
- 1寒武纪面试——数字IC,数字逻辑岗_寒武纪数字后端面试
- 2查询kafka信息,并设置Kafka的偏移量Offset_kafka 查下当下各分区offset
- 3【AI学习指南】轻量级模型-用 Ollama 轻松玩转本地大模型
- 4如何在 Spring Boot 中开发一个操作日志系统
- 5JAVA小白学习日记Day2
- 6Scrapy 框架采集亚马逊商品top数据_scrapy爬取亚马逊商品数据
- 7【实干!干货】Pycharm安装通义灵码ai智能编码助手
- 8昇思25天学习打卡营第三十天|快速入门
- 9PyQt5结合Yolo框架打包python为exe文件完整流程_用pyinstaller打包yolov5
- 10DataFrame 遍历访问方法_dataframe如何访问
集智书童 | 深度学习与先验方法在遥感与无人机影像去雾中的应用与挑战!_图像去雾2024
赞
踩
本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:深度学习与先验方法在遥感与无人机影像去雾中的应用与挑战!

在遥感与无人机应用中,高质量的图像至关重要,但大气雾霾会严重降低图像质量,使得图像去雾成为一个关键的研究领域。自从深度卷积神经网络被引入以来,已经提出了许多方法,随着视觉 Transformer 以及对比/少样本学习的发展,更多的方法也应运而生。
同时,也有关于适用于各种遥感领域(RS)的去雾架构的论文发表。这篇综述超越了传统的对基准雾天数据集的关注,作者还探讨了将去雾技术应用于遥感与无人机数据集的情况,全面概述了这些领域中的深度学习与基于先验的方法。
作者确定了关键挑战,包括缺乏大规模的遥感数据集以及需要更稳健的评价指标,并概述了潜在的解决方案和未来的研究方向以应对这些挑战。
据作者所知,这是首次提供对基于基准和遥感数据集(包括基于无人机的影像)的现有及最近(截至2024年)的去雾方法的全面讨论。
介绍
雾霾条件,由诸如雨雪等自然现象以及城市和森林火灾等人造灾害引起,可以严重降低摄影、监控和遥感等应用中的图像质量。这种退化导致对比度降低和色彩偏移,最终阻碍计算机视觉(CV)模型的性能,导致目标检测、图像分类和图像分割结果不佳。
因此,致力于从雾霾照片中提取清晰、高质量场景的研究数量在过去几十年里呈指数级增长。这一图像处理领域被称为_图像去雾_。
在深度学习在CV和图像处理中广泛应用之前,图像去雾技术大多依赖于基于先验的方法,在这些方法中,对给定的雾霾图像应用了各种假设,以统计方式提取和计算其去雾参数。
这些方法通常在特定雾霾场景和背景下提供良好的去雾输出和性能,但不一定适用于其他雾霾场景和背景。
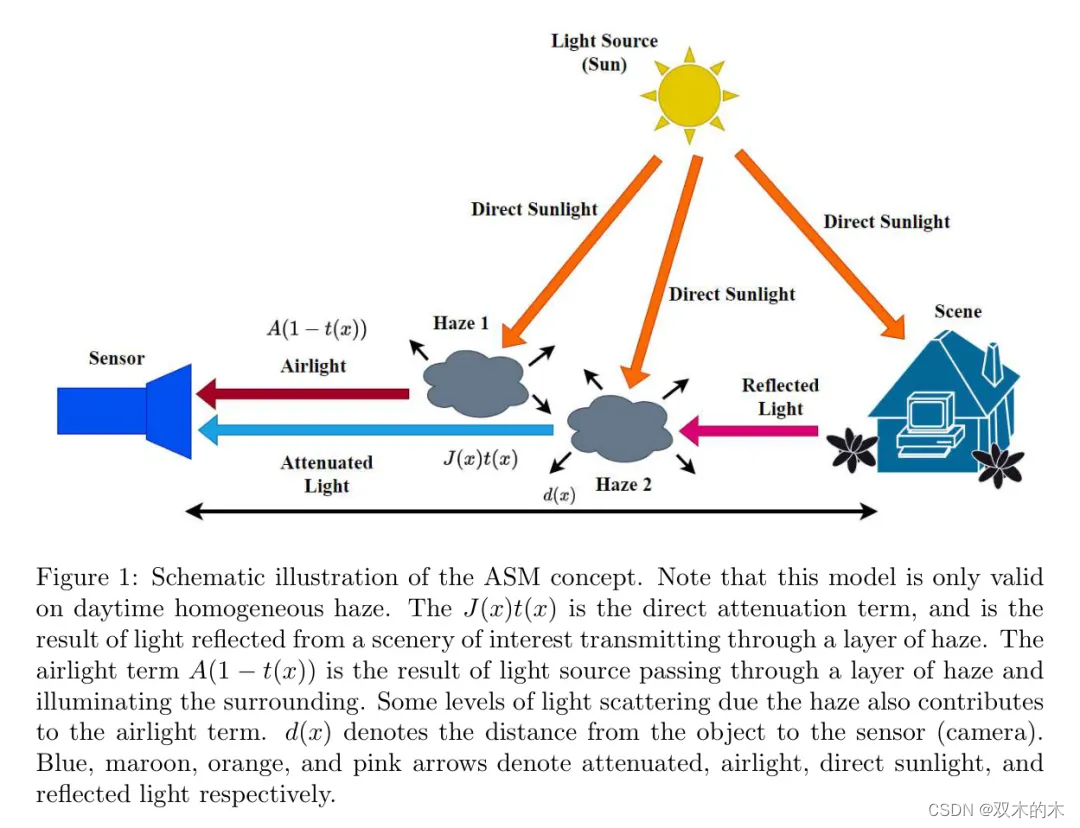
利用深度学习,去雾参数通常可以端到端计算,并且在各种雾霾场景中的性能指标通常高于基于先验的方法。通常采用大气散射模型(ASM)([1], [2]),该模型假设空气光和直接衰减主要是雾霾图像的贡献。
这种模型通常在许多去雾研究中被最普遍假设,可用于建模和生成雾霾。
早期的基于深度学习的去雾通常采用卷积神经网络(CNNs),而仅在最近几十年,才开始探索和利用视觉 Transformer (ViTs)。由于ViTs相对于CNNs的局部诱导偏差较低(因为处理的是图像块而不是像素),前者需要相对大量的训练数据以达到有竞争力的性能指标。
例如,在大型预训练数据集如JFT-300M [3]上训练典型的ViT,可以在分类任务中超越CNNs。第一个研究ViT去雾的DehazeFormer [4],通过在相对较大的雾霾数据集(例如,来自RESIDE [5]和RS-HAZE [4]的SOTS-indoor/SOTS-outdoor/SOTS-mix)上训练,获得了最先进(SOTA)性能。
此外,ViTs通常比CNNs计算需求更高,架构也更复杂,因此在没有进一步修改的情况下,可能不适用于移动和边缘设备,如无人机或自动驾驶汽车。
与此同时,利用对比学习以及零样本和单样本学习进行去雾的方法也在出现,尽管这些方法更常用于图像分类、分割和目标检测。这些方法不需要像CNN和ViT方法那样进行大规模的雾霾-清晰图像对训练,也避免了合成雾霾图像与真实生活雾霾图像信息量不足和一致性差的问题[6],这可能导致域偏移。
