
- 1mssql 数据库审计账户_SQL Server 创建服务器和数据库级别审计
- 2linux进程间通讯指南-打通IPC大门,高效沟通无阻_linux ipc通讯的最好方式
- 3Uniapp启动编译报错问题_uniapp parsing failed at character position 14 nea
- 4hiveserver2连接数与hivemetastore连接数详解_查看hivemetastore连接数
- 5unity 用LineRender画四边形并测面积
- 6【信息安全】DES加密算法
- 7深度学习环境完整安装(Python+Pycharm+Pytorch cpu版)_深度学习环境安装
- 8大语言模型原理与工程实践:全参数微调
- 9[677]python操作SQLite数据库_python sqliteutil
- 10微软Edge浏览器搜索引擎切换全攻略_edge浏览器修改默认搜索引擎
基于LangChain-Chatchat实现的本地知识库的问答应用-快速上手(检索增强生成(RAG)大模型)_langchain 接入搜索引擎metaphor
赞
踩
基于LangChain-Chatchat实现的本地知识库的问答应用-kuaisu(检索增强生成(RAG)大模型)

基于 ChatGLM 等大语言模型与 Langchain 等应用框架实现,开源、可离线部署的检索增强生成(RAG)大模型知识库项目。
1.介绍
- 一种利用 langchain思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
- 受 GanymedeNil 的项目 document.ai和 AlexZhangji 创建的 ChatGLM-6B Pull Request启发,建立了全流程可使用开源模型实现的本地知识库问答应用。本项目的最新版本中通过使用 FastChat接入 Vicuna, Alpaca, LLaMA, Koala, RWKV 等模型,依托于 langchain框架支持通过基于 FastAPI 提供的 API 用服务,或使用基于 Streamlit 的 WebUI 进行操作。
- 依托于本项目支持的开源 LLM 与 Embedding 模型,本项目可实现全部使用开源模型离线私有部署。与此同时,本项目也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。
- 本项目实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的
top k个 -> 匹配出的文本作为上下文和问题一起添加到prompt中 -> 提交给LLM生成回答。
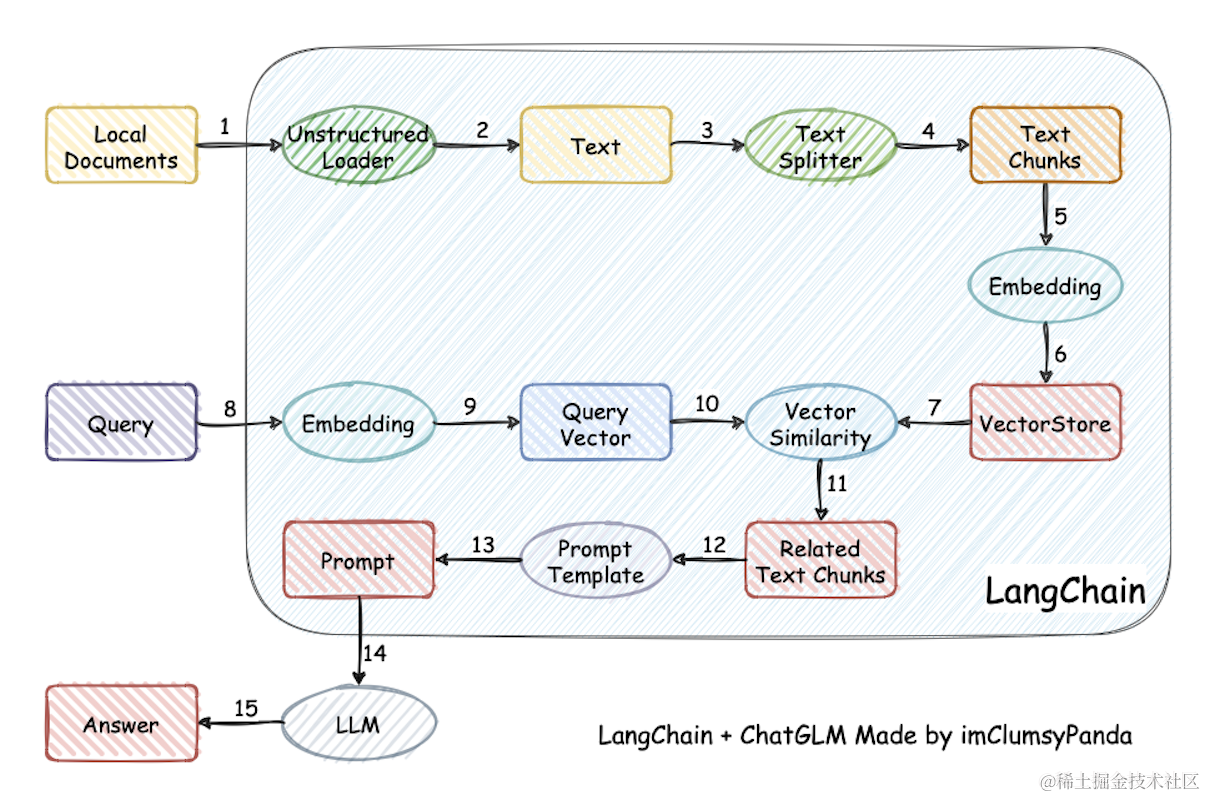
从文档处理角度来看,实现流程如下:
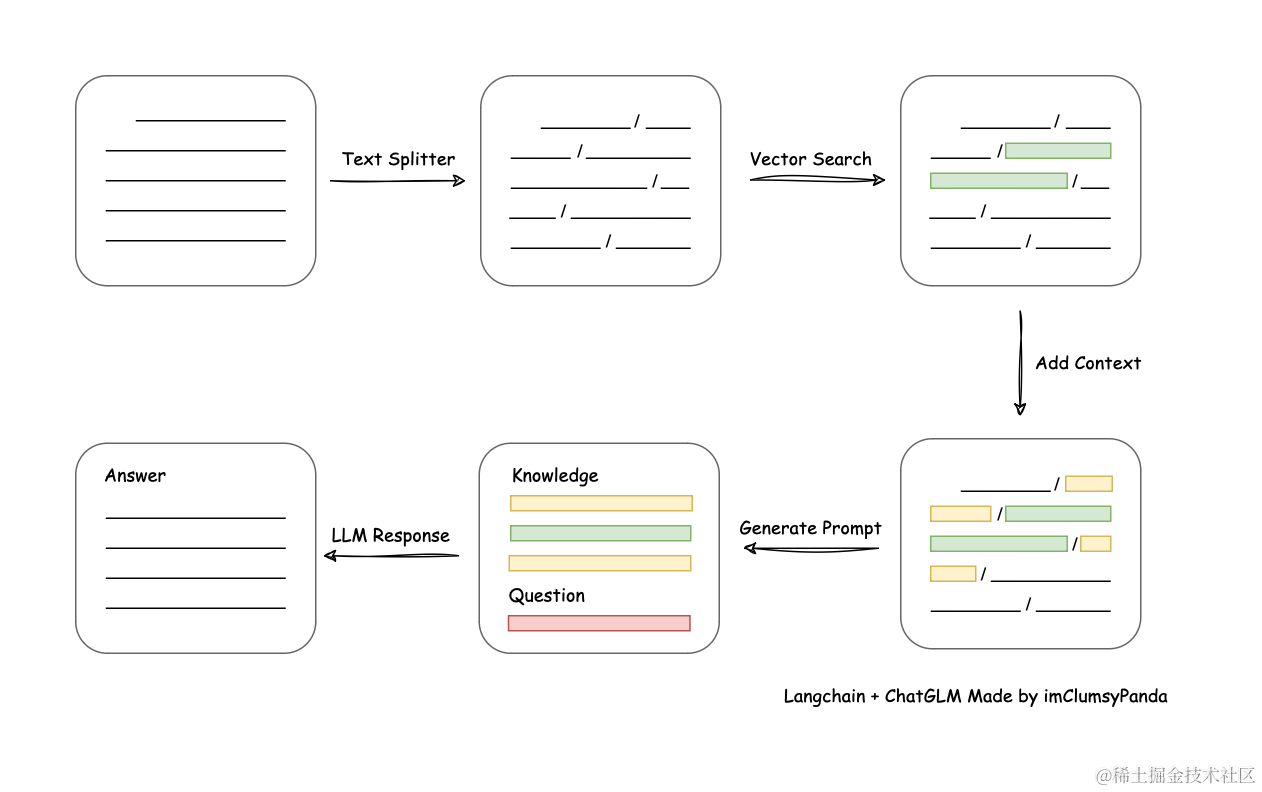
- 本项目未涉及微调、训练过程,但可利用微调或训练对本项目效果进行优化。
- AutoDL 镜像 中
0.2.10版本所使用代码已更新至本项目v0.2.10版本。 - Docker 镜像 已经更新到
0.2.10版本。 - 本次更新后同时支持DockerHub、阿里云、腾讯云镜像源:
代码语言:javascript
docker run -d --gpus all -p 80:8501 isafetech/chatchat:0.2.10
