
- 1批量修改表字段排序规则_批量修改表的排序规则
- 2MySQL并发控制_mysql 多个请求写入
- 3【启明智显分享】工业级HMI芯片-Model 4方案的触摸屏在工控领域的应用
- 42023年信息素养大赛小学组C++智能算法复赛真题_全国青少年信息素养大赛 算法创意实践挑战赛 小学组复赛 真题
- 52024年考PMP还有什么用?
- 6全球人工智能发展白皮书_2023德勤全球人工智能发展白皮书
- 7vue2.0 集成UEditor富文本编辑器_vue2富文本编辑器
- 8Sofa_bolt下的ConnectionFactory设计解析_sofabolt connection
- 9查看文件处于什么状态时,错误为“FATAL:在以下位置的存储库中检测到可疑所有权”_but the current user is:
- 10flink反压_什么是flink反压
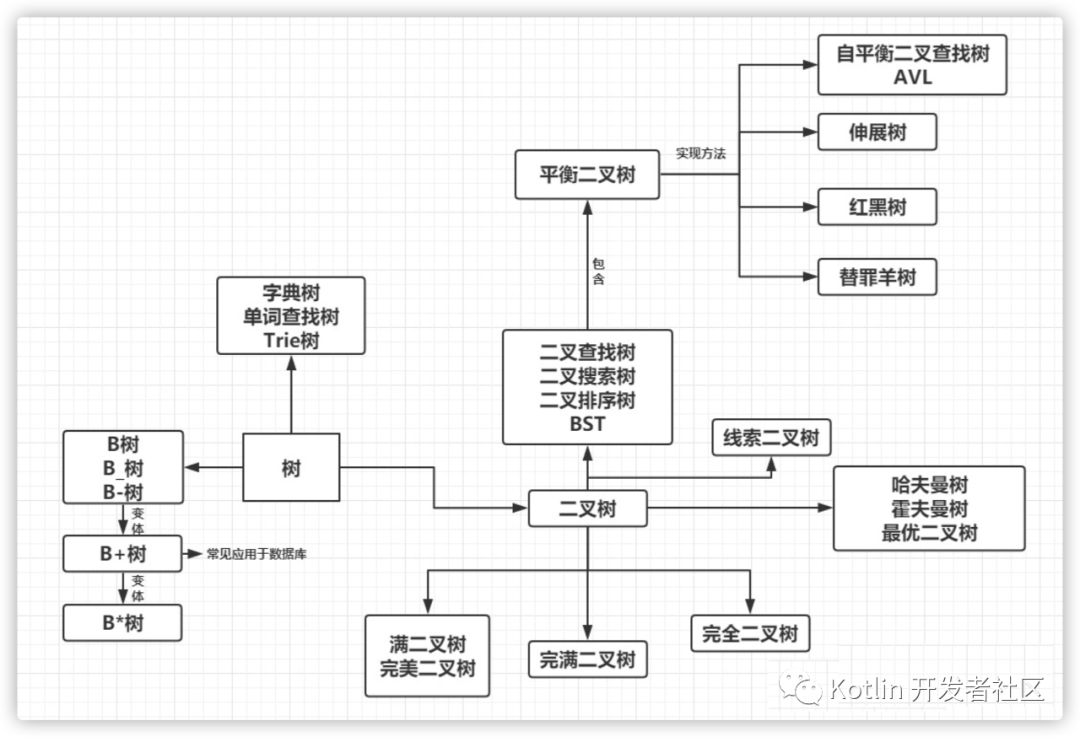
【数据结构与算法图文动画详解】终于可以彻底弄懂:红黑树、B-树、B+树、B*树、满二叉树、完全二叉树、平衡二叉树、二叉搜索树...
