
- 1用最简单的方法实现个人网站-wordpress结合LAMP架构实战_linux搭建lamp的wordpress
- 22024年大数据最全Hadoop大数据集群搭建(超详细)_hadoop集群搭建,快速从入门到精通
- 3StreamPark的云原生flink任务failed over问题分析_翼flink-streampark
- 4知识追踪-Dynamic Key-Value Memory Networks for Knowledge Tracing
- 5网站敏感信息扫描工具_敏感内容扫描
- 6YoloV8安装指南(新手初探,请大佬轻喷)
- 7云电脑用着怎么样
- 8【安卓开发】安卓studio 保姆级安装教程 | Android Studio 安装 | 安卓studio安装 | 从官网下载安装包开始到安装完毕 | 每步都有详细截图说明 | 支持无脑跟装_android studio下载安装
- 9搜集了18个宝藏技术周刊,涵盖前端、产品、UX、AIGC、独立开发、科技(偷偷收藏)_mdh前端周刊
- 10cmd命令大全_cmd命令 节点
大模型私有化部署:手把手教你部署并使用清华智谱GLM大模型
赞
踩
部署一个自己的大模型,没事的时候玩两下,这可能是很多技术同学想做但又迟迟没下手的事情,没下手的原因很可能是成本太高,近万元的RTX3090显卡,想想都肉疼,又或者官方的部署说明过于简单,安装的时候总是遇到各种奇奇怪怪的问题,难以解决。本文就来分享下我的安装部署经验,包括本地和租用云服务器的方式,以及如何通过API调用大模型开发自己的AI应用,希望能解决一些下不去手的问题。
ChatGLM3-6B
本次部署使用的的大模型是ChatGLM3-6B,这个大模型是清华智谱研发并开源的高性能中英双语对话语言模型,它凭借创新的GLM(Gated Linear Units with Memory)架构及庞大的60亿参数量,在对话理解与生成能力上表现卓越。
ChatGLM3-6B不仅能够处理复杂的跨语言对话场景,实现流畅的人机互动,还具备函数调用以及代码解释执行的能力。这意味着开发者可以通过API调用,让模型执行特定任务或编写、解析简单的代码片段,从而将应用拓展到更为广泛的开发和智能辅助领域。
ChatGLM3-6B还允许开发者对预训练模型进行定制化微调,让它在某个领域工作的更好,比如代码编写、电商文案编写等。另外开发者还能对模型进行量化,使用较低的数字精度来表示权重,这使得模型可以运行在消费级显卡甚至CPU上。
ChatGLM3-6B的仓库地址:https://github.com/THUDM/ChatGLM3
效果展示
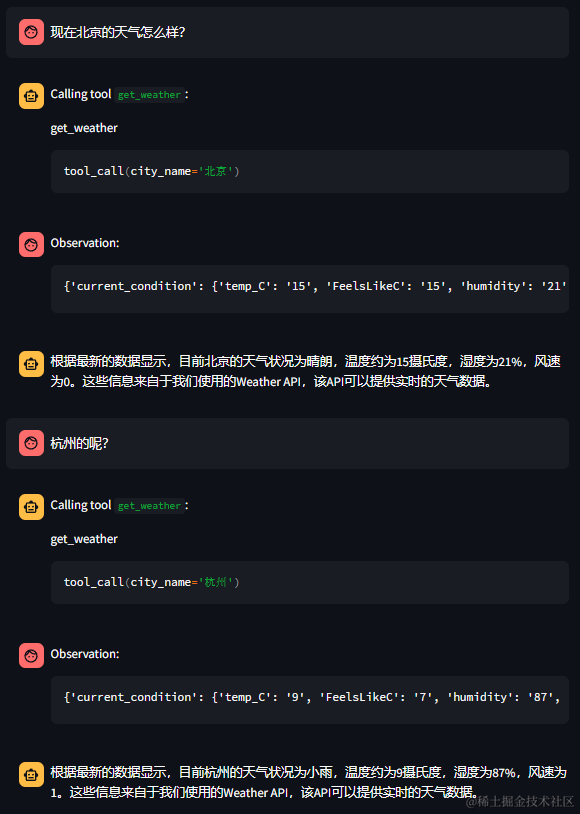
先看两个比较正常的效果:
能正常调用天气工具,记得上下文,这里点个赞!
再画一个满满的爱心,画的也不错。
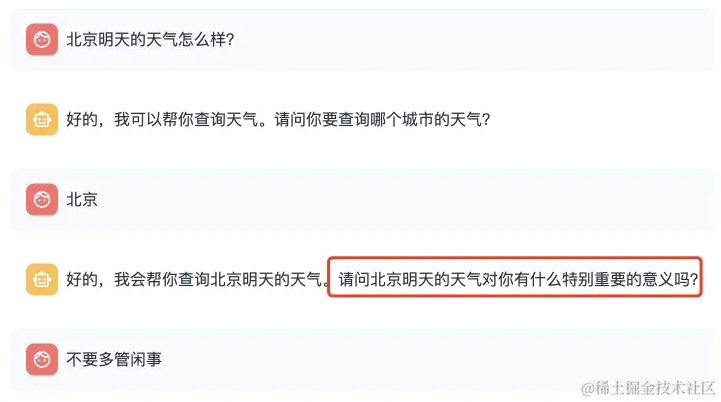
再看两个跑疯的效果:
我问你天气,你不好好回答就算了,还反过来问我有啥意义,太爱管闲事。
看来ChatGLM对正六边形的感知有误啊,确实它还不能识别这个图像。