与大多数CNN和ViT方法不同,对比、零样本和单样本学习方法利用无监督学习,零样本学习不需要 GT (清晰)图像,只需要给定的单个雾霾图像[7]。这些方法可以在不同雾霾强度场景下实现更好的泛化,这可能对视频任务(例如,监控森林火灾、活跃火山、雨雪)是真实的。
作者意识到已经有关于去雾的回顾性论文,既有新近的也有较早的。例如,Goyal等人[8]在作者撰写本文时提供了关于各种去雾方法的最新回顾,这些方法应用于众多基准数据集。然而,讨论的数据集并未包括在远程感知和无人机、自动驾驶车辆等空中移动平台背景下的大雾图像。
对于前者,分析雾天图像对于评估自然灾害(如森林火灾)造成的损害程度至关重要,同时也需要识别热点以协助消防工作。后者可能有助于在中小雨雪情境下(可能同时出现雾)进行自主操作。Agrawal和Jalal[9]包括了各种去雾方法的数值结果,并根据是否残留雾天伪影、是否应用于浓雾场景以及是否过度增强等方面评估了各技术的性能,同时评估了每种技术推理的速度。
Gui等人[10]提供了基于深度学习的去雾综合调查和分类。后者还涵盖了对比学习和少量样本去雾工作的回顾,并讨论了去雾领域仍存在的某些挑战和开放性问题,例如去雾对图像分类和分割等高级视觉任务的影响。
然而,与Agrawal和Jalal以及Goyal等人的评论类似,这些评论仅涵盖了技术在基准数据集上的表现,并未涵盖远程感知和移动平台图像的表现。
此外,与Agrawal和Jalal的工作不同,该工作没有为各种方法在基准数据集上的定量去雾指标制作表格,这会使观察所提方法的趋势更加容易,并看出哪种方法在目前给出了最佳的除雾性能。
最后,作者注意到Liu等人[11]关于基于远程感知的去雾回顾性论文;然而,据作者所知,这是唯一一份此类论文。

与其他回顾性工作相比,作者的去雾回顾性论文的独特之处在于,作者不仅涵盖了基于深度学习和先验知识的去雾方法,这些方法不仅在基准数据集上进行评估,也应用于远程感知和无人机。与Gui等人的工作类似,作者强调了上述领域仍然存在的某些开放挑战,并就如何解决这些问题进行了广泛讨论。此外,作者的回顾还讨论了最近提出的基于先验的方法(截至2023年),这并不是许多回顾性论文的关注点。
作者认为,尽管普遍认为基于深度学习的方法更为优越,但强调最新的基于先验的方法同样重要,因为这些工作也展示了具有竞争力且前景看好的成果。这类工作的存在也表明,基于先验的去雾范式研究并未完全消失。总之,作者的回顾性论文的贡献如下。
-
据作者所知,作者的综述是少数几个涵盖在较近时期(2020年后)提出的大气去雾先验的研究,并且更为详细。如前所述,这不仅仅是为了说明基于先验的大气去雾研究尽管流行观点如此,但仍然活跃,而且还为了展示这些方法可以在相应的数据集上超越基于学习的方法,而无需事先需要大量的图像进行训练。这有助于降低计算需求,并补充了遥感应用中的去雾技术。
-
作者提供了截至作者撰写时的大气去雾最新综述工作,扩展并涵盖了2024年发表的所有不同类型的大气去雾方法,应用于不同的基准测试和选定应用。
-
作者还涵盖了超出常见基准去雾数据集的工作,包括那些在遥感和国防无人机图像中使用的方法。特别是对于前者,作者探讨了在超光谱、极高分辨率(VHR)和合成孔径雷达(SAR)图像上应用的去雾技术。据作者所知,作者的工作是首次在回顾去雾文献时强调这三个关键领域。
图像除雾:概念和原理
在本节中,作者提供了关于图像去雾原理的背景信息。


大多数去雾工作都是在包含合成雾图像的基准数据集上测试的。例如,RESIDE数据集[5]仍然是最受欢迎的去雾基准之一,包含110,500个合成雾图像。另一个流行的基准是D-HAZY数据集[16],它改编自NYU深度室内图像收藏[17],并包含超过1400个真实景象和深度图用于合成雾生成。对于涉及真实雾的数据集,通常使用专业烟雾机进行生成,这样的数据集样本量通常远低于合成雾的样本量。例如,O-HAZE数据集[18]只包含55对真实均匀雾的雾气-清晰图像对,NH-HAZE(更具体地是NH-HAZE 2020[19])包含45对真实非均匀雾的雾气-清晰图像对,DENSE-HAZE[20]包含45对真实浓均匀雾的雾气-清晰图像对。尽管RESIDE数据集包含4807个真实雾图像,但它比生成的合成图像小23倍。因此,大多数去雾方法在O-HAZE和NH-HAZE上的性能指标通常较低,而在DENSE-HAZE上则更低,与RESIDE和D-HAZY相比。
