- 1vscode-合并分支代码_vscode 合并代码
- 2前台文本直接取数据库值doFieldSQL插入SQL
- 3OpenVoice——强大的语音克隆与生成技术_openvoice教程
- 4CodeWave系列:6.CodeWave 智能开发平台 扩展依赖库开发_nasl.ide.version
- 5【vim离线升级---vim 缓冲区错误漏洞】_centos离线升级vim
- 6XSS绕过waf
- 7Python+pandas将Excel文件xls批量转换xlsx(代码全注释)_xls批量转换成xlsx 保留格式
- 8手动添加Git Bash Here到右键菜单_git bush here
- 9黑金AX7Z100 FPGA开发板移植LWIP库(一)PS端_黑金ac7z100c 教程
- 10开发个人Ollama-Chat--1 项目介绍_openui 如何本地部署
【深度学习与神经网络】循环神经网络与NLP_循环对抗神经网络
赞
踩
背景知识
序列模型
分类问题:当前输入 -> 当前输出
预测问题:当前 + 过去输入 -> 当前输出
数据预处理
数值特征/类别特征:特征编码
文本处理:按字母/单词处理
文本预处理步骤:
1. 读取数据集
2. 词汇切分
3. 构建词索引表
文本嵌入:映射参数矩阵

RNN模型
序列数据建模
图像:1对1模型,输入输出维度固定
文本:输入维度不定,输出维度不定或1
RNN模型对序列数据建模(以文本为例)
输入x并拆分,输出h,映射参数矩阵为A
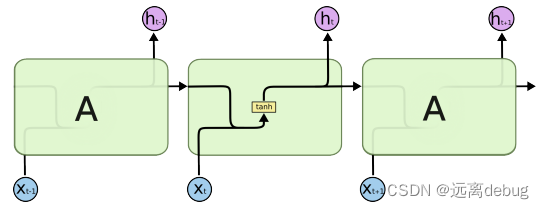