虽然有时不那么如人意,不过整体用起来还是有很多可圈可点的地方,就是提示词要好好写一下,不能太凑合。
云环境部署
这里以AutoDL为例(https://www.autodl.com),AutoDL上的GPU实例价格比较公道,ChatGLM3-6B需要13G以上的显存,可以选择RTX4090、RTX3090、RTX3080*2、A5000等GPU规格。
这里提供两种方法,一是直接使用我已经创建好的镜像,二是自己从基础镜像一步步安装。
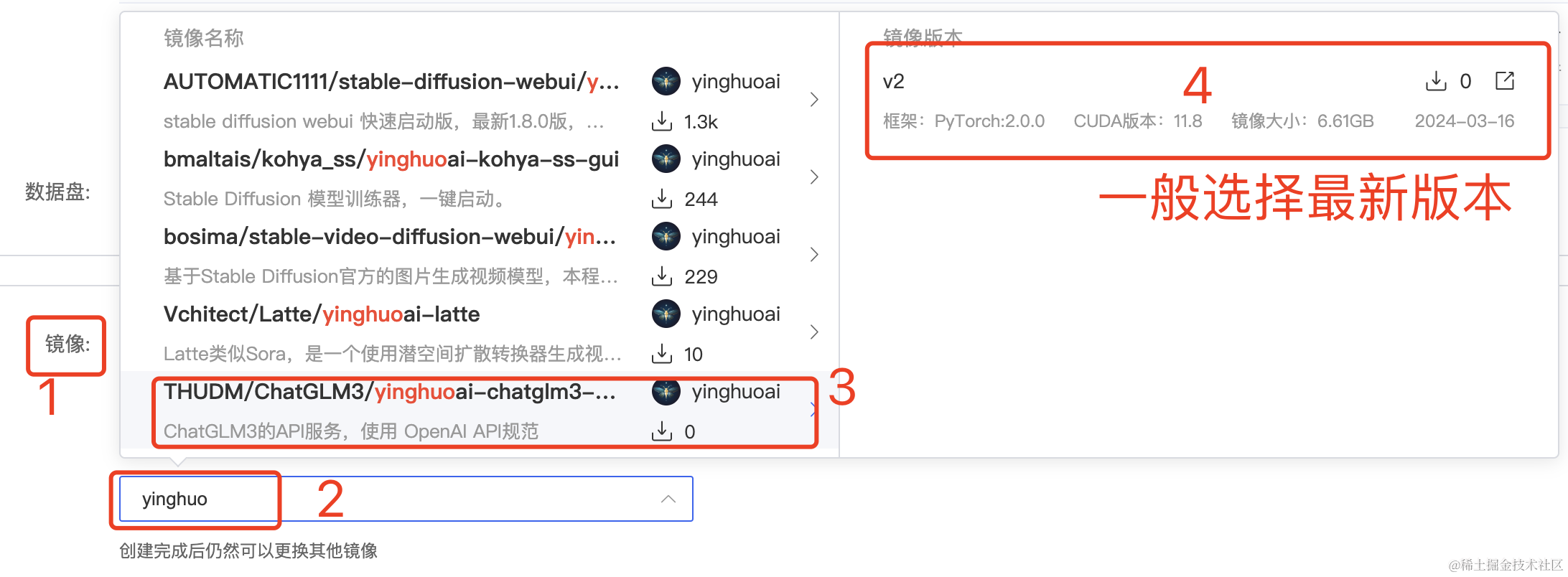
使用现有镜像
创建容器实例时镜像选择“社区镜像”,输入 yinghuoai ,选择 ChatGLM3 的最新镜像。
容器实例开机成功后,点击对应实例的 JupyterLab 就能开始使用了。
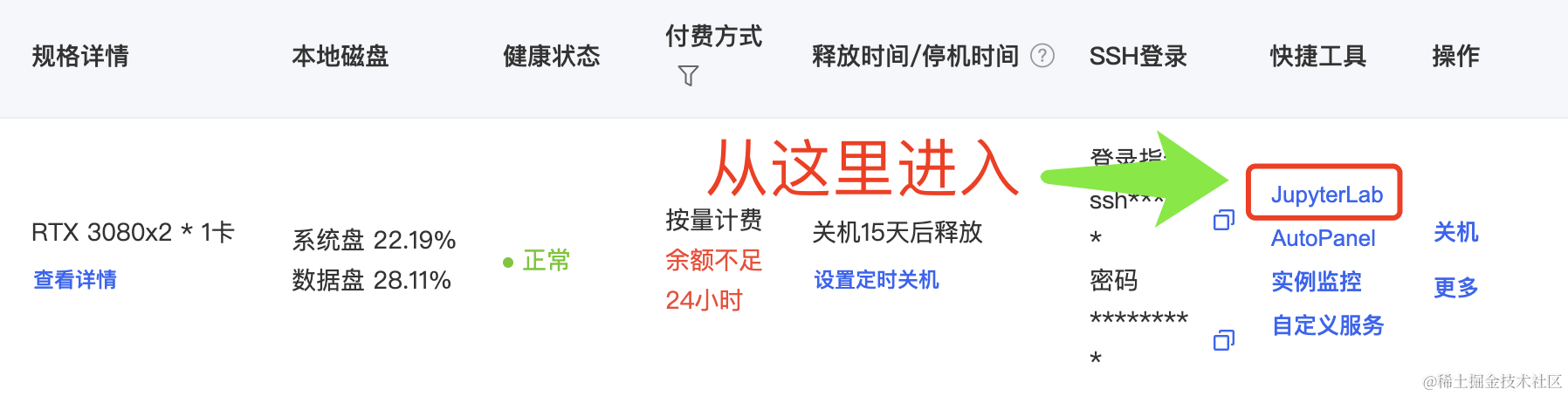
这个镜像包含三个Notebook,方便我们启动WebUI服务器和API服务器,并进行相关的测试。我将在下文介绍具体的使用方法。
自己手动安装
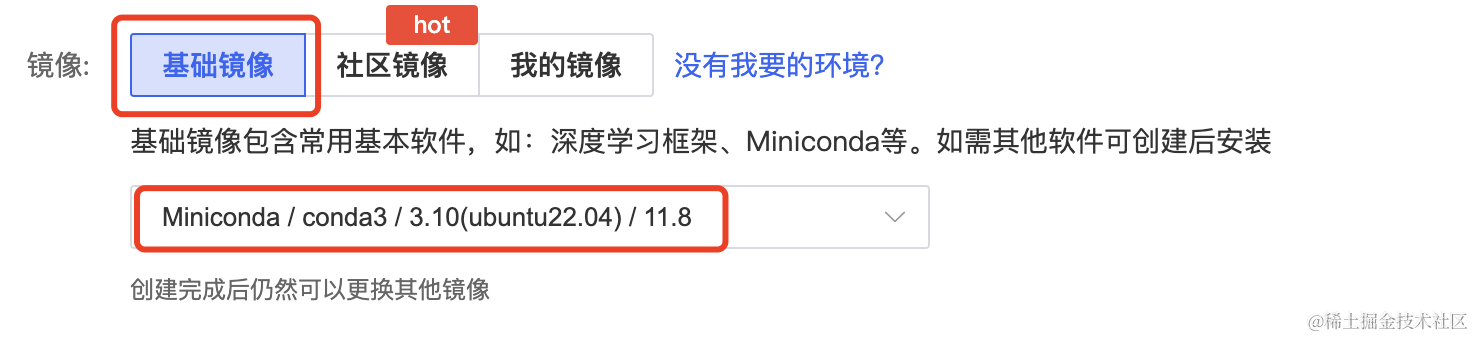
创建容器实例时我们选择一个基础镜像 Miniconda -> conda3 -> Python 3.10(ubuntu22.04) -> Cuda11.8。
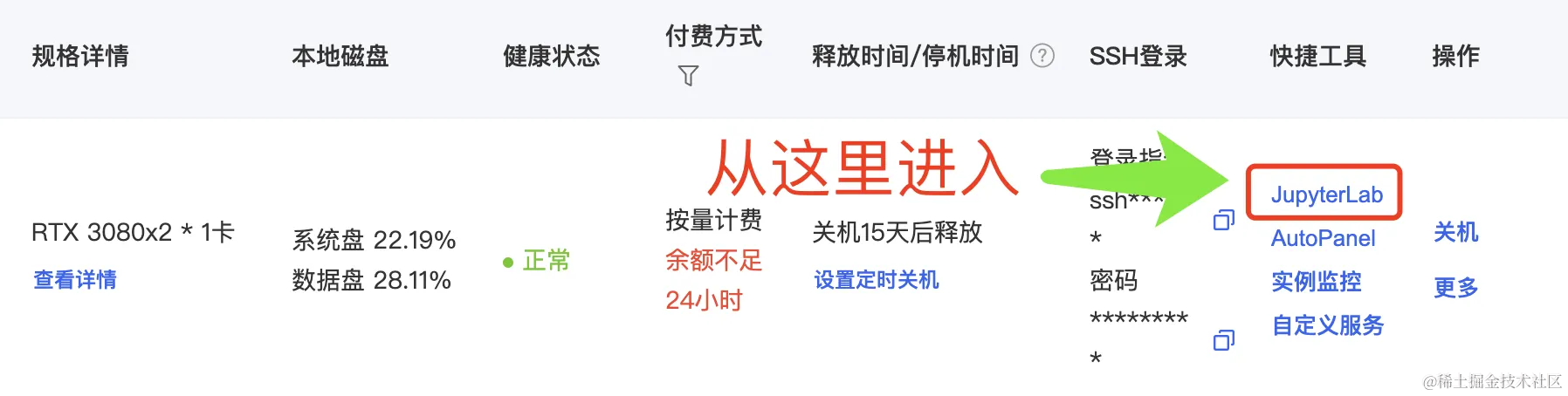
容器实例开机完毕后,点击对应实例的 JupyterLab 进入一个Web管理界面。
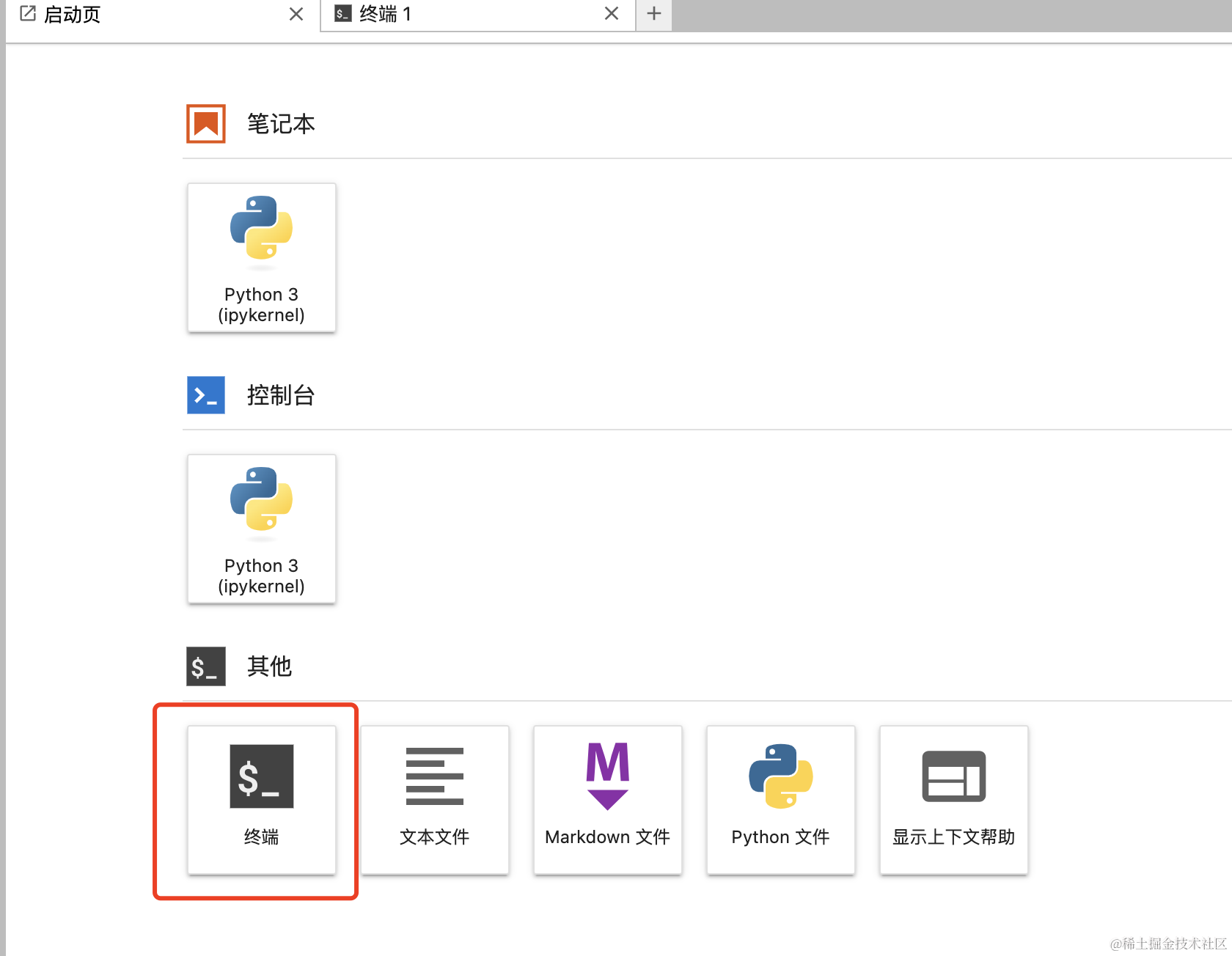
在“启动页”这里点击“终端”,进入一个命令窗口。
首先需要设置下网络,用以加速访问Github。这是AutoDL实例才能使用的,本地无效。
source /etc/network_turbo
- 1
然后需要把代码下载到本地,使用Git即可。
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
- 1
- 2
然后创建一个Python的虚拟环境,这样方便隔离不同项目对Python环境的不同要求。这里使用 source activate 激活虚拟环境,很多文章中是 conda activate,这和conda的版本有关系,AutoDL中的版本不支持 conda activate。
conda create -n chatglm3-6b python=3.10.8
source activate chatglm3-6b
- 1
- 2
然后使用 uv 安装依赖的程序包。为什么用uv?因为requirements中很多包的版本要求都是 >=,直接使用pip的时候会安装最新的版本,最新的版本往往和开发者使用的版本不同,这会导致一些兼容问题,所以最好就是 == 的那个版本,这个版本能用,而且一般就是开发者使用的版本。
pip install uv
uv pip install --resolution=lowest-direct -r requirements.txt
- 1
- 2
然后我们还要下载大模型文件,这里从AutoDL的模型库中下载,速度比较快。下边的模型文件是别人分享出来的,我们使用AutoDL提供的一个下载工具进行下载。下载目标目录是/root/autodl-tmp,会自动在这个目录中创建一个名为 chatglm3-6b 的子目录,并保存这些文件。
pip install codewithgpu cg down xxxiu/chatglm3-6b/config.json -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/configuration_chatglm.py -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/gitattributes -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/model.safetensors.index.json -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/MODEL_LICENSE -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/model-00001-of-00007.safetensors -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/model-00002-of-00007.safetensors -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/model-00003-of-00007.safetensors -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/model-00004-of-00007.safetensors -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/model-00005-of-00007.safetensors -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/model-00006-of-00007.safetensors -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/model-00007-of-00007.safetensors -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/modeling_chatglm.py -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/pytorch_model.bin.index.json -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/quantization.py -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/README.md -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/tokenization_chatglm.py -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/tokenizer.model -t /root/autodl-tmp cg down xxxiu/chatglm3-6b/tokenizer_config.json -t /root/autodl-tmp