docker run -d --gpus all -p 80:8501 uswccr.ccs.tencentyun.com/chatchat/chatchat:0.2.10
docker run -d --gpus all -p 80:8501 registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.10
- 1
- 2
- 3
本项目有一个非常完整的Wiki , README只是一个简单的介绍,仅仅是入门教程,能够基础运行。如果你想要更深入的了解本项目,或者想对本项目做出贡献。请移步 Wiki界面
2. 解决的痛点
该项目是一个可以实现 __完全本地化__推理的知识库增强方案, 重点解决数据安全保护,私域化部署的企业痛点。本开源方案采用Apache License,可以免费商用,无需付费。
我们支持市面上主流的本地大语言模型和Embedding模型,支持开源的本地向量数据库。支持列表详见Wiki
3.快速实现案例
3.1. 环境配置
- 首先,确保你的机器安装了 Python 3.8 - 3.11 (我们强烈推荐使用 Python3.11)。
代码语言:javascript
$ python --version
Python 3.11.7
- 1
- 2
接着,创建一个虚拟环境,并在虚拟环境内安装项目的依赖
代码语言:javascript
#拉取仓库
$ git clone https://github.com/chatchat-space/Langchain-Chatchat.git
#进入目录
$ cd Langchain-Chatchat
#安装全部依赖
$ pip install -r requirements.txt
$ pip install -r requirements_api.txt
$ pip install -r requirements_webui.txt
#默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
如果在安装"pip install -r requirements.txt "遇到报错:
代码语言:javascript
distutils.errors.DistutilsError: Command '['/Users/didiyu/ENTER/envs/chain/bin/python', '-m', 'pip', '--disable-pip-version-check', 'wheel', '--no-deps', '-w', '/var/folders/yd/mp5rd9bx1x3670cth1fp7n180000gn/T/tmpkl7z5ekl', '--quiet', 'setuptools_scm']' returned non-zero exit status 1.
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
× Encountered error while generating package metadata.
╰─> See above for output.
note: This is an issue with the package mentioned above, not pip.