赞
踩

1.树简介
1.1基本概念
树是由结点或顶点和边组成的(可能是非线性的)且不存在着任何环的一种数据结构。没有结点的树称为空(null或empty)树。一棵非空的树包括一个根结点,还(很可能)有多个附加结点,所有结点构成一个多级分层结构。下图是一个简单的树的示意图:
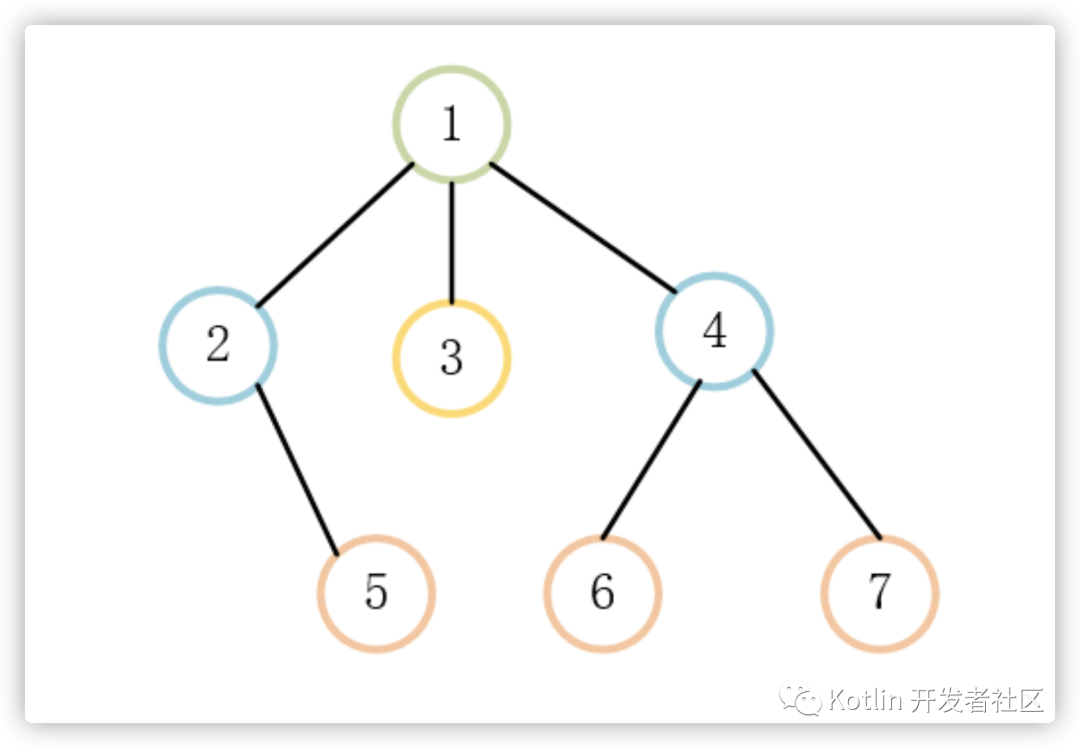
关键术语:
节点深度:对任意节点x,x节点的深度表示为根节点到x节点的路径长度。所以根节点深度为0,第二层节点深度为1,以此类推
节点高度:对任意节点x,叶子节点到x节点的路径长度就是节点x的高度
树的深度:一棵树中节点的最大深度就是树的深度,也称为高度
父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点
子节点:一个节点含有的子树的根节点称为该节点的子节点
节点的层次:从根节点开始,根节点为第一层,根的子节点为第二层,以此类推
兄弟节点:拥有共同父节点的节点互称为兄弟节点
度:节点的子树数目就是节点的度
叶子节点:度为零的节点就是叶子节点
祖先:对任意节点x,从根节点到节点x的所有节点都是x的祖先(节点x也是自己的祖先)
后代:对任意节点x,从节点x到叶子节点的所有节点都是x的后代(节点x也是自己的后代)
森林:m颗互不相交的树构成的集合就是森林
树结构的家族族谱:
1.2基本结构
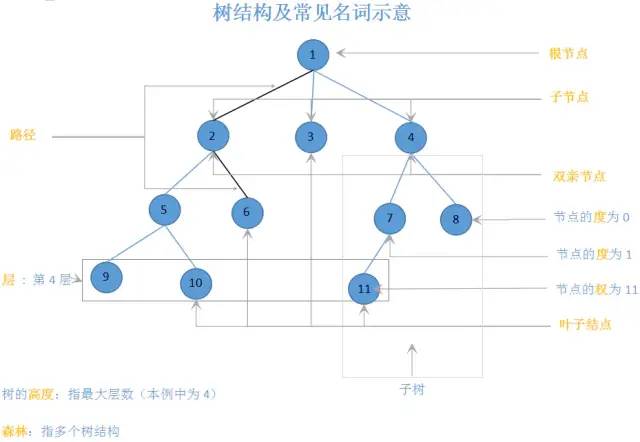
图1
补充:
兄弟节点:具有相同父节点的节点互称为兄弟节点。
树的深度:从根节点开始(其深度为0)自顶向下逐层累加的。上图中,3的深度是1,6的深度是2,10的深度是3。
节点高度:从叶子节点开始(其高度为0)自底向上逐层累加的。6的高度是1,根节点1的高度是3。
1.3 树的存储与表示
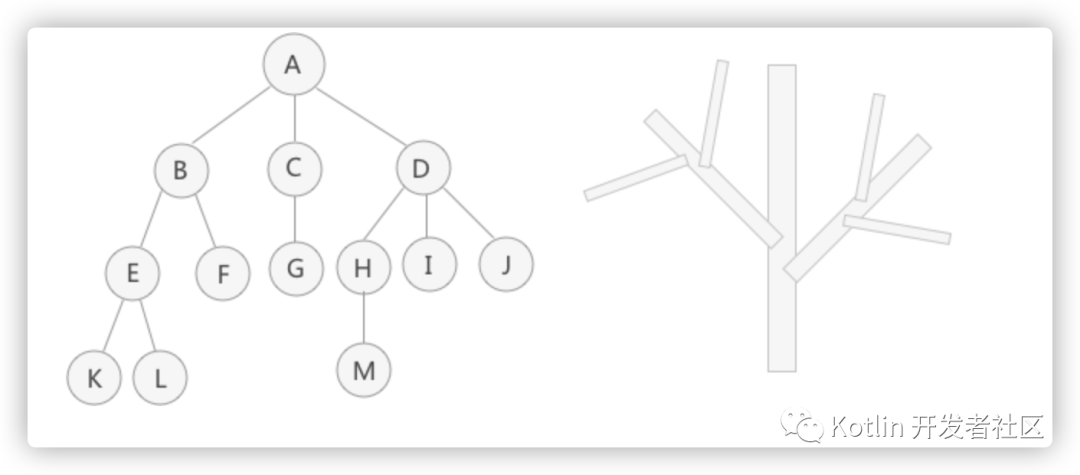
图中是使用树结构存储的集合 {A,B,C,D,E,F,G,H,I,J,K,L,M} 的示意图。对于数据 A 来说,和数据 B、C、D 有关系;对于数据 B 来说,和 E、F 有关系。这就是“一对多”的关系。 将具有“一对多”关系的集合中的数据元素按照树的形式进行存储,整个存储形状在逻辑结构上看,类似于实际生活中倒着的树,所以称这种存储结构为“树型”存储结构。
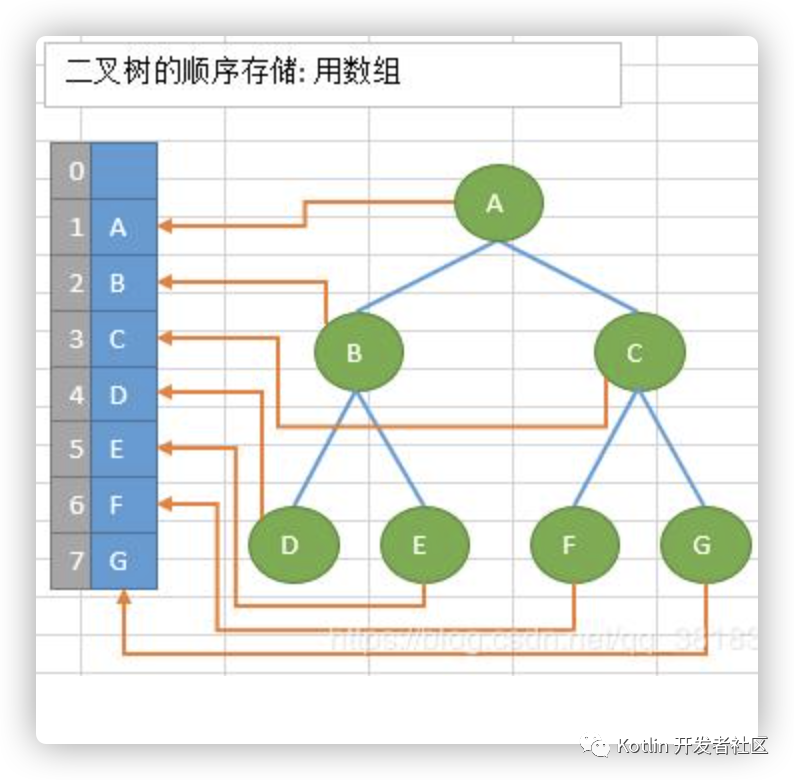
顺序存储:
将数据结构存储在固定的数组中,然在遍历速度上有一定的优势,但因所占空间比较大,是非主流二叉树。
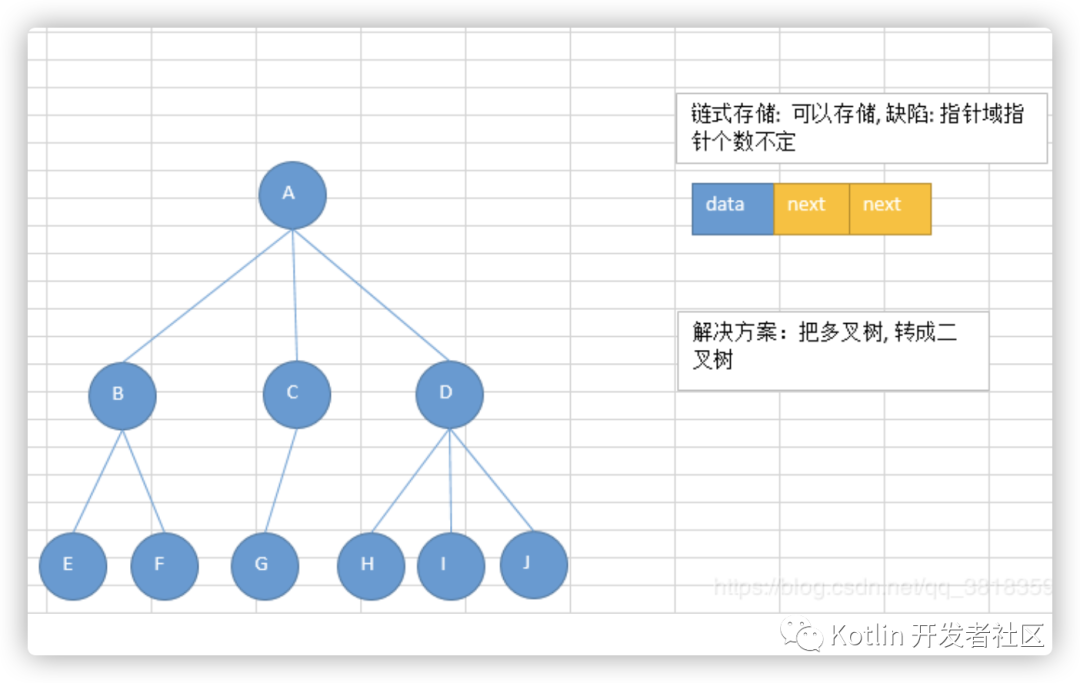
链式存储:
二叉树通常以链式存储。
除了图1表示树的方法外,还有其他表示方法:

(A) (B)
树的表示形式
上图 (A) 是以嵌套的集合的形式表示的(集合之间绝不能相交,即图中任意两个圈不能相交)。图 (B)使用的是凹入表示法(了解即可),表示方式是:最长条为根结点,相同长度的表示在同一层次。例如 B、C、D 长度相同,都为 A 的子结点,E 和 F 长度相同,为 B 的子结点,K 和 L 长度相同,为 E 的子结点,依此类推。