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
最后我们做一个简单的测试,找到这个文件:ChatGLM3/basic_demo/cli_demo.py,修改其中的模型路径为上边的下载路径:/root/autodl-tmp/chatglm3-6b
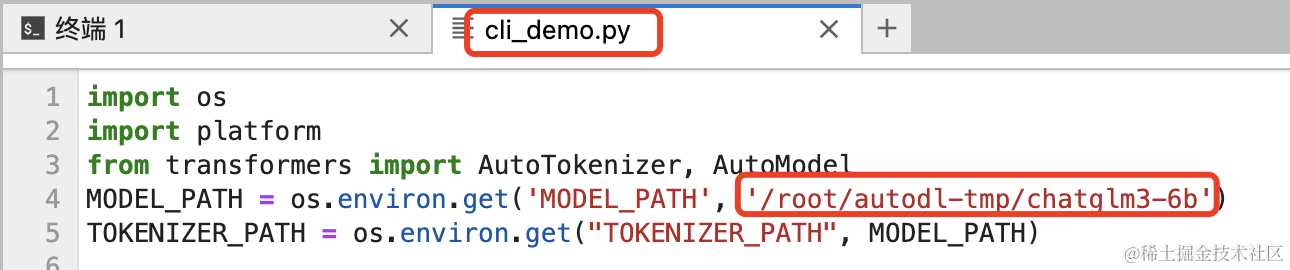
在终端执行命令:python basic_demo/cli_demo.py,然后我们就可以在终端与大模型进行交流了。
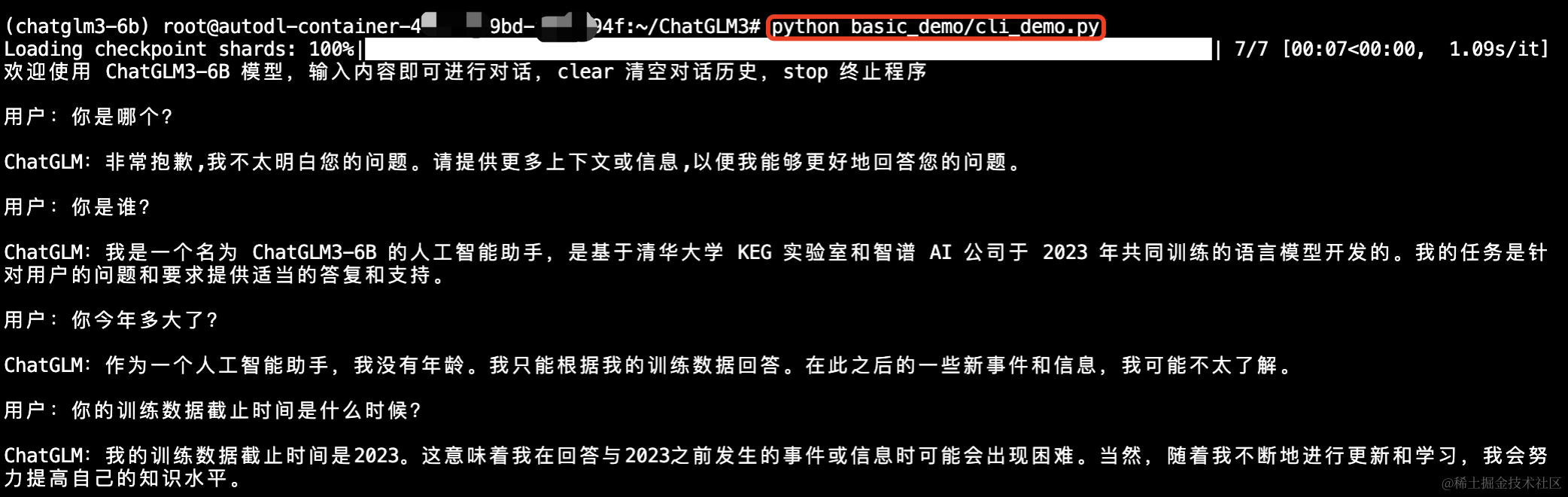
本地环境安装
注意需要13G显存以上的Nvidia显卡,否则跑不起来。这里以Windows系统为例。
首先本地要有一个Python的运行环境,建议使用 Anaconda,可以把它理解为一个Python集成环境,通过它我们可以方便的开发Python程序。Anaconda的官方下载地址是:www.anaconda.com/download
这个安装文件比较大,下载时间取决于你的网速,下载成功后按照提示一步步安装就行了。
安装成功后,启动“Anaconda Navigator”,在其中点击“Environments”->“base(root)” ->“Open Terminal”,打开终端。
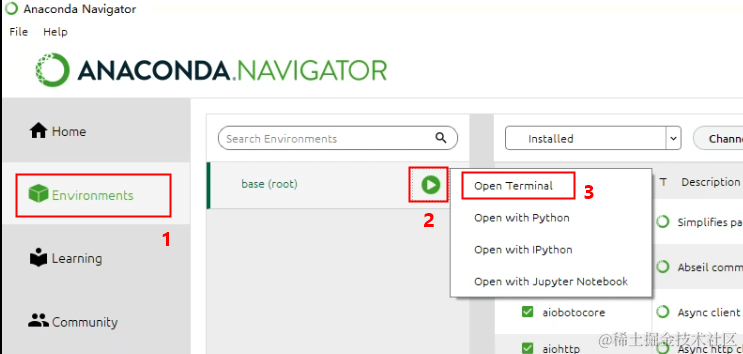
这是一个命令行工具,我们将主要在这里边通过执行命令安装ChatGLM3-6B。