hint: See above for details.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 解决方案
代码语言:javascript
step1: pip install setuptools_scm
step 2: pip install wavedrom -i https://pypi.tuna.tsinghua.edu.cn/simple
- 1
- 2
参考链接:https://github.com/chatchat-space/Langchain-Chatchat/issues/1268
https://github.com/chatchat-space/Langchain-Chatchat/issues/2054
请注意,LangChain-Chatchat 0.2.x 系列是针对 Langchain 0.0.x 系列版本的,如果你使用的是 Langchain 0.1.x系列版本,需要降级您的Langchain版本。
3.2. 模型下载
如需在本地或离线环境下运行本项目,需要首先将项目所需的模型下载至本地,通常开源 LLM 与 Embedding模型可以从 HuggingFace 下载。
以本项目中默认使用的 LLM 模型 THUDM/ChatGLM3-6B 与 Embedding模型 BAAI/bge-large-zh 为例:
下载模型需要先安装 Git LFS ,然后运行
代码语言:javascript
$ git lfs install
$ git clone https://huggingface.co/THUDM/chatglm3-6b
$ git clone https://huggingface.co/BAAI/bge-large-zh
- 1
- 2
- 3
- 如果遇到模型下载缓慢的情况,可以从魔塔下载
- chatglm3-6b: https://modelscope.cn/models/ZhipuAI/chatglm3-6b/files
- bge-large-zh-v1.5: https://modelscope.cn/models/AI-ModelScope/bge-large-zh-v1.5/files
代码语言:javascript
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
git clone https://www.modelscope.cn/Xorbits/bge-large-zh.git
git clone https://www.modelscope.cn/AI-ModelScope/bge-large-zh-v1.5.git
- 1
- 2
- 3
3.3 Embedding模型介绍
FlagEmbedding专注于检索增强llm领域,目前包括以下项目:
- Long-Context LLM: Activation Beacon, LongLLM QLoRA
- Fine-tuning of LM : LM-Cocktail
- Embedding Model: Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding
- Reranker Model: llm rerankers, BGE Reranker
- Benchmark: C-MTEB
BGE-M3-多语言
(Paper, Code) 在这个项目中,我们发布了BGE-M3,它是第一个具有多功能、多语言和多粒度特性的文本检索模型。
- 多功能:可以同时执行三种检索功能:单向量检索、多向量检索和稀疏检索。
- 多语言:支持100多种工作语言。
- 多粒度:它能够处理不同粒度的输入,从短句子到长达8192个词汇的长文档。
在本项目中,为了提高单一检索模式的性能,提出了一种新的自知识蒸馏方法。 我们优化了批处理策略,支持大批处理大小,这可以在对长文本或大型语言模型进行向量微调时简单使用。 我们还构建了一个用于文档检索的数据集,并提出了一个简单的策略来提高长文本的建模能力。 训练代码和微调数据将在不久的将来开源。
Visualized-BGE-多模态
官方链接 在这个项目中,我们发布了Visualized-BGE。 通过引入image token embedding,Visualized-BGE可以被用来编码混合图文数据。它可以被应用在广泛的多模态检索任务中,包括但不限于:多模态知识检索,多模态查询的图像检索等。
LongLLM QLoRA
我们通过 QLoRA 微调将 Llama-3-8B-Instruct 的上下文长度从 8K 扩展到 80K。 整个训练过程非常高效,在一台8xA800 (80G) GPU 机器上仅需要8个小时。 该模型在NIHS、主题检索和长上下文语言理解等广泛的评估任务中表现出卓越的性能; 同时,它在短上下文中也很好地保留了其原有的能力。 如此强大的长文本能力主要归因于GPT-4生成的仅3.5K合成数据,这表明LLM具有扩展其原始上下文的固有(但在很大程度上被低估)潜力。 事实上,一旦有更多的计算资源,该方法可以将上下文长度扩展更长。
Activation Beacon
由于有限的上下文窗口长度,有效利用长上下文信息是对大型语言模型的一个巨大挑战。 Activation Beacon 将 LLM 的原始激活压缩为更紧凑的形式,以便它可以在有限的上下文窗口中感知更长的上下文。 它是一种有效、高效、兼容、低成本(训练)的延长LLM上下文长度的方法。 更多细节请参考技术报告和代码。
LM-Cocktail
模型合并被用于提高单模型的性能。 我们发现这种方法对大型语言模型和文本向量模型也很有用, 并设计了”语言模型鸡尾酒“方案,其自动计算融合比例去融合基础模型和微调模型。 利用LM-Cocktail可以缓解灾难性遗忘问题,即在不降低通用性能的情况下提高目标任务性能。 通过构造少量数据样例,它还可以用于为新任务生成模型,而无需进行微调。 它可以被使用来合并生成模型或向量模型。 更多细节请参考技术报告和代码。
LLM Embedder
LLM-Embedder向量模型是根据LLM的反馈进行微调的。 它可以支持大型语言模型的检索增强需求,包括知识检索、记忆检索、示例检索和工具检索。 它在6个任务上进行了微调:问题回答,对话搜索,长对话, 长文本建模、上下文学习和工具学习。 更多细节请参考./FlagEmbedding/llm_embedder/README.md
BGE Reranker
交叉编码器将对查询和答案实时计算相关性分数,这比向量模型(即双编码器)更准确,但比向量模型更耗时。 因此,它可以用来对嵌入模型返回的前k个文档重新排序。 我们在多语言数据上训练了交叉编码器,数据格式与向量模型相同,因此您可以根据我们的示例 轻松地对其进行微调。 更多细节请参考./FlagEmbedding/reranker/README.md
我们提供了新版的交叉编码器,支持更多的语言以及更长的长度。使用的数据格式与向量模型类似,但是新增了prompt用于微调以及推理。您可以使用特定的层进行推理或使用完整的层进行推理,您可以根根据我们的示例 轻松地对其进行微调。 更多细节请参考./FlagEmbedding/llm_reranker/README.md
BGE Embedding
BGE Embedding是一个通用向量模型。 我们使用retromae 对模型进行预训练,再用对比学习在大规模成对数据上训练模型。 你可以按照我们的示例 在本地数据上微调嵌入模型。 我们还提供了一个预训练示例 。 请注意,预训练的目标是重构文本,预训练后的模型无法直接用于相似度计算,需要进行微调之后才可以用于相似度计算。 更多关于bge的训练情况请参阅论文和代码.
注意BGE使用CLS的表征作为整个句子的表示,如果使用了错误的方式(如mean pooling)会导致效果很差。
C-MTEB
中文向量榜单,已整合入MTEB中。更多细节参考 论文 和代码.
