
- 1Nginx网站使用CDN之后禁止用户真实IP访问的方法
- 2PyQt(Python+Qt)学习随笔:model/view架构中的两个标准模型QStandardItemModel和QFileSystemModel_qstandarditemmodel qfilesystemmodel
- 3音频变速python版_语音 语速语调 调节 python
- 4mac python3 轻松安装教程
- 5热力图_c++ opencv 热力图
- 6Streamlit+Echarts画出的图表,真的是太精湛了!!_streamlit echarts
- 7成为有钱人的终极秘诀:做到这7步,你也可以成为富人!_成为富人秘诀
- 8【SpringBoot Web框架实战教程(开源)】02 SpringBoot 返回 JSON
- 9【粉丝福利社】《AI高效工作一本通》(文末送书-完结)
- 10【全网唯一】触摸精灵iOS版纯离线本地文字识别插件_tomatoocr文字识别工具,纯本地离线识别
人工智能|GPU加速PyTorch训练_torch mps
赞
踩
版权声明:转载必须注明本文转自严振杰的博客:http://blog.yanzhenjie.com
1、GPU 的并行计算
我在人工智能|各名称与概念之介绍一文中提到过,深度学习是目前最主流的人工智能算法,从过程来看,它包括训练(Training)和推理(Inference)两个环节。
在训练环节,通过投喂大量的数据,训练出一个复杂的神经网络模型。在推理环节,利用训练好的模型,使用大量数据推理出各种结论。
训练环节由于涉及海量的训练数据和复杂的深度神经网络结构,所以计算规模非常庞大,对芯片的算力性能要求比较高。而推理环节,对简单指定的重复计算和实时性要求很高。模型所采用的具体算法,包括矩阵相乘、全连接层、卷积层、池化层、激活层、批归一化层和梯度运算等,分解为大量并行任务,可以有效缩短任务完成的时间。
总之,我想说明的是:神经网络模型的训练需要庞大的算力。那么它和 GPU 有什么关系呢?CPU 又在做什么?
理解 CPU 的角色。如果我们把处理器看成是一个餐厅的话,CPU 就像一个拥有几十名高级厨师的全能型餐厅,它什么菜系的菜都能做。但是因为菜系众多、工序复杂和厨师较少,所以需要花费大量的时间协调和配菜,上菜的速度相对比较慢。
理解 GPU 的角色。如果我们把处理器看成是一个餐厅的话,GPU 就像一个拥有千万名初级厨师的单一型餐厅,它只适合做某种指定菜系的菜。但是因为菜系单一、工序简单和厨师较多,所以仅需要少量时间通知任意一个厨师做菜,上菜速度反而快。
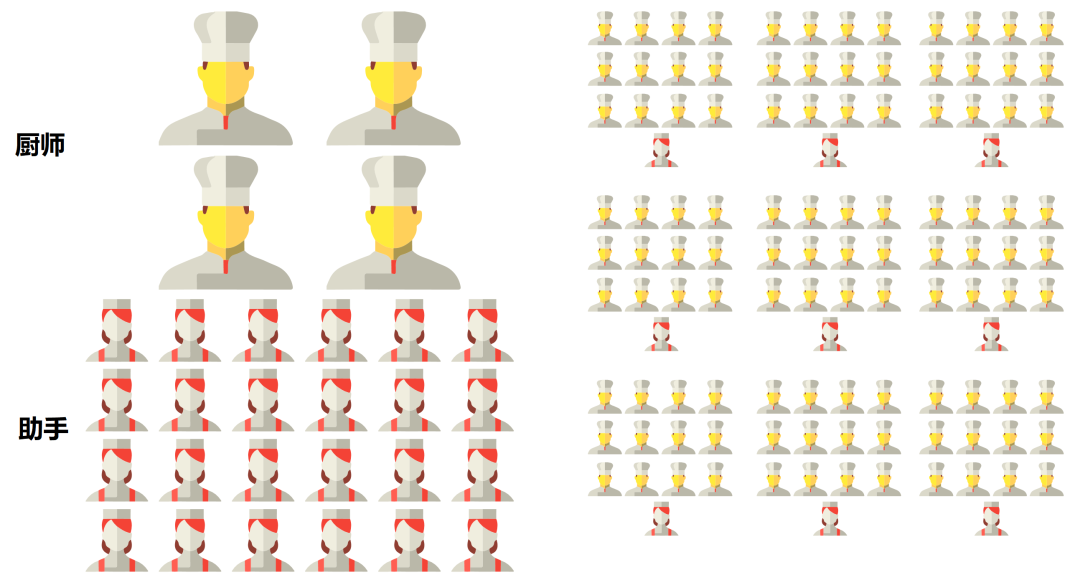 (图一)
(图一)
如图一所示,左侧为 CPU 角色,右侧为 GPU 角色。GPU 凭借自身强悍的并行计算能力以及内存带宽,可以很好地应对训练和推理任务,已经成为业界在深度学习领域的首选解决方案。如果对模型进行合理优化,一块 GPU 可以提供相当于几十块 CPU 的算力。
本小节内容引用自(有大量修改,侵删):https://www.toutiao.com/article/7319434384707158562
2、CUDA 和 MPS
torch.cuda和torch.mps是 PyTorch 中的 2 个不同的模块,用于加速 PyTorch 训练。开发者在安装 PyTorch 时就需要注意安装正确的版本。我们进入官网后可以看到本地部署引导,并且会默认选中是和我们电脑的版本并给出安装命令或者安装包地址。
我们可以用鼠标点击选择自己想要安装的版本(系统、包管理、语言、计算平台):
 (图二)
(图二)
比如本人使用的电脑为 MBP M2,可以选择稳定版 PyTorch、MacOS、Pip、Python、计算平台为 Default,出给出安装命令:
pip3 install torch torchvision torchaudio
- 1
需要注意的是,MBP M 芯片系列的电脑,计算平台中 CUDA 会被画横线,不能选择,如果强行选择则不能安装。
2.1、非 M 芯片验证 CUDA 可用性
如果是非 M 系列芯片的电脑(OS X、Linux、Window),安装命令大概率是包含 cadu 的:
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch
conda install pytorch torchvision torchaudio cudatoolkit -c pytorch
- 1
- 2
- 3
此时可以直接验证 GPU 状态是否正常可用:
import torch
torch.cuda.is_available()
- 1
- 2
如果正常可用,将输出:
True
- 1
如果不正常,将输出:
False
- 1
torch.cuda的详细 API 文档:https://pytorch.org/docs/master/cuda.html
2.2、M 芯片验证 MPS 可用性
如果是 M 系列芯片,那么是无法安装 CUDA 的:
 (图三)
(图三)
很早之前,PyTorch 是不支持 M 芯片的。我查了下相关信息,找到 soumith 在 PyTorch 项目下讨论过对 GPU 加速的支持:https://github.com/pytorch/pytorch/issues/47702,2020 年 10 月的回答,有兴趣的读者可以看看。
在 2022 年 5 月 18 日,PyTorch 发布博客说 PyTorch v1.12 版本支持了 Mac OS 的 GPU 加速:https://pytorch.org/blog/introducing-accelerated-pytorch-training-on-mac/。