最常用的表示方法是使用广义表的方式。图 1(A)用广义表表示为:
(A , ( B ( E ( K , L ) , F ) , C ( G ) , D ( H ( M ) , I , J ) ) )
1.4 树的应用场景
1.xml,html等,那么编写这些东西的解析器的时候,不可避免用到树
2.路由协议就是使用了树的算法
3.mysql数据库索引
4.文件系统的目录结构
5.所以很多经典的AI算法其实都是树搜索,此外机器学习中的decision tree也是树结构
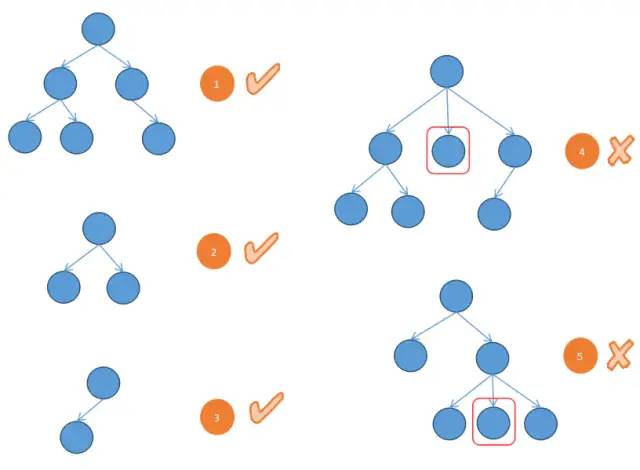
2. 二叉树(Binary Tree)
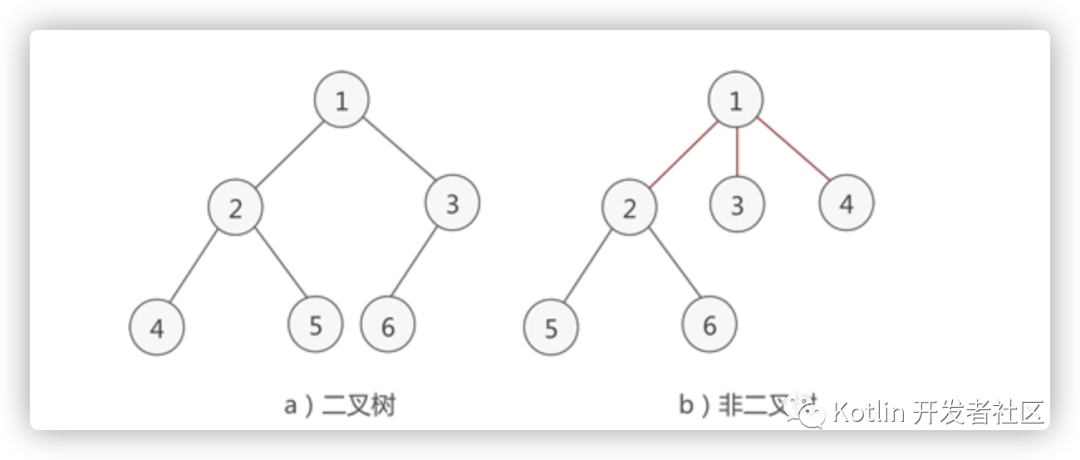
任何一个节点的子节点数量不超过2(子节点分为左节点与右节点)。
二叉树数据结构代码模型:
- class TreeNode<E> {
-
-
- E element;
- TreeNode<E> left;
- TreeNode<E> right;
-
-
- public TreeNode(E e) {
- element = e;
- }
- }
二叉树的遍历方式:
先序遍历:先根节点->遍历左子树->遍历右子树
中序遍历:遍历左子树->根节点->遍历右子树
后序遍历:遍历左子树->遍历右子树->根节点

深度优先搜索(DFS)与广度优先搜索(BFS):
实现:
bfs=队列,入队列,出队列 一次访问一条路径;
dfs=栈,压栈,出栈 一次访问多条路径。
关系:用DFS解决的问题都可以用BFS解决。DFS易于编写(递归),时间消耗较少但是容易发生爆栈,而BFS可以控制队列的长度。
二叉查找树的三种遍历都可以直接用递归的方法来实现:
代码:先序遍历
- protected void preorder(TreeNode<E> root) {
-
-
- if (root == null)
- return;
-
-
- System.out.println(root.element + " ");
-
-
- preorder(root.left);
-
-
- preorder(root.right);
- }
代码:中序遍历
- protected void inorder(TreeNode<E> root) {
-
-
- if (root == null)
- return;
-
-
- inorder(root.left);
-
-
- System.out.println(root.element + " ");
-
-
- inorder(root.right);
- }
代码:后序遍历
- protected void postorder(TreeNode<E> root) {
-
-
- if (root == null)
- return;
-
-
- postorder(root.left);
-
-
- postorder(root.right);
-
-
- System.out.println(root.element + " ");
- }
代码:二叉查找树的简单实现