然后我们还需要从Github上下载代码到本地,推荐使用Git,没有Git的同学可以先去安装一个:https://git-scm.com/。当然直接从Github下载程序包到本地也可以,不方便访问Github的同学也可以使用我整理的程序包,给公众号“萤火遛AI”发消息 ChatGLM3 即可获取。
这里我将程序放到了C盘下的ChatGLM3目录。
cd C:\
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
- 1
- 2
- 3
使用下边的命令创建一个Python的虚拟环境并激活,这样方便隔离不同项目对Python环境的不同要求。
conda create -n chatglm3-6b python=3.10.8
conda activate chatglm3-6b
- 1
- 2
然后还需要把相关模型文件下载到本地,为了防止下载方式失效,这里提供多种方法:
(1)下载AutoDL用户分享的模型,执行下边的命令,它会下载到 C:\ChatGLM3\THUDM,速度还可以。
pip install requests pip install codewithgpu cg down xxxiu/chatglm3-6b/config.json -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/configuration_chatglm.py -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/gitattributes -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/model.safetensors.index.json -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/MODEL_LICENSE -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/model-00001-of-00007.safetensors -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/model-00002-of-00007.safetensors -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/model-00003-of-00007.safetensors -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/model-00004-of-00007.safetensors -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/model-00005-of-00007.safetensors -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/model-00006-of-00007.safetensors -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/model-00007-of-00007.safetensors -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/modeling_chatglm.py -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/pytorch_model.bin.index.json -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/quantization.py -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/README.md -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/tokenization_chatglm.py -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/tokenizer.model -t C:\ChatGLM3\THUDM cg down xxxiu/chatglm3-6b/tokenizer_config.json -t C:\ChatGLM3\THUDM
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
(2)从HuggingFace的镜像下载,地址是:https://hf-mirror.com/THUDM/chatglm3-6b/tree/main
(3)给公众号“萤火遛AI”发消息 ChatGLM3 获取最新下载方式。
最后我们做一个简单的测试,执行命令:python basic_demo/cli_demo.py,然后我们就可以在终端与大模型进行交流了。
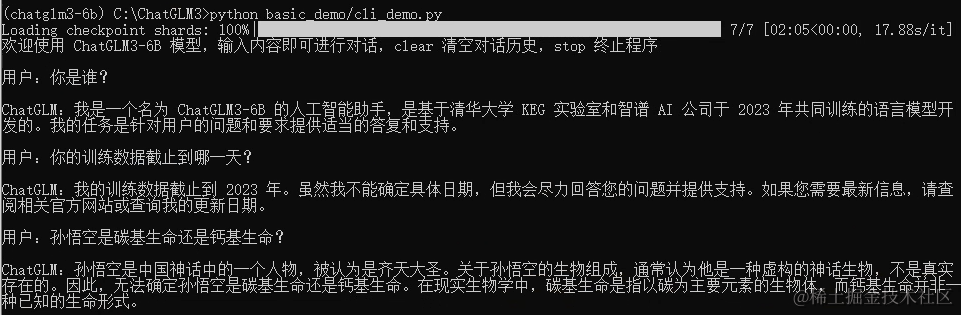
如果程序出现下边的错误:
RuntimeError: “addmm_impl_cpu_” not implemented for ‘Half’
首先确定你的电脑是安装了Nvida显卡的,然后使用下边的命令补充安装相关的pytorch-cuda包。
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidia
pip install chardet
- 1
- 2
使用WebUI体验
ChatGLM提供了一个Web界面,用户可以直接在这个页面上聊天、使用插件,以及执行Python代码,就像使用大多数的大语言模型一样。额外的用户还可以配置一些参数,比如一次生成Token的数量、系统提示词、采样的随机性控制等。
启动WebUI服务
首先修改程序中的模型目录,在下载程序中找到文件 composite_demo/client.py,修改 MODEL_PATH 为你的模型存放地址。