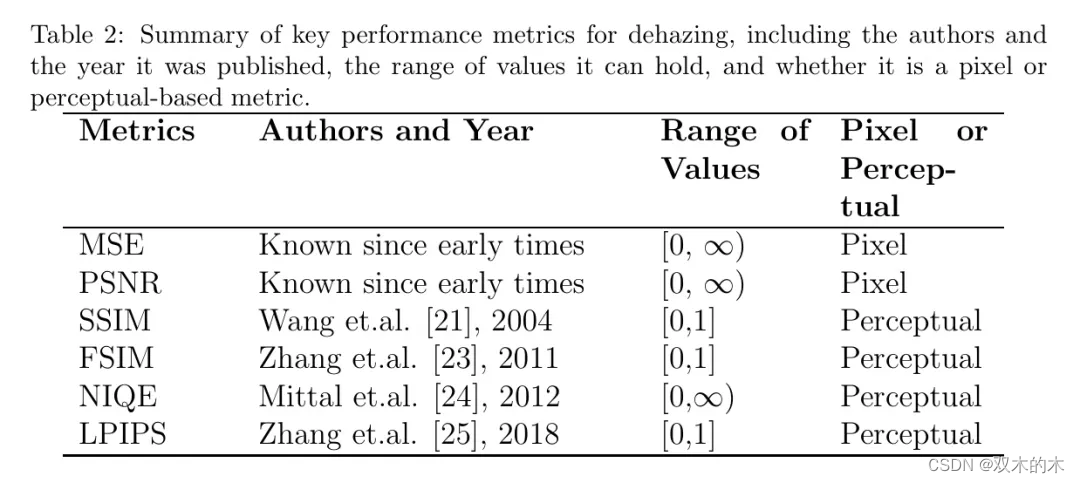
常用的除雾指标
在突出一些基于先验的除雾方法和基于学习的除雾方法(卷积神经网络、视觉 Transformer 、对比学习和小样本学习)之前,作者提供了广泛文献中常用的除雾度量的简要总结。




Dehazing方法
基于先验的图像去雾技术


密度分类先验是由Yang等人[33]在2023年提出的。这是基于观察到的雾增强了图像的亮度,并且通过计算通道差异可以确定雾的密度。这在数学上如下所示:


用于图像去雾的深度学习方法

如前所述,在作者的回顾中,基于学习的去雾方法可以分为基于CNN的去雾、基于ViT的去雾以及对比性和小样本去雾。
基于CNN的图像去雾
蔡等人[36]提出了DehazeNet,可以说是最早的基于CNN的端到端去雾网络之一,该网络仅需要ASM指导下的模糊-清晰对应图像对。他们的网络引入了双边整流线性单元(BReLU),基于作者观察到的ReLU可能不适用于回归问题(如去雾)。BReLU保持了双边约束和局部线性,这减轻了图像恢复问题中最后一层的响应溢出问题,对于最后一层的输出值,在小范围内需要在上限和下限之间进行限制。他们的网络仅由四个CNN层组成,需要学习的网络参数包括每层的滤波器和偏置。
李等人[37]引入了All-in-One Dehazing Network(AOD-Net),这是最早的轻量级CNN与ASM结合的网络之一。AOD-Net使用了一个修改后的ASM公式,由以下式子描述:

任等人[38]引入了一个多尺度CNN(MSCNN)用于单图像去雾,该网络使用了一个粗糙细节网络,整体估计模糊图像的传输图,以及一个精细细节网络,该网络在局部范围内细化粗糙网络输出的去雾结果。粗糙网络和细粒度网络都由卷积层、最大池化层和上采样层按顺序排列组成。在各自的中间输出被送入线性组合层之前,两个网络中都有三套这样的组合。据作者所知,这是第一个强调通过结合细粒度结构进行细节恢复的去雾工作,这种结构通常用于相关的图像去雨工作,但在去雾文献中关注较少。

Liu等人[40]提出了GridDehazeNet,一个基于网格网络的多尺度估计,通过注意力机制减少了传统多尺度技术中常见的瓶颈问题。与其他迄今为止描述的技术不同,GridDehazeNet不依赖于ASM。他们的网络包括预处理模块、 Backbone 模块和后处理模块。预处理块包含残差密集块(RDB)以及没有激活函数的卷积层。从有雾图像中,它创建了16个特征图,这些被称为学习输入。 Backbone 模块使用改进的GridNet [41],后者最初用于语义分割。使用预处理模块提供的学习输入,实现了基于注意力的多尺度估计。
与仅包含RDB的预处理模块不同, Backbone 模块包括下采样和上采样模块,以及基于注意力的特征添加。最后,后处理模块通过消除伪影来提高去雾图像的质量,其算法架构与预处理模块对称。后者模块的工作方式类似于MSCNN中的精细细节网络。
张和帕特尔[42]提出了一种金字塔架构,名为Densely Connected Pyramid Dehazing Network(DCPDN)。该网络可以同时学习传输图、 airlight和去雾任务,并融入了密集连接的编码器-解码器结构,以最大化信息流并利用来自不同层的特征来估计传输图。因为传输图和去雾图像的结构高度相关,所以使用了基于GAN的联合判别器来确定配对样本(传输图和去雾图像)是否来自同一数据分布。这项研究也融入了ASM。
考虑到编码器和解码器中的互补信息,以及修改不同尺度局部梯度的瓶颈残差块层,Yi等人[43]提出了一种多尺度密集跳跃连接去雾网络(MSNet),扩展了传统的U-Net架构。该网络还包含了一种跨尺度特征复用机制,允许以端到端的方式更好地学习I(x)和J(x)之间的内在关系。在编码器阶段,有多个下采样跳跃连接,而在解码器阶段,有多个上采样跳跃连接。他们的网络没有包含ASM。