- public class MyBinSearchTree<E extends Comparable<E>> {
-
-
- // 根
- private TreeNode<E> root;
-
-
- // 默认构造函数
- public MyBinSearchTree() {
- }
-
-
- // 二叉查找树的搜索
- public boolean search(E e) {
-
-
- TreeNode<E> current = root;
-
-
- while (current != null) {
-
-
- if (e.compareTo(current.element) < 0) {
- current = current.left;
- } else if (e.compareTo(current.element) > 0) {
- current = current.right;
- } else {
- return true;
- }
- }
-
-
- return false;
- }
-
-
- // 二叉查找树的插入
- public boolean insert(E e) {
-
-
- // 如果之前是空二叉树 插入的元素就作为根节点
- if (root == null) {
- root = createNewNode(e);
- } else {
- // 否则就从根节点开始遍历 直到找到合适的父节点
- TreeNode<E> parent = null;
- TreeNode<E> current = root;
- while (current != null) {
- if (e.compareTo(current.element) < 0) {
- parent = current;
- current = current.left;
- } else if (e.compareTo(current.element) > 0) {
- parent = current;
- current = current.right;
- } else {
- return false;
- }
- }
- // 插入
- if (e.compareTo(parent.element) < 0) {
- parent.left = createNewNode(e);
- } else {
- parent.right = createNewNode(e);
- }
- }
- return true;
- }
-
-
- // 创建新的节点
- protected TreeNode<E> createNewNode(E e) {
- return new TreeNode(e);
- }
-
-
- }
-
-
- // 二叉树的节点
- class TreeNode<E extends Comparable<E>> {
-
-
- E element;
- TreeNode<E> left;
- TreeNode<E> right;
-
-
- public TreeNode(E e) {
- element = e;
- }
- }

二叉查找树中删除节点分析