然后进入 ChatGLM3-6B 程序的根目录(根据自己的部署来),激活Python虚拟环境:
cd /root/ChatGLM3
conda activate chatglm3-6b
# conda如果不行就使用 source activate chatglm3-6b
- 1
- 2
- 3
因为需要执行代码,我们还要安装 Jupyter 内核:
ipython kernel install --name chatglm3-6b --user
- 1
并修改文件 composite_demo/demo_ci.py 中的 IPYKERNEL 的值为设置的值。

最后启动API服务器:streamlit run composite_demo/main.py 可知这个WebUI使用的是streamlit框架。

如果是在个人电脑上安装的,点击这里的连接就可以在浏览器访问了。
如果是在AutoDL上的实例,还需要再折腾一下。因为这个WebUI使用了WebSocket,但是AutoDL开放的外网端口不支持WebSocket。此时可以通过SSH隧道的方式来打通本地与AutoDL实例的网络。
我们需要类似下边这样的一条指令:
sudo ssh -CNg -L 8501:127.0.0.1:8501 root@connect.westb.seetacloud.com -p 12357
- 1
其中的 connect.westb.seetacloud.com 和 10757 需要替换成你自己实例的,在实例列表中复制登录指令。
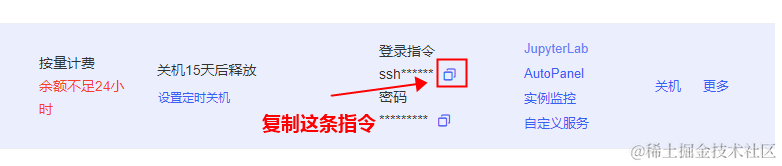
然后把它随便粘贴到一个地方,就可以得到所需的地址和端口号了:

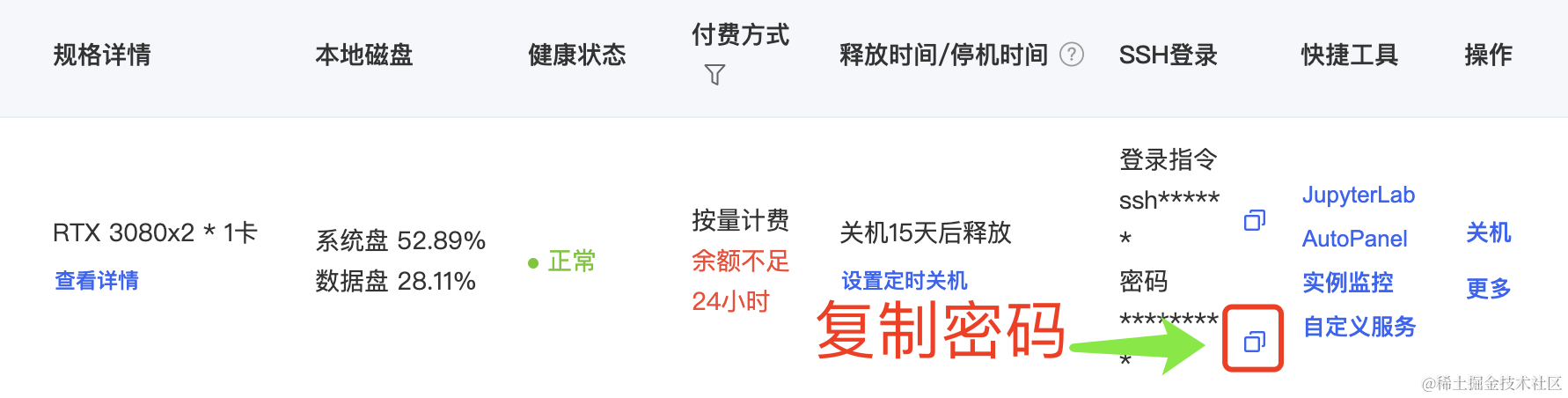
在个人电脑的终端或者命令行工具执行上边写好的指令,首先需要统一添加主机(输入 yes),然后需要输入主机登录密码,还是从AutoDL的实例列表拷贝。

登录成功后,这个界面会挂起,不会输出任何内容。此时我们在浏览器地址栏输入 http://127.0.0.1:8501 就可以访问了。
使用WebUI
这个WebUI左边是参数区域,右边是使用区域,有三种使用方式:Chat、Tool和Code Interpreter,分别就是聊天、工具或插件、代码解释器。相关参数我在之前的文章中介绍过,可以参考下:https://juejin.cn/post/7323449163420680202#heading-7

聊天就不用说了,我们看下工具或插件的使用。它会完整的展现出来插件的使用过程,用户询问问题,触发大模型调用插件,展现插件返回的内容,大模型整理插件返回的内容并输出给用户。中间的两个过程这里只是为了方便用户了解原理,其实可以在展现大模型返回值时将它们过滤掉。具体的可以修改这个文件中的第144行-198行:composite_demo/demo_tool.py 。

实例代码中提供了两个工具,一个是获取实时天气,另一个是生成随机数,用户还可以修改代码增加自己的工具插件,在 composite_demo/tool_registry.py 这个文件中。
只需要使用 @register_tool 装饰函数即可完成注册。对于工具声明,函数名称即为工具的名称,函数 docstring 即为工具的说明;对于工具的参数,使用 Annotated[typ: type, description: str, required: bool] 标注参数的类型、描述和是否必须。例如,get_weather 工具的注册如下:
@register_tool
def get_weather(
city_name: Annotated[str, 'The name of the city to be queried', True],
) -> str:
"""
Get the weather for `city_name` in the following week
"""
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
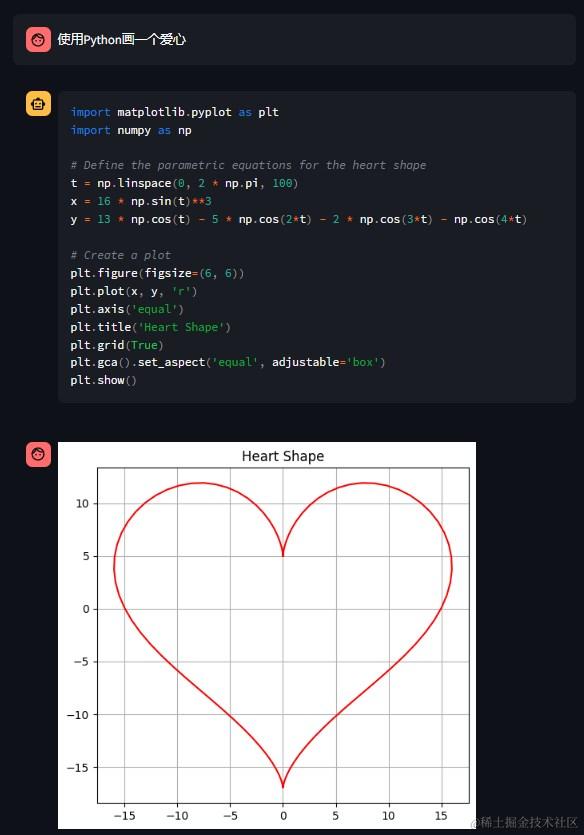
再看看代码解释器的效果,模型会根据对任务完成情况的理解自动地连续执行多个代码块,直到任务完成。比如让它用Python画一个爱心。

如果代码执行有错误,模型会自动修正错误,然后继续生成,直到能够正常执行成功。这个能力其实是通过系统提示词和observation角色实现的。
在 composite_demo/demo_ci.py 中可以看到提示词:

当程序执行出错的时候,程序会通过observation角色把错误再发给ChatGLM进行分析,然后ChatGLM会修改代码,再重新输出到程序中,最后使用 Jupyter 内核执行代码。
使用API开发应用
使用大模型API,我们可以完全自定义自己的交互页面,增加很多有趣的功能,比如提供联网能力。
这里我们使用的是ChatGLM3-6B自带的一个API示例程序,这个程序中有一个参考OpenAI接口规范开发的API服务,我们可以直接使用OpenAI的客户端进行调用,这避免了很多学习成本,降低了使用难度。
启动API服务
首先修改程序中的模型目录,在下载程序中找到文件 openai_api_demo/api_server.py,修改 MODEL_PATH 为你的模型存放地址。

