
- 1CCF的A类期刊和会议有哪些?人工智能顶会ACL,ICML,NeurIPS,ICLR论文投稿时间以及影响因子等_ccfa类期刊
- 2机器学习与高维信息检索 - Note 1 - 信息检索、机器学习与随机变量_高维信息搜索
- 3【Oracle】玩转Oracle数据库(三):数据库的创建和管理_oracle 创建数据库
- 4云计算的技术发展趋势_云计算技术的发展趋势
- 5Mac上如何安装Mysql5以及可视化工具navicat_可视化工具navicatmac 版
- 6map中的value保存遇到的问题_map里面的value可以放数组吗
- 7Vue使用socket实现实时通信
- 8FIR带通滤波器设计与验证_带通滤波器 csdn
- 9FIFO设计笔记(双口RAM、同步FIFO、异步FIFO)Verilog及仿真_双口异步ram空满判断的方法
- 10案例115:基于微信小程序的音乐播放器的设计与实现
UltraLight VM-UNet:平行视觉 Mamba 显着减少皮肤病变分割参数_视觉曼巴
赞
踩
UltraLight VM-UNet: Parallel Vision MambaSignificantly Reduces Parameters for Skin Lesion Segmentation
摘要
传统上,为了提高模型分割性能,大多数方法倾向于添加更复杂的模块。但这并不适用于医疗领域,尤其是在移动医疗设备上,由于计算资源限制,计算负担重的模型不适合真实的临床环境。最近,以Mamba为代表的状态空间模型(SSMs)成为传统卷积神经网络(CNNs)和Transformers的有力竞争者。在本文中,作者深入探讨了Mamba中参数影响的关键要素,并基于此提出了超轻量级视觉Mamba UNet(UltraLight VM-UNet)。
具体来说,作者提出了一种在并行视觉Mamba中处理特征的方法,称为PVM层,在保持处理通道总数不变的同时,实现了最低的计算负载和卓越的性能。作者在三个皮肤病变公共数据集上进行了与几个最先进的轻量级模型的比较和消融实验,并展示了仅拥有0.049M参数和0.060 GFLOPs的UltraLight VM-UNet具有同样强大的性能竞争力。此外,本研究深入探讨了Mamba中参数影响的关键要素,这将为Mamba可能在未来成为轻量化领域的新主流模块奠定理论基础。
代码:https://github.com/wurenkai/UltraLight-VM-UNet
Introduction
随着计算机技术和硬件计算能力的不断发展,计算机辅助诊断已经在医疗领域得到广泛应用,而医学图像分割是其重要的组成部分。医学图像分割通常是通过使用以卷积和 Transformer 为代表的深度学习网络来实现的。卷积在局部特征提取方面具有出色的能力,但在建立远程信息的关联方面存在不足。在之前的工作中,研究行人提出利用大卷积核来缓解这一问题。至于基于 Transformer 的网络架构,近年来,研究行人已经深入探讨了其方法。尽管自注意力机制可以通过连续的图像块序列解决远程信息提取的问题,但它也引入了更多的计算负载。这是因为自注意力机制的二次复杂度与图像大小密切相关。