要在二叉查找树中删除一个元素,首先需要定位包含该元素的节点,以及它的父节点。假设current指向二叉查找树中包含该元素的节点,而parent指向current节点的父节点,current节点可能是parent节点的左孩子,也可能是右孩子。这里需要考虑两种情况:
current节点没有左孩子,那么只需要将patent节点和current节点的右孩子相连。
current节点有一个左孩子,假设rightMost指向包含current节点的左子树中最大元素的节点,而parentOfRightMost指向rightMost节点的父节点。那么先使用rightMost节点中的元素值替换current节点中的元素值,将parentOfRightMost节点和rightMost节点的左孩子相连,然后删除rightMost节点。
- // 二叉搜索树删除节点
- public boolean delete(E e) {
-
-
- TreeNode<E> parent = null;
- TreeNode<E> current = root;
-
-
- // 找到要删除的节点的位置
- while (current != null) {
- if (e.compareTo(current.element) < 0) {
- parent = current;
- current = current.left;
- } else if (e.compareTo(current.element) > 0) {
- parent = current;
- current = current.right;
- } else {
- break;
- }
- }
-
-
- // 没找到要删除的节点
- if (current == null) {
- return false;
- }
-
-
- // 考虑第一种情况
- if (current.left == null) {
- if (parent == null) {
- root = current.right;
- } else {
- if (e.compareTo(parent.element) < 0) {
- parent.left = current.right;
- } else {
- parent.right = current.right;
- }
- }
- } else { // 考虑第二种情况
- TreeNode<E> parentOfRightMost = current;
- TreeNode<E> rightMost = current.left;
- // 找到左子树中最大的元素节点
- while (rightMost.right != null) {
- parentOfRightMost = rightMost;
- rightMost = rightMost.right;
- }
-
-
- // 替换
- current.element = rightMost.element;
-
-
- // parentOfRightMost和rightMost左孩子相连
- if (parentOfRightMost.right == rightMost) {