有方法利用知识蒸馏(KD),这涉及一个教师-学生模型,其中教师模型将其知识或权重传递给学生模型,以确保在更高的计算效率或较小的样本量下实现最佳性能。Hong等人[44]提出了一种知识蒸馏去雾网络(KDDN),该网络通过异构任务模仿进行网络蒸馏。
教师网络具有一个现成的自编码网络用于图像重建,学生网络模仿教师网络的任务。学生网络还设计了一个空间加权残差通道注意力块,以自适应地学习上下文感知的通道注意力。该 Proposal 的网络中没有使用大气散射模型。Lan等人[45]提出了一种在线知识蒸馏网络(OKDNet),该网络在利用包含基于注意力的残差密集块的多尺度网络获取共享特征之前,先对输入的模糊图像进行预处理。然后,将中间特征输入到不同的分支中。第一个分支用于通过ASM估计去雾图像,而另一个分支则在没有模型的条件下将模糊图像和真实图像相关联。最后,使用聚合块来有效地融合两个分支的信息,联合优化执行在线一阶段KD。Deng等人[46]引入了雾觉表示蒸馏GAN(HardGAN),其实施雾觉表示蒸馏(HARD)模块不仅包括归一化层,还通过雾觉图注意地将不同雾强度引起的空间信息和环境光进行聚合。GAN网络用于直接学习风格转换映射。
所有上述方法对于均匀雾的表现都很好,但可能不适用于非均匀雾(如NH-HAZE[19])和浓雾(如DENSE-HAZE[20])。这是因为单一的神经网络去雾模型无法模拟不同的雾强度。集成学习已被证明可以减少神经网络的方差,这意味着集成模型的表现可能优于最佳的单一神经网络模型。鉴于这一点,Yu等人[47]首先引入了EDN-3J,它包含一个共享的密集编码器和四个密集解码器模块。
其中三个解码器以加权的不同方式输出使用不同重建损失函数获得的独特的值。最后一个解码器有效地生成了用于组合三个解码器输出的权重图。其次,他们引入了EDN-AT,在末端包含了ASM,其配置与EDN-3J相同,但有两个解码器输出环境光图,一个解码器输出大气透射图。最后,他们还提出了EDN-EDU,它由密集编码器、解码器和U-Net的顺序集成组成。这里的目的是将具有不同能力的编码器-解码器网络级联起来,使其能够很好地推广到复杂的雾场景。
Yu等人引入了一个双分支基于CNN的神经网络,其中第一个分支是已经使用ImageNet进行预训练的迁移学习网络。其目的是由于缺乏大规模非均匀雾数据集而减轻过拟合,并提供鲁棒的迁移学习特征。第二个分支涉及通过残差通道注意力网络(RCAN)构建的当前数据拟合子网,它通过不包含任何下采样模块来保持输入的原始分辨率,从而保留了输入的更精细的细节特征。在集成策略的末尾包含了一个融合尾。本研究中没有包含ASM。
江等人引入了一种深度混合网络。江等人(2019)再次考虑了如MSCNN中的细节细化以及去雾处理。对于去雾,采用了挤压和激励(SE)块张等人(2019),并构成了它们的风雾残留注意力子网络分支。细节细化子网络分支以去雾后的图像作为输入,并利用多尺度上下文信息聚合。通过联合训练这两个分支,可以在不牺牲细节和引入不希望的艺术效果的情况下实现有效的去雾。
最近也有利用图卷积网络(GCN)进行去雾的研究。例如,胡等人胡等人(2019)提出了一种结合了CNN和GCN的网络,以捕捉局部和全局的雾特征。将三元注意力模块整合到CNN结构中,以强调对局部特征的权重,而双重GCN模块被整合以融合空间连贯性与通道相关性以提取全局特征。他们的整体架构受到了U-Net的启发。
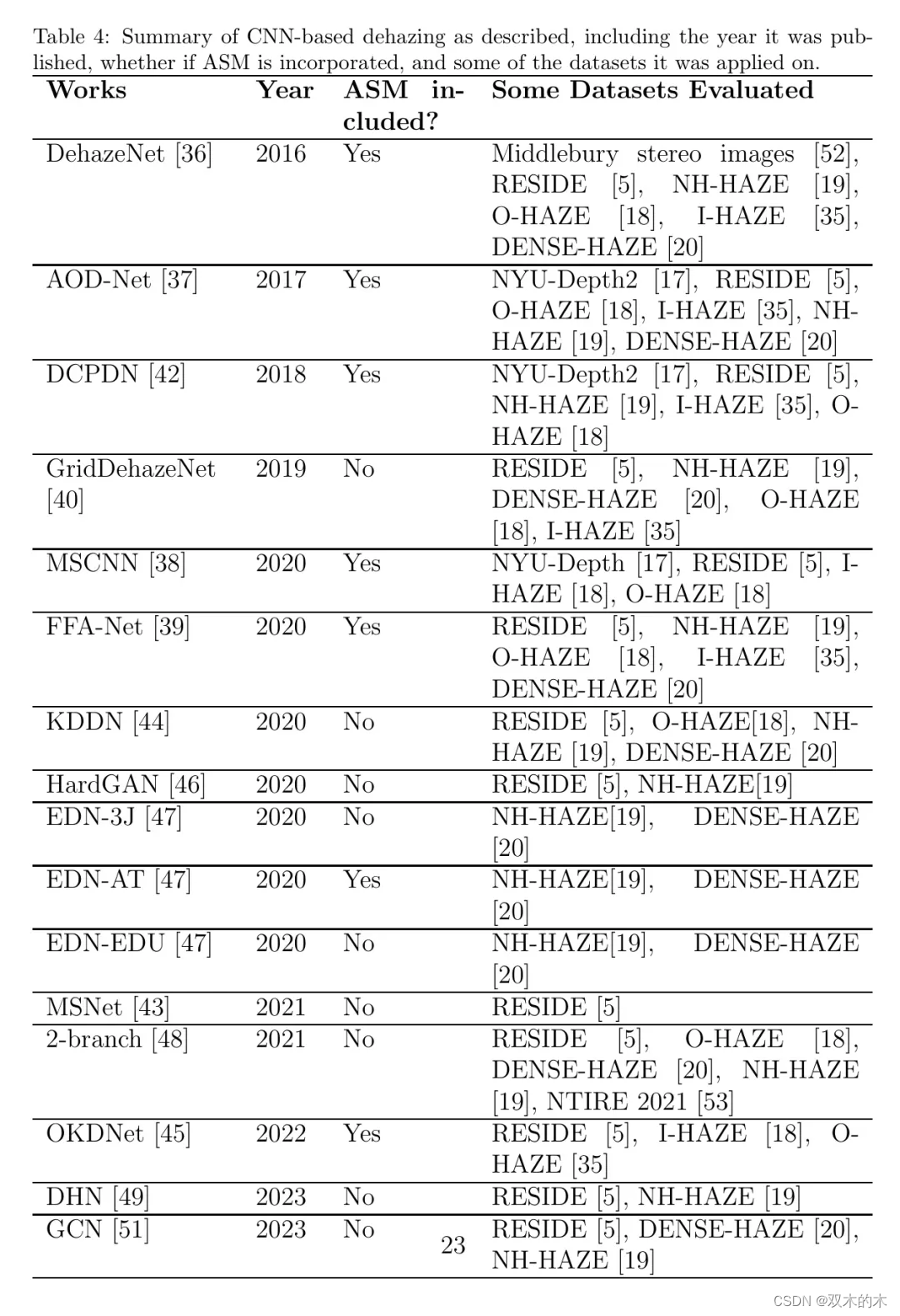
表4总结了迄今为止所涉及的基于CNN的去雾方法,以及这些工作的发表年份、是否融入了ASM,以及评估这些工作的一些数据集。
基于ViT的图像去雾
最早基于ViT的去雾方法之一是由Song等人提出的DehazeFormer。Song等人(2019)利用了swin Transformer 架构Song等人(2019),以及一个修改后的规范化层(该层使用重缩放规范化而不是通常的层规范化),一种空间信息聚合方案,以及一个修改后的激活函数(软RELU而不是GELU和RELU)。这些修改是因为作者观察到使用典型的规范化层和激活函数会降低ViT在去雾任务中的性能。他们测试了DehazeFormer的不同变体,特别是DehazeFormer-T,DehazeFormer-S,DehazeFormer-B,DehazeFormer-M和DehazeFormer-L,发现DehazeFormer-M和DehazeFormer-L在所有评估的数据集上性能最佳。此外,他们还引入了RS-HAZE,该RS-HAZE从遥感的角度出发,包括高级云和雾的去除。