此外,在提高计算机辅助诊断的准确性方面,算法模型的参数数量通常会被增加以增强模型的预测能力。然而,对于临床和实际医疗环境来说,现实的计算能力和内存限制往往需要被考虑。在mHealth任务中,低参数和最小的计算内存占用是至关重要的考虑因素。因此,对于未来移动医疗设备来说,迫切需要一种具有低计算负担和良好性能的算法模型。
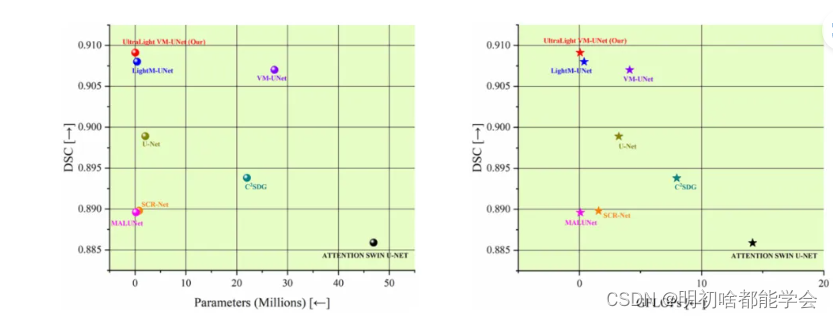
图1:对ISIC2017数据集的比较结果可视化。X轴对应于参数和GFLOPs,越少越好。Y轴对应于分割性能(DSC),
越高越好。
- 1
- 2
近期,状态空间模型(SSMs)在输入尺寸和内存占用方面显示出线性复杂性,这使得它们成为轻量级模型基础的关键。此外,SSMs擅长捕捉远程依赖关系,这可以关键性地解决在提取远距离信息时卷积的问题。在Gu等人[7]中,将时变参数引入到SSM中以获得Mamba,并且证明了Mamba能够使用比Transformers更低的参数处理文本信息。在视觉方面,Vision Mamba的引入再次加深了人们对Mamba的理解,它在不需要注意力机制的情况下,在推理1248×1248大小的图像时节省了86.8的内存。以上提到的研究行人所做的重要工作,使作者更有信心相信Mamba将在未来作为轻量级模型的基本构建块占据重要位置。
在本文中,作者基于Vision Mamba构建了一个轻量级模型。作者深入探讨了Mamba的关键内存占用及其性能权衡,并提出了一个超轻量级Vision Mamba UNet(UltraLight VM-UNet)。据作者所知,所提出的UltraLight VM-UNet是现有最轻量的Vision Mamba模型(具有0.049M的参数和0.060的GFLOPs),并且在三个皮肤病变分割任务中表现出极具竞争力的性能。具体来说,作者深入研究了对Mamba计算负载影响的关键因素,并得出结论:通道数是Mamba计算中内存占用激增的关键因素。
基于这一发现,作者提出了一种名为PVM层的并行Vision Mamba方法来处理深层特征,同时保持了总体处理通道数恒定。所提出的PVM层以惊人的低参数数量实现了卓越的性能。此外,作者仅使用包含Mamba的PVM层来实现所提出的UltraLight VM-UNet的深层特征提取,如图2所示。在方法部分,作者将介绍所提出的UltraLight VM-UNet的细节,以及Mamba中参数影响的关键因素和性能平衡方法。
作者的贡献和发现总结如下:
-
提出了一种超轻量级视觉曼巴UNet(UltraLight VM-UNet),用于皮肤病变分割。该模型参数仅为0.049M,GFLOPs为0.060,是目前已知最轻的视觉曼巴模型之一。
-
提出了PVM层,一种并行视觉Mamba方法,用于处理深度特征。该方法在保持处理通道总数不变的情况下,实现了最低的计算负载,表现出优异的性能。