Embedding模型列表
| Model | Language | Description | query instruction for retrieval [1] | |
|---|---|---|---|---|
| BAAI/bge-m3 | Multilingual | 推理 微调 | 多功能(向量检索,稀疏检索,多表征检索)、多语言、多粒度(最大长度8192) | |
| LM-Cocktail | English | 微调的Llama和BGE模型,可以用来复现LM-Cocktail论文的结果 | ||
| BAAI/llm-embedder | English | 推理 微调 | 专为大语言模型各种检索增强任务设计的向量模型 | 详见 README |
| BAAI/bge-reranker-large | Chinese and English | 推理 微调 | 交叉编码器模型,精度比向量模型更高但推理效率较低 [2] | |
| BAAI/bge-reranker-base | Chinese and English | 推理 微调 | 交叉编码器模型,精度比向量模型更高但推理效率较低 [2] | |
| BAAI/bge-large-en-v1.5 | English | 推理 微调 | 1.5版本,相似度分布更加合理 | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en-v1.5 | English | 推理 微调 | 1.5版本,相似度分布更加合理 | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en-v1.5 | English | 推理 微调 | 1.5版本,相似度分布更加合理 | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh-v1.5 | Chinese | 推理 微调 | 1.5版本,相似度分布更加合理 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh-v1.5 | Chinese | 推理 微调 | 1.5版本,相似度分布更加合理 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh-v1.5 | Chinese | 推理 微调 | 1.5版本,相似度分布更加合理 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-large-en | English | 推理 微调 | 向量模型,将文本转换为向量 | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en | English | 推理 微调 | base-scale 向量模型 | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en | English | 推理 微调 | small-scale 向量模型 | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh | Chinese | 推理 微调 | 向量模型,将文本转换为向量 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh | Chinese | 推理 微调 | base-scale 向量模型 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh | Chinese | 推理 微调 | small-scale 向量模型 | 为这个句子生成表示以用于检索相关文章: |
3.4 ChatGLM3-6B
ChatGLM3-6B 是 ChatGLM 系列最新一代的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的预训练模型中最强的性能。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM-6B-Base、长文本对话模型 ChatGLM3-6B-32K。
代码语言:javascript
pip install protobuf 'transformers>=4.30.2' cpm_kernels 'torch>=2.0' gradio mdtex2html sentencepiece accelerate
- 1
- 模型下载
代码语言:javascript
pip install modelscope
from modelscope import snapshot_download
model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0")
- 1
- 2
- 3
- git下载
代码语言:javascript
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
- 1
- 2
- 代码调用
代码语言:javascript
from modelscope import AutoTokenizer, AutoModel, snapshot_download
model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0")
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.5. 初始化知识库和配置文件
按照下列方式初始化自己的知识库和简单的复制配置文件
代码语言:javascript
$ python copy_config_example.py
$ python init_database.py --recreate-vs
- 1
- 2
- 配置文件下内容
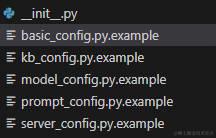
- basic_config.py.example
代码语言:javascript
import logging import os import langchain import tempfile import shutil #是否显示详细日志 log_verbose = False langchain.verbose = False #通常情况下不需要更改以下内容 #日志格式 LOG_FORMAT = "%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s" logger = logging.getLogger() logger.setLevel(logging.INFO) logging.basicConfig(format=LOG_FORMAT) #日志存储路径 LOG_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "logs") if not os.path.exists(LOG_PATH): os.mkdir(LOG_PATH) #临时文件目录,主要用于文件对话 BASE_TEMP_DIR = os.path.join(tempfile.gettempdir(), "chatchat") try: shutil.rmtree(BASE_TEMP_DIR) except Exception: pass os.makedirs(BASE_TEMP_DIR, exist_ok=True)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- kb_config.py.example
代码语言:javascript
import os #默认使用的知识库 DEFAULT_KNOWLEDGE_BASE = "samples" #默认向量库/全文检索引擎类型。可选:faiss, milvus(离线) & zilliz(在线), pgvector, chromadb 全文检索引擎es DEFAULT_VS_TYPE = "faiss" #缓存向量库数量(针对FAISS) CACHED_VS_NUM = 1 #缓存临时向量库数量(针对FAISS),用于文件对话 CACHED_MEMO_VS_NUM = 10 #知识库中单段文本长度(不适用MarkdownHeaderTextSplitter) CHUNK_SIZE = 250 #知识库中相邻文本重合长度(不适用MarkdownHeaderTextSplitter) OVERLAP_SIZE = 50 #知识库匹配向量数量 VECTOR_SEARCH_TOP_K = 3 #知识库匹配的距离阈值,一般取值范围在0-1之间,SCORE越小,距离越小从而相关度越高。 #但有用户报告遇到过匹配分值超过1的情况,为了兼容性默认设为1,在WEBUI中调整范围为0-2 SCORE_THRESHOLD = 1.0 #默认搜索引擎。可选:bing, duckduckgo, metaphor DEFAULT_SEARCH_ENGINE = "duckduckgo" #搜索引擎匹配结题数量 SEARCH_ENGINE_TOP_K = 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- model_config.py.example
代码语言:javascript
import os #可以指定一个绝对路径,统一存放所有的Embedding和LLM模型。 #每个模型可以是一个单独的目录,也可以是某个目录下的二级子目录。 #如果模型目录名称和 MODEL_PATH 中的 key 或 value 相同,程序会自动检测加载,无需修改 MODEL_PATH 中的路径。 MODEL_ROOT_PATH = "" #选用的 Embedding 名称 EMBEDDING_MODEL = "bge-large-zh-v1.5" #Embedding 模型运行设备。设为 "auto" 会自动检测(会有警告),也可手动设定为 "cuda","mps","cpu","xpu" 其中之一。 EMBEDDING_DEVICE = "auto" #选用的reranker模型 RERANKER_MODEL = "bge-reranker-large" #是否启用reranker模型 USE_RERANKER = False RERANKER_MAX_LENGTH = 1024 #如果需要在 EMBEDDING_MODEL 中增加自定义的关键字时配置 EMBEDDING_KEYWORD_FILE = "keywords.txt" EMBEDDING_MODEL_OUTPUT_PATH = "output" #要运行的 LLM 名称,可以包括本地模型和在线模型。列表中本地模型将在启动项目时全部加载。 #列表中第一个模型将作为 API 和 WEBUI 的默认模型。 #在这里,我们使用目前主流的两个离线模型,其中,chatglm3-6b 为默认加载模型。 #如果你的显存不足,可使用 Qwen-1_8B-Chat, 该模型 FP16 仅需 3.8G显存。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- prompt_config.py.example
代码语言:javascript
