
- 1贪心算法-01:跳跃游戏_java 贪心算法跳跃游戏
- 2nginx 配置 TLS 加密方式 、密钥交换方式_nginx椭圆曲线加密
- 3解密阿里前端技术体系
- 4解锁、唤醒屏幕用到KeyguardManager,KeyguardLock,PowerManag_keyguardmanager.disablekeyguard 密码界面
- 5看破世态炎凉!吾儿大帝之姿30岁转行学习软件测试拿到13k+_30岁转行去做软件测试
- 6linux-conda环境安装配置教程
- 7基于SSM的网上商城系统设计与实现_基于ssm的网上商城的设计与实现
- 8【微信小程序】实现授权登入---超详细讲解_微信小程序登录_微信小程序 微信登录
- 9怎样在github上发布pre-release和release?(我跟着这个操作成功了)_github pre-release
- 10入门智能车 | 带你认识PID闭环控制 - 增量式PID实现电机速度闭环_增量式pid输出清零
Flink 流批一体场景应用及落地情况_flink的应用场景实例
赞
踩
摘要:本文由阿里云 Flink 团队苏轩楠老师撰写,旨在介绍 Flink 流批一体在几个常见场景下的应用。内容主要分为以下四个部分:
主要场景
落地情况
未来展望
总结
上篇:流批一体技术简介
在上篇文章中,给大家整体介绍了 Flink 流批一体的技术和挑战。使用流批一体的架构,可以避免维护两套系统的运维成本,减少存储链路的冗余和成本,以及降低用户的学习成本和开发成本。同时,使用统一的计算引擎,统一的代码可以更好地保证数据的一致性。今天,会给大家介绍一下,Flink 流批一体在几个常见场景下的应用,以及在公开途径收集了一些公司使用 Flink 流批一体的落地情况。
一、主要场景
我们在公开途径下,收集了近几年各个公司使用 Flink 流批一体的情况,目前 Flink 流批一体架构主要在数据湖仓、数据集成和特征计算的业务场景下应用较多。接下来,我们会详细的看一下,使用 Flink 流批一体是如何在这几个场景中发挥作用的。
1.数据湖仓
数据湖仓是 Flink 流批一体发挥重要作用的场景。我们以阿里云高级专家喻良,在 Flink Forward Asia 2023 主会场的分享,来介绍一下使用 Flink + Paimon + Hologres 来构建湖仓一体数据分析[1]。