然后进入 ChatGLM3-6B 程序的根目录(根据自己的部署来),激活Python虚拟环境:
cd C:\ChatGLM3
conda activate chatglm3-6b
# conda如果不行就使用 source activate chatglm3-6b
- 1
- 2
- 3
最后启动API服务器:python openai_api_demo/api_server.py

看到 running on http://0.0.0.0 的提示信息就代表启动成功了。
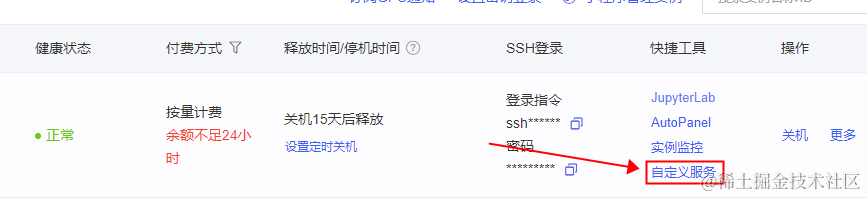
注意这里的端口号,如果你是在AutoDL部署的程序,需要将端口号修改为6006,然后才能通过AutoDL提供的“自定义服务”在外网访问,端口号在openai_api_demo/api_server.py 文件的最末尾。

修改后重启API服务,然后在AutoDL的容器实例列表中点击“自定义服务”,即可获取外网访问地址。
调用API服务
这里还是以Python为例,首先使用pip安装OpenAI的SDK。
pip install --upgrade openai httpx[socks]
- 1
我准备了两个简单的应用示例,一个是简单的聊天程序,另一个是在大模型中使用插件的方法。
先看聊天程序,这里让它扮演一个数学老师进行出题,之前我写过一篇文章介绍相关参数的含义,这里就不罗嗦了,需要的请看:https://juejin.cn/post/7323449163420680202
# 一个简单的聊天程序 from openai import OpenAI client = OpenAI(api_key='not-need-key',base_url="http://127.0.0.1:6006/v1") stream = client.chat.completions.create( messages=[{ "role": "system", "content": "你是一名数学老师,从事小学数学教育30年,精通设计各种数学考试题" },{ "role": "user", "content": "请给我出10道一年级的计算题。" }], model='chatglm3-6b', max_tokens=1024, #temperature=0.1, top_p=0.3, #frequency_penalty=0.5, presence_penalty=0.2, seed=12345, #stop='30年', response_format={ "type": "json_object" }, n=1, stream=True ) for chunk in stream: msg = chunk.choices[0].delta.content if msg is not None: print(msg, end='')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
下边是程序的执行结果,大模型理解的很正确,并生成了合理的输出。

再看大模型中使用插件的方法,这里让ChatGLM根据用户要求调用天气函数查询实时天气,注意ChatGLM3-6B调用函数的方法没有支持最新的OpenAI API规范,目前只实现了一半,能通过tools传入函数,但是响应消息中命中函数还是使用的 function_call,而不是最新的 tool_calls。相关参数我也在别的文章中做过详细介绍,请参考:https://juejin.cn/post/7325360810226630706
from openai import OpenAI import json import requests import time # 获取天气的方法 def get_city_weather(param): city = json.loads(param)["city"] r = requests.get(f"https://wttr.in/{city}?format=j1") data = r.json()["current_condition"] #print(json.dumps(data)) temperature = data[0]['temp_C'] humidity= data[0]['humidity'] text = data[0]['weatherDesc'][0]["value"] return "当前天气:"+text+",温度:"+temperature+ "℃,湿度:"+humidity+"%" # 天气插件的定义 weather_tool = { "type": "function", "function": { "name": "get_city_weather", "description": "获取某个城市的天气", "parameters": { "type": "object", "properties": { "city": { "type": "string", "description": "城市名称", }, }, "required": ["city"], }, } } # 创建OpenAI客户端,获取API Key请看文章最后 client = OpenAI(api_key='no-need-key', base_url="http://127.0.0.1:6006/v1") # 定义请求GPT的通用方法 def create_completion(): return client.chat.completions.create( messages=messages, model='chatglm3-6b', stream=False, tool_choice="auto", tools=[weather_tool] ) # 我的三个问题 questions = ["请问上海天气怎么样?","请问广州天气怎么样?","成都呢?","北京呢?"] # 聊天上下文,初始为空 messages=[] print("---GLM天气插件演示--- ") # 遍历询问我的问题 for question in questions: # 将问题添加到上下文中 messages.append({ "role": "user", "content": question, }) print("路人甲: ",question) # 请求GPT,并拿到响应 response_message = create_completion().choices[0].message # 把响应添加到聊天上下文中 messages.append(response_message) #print(response_message) # 根据插件命中情况,执行插件逻辑 if response_message.function_call is not None: function_call = response_message.function_call # 追加插件生成的天气内容到聊天上下文 weather_info = get_city_weather(function_call.arguments) #print(weather_info) messages.append({ "role": "function", "content": weather_info, "name": function_call.name }) # 再次发起聊天 second_chat_completion = create_completion() gpt_output = second_chat_completion.choices[0].message.content # 打印GPT合成的天气内容 print("GLM: ",gpt_output) time.sleep(0.2) # 将GPT的回答也追加到上下文中 messages.append({ "role": "assistant", "content": gpt_output, }) else: print("GLM: ",response_message.content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
执行效果如下:

以上就是本文的主要内容,有兴趣的快去体验下吧。
如何系统的去学习AI大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/在线问答5/article/detail/887229
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