RNN误差反传
每个时间步的隐状态和输出可以写为:
既依赖于
又依赖于
,其中
的计算也依赖于
。因此,用链式法则就会产生:
进一步可写为:
阶段时间步:在步后阶段上述公式中的求和计算
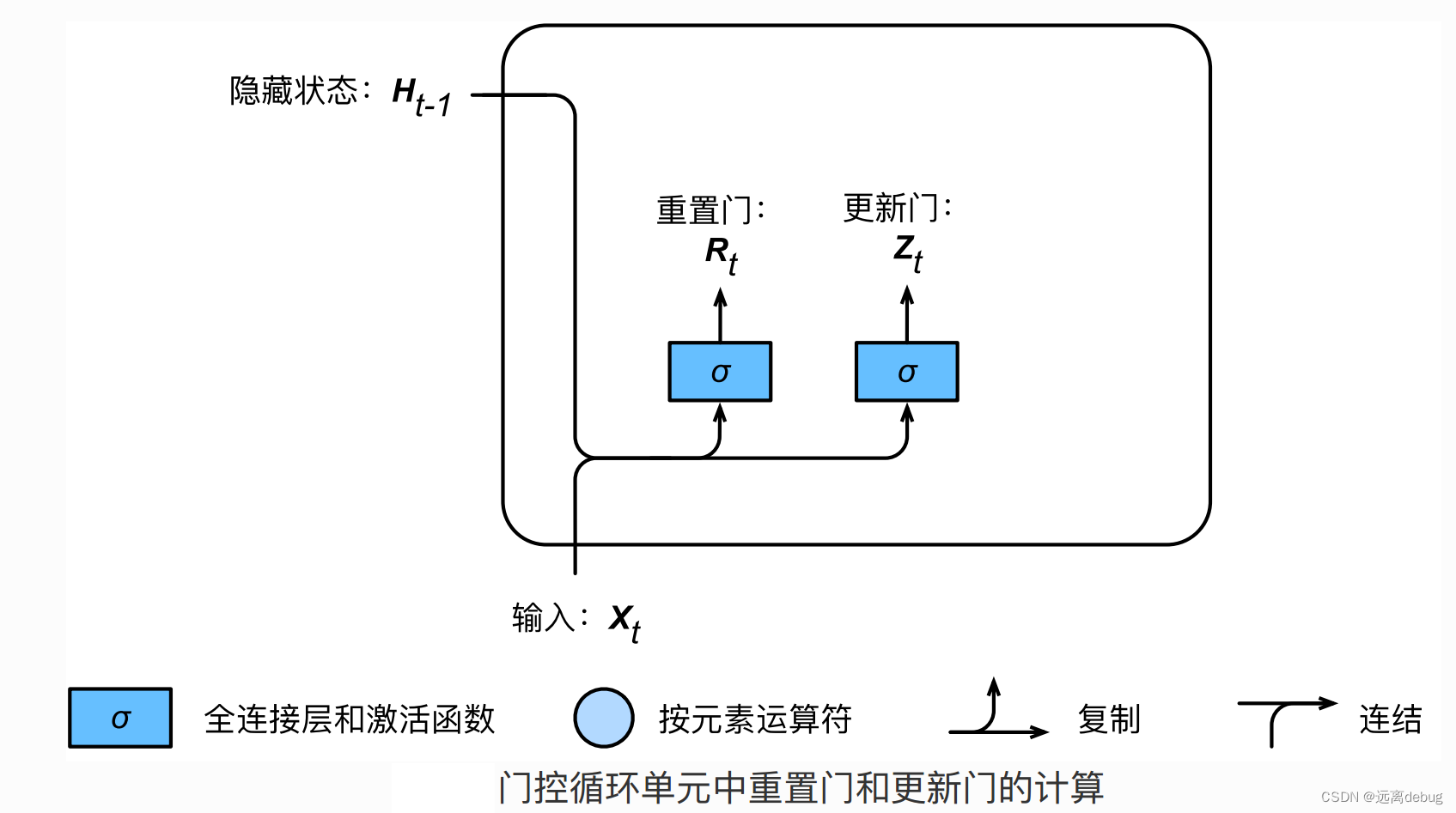
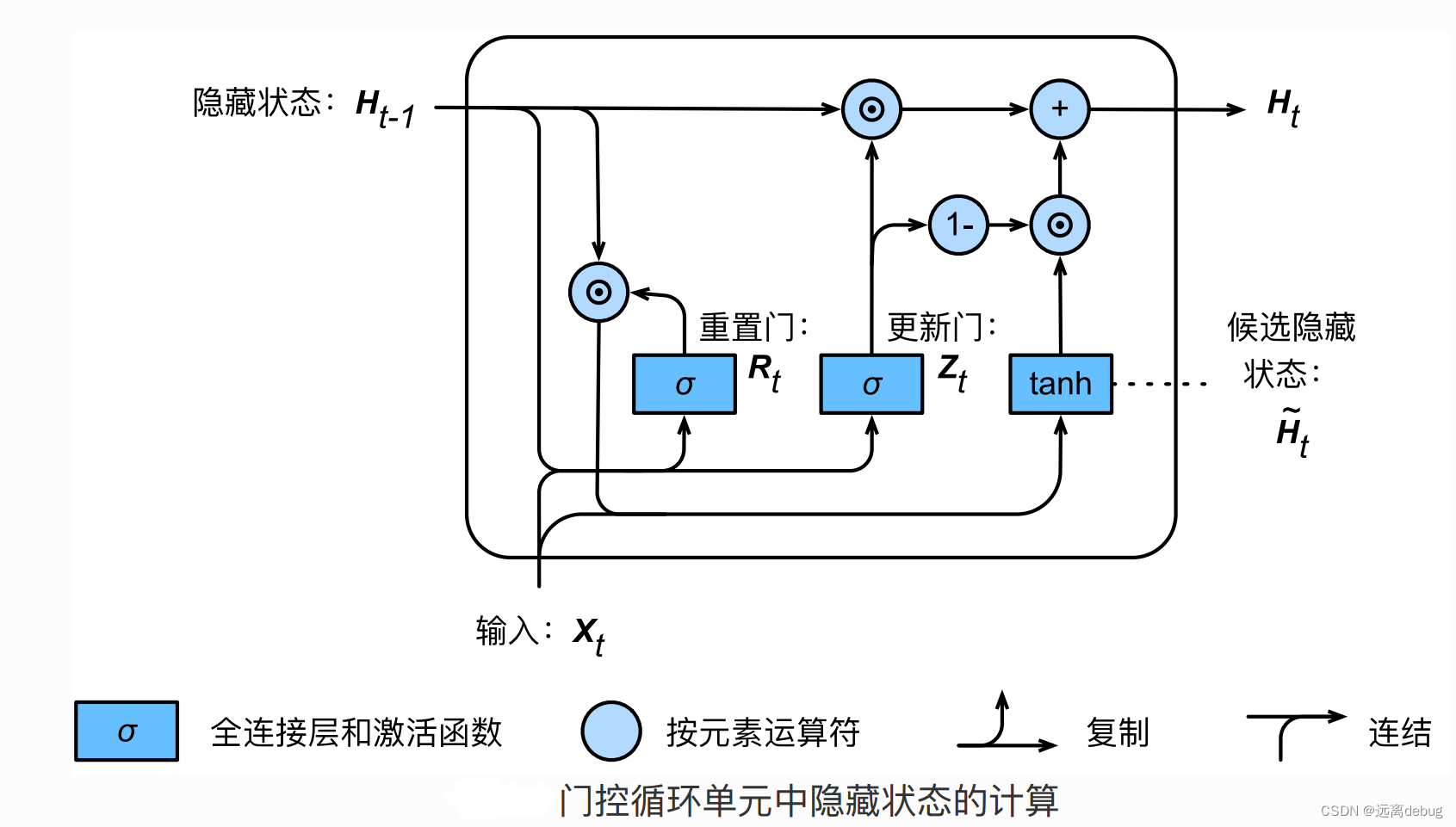
门控循环单元(GRU)
基本思想
不是每个观察都同等重要
关注机制:更新门
遗忘机制:重置门
GRU基本结构
候选隐状态
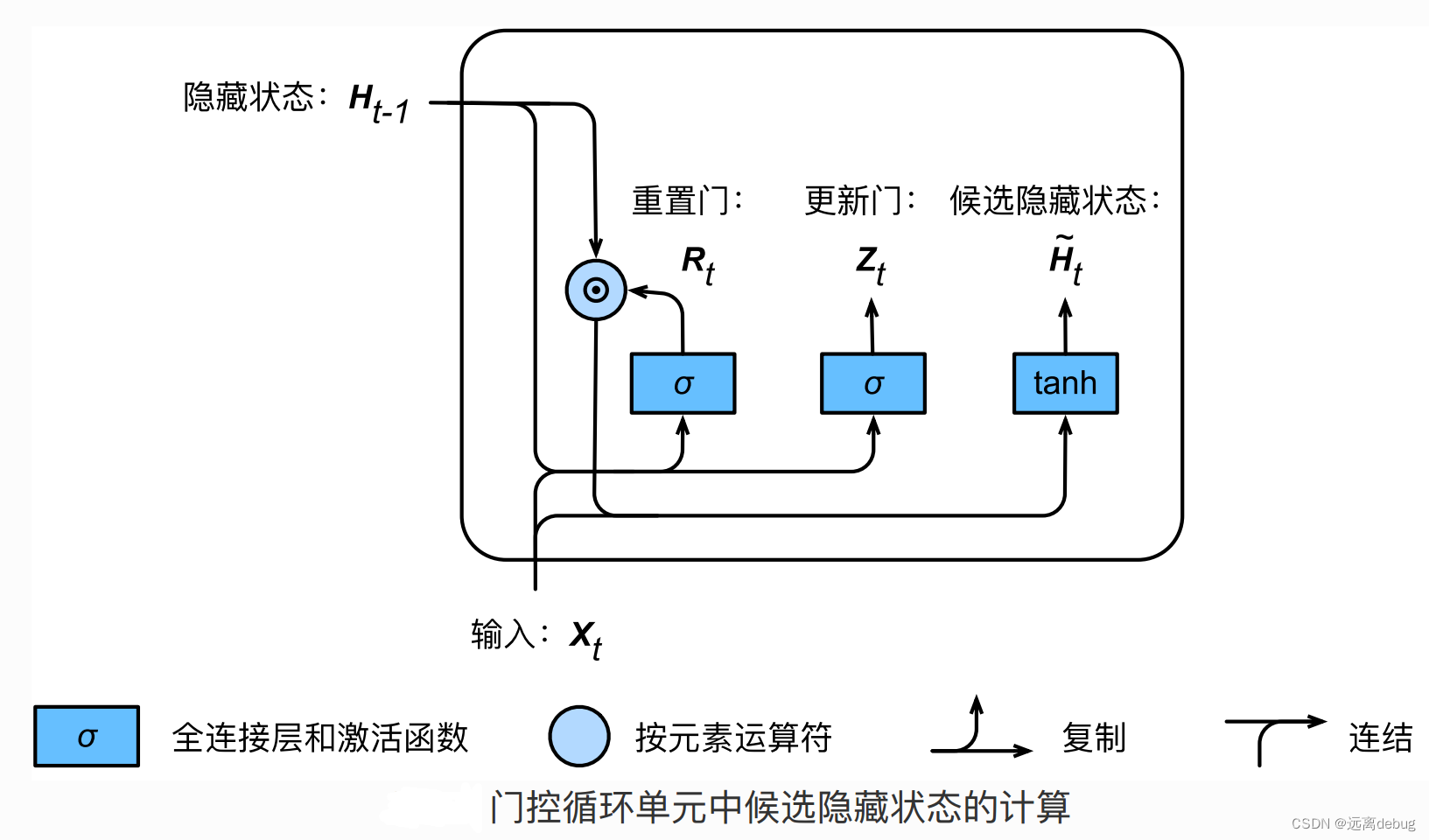
隐状态
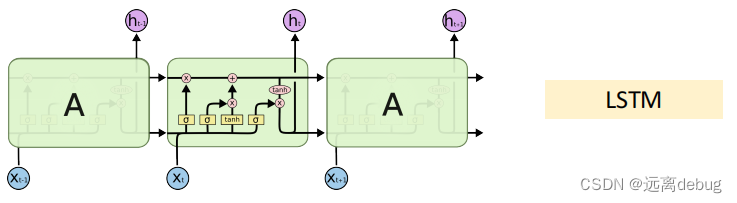