Apache Paimon 是一个专为实时数据处理而设计的湖表格式,它最大的亮点是使用了 LSM Tree 技术。与 Hudi 相比,Paimon 在更新插入(Upsert)操作上速度快了4倍,查询扫描(Scan)速度也提高了10倍。这意味着它能提供更快的响应速度,同时降低数据入湖的成本,并且让开发者用起来更高效。Paimon 社区十分活跃,很多产品都在迅速与其兼容,这让它的生态系统发展得比其他湖库表格式更快、更全面。
Hologres 是阿里云推出的面向数据服务层设计的统一的数据平台,可以将 OLAP 引擎查询、即席分析、在线服务、向量计算等多个数据应用构建在统一存储上,实现一份数据多种计算。性能上,Hologres 在 TPC-H 30TB 上排名世界第一。近两年的双十一, Hologres 在阿里集团内部的峰值写入达到 10 亿每秒。另外,在信通院的测试中,Hologres 基于 Serverless 能力,可以把节点的规模推到 8192 节点,实现了超大规模的 OLAP 引擎。
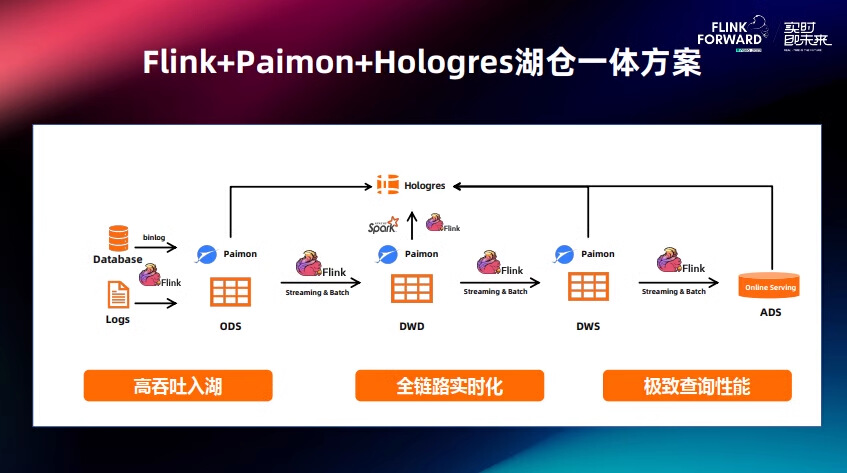
图片来源:Flink Forward Asia 2023 - Flink+Paimon+Hologres构建实时湖仓数据分析 [1]
Flink + Paimon + Hologres 流式湖仓方案将 3 个产品做了非常紧密的结合,首先使用 Flink 流批一体计算引擎将数仓以 Paimon 格式在湖上构建,使用 Flink 完成数仓 ODS 到 DWD 层,DWS 和 ADS 的计算。通过使用 Hologres 对各层数仓做统一的 OLAP 查询和 ADS 层在线分析。基于 Paimon 可以实现高吞吐入湖;基于 Flink 可以实现全链路的流批一体计算,基于 Hologres 可以实现高性能的 OLAP 查询,所以整个链路从实时性、时效性、成本几个方面都可以取得比较好的平衡。
在数据湖仓场景下,使用 Flink 可以完成复杂的数据拼接以及聚合计算,并且达到很高的实时性的要求。另外,实时链路在使用的过程中不可避免的会因为一些数据延迟等问题导致会有数据修正和数据回溯的需求。Flink 流批一体的特性能够让用户方便的使用与实时链路一样的作业代码,高效地完成数据修正和数据回溯的需求。
2. 数据集成/数据同步
大多公司都有数据导入和导出的需求,基于 Flink 丰富的生态可以非常方便地实现不同场景的数据集成。并且,借助 Flink 流批一体的能力,同时支持离线集成和实时集成。我们以小米在 2021 年 Flink Forward Asia 的演讲[2],来介绍一下 Flink 流批一体在数据集成场景下的应用。小米把数据集成的使用场景分为三类:离线集成、实时集成以及流批混合的数据集成。
