
- 1GitHub上只下载部分文件的操作教程_github如何下载部分代码
- 2目标检测实战(五): 使用YOLOv5-7.0版本对图像进行目标检测完整版(从自定义数据集到测试验证的完整流程))_yolov5.7介绍
- 3Android动态权限详解
- 4【DevOps】Kibana:数据可视化与探索的强大工具
- 5MySQL索引下推(Index Condition Pushdown, ICP)优化深入解析_mysql 索引下推
- 6spss安装后 python_python从入门到入土教程(7)——用python实现SPSS的各种功能
- 7软件测试学习职业生涯必读的书籍【附电子版】_探索式软件测试电子书
- 8python爬虫及数据可视化分析_python爬虫与可视化项目简介怎么写
- 9【AI学习指南】七、PaddlePaddle自然语言处理-PaddleNLP的基础使用/中文分词/词性标注/实体识别/依存句法分析_paddlenlp 分词
- 10strongswan交叉编译与安装
数据预处理之异常值处理_交通数据异常值处理
赞
踩
异常值
在一般的预测问题中,模型通常是对整体样本数据结构的一种表达方式,这种表达方式通常抓住的是整体样本一般性的性质,而那些在这些性质上表现完全与整体样本不一致的点,我们就称其为异常点,通常异常点在预测问题中是不受开发者欢迎的,因为预测问题通产关注的是整体样本的性质,而异常点的生成机制与整体样本完全不一致,如果算法对异常点敏感,那么生成的模型并不能对整体样本有一个较好的表达,从而预测也会不准确。
从另一方面来说,异常点在某些场景下反而令分析者感到极大兴趣,如疾病预测,通常健康人的身体指标在某些维度上是相似,如果一个人的身体指标出现了异常,那么他的身体情况在某些方面肯定发生了改变,当然这种改变并不一定是由疾病引起(通常被称为噪音点),但异常的发生和检测是疾病预测一个重要起始点。相似的场景也可以应用到信用欺诈,网络攻击等等。
常见的异常值检测方法
- 简单统计
- 3σ原则
- 箱线图法
常见的异常值处理方法
- 删除
- 视为缺失值——用缺失值处理方法处理(填充,插值等)异常值
3σ原则
这个原则有个条件:数据需要服从正态分布。在3σ原则下,异常值如超过3倍标准差,那么可以将其视为异常值。正负3σ的概率是99.7%,那么距离平均值3σ之外的值出现的概率为P(|x-u| > 3σ) <= 0.003,属于极个别的小概率事件。
如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。

首先检验数据是否正态分布
# pvalue大于0.05则认为数据呈正态分布
from scipy import stats
mean = df['age'].mean()
std = df['age'].std()
print(stats.kstest(df['age'],'norm',(mean,std)))
- 1
- 2
- 3
- 4
- 5
# 选取小于3个标准差的数据
data = data[np.abs(df['age']- mean) <= 3*std]
- 1
- 2
如果数据不符合正态分布,也可以用远离平均值的多少倍标准差来筛选异常值。具体倍数看数据情况和业务需求
# 定义远离平均值4倍标准差为异常值
a = mean + std*4
b = mean - std*4
data = data[(data['Age'] <= a) & (data['Age'] >= b)]
- 1
- 2
- 3
- 4
箱线图
这种方法是利用箱型图的四分位距(IQR)对异常值进行检测,也叫Tukey‘s test。
四分位距(IQR)就是上四分位与下四分位的差值。而我们通过IQR的1.5倍为标准,规定:超过上四分位+1.5倍IQR距离,或者下四分位-1.5倍IQR距离的点为异常值。

画箱线图
data['Age'].plot(kind = 'box')
- 1
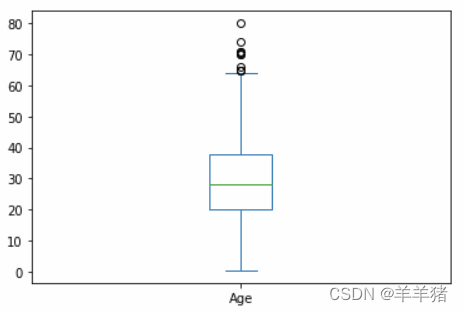
异常值处理
# 具体思路
# 算出上界和下届
q1 = data["Age"].quantile(0.25)
q3 = data["Age"].quantile(0.75)
iqr = q3 - q1
bottom = q1 - 1.5*iqr
upper = q3 + 1.5*iqr
# 筛选异常值
data[(data['Age'] >= bottom) & (data['Age'] <= upper)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
dataframe实现
def Drop_outliers(data):
column = [] # 需要进行异常值处理的列
for col in column:
# 算出上界和下届
q1 = data[col].quantile(0.25)
q3 = data[col].quantile(0.75)
iqr = q3 - q1
bottom = q1 - 1.5*iqr
# 按业务要求进行其他有可能需要的处理
# bottom = np.where(bottom<0, 0, bottom)
upper = q3 + 1.5*iqr
# 异常值赋值为空值
data.loc[(data[col] < bottom) | (data[col] > upper), col] = np.nan
return data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