长短期记忆网络(LSTM)
LSTM网络模型
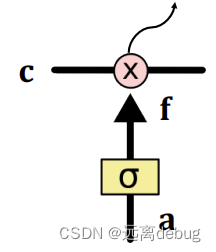
遗忘门
×代表逐元素相乘(点积)
输入门

确定传送带
的哪些值被更新,新值
加到
上
传送带更新

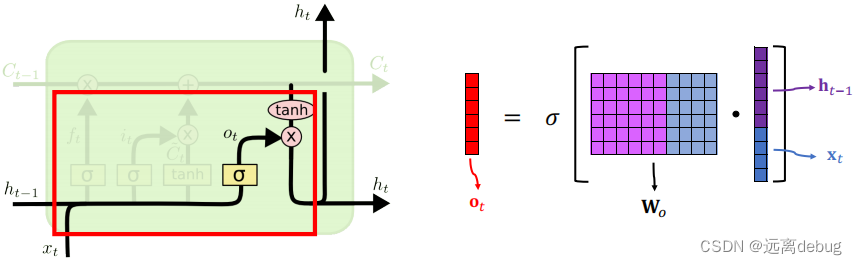
输出门
LSTM与RNN
LSTM参数量是RNN的四倍
LSTM输入输出与RNN相同
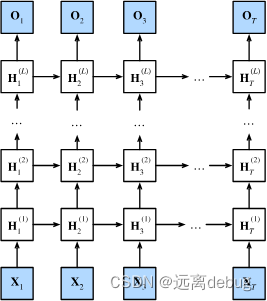
深度循环神经网络
具有L个隐藏层的深度循环神经网络,每个隐状态都连续地传递到当前层的下一个时间步和下一层的当前时间步。
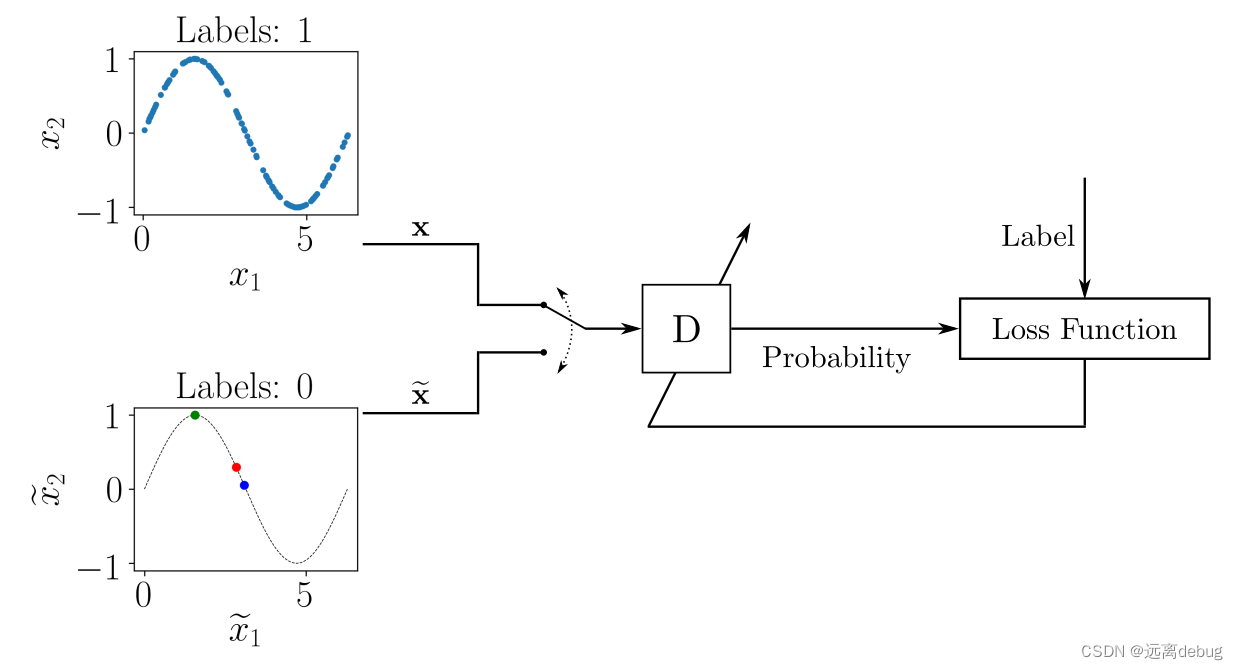