苹果的 MPS(Metal Performance Shaders)扩展了 PyTorch 框架,可以作为 PyTorch 的后端加速 GPU 训练,它提供了在 Mac 上设置和运行操作的脚本和功能,MPS 通过针对每个 Metal GPU 系列的独特特性进行了微调的内核来优化计算性能。
如果你安装的 PyTorch 的版本是大于等于 v1.12 的,那么默认就支持加速 PyTorch 训练的。
此时可以直接验证 GPU 状态是否正常可用:
import torch
torch.backends.mps.is_available()
- 1
- 2
如果正常可用,此时将输出:
True
- 1
如果不正常,此时将输出:
False
- 1
torch.mps的详细 API 文档:
3、CPU 和 GPU 的切换
首先需要确定在设备上有 1 个或者多个 GPU 可用,在 2 中我们已经确认过了。现在我们需要将我们的数据转移到 GPU 可以看到的地方,是什么意思呢?我们知道 CPU 做计算靠的是 RAM,GPU 做计算靠的是 VRAM(Video Random Access Memory),VRAM 是 GPU 的专用内存。因此我们可以说把数据移动到 GPU 连接的内存,或者简称把数据移动到 GPU。
默认情况下,我们创建张量是在 CPU 设备上的(打印张量时,通过张量的属性可以看到):
import torch
x = torch.Tensor([1, 2, 3])
print(x, x.device)
- 1
- 2
- 3
- 4
此时可以看到输出:
tensor([1., 2., 3.]) cpu
- 1
以torch.rand()函数为例,如果我们事先知道此时 GPU 的可用状态,那么我们直接创建即可:
if torch.cuda.is_available():
my_device = torch.device('cuda')
elif torch.backends.mps.is_available():
my_device = torch.device('mps')
else:
my_device = torch.device('cpu')
print('Device: {}'.format(my_device))
x = torch.rand(2, 2, device=my_device)
print(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如果 GPU 支持cuda,此时可以看到输出:
Device: cuda
tensor([[0.0024, 0.6778],
[0.2441, 0.6812]], device='cuda:0')
- 1
- 2
- 3
如果 GPU 支持mps,此时可以看到输出:
Device: mps
tensor([[0.5986, 0.4086],
[0.0624, 0.7131]], device='mps:0')
- 1
- 2
- 3
当然,每次写一堆if else会感觉比较费劲,可以用三元表达式简写它们:
device_name = (
"cuda" if torch.cuda.is_available() else "mps"
if torch.backends.mps.is_available() else "cpu"
)
print(device_name)
- 1
- 2
- 3
- 4
- 5
OK,现在我们可以使用.to函数让张量在 CPU 和 GPU 之间进行切换了:
# 先拿到处理器名称 device_name = ( "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu" ) # 声明处理器 cpu_device = torch.device("cpu") gpu_device = torch.device(device_name) # 声明张量 x = torch.Tensor([1, 2, 3]) # 切换到CPU x = x.to(cpu_device) print(x, x.device) # 切换到GPU x = x.to(gpu_device) print(x, x.device)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
此时可以看到输出:
tensor([1., 2., 3.]) cpu
tensor([1., 2., 3.], device='mps:0') mps:0
- 1
- 2
PyTorch 官网一个很老的文档,但不及本文新:https://pytorch.org/tutorials/beginner/introyt/tensors_deeper_tutorial.html#moving-to-gpu
有兴趣一起交流学习的,可以加我的QQ群:874450808
本文完!
版权声明:转载必须注明本文转自严振杰的博客:http://blog.yanzhenjie.com
![[nlp] torch.load 和 torch.load_state_dict 有什么区别](https://img-blog.csdnimg.cn/img_convert/77fcfea2a41749d7867f62f0e98b01ca.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)