-
深入分析了影响Mamba参数的关键因素,并为Mamba在未来成为轻量级建模的主流模块提供了理论依据。
-
所提出的UltraLight VM-UNet参数比传统的纯Vision Mamba UNet模型低99.82%,比当前最轻的Vision Mamba UNet模型(LightM-UNet)低87.84%。此外,UltraLight VM-UNet在所有三个公开可用的皮肤病变分割数据集上都保持了强大的性能竞争力。
这些发现为轻量级视觉曼巴模型的发展提供了重要的理论基础,并在皮肤病变分割领域展现出了实用性和竞争力。
Related Work
随着计算机计算能力的显著提升,计算机视觉已成为当今计算机技术中一个重要的领域。作为计算机视觉的一个分支,图像分割已经被相关研究者研究了数十年。传统的图像分割技术通过简单的阈值处理或数学方法来区分不同物体,这在不同像素区域之间造成了明显的差异。然而,传统方法难以应用于精细区域的分割。随着深度学习的不断发展,全卷积模型(FCN)首次在图像分割方法上展现了卓越的性能。FCN的出现也导致了深度学习图像分割方法的快速发展。在FCN出现后不久,另一个全卷积模型(U-Net)的出现再次引发了关注。U-Net中的跳跃连接操作能够很好地融合高层特征和低层特征,这对于图像分割尤其重要,特别是在需要细粒度分割的医疗图像分割中。
医学图像分割作为图像分割的重要分支之一,也是许多研究行人投入大量努力的研究方向。其中,多尺度变化问题和特征细化学习是医学图像分割中的关键问题。而皮肤病变分割具有丰富多变的特征信息以及由于其恶性黑色素瘤导致的高死亡率,这促使许多研究行人围绕皮肤病变分割进行一系列研究。
以皮肤病变为代表的医学图像分割算法在U-Net出现后得到了迅速发展。在Aghdam等人[1]的研究中,针对基于Swin U-Net[2]的皮肤病变分割,提出了级联操作中注意力机制的抑制操作。MHorUNet模型提出了一种用于皮肤病变分割的高阶空间交互UNet模型。在Wu等人[30]的研究中,提出了一种针对高阶交互的自适应选择UNet模型用于皮肤病变分割。
此外,基于U-Net改进的用于皮肤病变分割的算法非常多。然而,研究者们通常会在模型中添加更丰富的模块以提高识别的准确性,但这也会显著增加模型的参数数量和计算复杂性。在Vision Mamba出现后,LightM-UNet基于Mamba被提出以减少模型中的参数数量。LightM-UNet通过使用残差Vision Mamba进一步提取深层语义和远程关系,并在参数数量较少的情况下实现更优的性能。另外,U-Mamba首次将Vision Mamba引入到U型框架中,但其大量的参数(173.53M)限制了在真实临床环境中的应用。
在本文中,为了解决当前大型模型参数的问题,并揭示影响Mamba参数的关键因素,作者提出了一个基于Mamba的仅具有0.049M参数的超轻量级视觉Mamba UNet(UltraLight VM-UNet)。在三个公开的皮肤病变数据集上,UltraLight VM-UNet被证实仍然保持强大的竞争力。在下一节中,将详细描述作者的方法。