生成对抗网络(GAN)
GAN是一类神经网络,可以学习模仿给定的数据分布,可以像人类一样生成图像、音乐、语音或文本等素材。
GANs由两个神经网络组成,一个用于生成数据,另一个用于区分虚假数和真实数据。
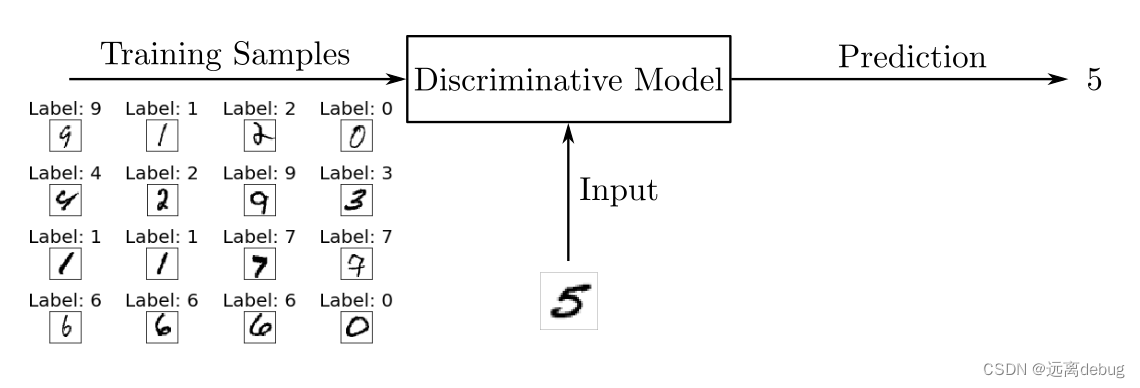
判别模型
在训练过程中,将使用算法调整模型的参数。目标是最小化损失函数,以使模型学习在给定输入时的输出概率分布。在训练阶段之后,使用该模型通过估计输入对应的最可能的数字对手写数字图像进行分类。
生成模型
像GANs这样的生成模型经过训练,可以用概率模型来描述数据集是如何生成的。通过从生成模型中采样,可以生成新数据。判别模型用于监督学习,而生成模型通常用于未标记的数据集,可以看作是一种无监督学习。