Wasi和Shiney [55]提出的DHFormer在注意力模块中利用了残差学习和ViT,并包含两个网络。第一个网络使用有雾图像与透射矩阵的比率来得到残差图。第二个网络利用该图,通过多个卷积层,并将中间输出叠加到生成的结果特征图上。最后,使用全局上下文和深度感知的变换编码器来获得通道注意力,这可以用来推导出空间注意力图,得到最终的去雾图像。
Guo等人[56]提出了Dehamer,这是首次将CNN与ViT结合用于去雾的工作之一。他们建议在CNN捕获的特征上进行特征调节技术,以解决CNN与变换模块之间的特征不一致问题。这使得他们的程序能够同时继承CNN的全局特征建模能力和 Transformer 的局部特征建模能力。Zhao等人[57]提出了一种基于Hybrid Local-Global(HyLoG)注意力的架构,该架构结合了局部和全局变换路径,同时捕捉图像中的全局和局部特征依赖。引入了互补特征选择模块(CFSM)以自适应地选择去雾任务的重要互补特征。Bian等人[58]提出了Swin Transformer U-Net架构(ST-UNet)用于有效去雾,同时显著增加了处理时间。在预测工作流程中也使用了并行处理和数据结构修改,以最大化计算资源。这是少数几个应用于遥感视角下去雾图像,用于地震后场景评估和分析的去雾工作之一。
池等人提出的Trinity-Net [59] 结合了先验和基于深度学习的策略来恢复真实的表面信息。一个利用梯度图中的结构先验的梯度引导模块,允许生成视觉上令人愉悦的去雾输出。同时使用了CNN和ViT架构来解释先验信息,并合理估计雾参数。该研究还受到军事领域数据稀缺的启发,促使他们开发了一个遥感图像去雾基准(RSID)和一个自然图像去雾(NID)基准,以与SOTAs对比评估他们的工作。
张等人引入了深度引导变换去雾网络(DGDTN)[60],该网络结合了CNN以捕捉局部信息,同时 Transformer 捕捉长距离依赖。还使用了引导滤波器以加快去雾处理时间。刘等人提出了一个结合了视觉 Transformer 和生成对抗网络的ViTGAN网络[61]。鉴别器和生成器网络都使用了ViT架构;然而,由于训练可能不稳定,因此使用了生成器结构优化和鉴别器正则化。李等人提出了一种两阶段去雾网络,其中包括一个swin Transformer [62],该网络在编码器和解码器模块之间包含一个块内监督机制,用于特征细化、监督和选择,从而提高传输效率。此外,在网络架构的不同阶段之间增加了融合注意力机制,以确保第一阶段特征信号的传输真实性,并进一步精化模型的效率。
张等人提出了一种基于 Transformer 的去雾小波网络(WaveletFormerNet)[63],该网络将离散小波变换(DWT)融入ViT中,并引入了WaveletFormer和IWaveletFormer块以减少由于下采样导致的纹理细节损失、色彩伪影和失真。 Transformer 块中还包括了平行卷积,允许在不堆叠卷积块的情况下捕捉关于图像频率的多种信息,从而提高模型的效率。还使用了特征聚合模块(FAM)以增强特征提取功能同时保留分辨率。
与基于CNN的方法类似,集成学习也已被用于 Transformer 架构。例如,由Hoang等人提出的TransER [64],它包括在第一阶段使用TransConv融合去雾(TFD)模型,在第二阶段使用轻量级集成重建。TFD模型是一个基于集成的架构,包括一个共享的基于ViT的编码器,其布局受到TransConv模块的启发,以及三个具有与U-Net类似的跳跃连接的独立对应解码器。通过选择性 Kernel 融合(SKF)[65]将编码器和解码器特征图中的众多注意力通道连接起来,这已被证明比典型的拼接更有效。在第二阶段实施知识蒸馏(KD),将教师网络中学到的权重提炼到学生网络中,以更好地利用中间特征图,进而利用TRN中无雾图像的分布。最后,引入了轻量级集成重建(LER)作为一个集成重建网络,包括两个编码器和一个编码器,并自适应地使用门控卷积模块(GCM)进行特征图的提取和组合,以最大化信息的保留。