- parentOfRightMost.right = rightMost.left;
- } else {
- parentOfRightMost.left = rightMost.left;
- }
- }
-
-
- return true;
- }
2.1 满二叉树(Full Binary Tree)
所有叶子结点都在最后一层。
节点的总数为2^n-1 (n为树的高度)。
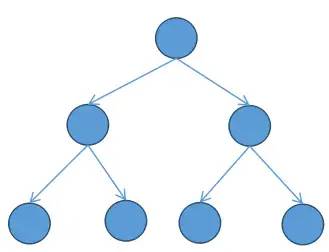
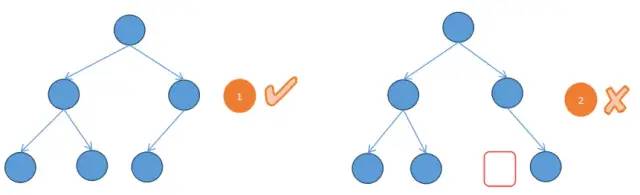
2.2 完全二叉树(Complete Binary Tree)
所有叶子结点都在最后一层或倒数第二层。
最后一层的叶子结点在左边连续,倒数第二节的叶子结点在右侧连续。
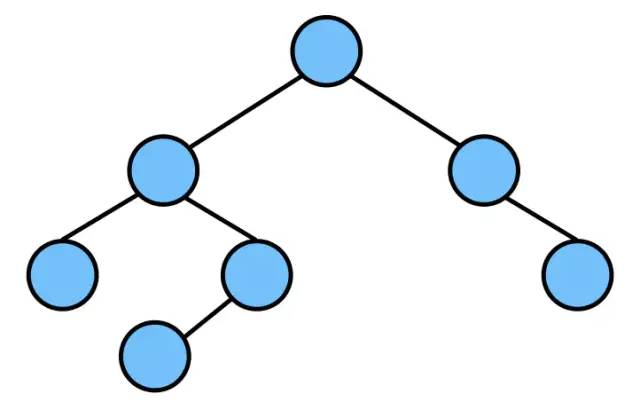
2.3 平衡二叉树(AVL,Balanced Binary Tree)
也叫 AVL 树。
它是一颗空树或左右两个子树的高度差的绝对值不超过1。
左右两个子树均为平衡二叉树。
AVL树是最先发明的自平衡二叉查找树算法。在AVL中任何节点的两个儿子子树的高度最大差别为1,所以它也被称为高度平衡树,n个结点的AVL树最大深度约1.44log2n。查找、插入和删除在平均和最坏情况下都是O(log n)。
通过自平衡操作(即旋转)构建两个子树高度差不超过1的平衡二叉树。
> 具体可以参阅1962年G.M. Adelson-Velsky 和 E.M. Landis的论文"An algorithm for the organization of information"。
增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。
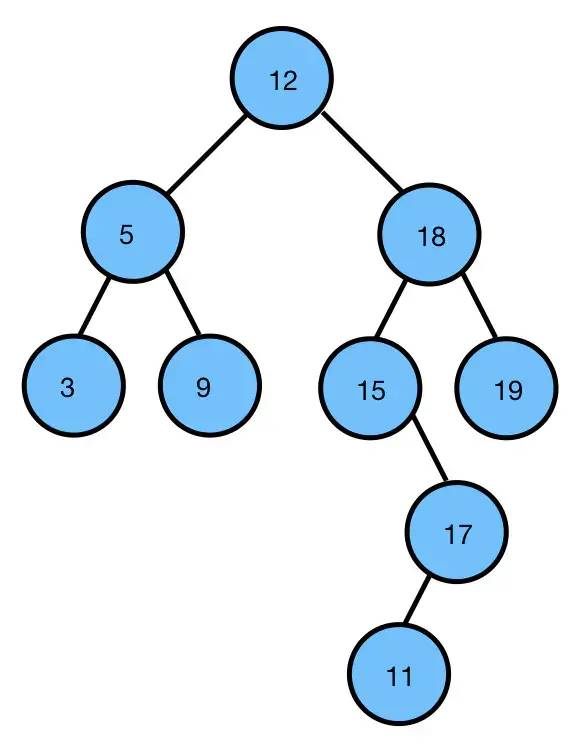
2.4 二叉搜索树(BST,Binary Search Tree)
也叫二叉查找树、二叉排序树。
若子树不空,则子树上所有节点的值均小于或等于根节点的值。
若右子树不空,则右子树所有节点的值均大于或等于根节点的值。(左右是镜像的,所以,这里看你怎么用左右了。)
左、右子树也分别为二叉排序树,或是一颗空树。
2.5 红黑树(Red Black Tree)
每个节点都带有颜色属性(颜色为红或黑)的平衡二叉查找树。
节点是红色或黑色。
根节点是黑色。
所有叶子结点都是黑色。
每个红色节点必须有两个黑色的子节点(从每个叶子到根的所有路径上不能有两个连续的红色节点)。
从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
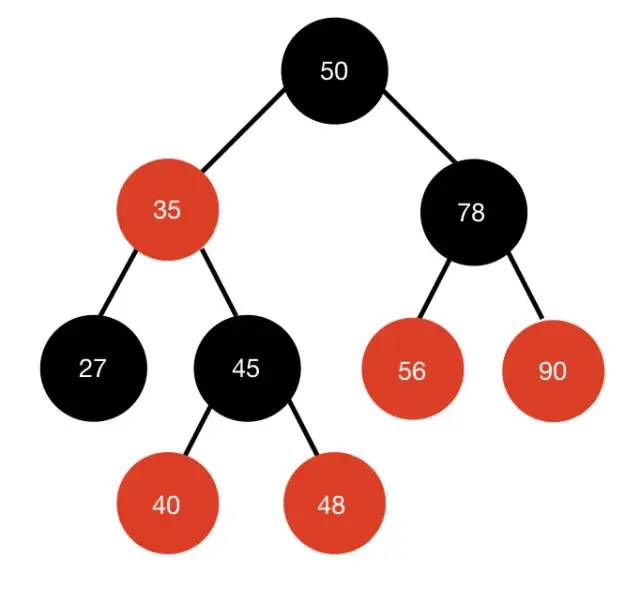
红黑树,是一种自平衡二叉查找树, 通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保从根到叶子节点的最长路径不会是最短路径的两倍,用非严格的平衡来换取增删节点时候旋转次数的降低,任何不平衡都会在三次旋转之内解决。
使用场景:
