ('http:/ /www . baidu. com')#使用read()方法读取获取到的网页内容
-
- html=response. read() . decode ('UTF-8')
-
- #打印网页内容
-
- print (html)
爬取结果如图所示:
 三.使用urllib爬取百度贴吧
三.使用urllib爬取百度贴吧
下面直接展示我使用urllib爬取网络贴吧的代码:
- import urllib.request
-
- # 定义一个函数爬取贴吧页面
- def crawl_tieba(url):
- resp = urllib.request.urlopen(url)
- html = resp.read().decode('utf-8')
- return html
-
- if __name__ == '__main__':
- base_url = 'https://tieba.baidu.com/f?kw='
- tieba_name = input("请输入要爬取的贴吧名称:")
- url = base_url + urllib.request.quote(tieba_name)
- html = crawl_tieba(url)
-
- # 保存结果
- with open('tieba.html', 'w', encoding='utf-8') as f:
- f.write(html)
- print('您的贴吧的页面已保存成功!')
代码运行成功的结果:

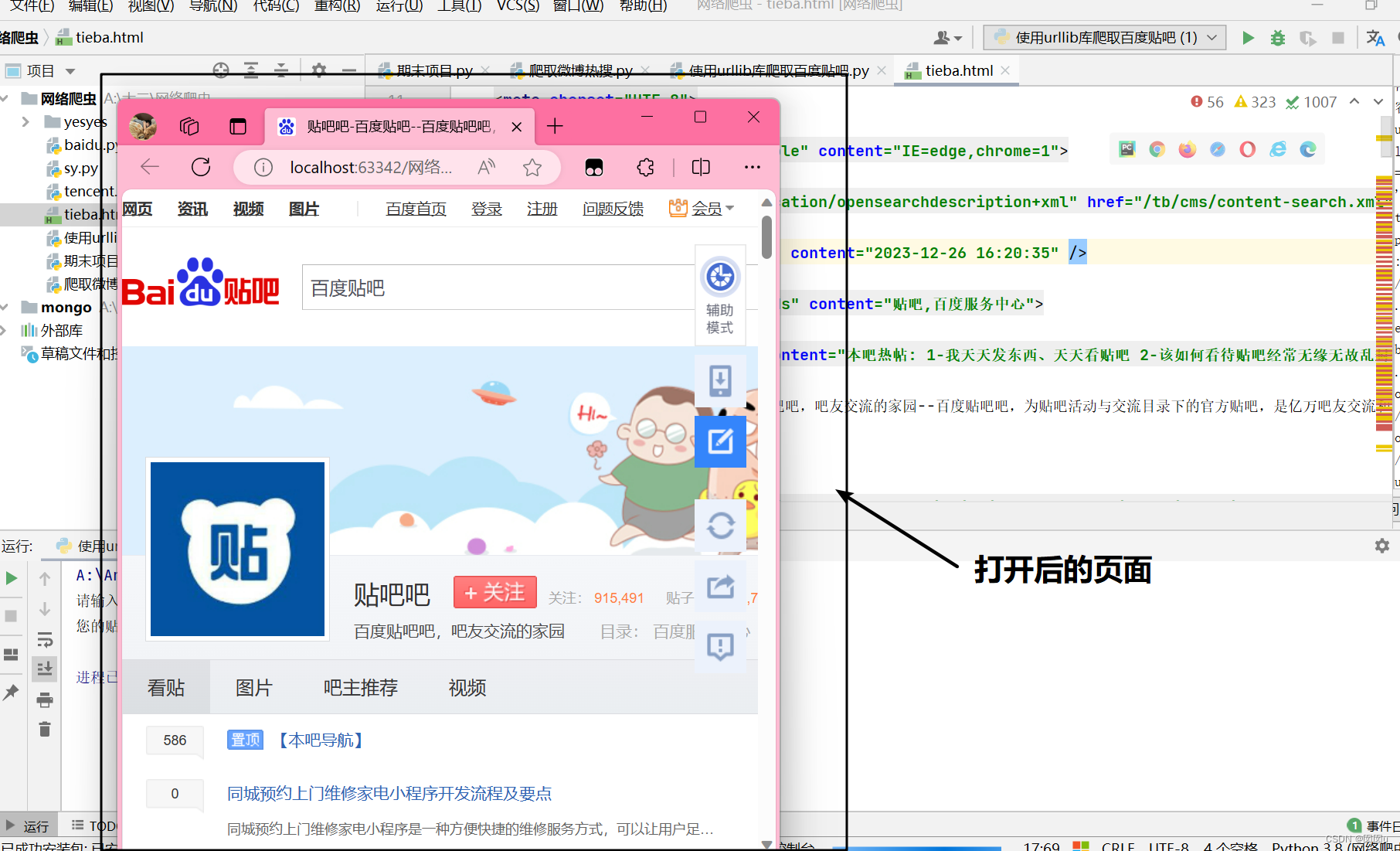 这是一个相对简单爬取网页的方法。
这是一个相对简单爬取网页的方法。