#prompt模板使用Jinja2语法,简单点就是用双大括号代替f-string的单大括号 #本配置文件支持热加载,修改prompt模板后无需重启服务。 #LLM对话支持的变量: #- input: 用户输入内容 #知识库和搜索引擎对话支持的变量: #- context: 从检索结果拼接的知识文本 #- question: 用户提出的问题 #Agent对话支持的变量: #- tools: 可用的工具列表 #- tool_names: 可用的工具名称列表 #- history: 用户和Agent的对话历史 #- input: 用户输入内容 #- agent_scratchpad: Agent的思维记录
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- server_config.py.example
代码语言:javascript
import sys from configs.model_config import LLM_DEVICE #httpx 请求默认超时时间(秒)。如果加载模型或对话较慢,出现超时错误,可以适当加大该值。 HTTPX_DEFAULT_TIMEOUT = 300.0 #API 是否开启跨域,默认为False,如果需要开启,请设置为True #is open cross domain OPEN_CROSS_DOMAIN = False #各服务器默认绑定host。如改为"0.0.0.0"需要修改下方所有XX_SERVER的host DEFAULT_BIND_HOST = "0.0.0.0" if sys.platform != "win32" else "127.0.0.1" #webui.py server WEBUI_SERVER = { "host": DEFAULT_BIND_HOST, "port": 8501, }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4. 一键启动
按照以下命令启动项目
代码语言:javascript
$ python startup.py -a
- 1
5. 启动界面示例
如果正常启动,你将能看到以下界面
- FastAPI Docs 界面
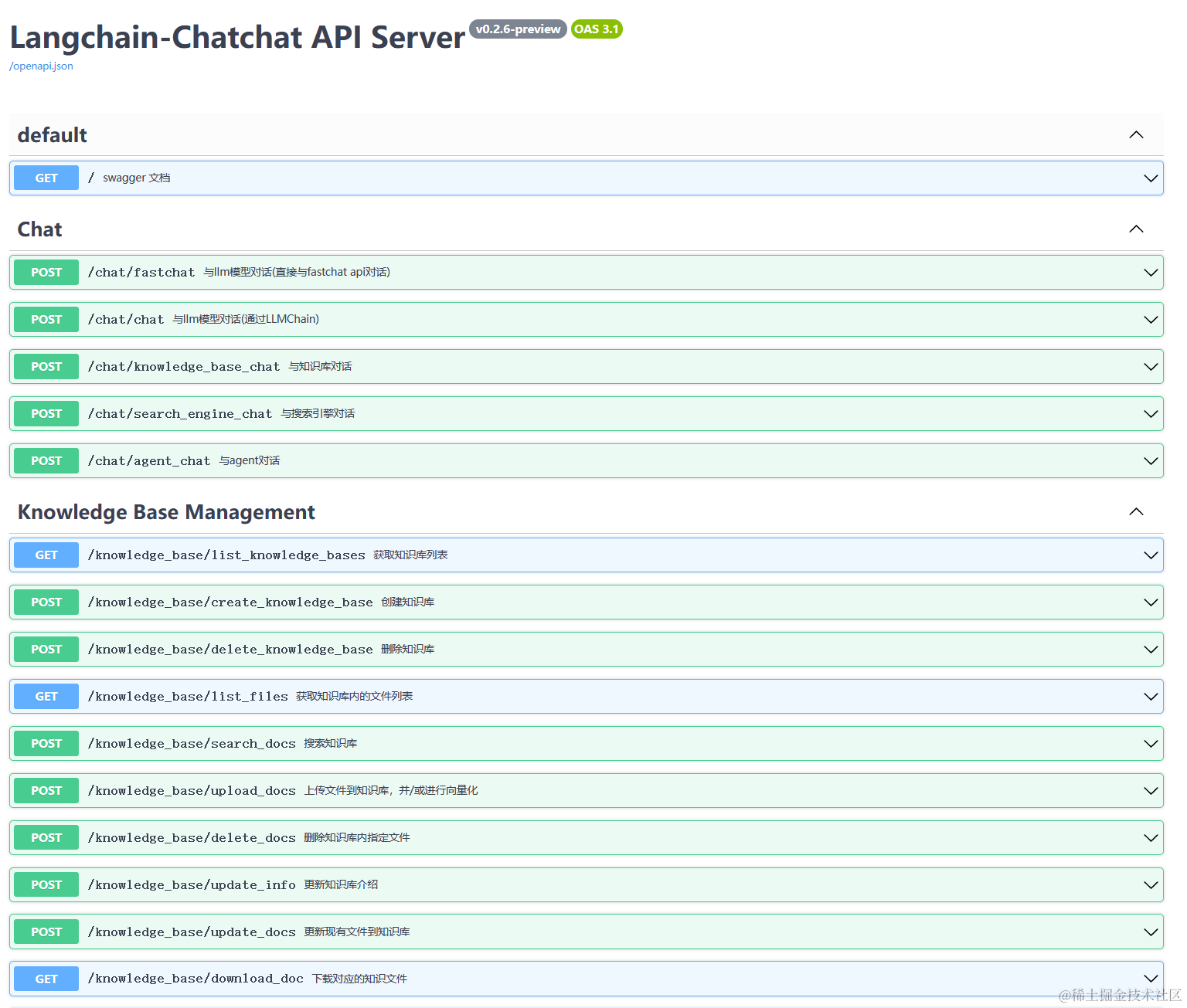
- Web UI 启动界面示例:
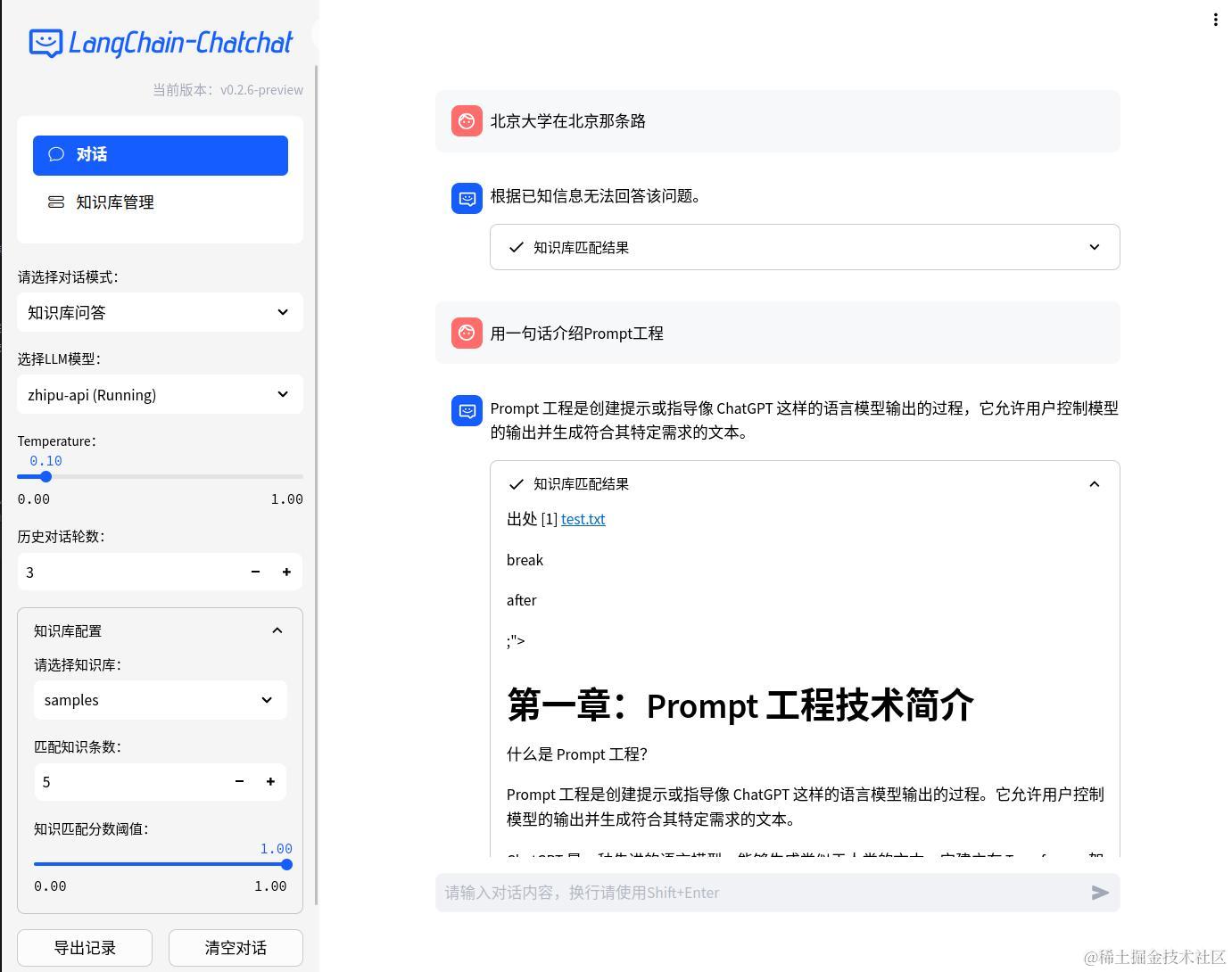
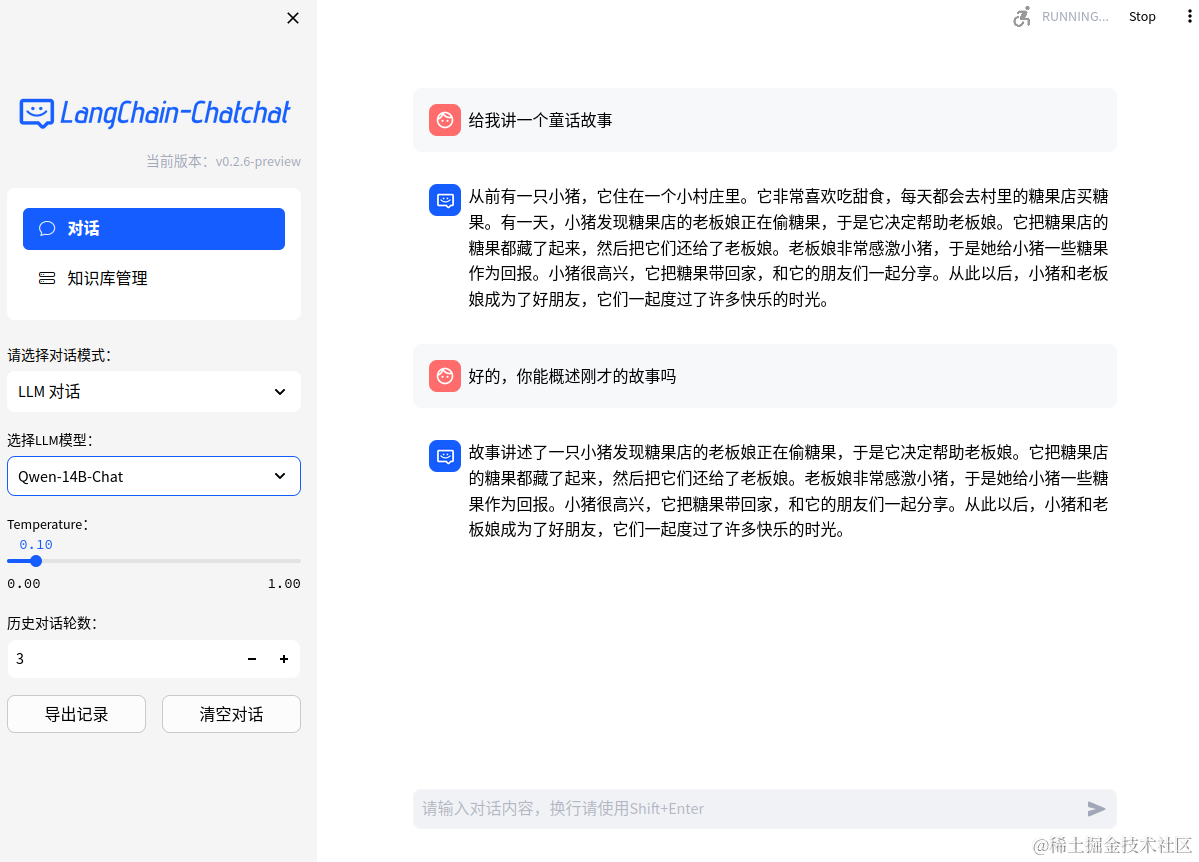
- Web UI 对话界面:
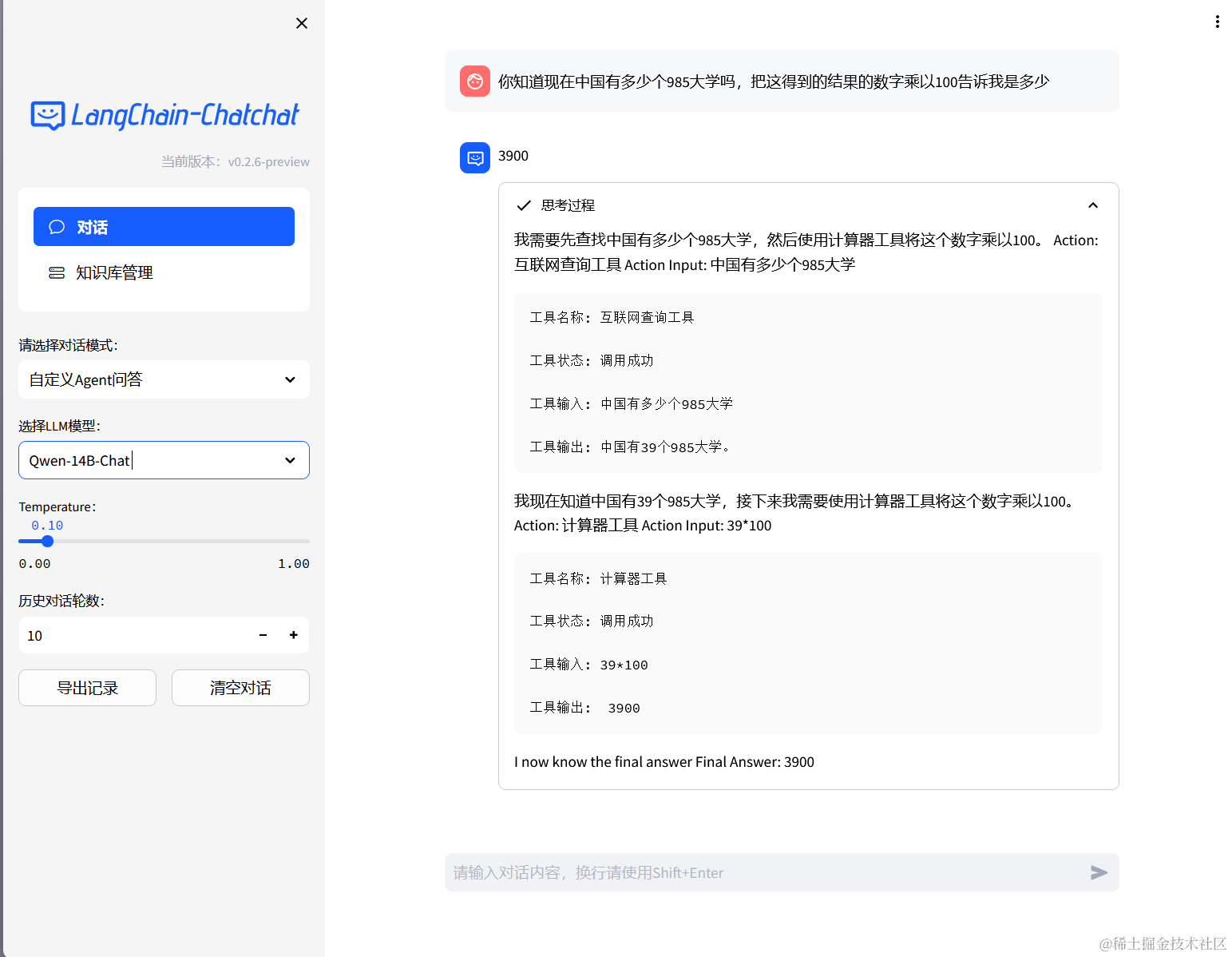
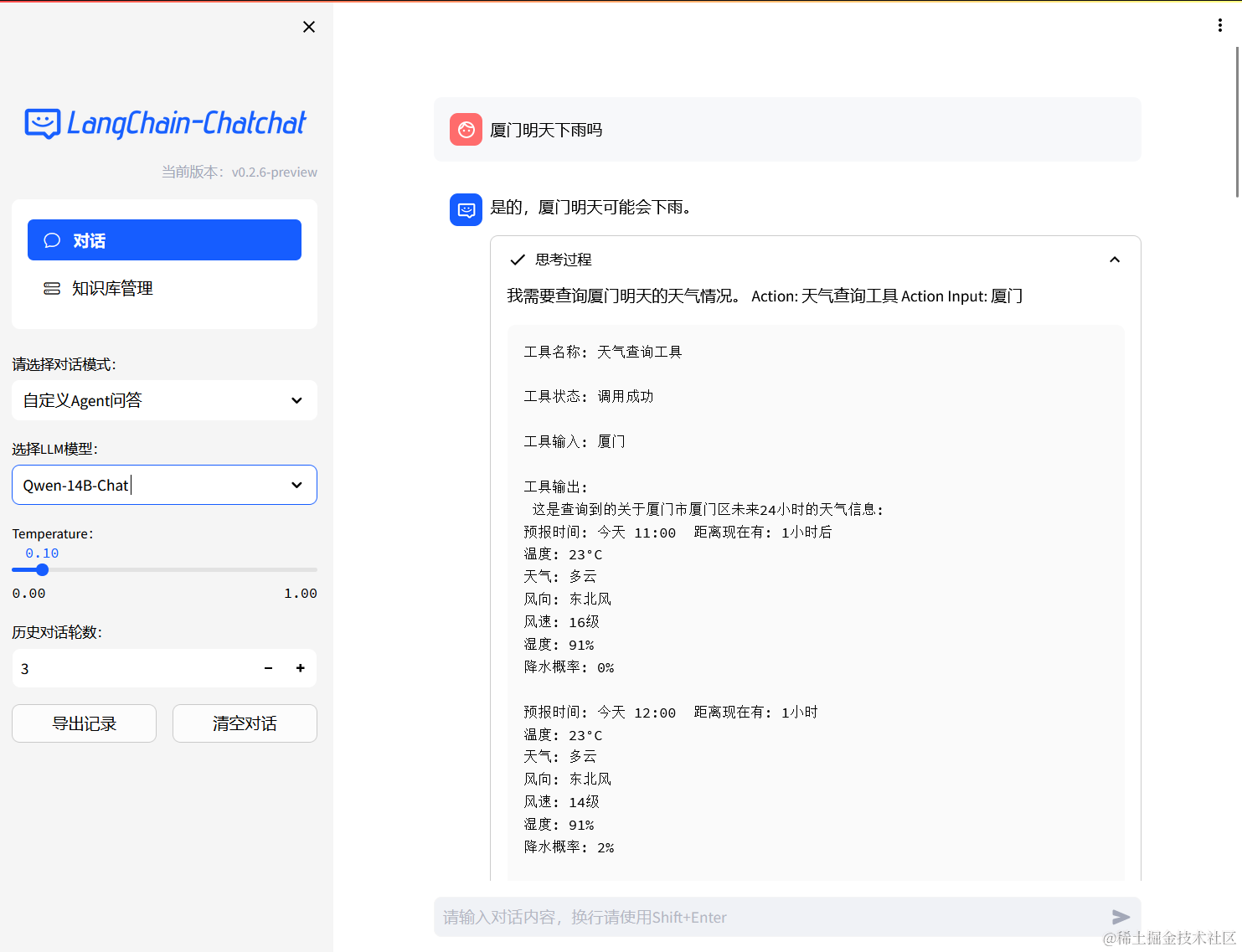
- Agent-Tool效果
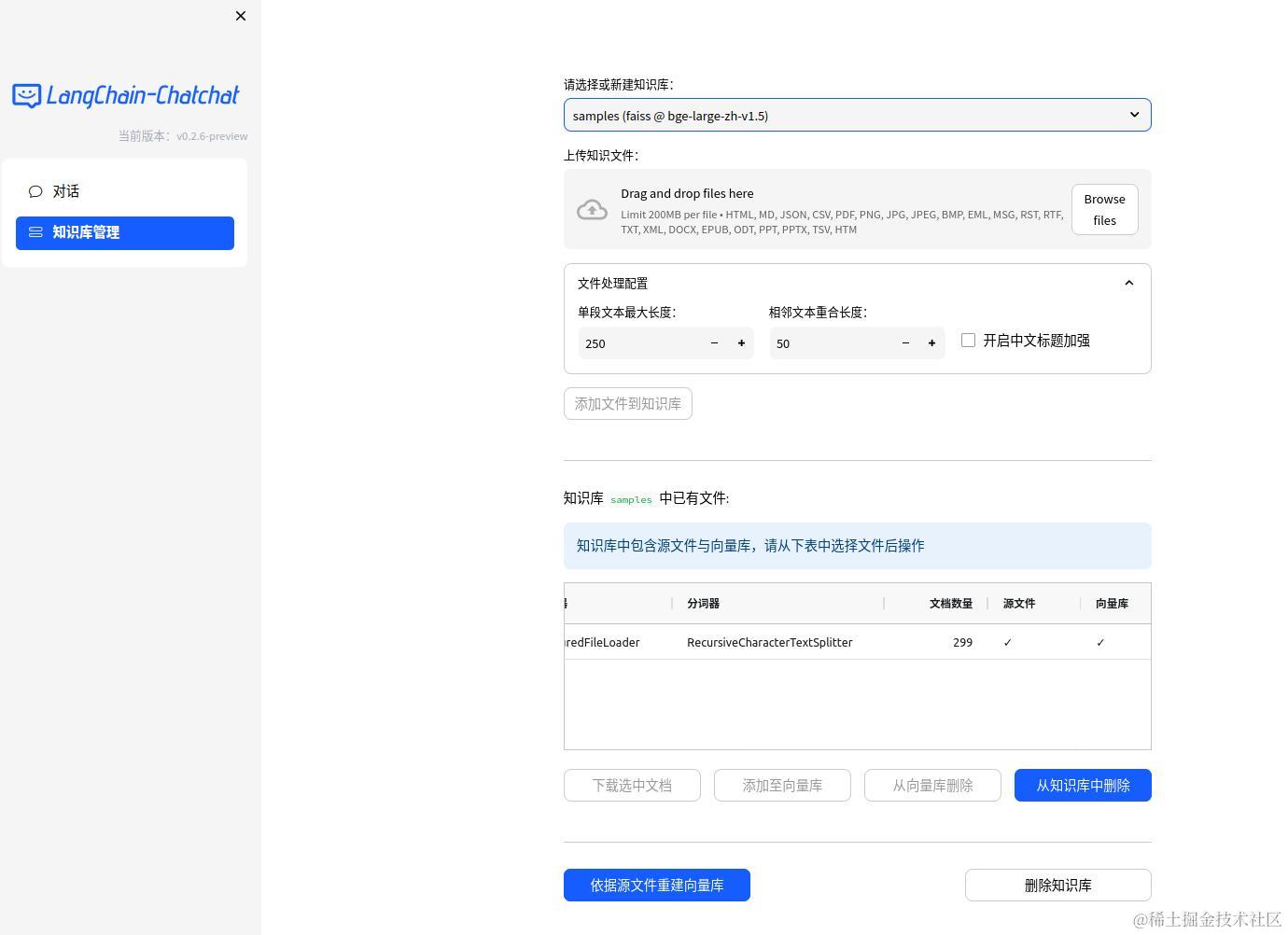
- Web UI 知识库管理页面:
如何系统的去学习大模型LLM ?
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