Method
Architecture Overview
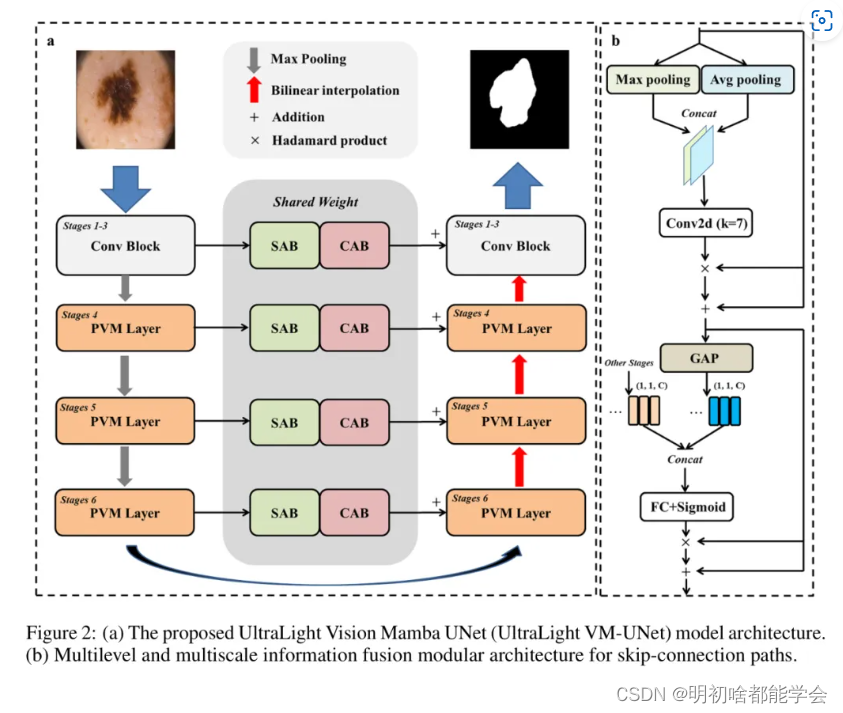
提出的超轻量级视觉曼巴UNet(UltraLight VM-UNet)如图2所示。UltraLight VM-UNet总共有6层结构,由U形结构(编码器、解码器和跳跃连接路径)组成。6层结构中的通道数设置为。前3层浅层特征的提取由卷积模块(Conv Block)组成,其中每一层包括一个具有3x3卷积核的标准卷积和一个最大池化操作。从第4层到第6层的深层特征是作者的核心部分,每一层由作者提出的并行视觉曼巴层(PVM Layer)组成。解码器部分保持与编码器相同的设置。跳跃连接路径利用通道注意力桥(CAB)模块和空间注意力桥(SAB)模块进行多 Level 和多尺度的信息融合。
Mamba Parameter Impact Analysis
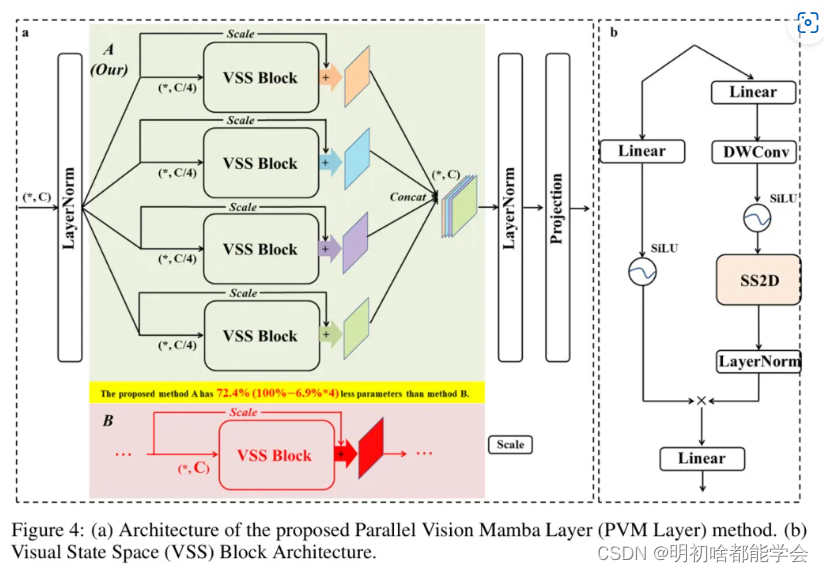
在视觉任务中,Mamba通常被嵌入到视觉状态空间(Visual State Space, VSS)块中以便使用,如图4(b)所示。VSS块主要由两个主要分支组成,第一个分支主要由线性层和SiLU激活函数[6]构成。第二个分支主要由线性层、深度卷积、SiLU激活函数、2D选择性扫描模块(SS2D)和层归一化(LayerNorm)组成。最后,两个分支通过逐元素的乘法进行合并以输出结果。
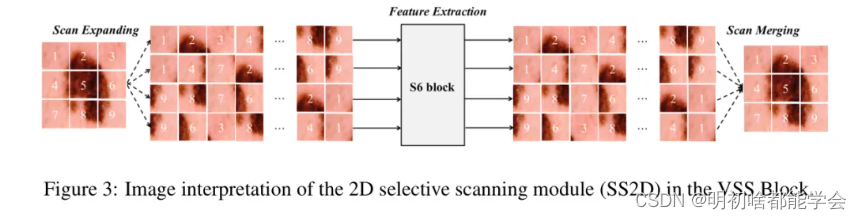
在VSS块中对参数影响最大的模块是SS2D。SS2D的组成部分如图3所示。它们包括扫描扩展操作、S6块特征提取以及扫描合并操作。首先通过扫描扩展操作,序列在四个方向上从左上到右下、从右下到左上、从右上到左下以及从左下到右上进行扩展。然后输入到S6块[7]进行特征提取。最后,通过扫描合并操作将其恢复到原始初始图像的大小。
其中,在SS2D中,输入通道的数量、S4D层状态维度的大小、内部卷积核的大小、投影扩张倍数以及投影矩阵的秩都影响着参数的数量。在这之中,输入通道数量的影响是巨大的,其影响主要来自四个方面:
- SS2D内部扩展投影通道
d_inner由投影扩展乘数和输入通道数量的乘积确定,具体表示为以下方程:
d_inner = expand * d_model
- 1
其中,d_inner 是内部扩展投影通道,expand 是投影扩展倍数(默认固定为2),而 d_model 是输入通道的数量。作者可以看到,随着模型中每层通道数的急剧增加,d_inner 将指数级上升。
- 其次,在SS2D中,输入投影层和输出投影层的参数将直接与输入通道的数量相关。输入投影层和输出投影层的工作方式如下:
in_proj : nn.Linear(d_model, d_inner * 2)