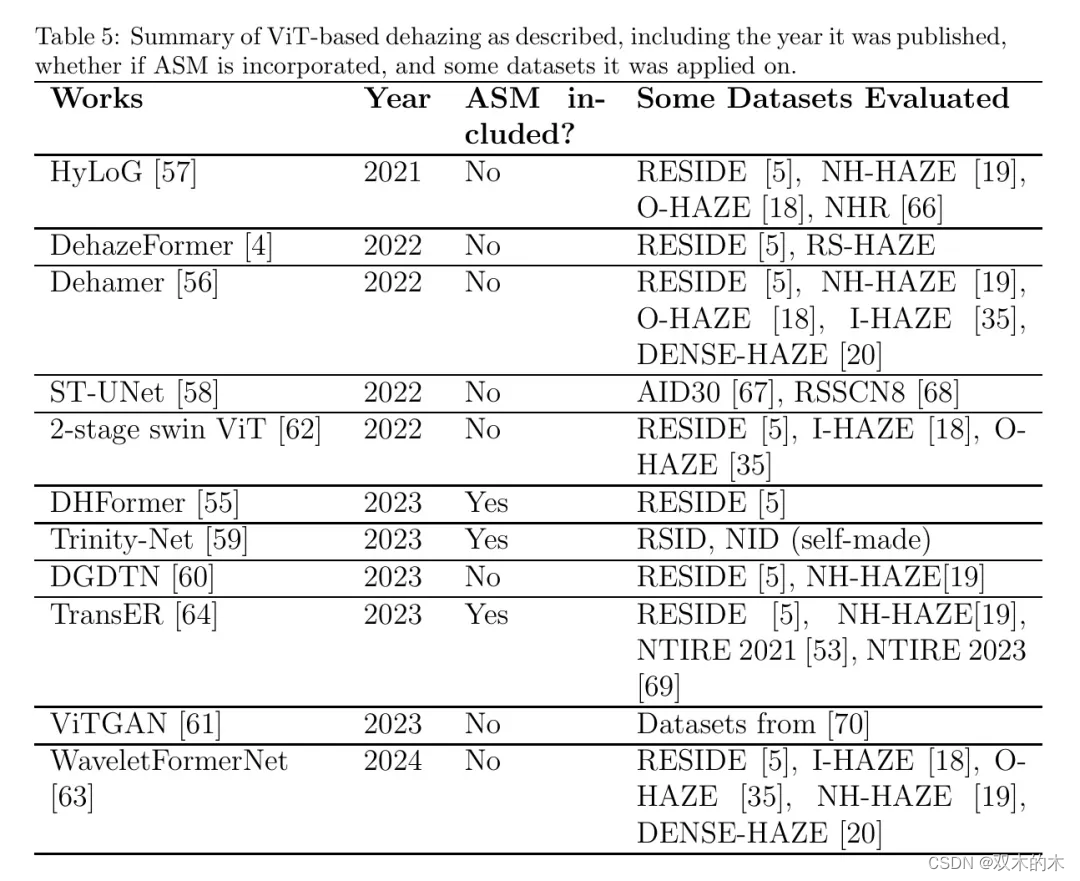
表5总结了上述基于ViT的去雾方法,以及这些工作的发表年份、是否融入了ASM以及评估这些工作的一些数据集。作者可以立即观察到的一个趋势是,基于ViT的去雾方法已经开始受到关注并在2021年后被更多地融入,随着2023年在这个方向上工作的增加,如下表所示。
图像去雾的对比学习
吴等人提出的AECR-Net [71] 将类似自动编码器的结构与对比正则化相结合,该方法受到了三元损失网络的启发。在他们的工作中, Anchor 图像是去雾图像,正图像是 GT 清晰图像,负图像是原始雾天图像。损失函数的设计使得嵌入的 Anchor 和正图像特征尽可能接近,而嵌入的 Anchor 和负图像特征尽可能远离。从数学上讲,这表现为重建损失和正则化项的和,如下所示:

利用对比解缠学习(CDL),陈等人 [72] 提出了一种基于非配对学习的去雾范式,将问题视为一个两类分离因子的解缠任务。提出了一个循环GAN框架,通过将生成的图像与潜在因子相关联来指导解缠表示的学习。生成器用于生成负对抗样本,然后以端到端的方式与代表性网络一起训练以更好地获取所需的信息以进行区分,从而通过优化对抗对比损失来提高解缠因子。他们的实验还表明,硬负样本可以抑制与任务无关的因子,而非配对的无雾样本可以提高与任务相关的因子,这些共同提高了去雾性能。
王等人 [73] 提出了一个分层对比去雾(HCD)范式,利用特征融合和对比学习。分层交互模块利用多尺度激活来利用网络中的特征层次结构并修正它们的响应。一个新颖的分层损失函数在成对样本上进行对比学习,指导图像去雾。 Bai和Yuan [74] 在小波域中引入了低频子带对比正则化(LSCR)模块。他们的动机是现有的去雾方法忽略了一个事实,即雾的外观主要影响图像的低频分量,这意味着对不同分量进行了无差别处理,导致去雾效果较低。通过利用这些方法,受雾影响很大的 Anchor 图像分量被拉近到接近 GT 图像,同时推离雾天图像。同时还引入了高频子带损失,以确保去雾图像的高频分量与 GT 图像一致。
郑等人 [75] 引入了课程对比正则化,用于物理感知的去雾,该方法试图使对比去雾任务达成共识(即通过将原始雾天图像与其他方法得到的去雾图像混合,增加负样本的多样性)。
这缓解了仅将原始雾天图像作为下界约束的解空间约束不足的问题。更具体地说,负样本被分为三个难度 Level :简单(E),困难(H)和超困难(U),其中原始雾天图像被分类为E,并使用粗略策略来区分其他两种情况。然后为上述负对分配不同的权重,并实现了一个物理感知的双分支单元(PDU),它使用基于物理的先验在双分支中近似环境光特征和透射图,从而比仅使用ASM更精确地合成潜在清晰图像的特征。他们的C PNet以级联 Backbone 的方式实现了PDUs。
少样本去雾算法
李等人引入的零样本图像去雾(ZID)范式[7]利用了层分离的假设,意味着可以将图像视为由许多简单层纠缠在一起。对于有雾的图像,可以将其看作是无雾图像、透射图和环境光三个层纠缠在一起形成有雾图像。所提出的ZID使用了三个联合子网络,J-Net、T-Net和A-Net,将输入分离为这三个层,并随后估计有雾参数并恢复无雾图像。他们的方法是一种特殊的零样本方法,因为它只利用观察到的单个有雾图像中的信息,并不需要在数据集上训练。这与其他视觉任务中的典型零样本学习不同,后者需要一个经过训练的模型来推理未见过的类别。因此,ZID可以避免费力的数据收集,同时由于使用合成有雾图像来处理真实世界的有雾场景,还可以避免领域偏移问题。
卡尔等人[76]提出了一种估计ASM参数以执行图像去雾的零样本网络。这是基于他们的观察,即合适的图像退化意味着ASM参数的有控制扰动,这些参数描述了原始未扰动图像与输入图像之间的关系。通过优化过程实现零样本学习,该过程保持从输入及其退化形式获得的ASM参数对之间的前述关系。
他们的方法还使用真实世界的水下图像进行评估,这些图像显示出不同程度的对比度和颜色。另外一项研究由韦等人[77]提出,结合了层分离范式与他们的新型再退化雾霾模型进行零样本去雾,并使用遥感图像评估了他们的方法。