红黑树多用于搜索,插入,删除操作多的情况下
红黑树应用比较广泛:
1.广泛用在C++的STL中。map和set都是用红黑树实现的。
2.著名的linux进程调度Completely Fair Scheduler,用红黑树管理进程控制块。
3.epoll在内核中的实现,用红黑树管理事件块
4.nginx中,用红黑树管理timer等
红黑树的性能:
红黑树的查询性能略微逊色于AVL树,因为比AVL树会稍微不平衡最多一层,也就是说红黑树的查询性能只比相同内容的AVL树最多多一次比较,但是,红黑树在插入和删除上完爆AVL树,AVL树每次插入删除会进行大量的平衡度计算,而红黑树为了维持红黑性质所做的红黑变换和旋转的开销,相较于AVL树为了维持平衡的开销要小得多。
红黑树和平衡二叉树区别如下:
(1) 红黑树放弃了追求完全平衡,追求大致平衡,在与平衡二叉树的时间复杂度相差不大的情况下,保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单。
(2) 平衡二叉树追求绝对平衡,条件比较苛刻,实现起来比较麻烦,每次插入新节点之后需要旋转的次数不能预知。
3. B 树(B- 树)
B-tree(多路搜索树,并不是二叉的)是一种常见的数据结构。使用B-tree结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度。按照翻译,B 通常认为是Balance的简称。这个数据结构一般用于数据库的索引,综合效率较高。
3.1 B- 树
B-树 就是指 B树,也是一种用于查找的平衡树,但是它不是二叉树,B树可以拥有多于2个子节点,能够用来存储排序后的数据。这种数据结构能够让查找数据、循序存取、插入数据及删除的动作,都在对数时间内完成。这种数据结构常被应用在数据库和文件系统的实作上。
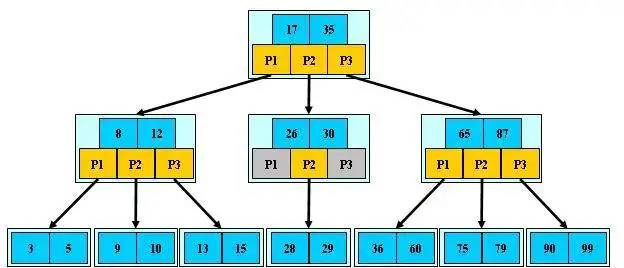
定义任意非叶子结点最多只有M个儿子;且M>2。
根结点的儿子数为[2, M]。
除根结点以外的非叶子结点的儿子数为[M/2, M]。
每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)。
非叶子结点的关键字个数=指向儿子的指针个数-1。
非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1]。
非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树。
所有叶子结点位于同一层。
插入与平衡过程:
下图用以表示往 4 阶 B 树中依次插入下面这组数据的过程:6 10 4 14 5 11 15 3 2 12 1 7 8 8 6 3 6 21 5 15 15 6 32 23 45 65 7 8 6 5 4

3.2 B+ 树
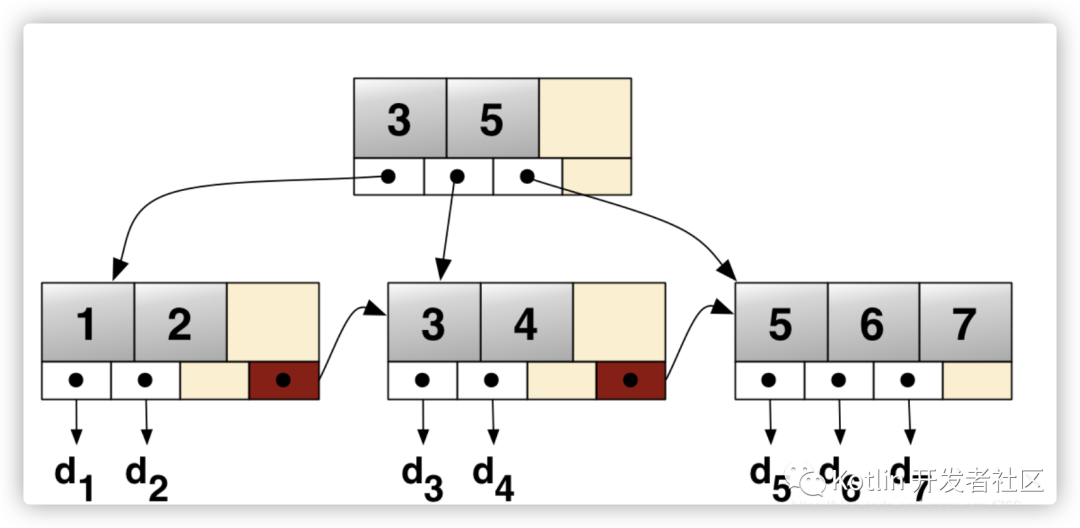
通常在多数节点在次级存储比如硬盘中的时候出现。通过最大化在每个内部节点内的子节点的数目减少树的高度,平衡操作不经常发生,而且效率增加了。
B+树 是 B树 的变体,也是一种多路搜索树。