out_proj : nn.Linear(d_inner, d_model)
- 1
- 2
其中,输入投影 (in_proj) 层的参数为 (d_model * d_inner * 2) + (d_inner * 2),输出投影 (out_proj) 层的参数为 (d_inner * d_model) + d_model。作者可以看到,输入通道数 d_model 是控制参数的关键要素,而内部扩展投影通道 d_inner 也是受 d_model 控制的。
- 此外,SS2D网络中S6块内的四个线性投影层也是参数效果的关键。每个线性投影层具体指定如下:
a_proj = nn.Linear(d_inner, (dt_rank + d_state * 2))
- 1
其中 dt_rank 是投影矩阵的秩 (dt_rank = d_model/16),d_state 是S4D层状态维
好的,下面是Markdown格式的文本:
度的大小(固定为16),每个线性投影层的参数为
(d_inner * (dt_rank + d_state * 2))+(dt_rank + d_state * 2)。
- 1
然而,总共有4个线性投影层,所以总参数量为
4 * (d_inner * (dt_rank + d_state * 2)) +(dt_rank + d_state * 2)。
- 1
因此,从上述内容作者可以知道,所有参数仍然主要由输入通道数d_model控制。
同样,在SS2D模块中,控制S4D层不同状态注意力权重的参数矩阵的A_logs是一个重要的影响因素。A_logs是一个形状为(K* d_inner, d_state)的参数矩阵,而K是一个通常固定为4的超参数。因此,参数A_logs可以推导为
d_inner * d_state * 4。
- 1
总之,假设原始的输入通道数为1024,保持其他参数不变,将通道数减少到原来的四分之一(输入通道数变为256),根据上述参数公式计算,原始的总参数可以从7669760减少到525312。参数的大幅减少表明通道数减少了93.1,这进一步确认了输入通道数对SS2D参数具有非常关键的影响。这也进一步证实了输入通道数对SS2D参数具有极其重要的影响。
基于对影响Mamba参数的关键要素的深入研究发现,作者提出了一种在并行视觉Mamba中处理特征的方法,名为PVM层。在保持处理通道总数不变的情况下,实现了最低的计算负载和卓越的性能。具体细节将在下一节中详细说明。
Skip-connection Path
Short-Cut 路径使用了由Ruan等人提出的空间注意力桥(SAB)模块和通道注意力桥(CAB)模块,如图2(b)所示。SAB和CAB的结合使用使得能够融合UltraLight VM-UNet不同尺度上的多阶段特征。
SAB模块包括最大池化、平均池化和共享权重的扩展卷积。CAB模块包括全局平均池化、拼接操作、全连接层和sigmoid激活函数。在之前的工作中已经显示,SAB和CAB均能有效提高模型的收敛能力并增强对病变的敏感性。