表6总结了迄今为止讨论的对比和少样本基础去雾方法,以及工作发表年份、是否融入了ASM以及评估该工作的部分数据集。
图像去雾技术的比较分析
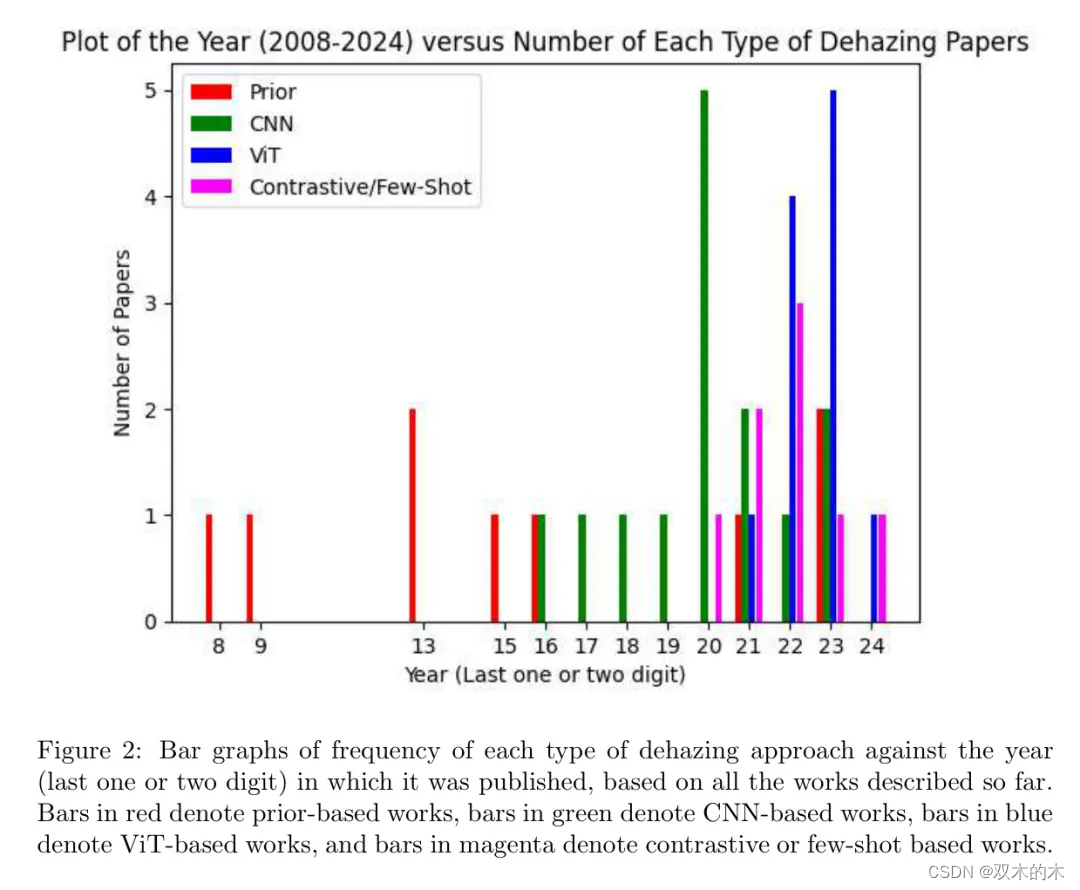
图2展示了基于迄今为止所描述的所有工作,每种去雾方法的频率与发表年份的条形图。这些年份从2008年跨度到2024年。作者可以立即观察到,基于CNN的去雾方法在2016年开始受到关注(在此之前,基于先验的去雾工作占主导地位),并在2020年代基于此类论文的发表频率上受到了最多的关注,而ViT和对比性/小样本去雾方法从2021年到2023年获得了越来越多的认可。
基于ViT的去雾方法在2023年的数量激增,从视觉上直观地表明人们关注的重点从使用CNN转向了ViT进行图像去雾,这是由于其新颖性以及与基于CNN的方法相比具有前景的结果。同样的论点也适用于对比性/小样本去雾工作。由于2024年是撰写本文的当年,相应发表的作品数量显然较低,但作者预见到这类论文的数量将会持续增加。基于迄今为止的回顾,以下是一些讨论点:
-
虽然关于使用卷积神经网络(CNN)架构方法利用图卷积网络(GCN)的研究很少,但目前几乎还没有将GCN与视觉Transformer(ViT)架构结合用于去雾的研究。除了暗示一个可能和潜在的未来研究方向外,利用图表可以提供关于图像的全局或局部信息。对于局部信息,它们的交互可以通过无向图邻接矩阵来定义,并且为了将这种局部性融入到ViT中,一种方法是插入一个谱GCN通过矩阵乘法进行简单的局部特征提取,并将其与SE块结合以在ViT的前馈阶段建模通道间的相互依赖性[82]。对于全局信息,可以修改Hu等人[51]描述的双GCN模块以适应ViT架构。
-
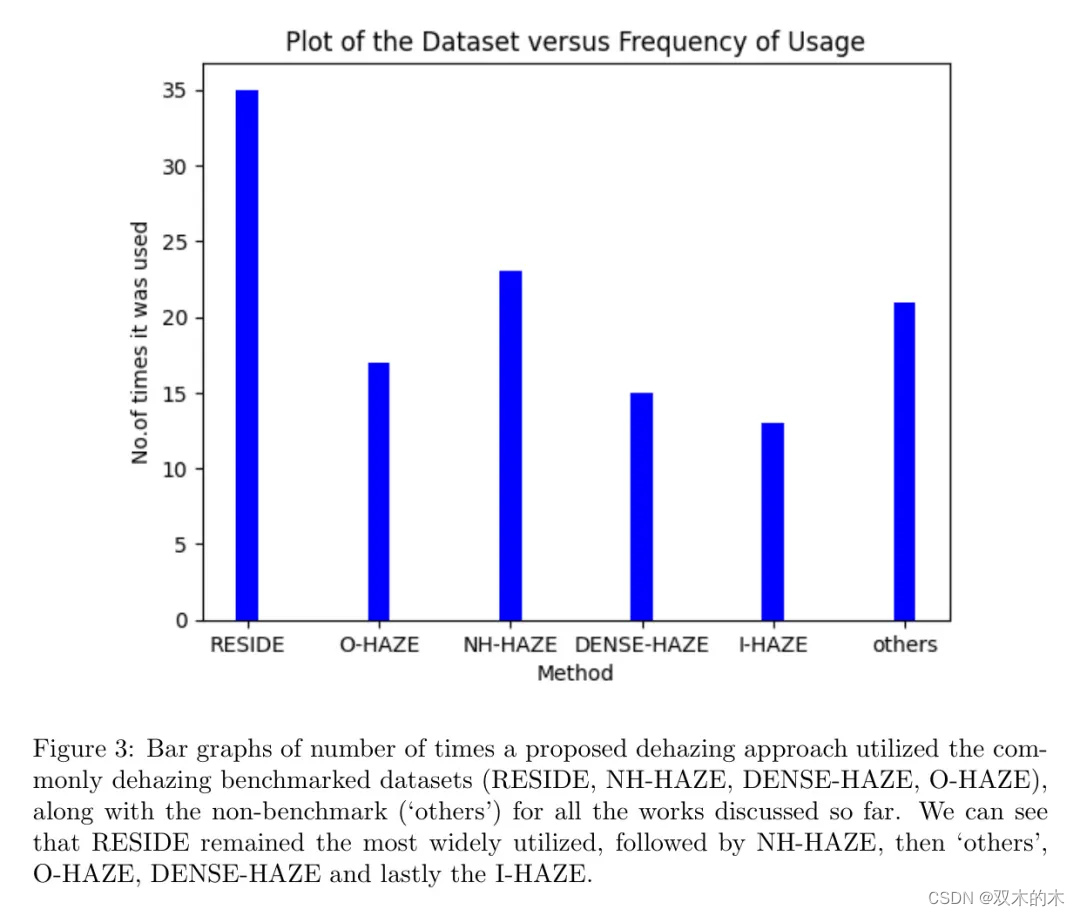
无论提出哪种去雾方法,RESIDE数据集仍然是评价中最受欢迎的基准数据集。如引言中所述,它是第一个大规模图像去雾数据集之一,包含110,500个合成雾天图像和4807个真实雾天图像,因此即使是基于ViT的方法也能通过它们获得很高的性能指标。O-HAZE、NH-HAZE和DENSE-HAZE也是紧随其后被高度利用的基准。图3展示了根据作者目前的回顾,每种去雾基准的使用频率条形图,其中“其他”表示上述未提及的数据集。从图中作者可以定量地展示作者之前提到的观点,即RESIDE是最常用的基准,其次是NH-HAZE,然后是“其他”,O-HAZE,DENSE-HAZE,最后是I-HAZE。
-
被归类为“其他”的评价数据集数量的增加表明新兴的研究工作已开始超越上述基准,使所提出算法的评价更加全面。一些研究,如Wei等人[77]的研究和由Bian等人[58]提出的ST-UNet,已经应用于遥感去雾,这表明人们越来越关注去雾的适用性,而不仅仅是将提出的算法与其他算法在基准数据集上进行比较。
基准数据集的性能评估:NH-HAZE, DENSE-HAZE, I-HAZE和O-HAZE
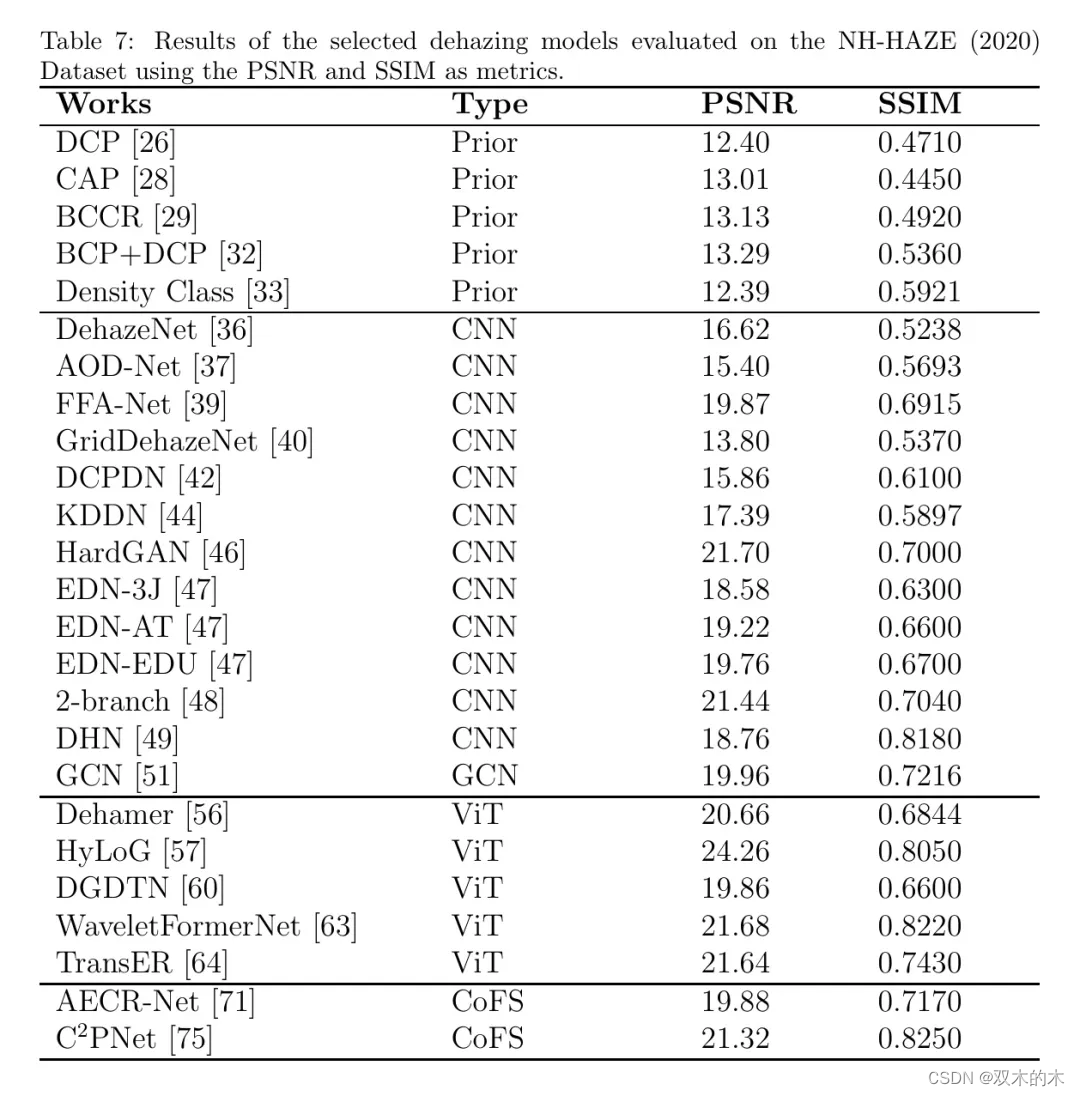
表7、8、9和10分别展示了所选方法在NH-HAZE(2020)、DENSE-HAZE、O-HAZE和I-HAZE上的去雾指标对比。
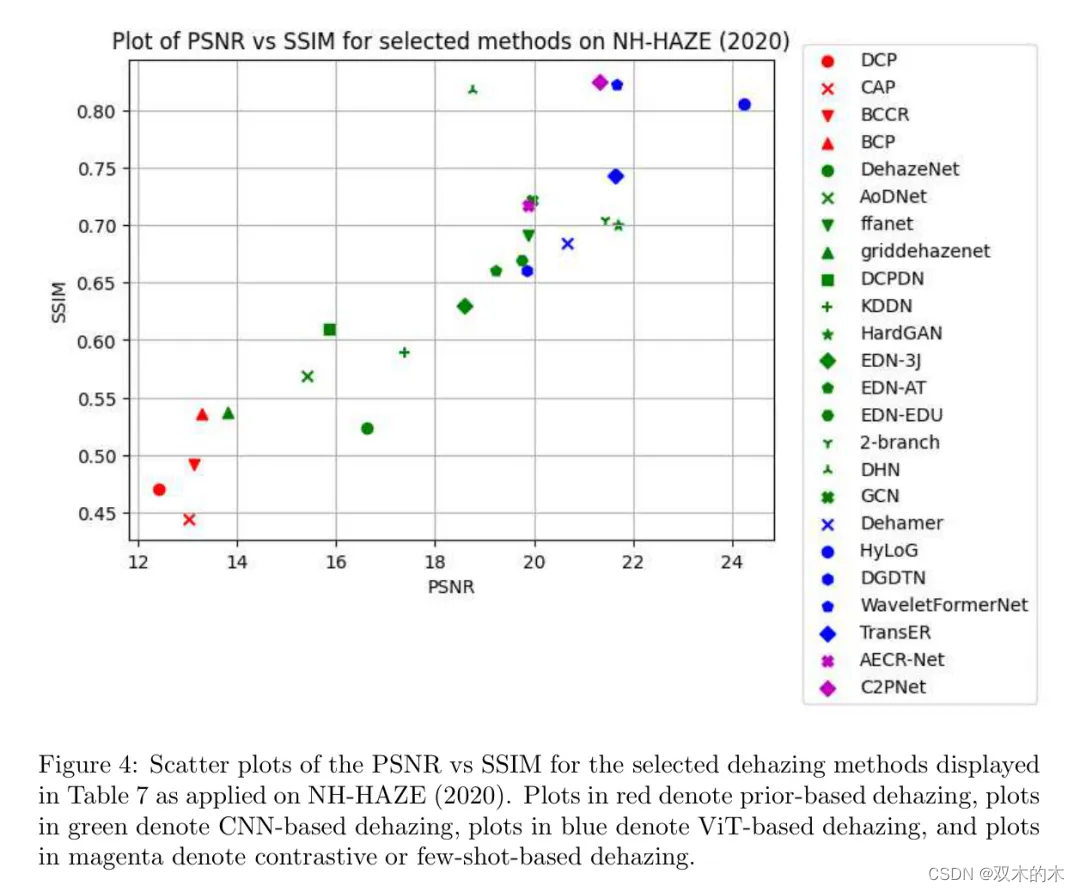
对应的数据库中方法的PSNR与SSIM的绘图分别展示在图4、5、6和7中。
作者选择2020年提出的NH-HAZE基准进行数值比较,因为它相对于2021和2023版本是最广泛使用的非均匀雾气数据集。作者可以观察到的第一个趋势是,对于所有描述的数据集,基于ViT的方法在PSNR与SSIM图的高端位置,相对于一般的基于CNN的去雾方法,显示了其有希望且优越的去雾能力。
基于先验的方法通常不如其他方法,这在NH-HAZE散点图中最为明显。对比方法和少量样本方法根据所使用的数据集类型显示出混合的结果。
对于NH-HAZE和DENSE-HAZE,一些方法,如CPNet通常在一般基于CNN的去雾方法中表现更好,而其他方法,如AECR-Net在NH-HAZE中的表现优于DENSE-HAZE。在O-HAZE中,所选方法相对于基于ViT的方法表现不佳。然而,对于I-HAZE,对比方法和少量样本方法在PSNR方面表现优于基于CNN的去雾方法,但不是SSIM。