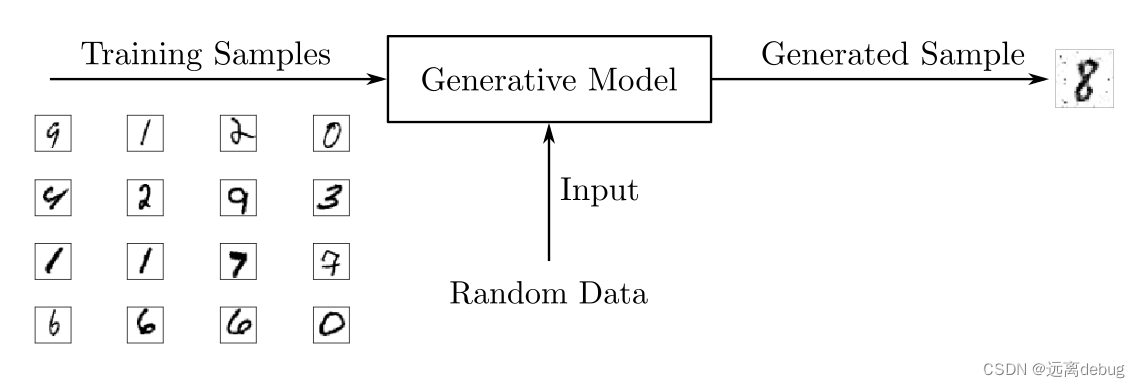
为了输出新的样本,生成模型通常考虑一个随机元素影响模型生成的样本。用于驱动生成器的随机样本来自一个隐空间,其中的向量代表了生成样本的一种压缩形式。
与判别性模型不同,生成性模型学习输入数据x的概率P(x),通过掌握输入数据的分布,它们能够生成新的数据实例。
GAN架构
生成式对抗网络由两个神经网络组成,即生成器和判别器。
生成器的作用是估计真实样本的概率分布,以便提供与真实数据相似的生成样本。
判别器被训练来估计一个给定样本来自真实数据而不是由生成器提供的概率。
这些结构被称为生成式对抗网络,因为生成器和鉴别器被训练成相互竞争:生成器试图更好地欺骗鉴别器,而鉴别器则试图更好地识别生成的样本。