
热门标签
热门文章
- 1[常微分方程的数值解法系列二] 欧拉法_c2d 后向欧拉法
- 2Spring DI简介及依赖注入方式和依赖注入类型
- 3如何查找下载安装安卓APK历史版本?_旧版本apk
- 4CodeWave学习笔记--采购管理系统_code ware
- 5DETR训练自己的数据集,yolo数据集格式转为coco数据集格式_yolo格式转coco格式
- 6DO280OpenShift访问控制--security policy和章节实验_redhat do280
- 7centos 7解决service iptables save报错
- 8在 VSCode 中搭建 Flutter 开发环境并运行项目_vscode flutter
- 9Reed-and-Shepp曲线解析_curve continous reedy shepp
- 10selenium-4 键盘事件
当前位置: article > 正文
昇思25天学习打卡营第11天|基于MindSpore的GPT2文本摘要
作者:喵喵爱编程 | 2024-07-19 17:04:31
赞
踩
昇思25天学习打卡营第11天|基于MindSpore的GPT2文本摘要
课程打卡凭证

数据集加载与处理
本实验使用了NLPCC2017的数据,主要内容是新闻正文及其摘要,共计50000个样本。
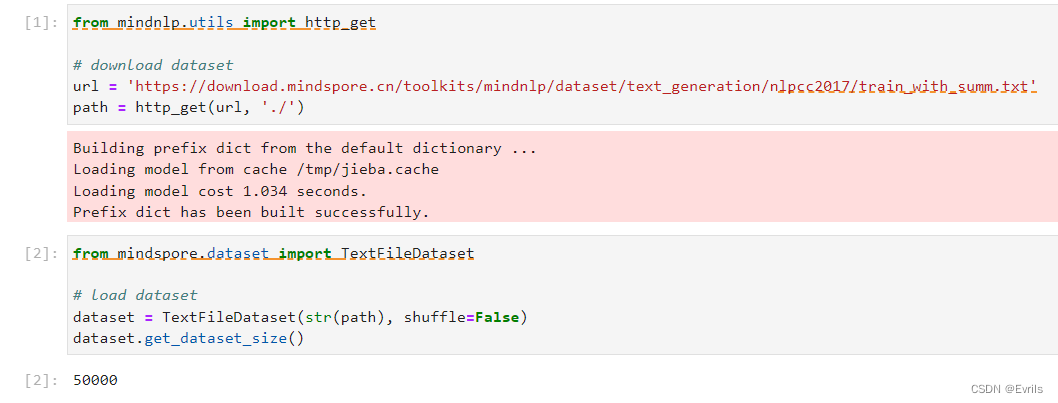
将数据划分为训练集和测试集。

定义数据集处理函数process_dataset,首先从原始数据集中提取文章和摘要字段,然后使用tokenizer对文章和摘要进行标记化、填充和截断,将数据集分成小批次并根据需要打乱数据,最后返回处理后的数据集,准备用于模型训练。
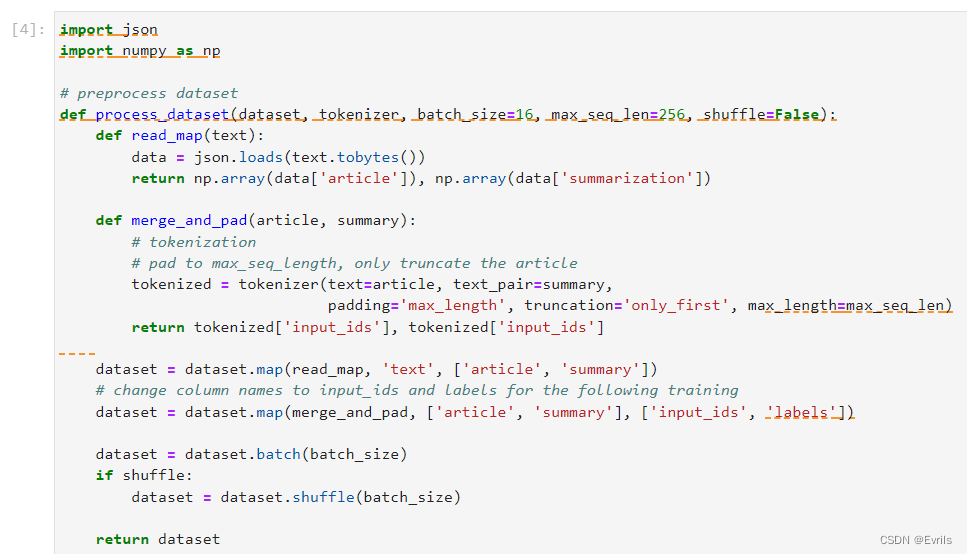
使用BertTokenizer替代GPT2中的Tokenizer。
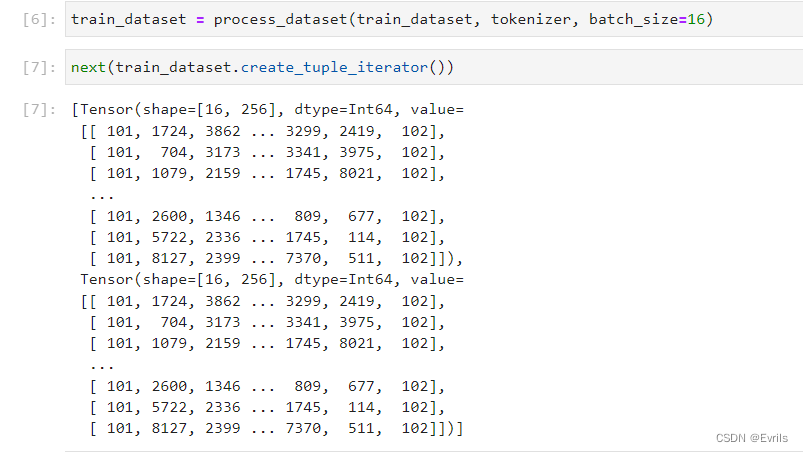
预处理训练数据集。
模型构建
自定义GPT2模型用于摘要生成。