作者可以明显观察到的第二个趋势是,从DENSE-HAZE获得的数值结果普遍低于O-HAZE、I-HAZE和NH-HAZE的结果,无论采用哪种去雾方法。DENSE-HAZE的原始数据集作者指出,该数据集旨在测试SOTA去雾架构的极限,并专注于浓雾去除问题。这个数据集上获得的最高PSNR和SSIM是WaveletFormerNet,分别为16.95和0.5930。据作者所知,没有现有的工作将PSNR和SSIM值分别推到18.00和0.6500以上。尽管在这种情况下视觉输出并不令人满意,但它可能为实现有效的浓雾去除算法奠定了第一步,这对于在极端雾气场景下(如严重的森林火灾)通过RGB光谱分析景象的遥感卫星和无人机可能很有用。这可以补充来自红外传感器数据的相应分析,因为红外辐射由于其较低波长而能轻易透过浓雾,更容易获得。
基于RESIDE基准数据集的性能评估
RESIDE数据集稍微复杂一些,因为评估或测试图像子集可以分为三个子集,即合成客观训练集(SOTS),可以是室内(SOTS-Indoor)或室外(SOTS-Outdoor)图像,或者是混合主观测试集HSTS。
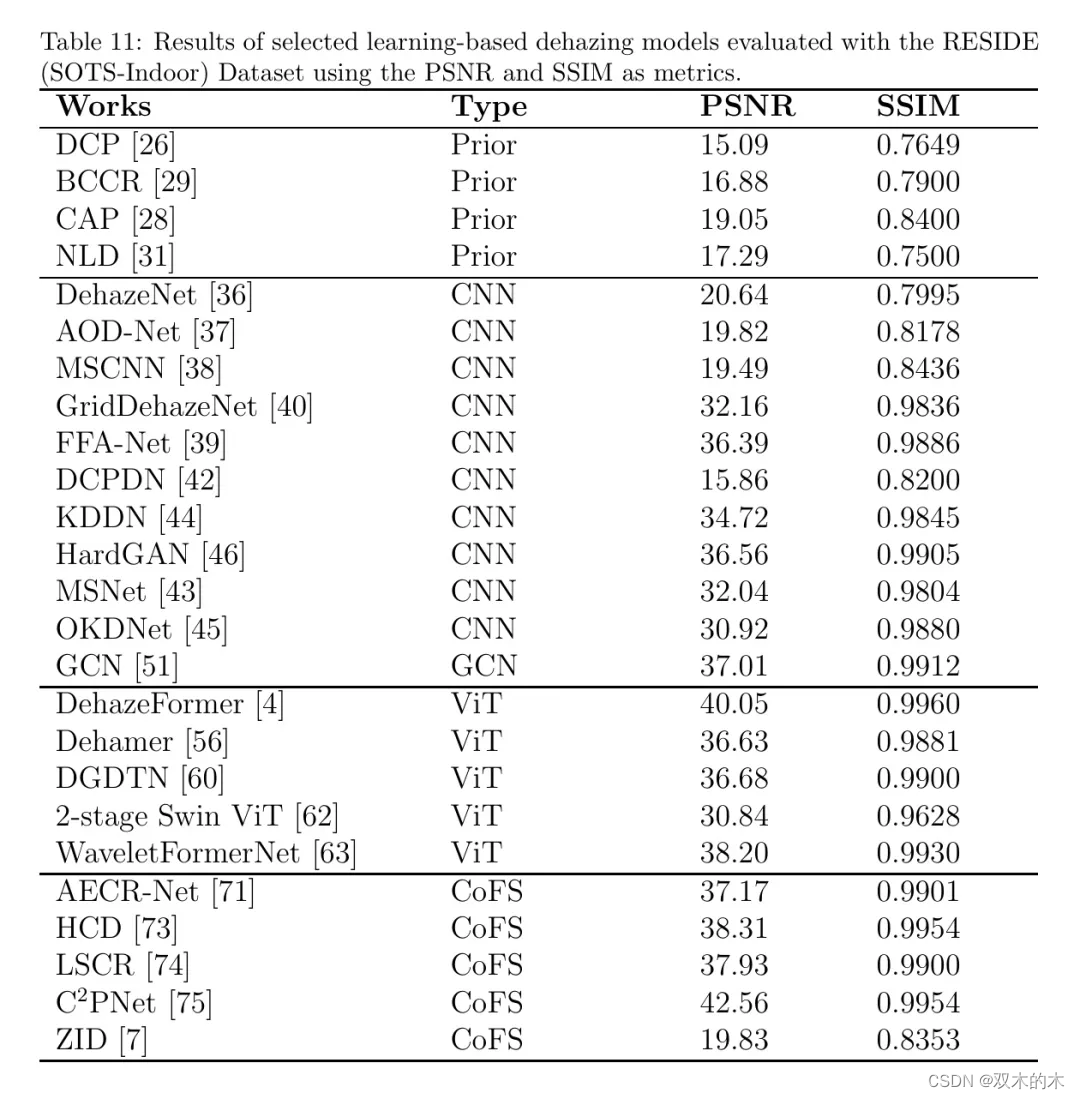
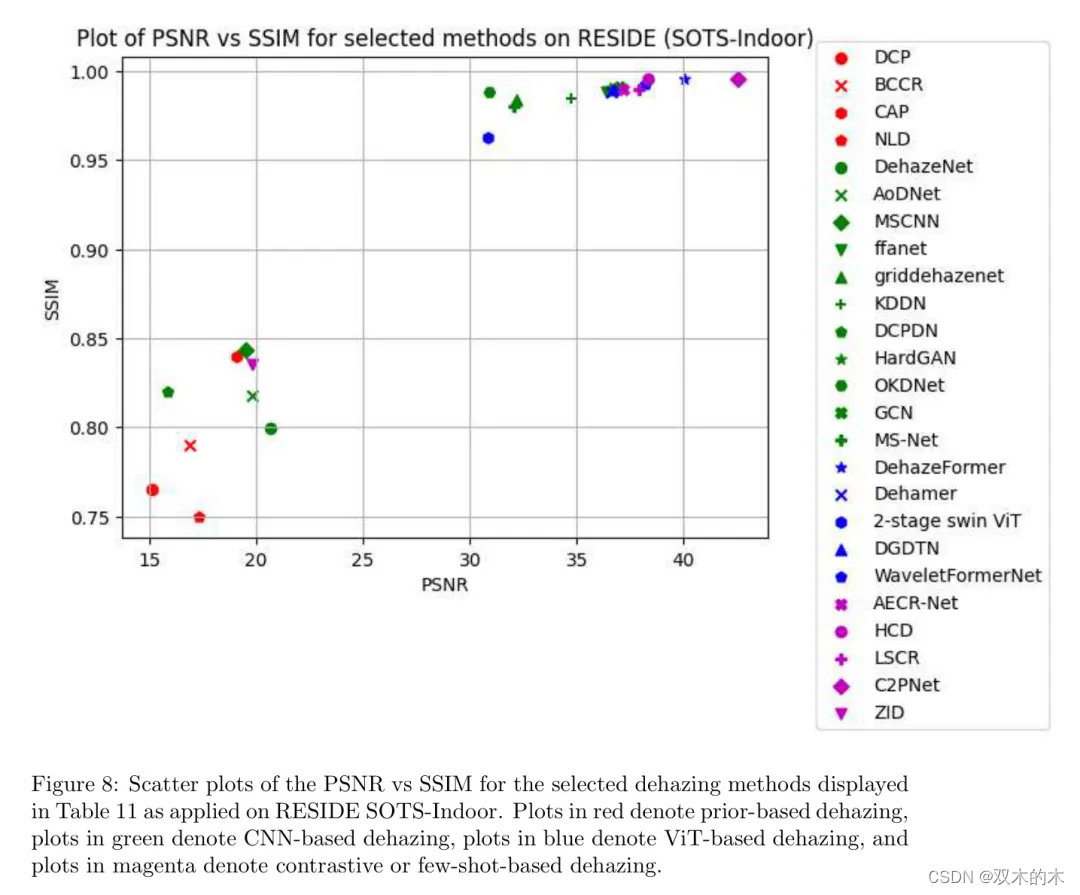
表11和图8分别展示了选定方法在SOTS-Indoor上的数值PSNR和SSIM值的表格以及相应的PSNR与SSIM散点图;
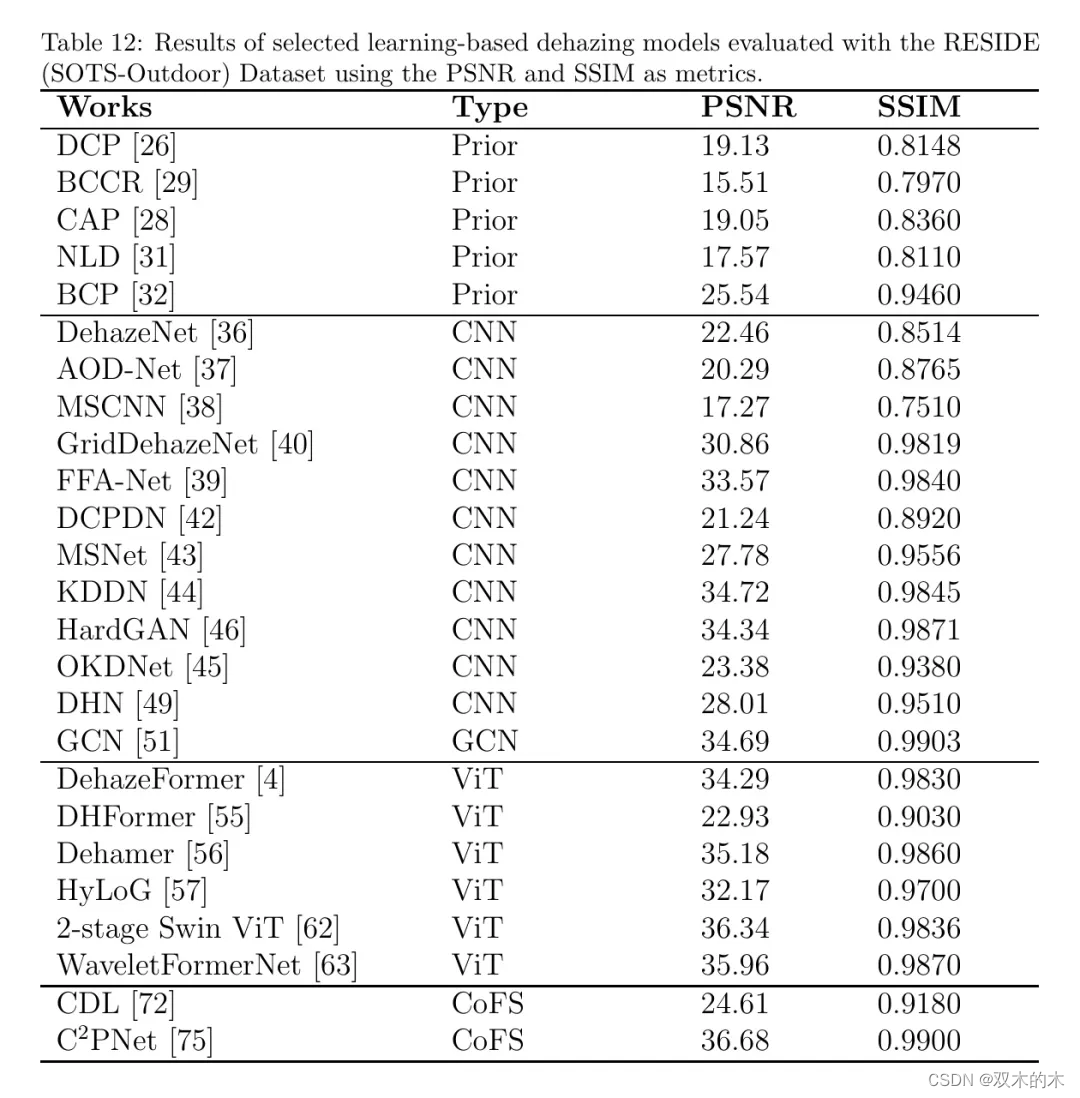

而表12和图9分别展示了SOTS-Outdoor上的对应表格和散点图。除了观察到大多数方法相对于先前数据集在两个RESIDE子集上报告了更优的度量值之外,在这种情形下,基于CNN的去雾与基于ViT的去雾以及对比/少样本去雾竞争以达到最佳去雾性能。
此外,即使是基于先验的方法也能产生高的度量值,BCP在SOTS-Outdoor上达到了PSNR = 25.54和SSIM = 0.9460的新纪录,与许多基于学习的方法相媲美。
这可能是因为RESIDE中的雾气强度较轻且分布比其他数据集更加均匀,使得即使是典型的CNN方法也能更容易、更有效地进行去雾。然而,正如我们在“去雾方法”一节中所说明的那样,大多数提议的方法都没有利用 ASM,而是以端到端的方式进行去雾。因此,这也有助于解释为什么最近人们将大量的研究重点投入到设计端到端的去雾架构上。
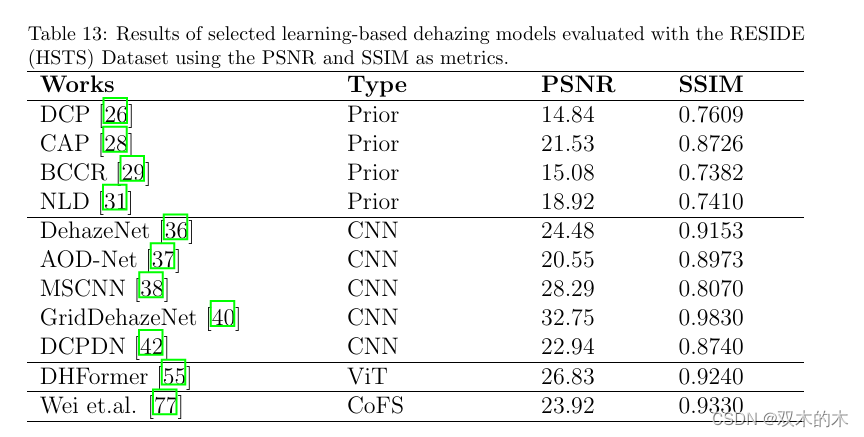
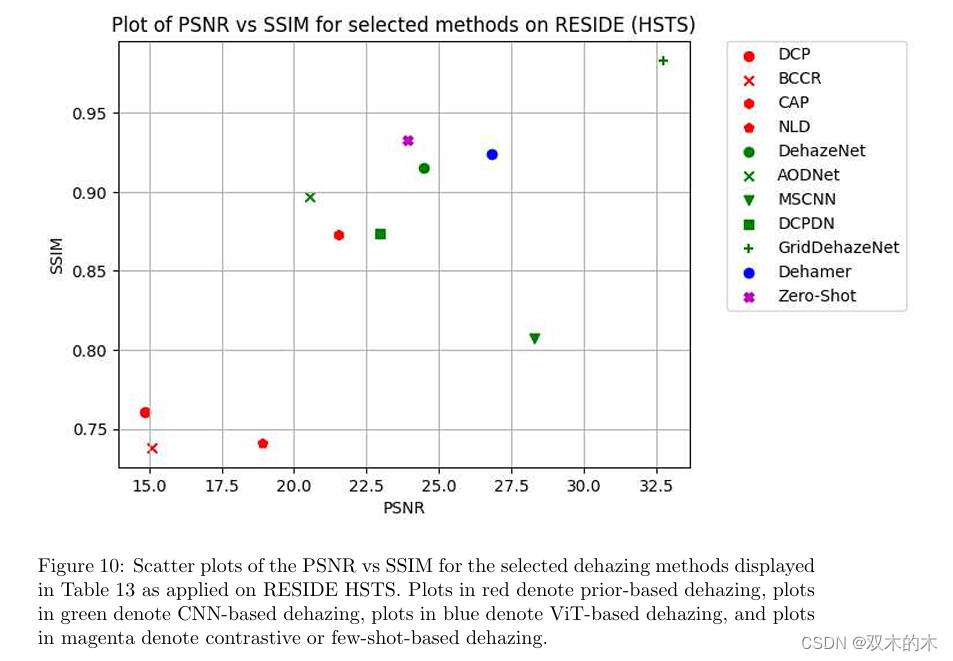
表 13 和图 10 显示了 HSTS 的表格值和散点图。由于相对于其他 RESIDE 子集,用于评估的方法相对较少,因此在这种情况下,我们无法概括哪种去雾化方法最好,但我们可以再次观察到Dehamer 是这里唯一基于 ViT 的方法,相对于所有基于先验的作品和大多数 CNN,它产生了高性能指标,除了 GridDehazeNet 和 MSCNN 在 PSNR 方面。[77],这是该子集中突出显示的唯一对比/少镜头方法,具有 SSIM值较高,但PSNR值低于Dehamer。
结论
本文综述了图像去雾研究的最新进展,重点介绍了遥感和无人机图像去雾的研究进展。雾霾会严重降低这些领域的图像质量和可解释性,因此除雾是至关重要的一步。我们的综述为研究人员和工程师提供了宝贵的资源,包括针对各种图像类型(包括高光谱、高分辨率、SAR和无人机图像)的除雾方法的分类。我们评估并比较了不同除雾方法的性能,包括基于先验的技术、深度学习架构,以及对比学习和少量学习等新兴方法。该综述还指出了开放的问题、研究差距和未来的方向,包括对各种现实世界雾霾数据集、高效算法以及将特定领域知识集成到基于学习的框架中的需求。这一及时的综述为了解图像去雾的最新进展和规划未来的研究方向提供了坚实的基础。随着对高质量图像的需求不断增长,开发准确、高效、强大的除雾技术将仍然是一个具有重要实际意义的关键研究领域。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