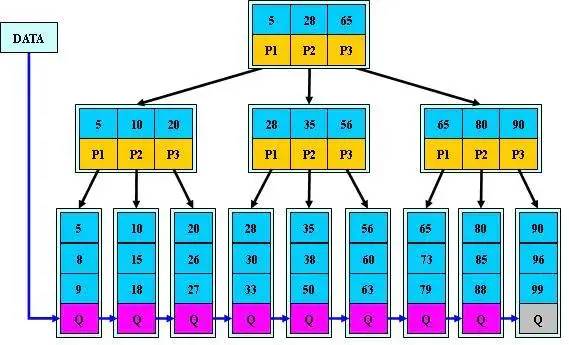
其定义基本与B-树相同,除了:
非叶子结点的子树指针与关键字个数相同。
非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间)。
为所有叶子结点增加一个链指针。
所有关键字都在叶子结点出现。
特性:
所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的。
不可能在非叶子结点命中。
非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层。
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针。
更适合文件索引系统。
使用场景:
文件系统和数据库系统中常用的B/B+ 树,他通过对每个节点存储个数的扩展,使得对连续的数据能够进行较快的定位和访问,能够有效减少查找时间,提高存储的空间局部性从而减少IO操作。他广泛用于文件系统及数据库中,如:
Windows:HPFS 文件系统
Mac:HFS,HFS+ 文件系统
Linux:ResiserFS,XFS,Ext3FS,JFS 文件系统
数据库:ORACLE,MYSQL,SQLSERVER 等中
B树:有序数组+平衡多叉树
B+树:有序数组链表+平衡多叉树
B+ 树的优点:
层级更低,IO 次数更少
每次都需要查询到叶子节点,查询性能稳定
叶子节点形成有序链表,范围查询方便
B+树还有一个最大的好处,方便扫库。B树必须用中序遍历的方法按序扫库,而B+树直接从叶子结点挨个扫一遍就完了。
B+树支持range-query非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
B+树插入和平衡:

3.3 B* 树
是 B+树 的变体,在 B+树 的非根和非叶子结点再增加指向兄弟的指针
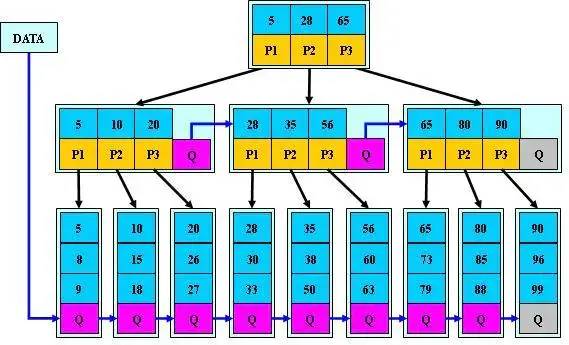
特性:
B*树定义了非叶子结点关键字个数至少为(2/3)M,即块的最低使用率为2/3(代替B+树的1/2)。
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。
所以,B*树分配新结点的概率比B+树要低,空间使用率更高。
相关阅读: 图结构(Graph)
图是一种较线性表和树更为复杂的数据结构,在线性表中,数据元素之间仅有线性关系,在树形结构中,数据元素之间有着明显的层次关系,而在图形结构中,节点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关。图的应用相当广泛,特别是近年来的迅速发展,已经渗入到诸如语言学、逻辑学、物理、化学、电讯工程、计算机科学以及数学的其他分支中。
我们将在后面的文章中介绍。
参考资料:
https://www.jianshu.com/p/3585745cc45b
https://www.jianshu.com/p/912357993486
https://www.jianshu.com/p/042052edeedd