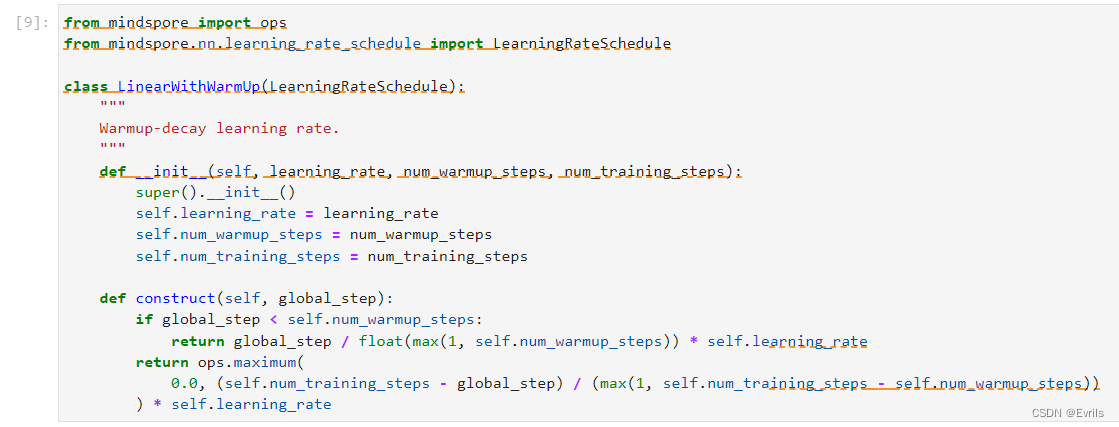
自定义学习率调度器。
模型训练
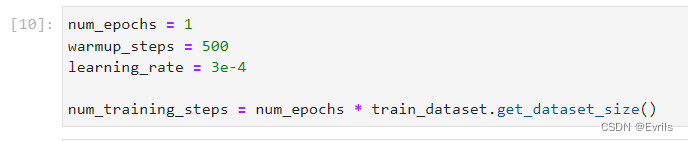
设置训练批次、预热步骤、学习率、训练步数等。
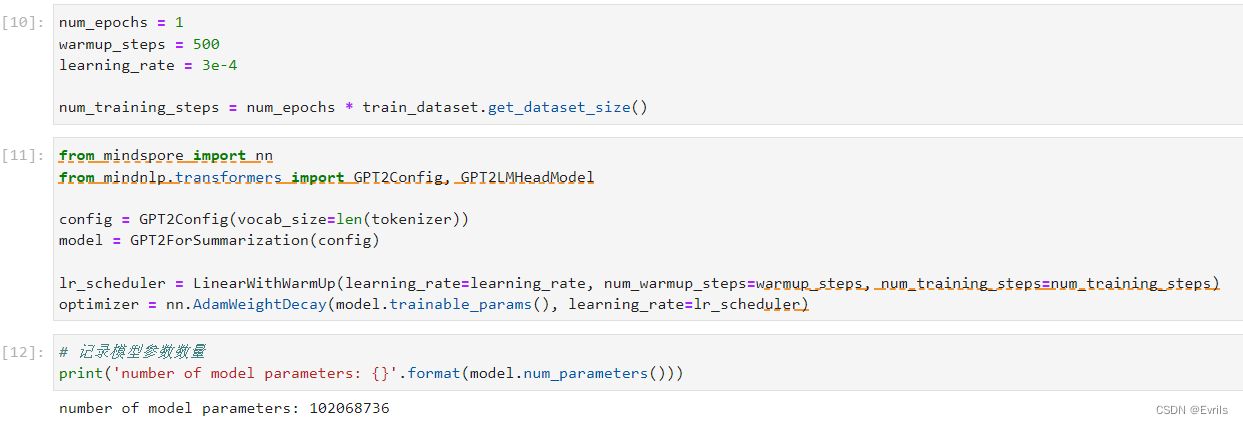
配置模型和优化器,记录模型参数数量。
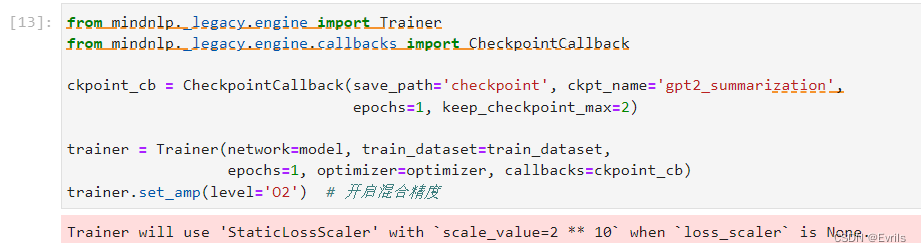
配置训练器。
开始训练模型。

为了追求快速收敛,loss反而越来越大。因此,这里将调整部分参数,重新训练模型,如下图所示。


声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/喵喵爱编程/article/detail/852595
推荐阅读
相关标签