2.1 离线集成和实时集成
对于单纯的离线或实时集成的需求,借助 Flink 的生态,可以非常方便地实现不同系统数据导入导出的需求。同时基于 Flink SQL 可以非常方便地实现字段的映射。对于实时集成的需求,也可以使用 Flink CDC 来做到存增量一体的数据实时同步。
2.2 流批混合数据集成
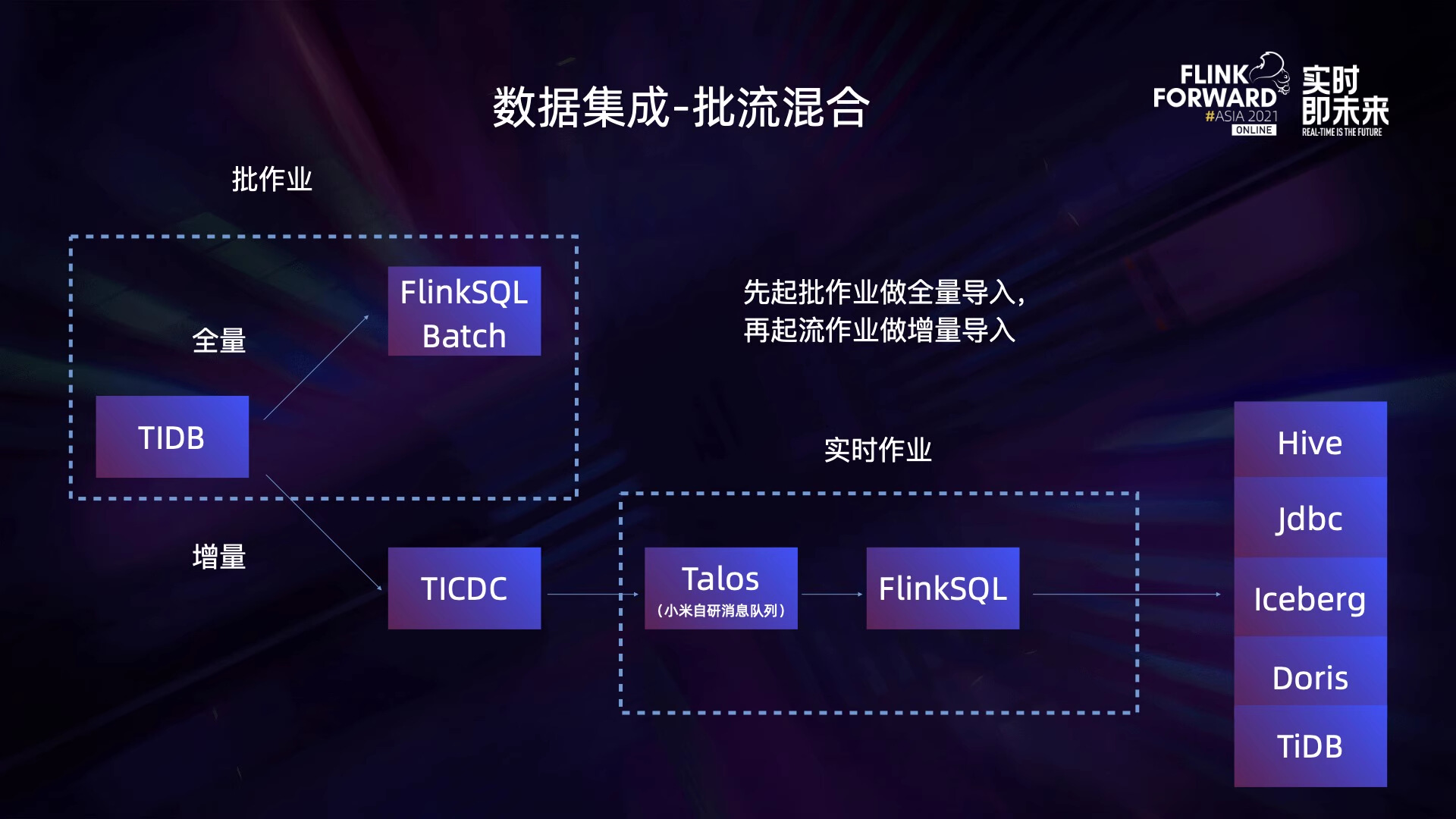
图片来源:Flink Forward Asia 2021 - Flink 流批一体在小米的实践 [2]
小米在实际的使用中还需要使用到流批混合的同步方式以适用不同的场景, 比如分库分表场景, 部分链路重做场景,新增库表等场景。例如,他们在支持 TiDB 的数据收集和转储时,无法直接使用 Hybrid Source,因为 TiDB 的全量数据往往非常大,他们需要使用大量并发来加速全量数据的转储,而增量数据则只需要较小并发即可。所以,在全量数据部分他们会使用批作业来完成,通过灵活调整并发,以获得更高的处理效率,增量部分则以较小的并发能转储即可,以节省资源。
3. 特征计算
在推荐系统的整个数据处理链路中,流式处理和批式处理都占据着重要的位置。尤其是在特征计算模块,推荐系统需要为用户实时地推荐信息流,保证实时性和准确性,同时也需要进行模型训练以提升推荐准确性。我们以字节跳动的推荐系统为例,向大家介绍字节跳动是如何使用 Flink 流批一体来完成特征计算场景的[3]。

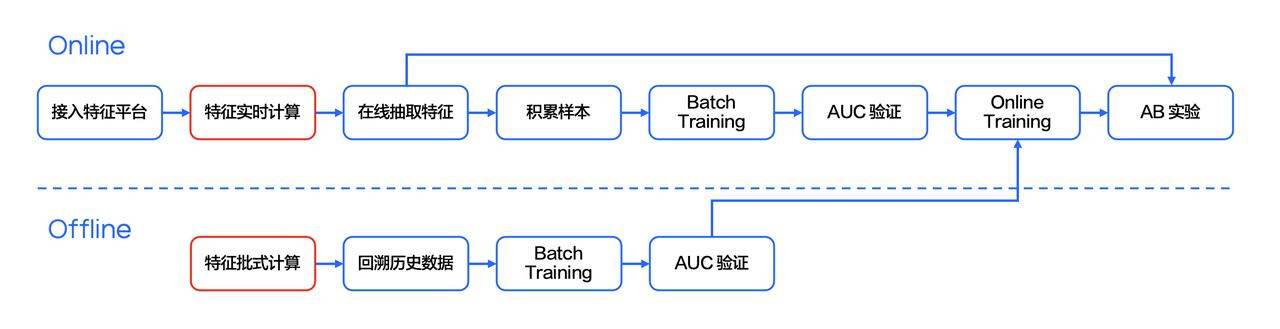
图片来源:Flink 流批一体在字节跳动的探索与实践 [3]
如上图所示,在字节跳动的推荐系统中,同时存在实时链路与离线链路。实时链路从收到用户的请求开始,接着系统会获取用户的实时在线特征。这些实时在线特征经过实时的流式处理之后,再结合在线特征库,就可以得到一个比较庞大的特征组。随后,将整个特征组输入到在线预测模型中,就可以得到预测的结果,从而实时地为用户推荐信息流。
与此同时,这些特征也会被存入离线存储(例如 HDFS)中,后续这些特征会被用于线下的模型离线训练。对于离线训练来说,存入 HDFS 中的数据,经过批式的 ETL 处理后,输入到离线的模型训练中,训练出的模型可以用于更新在线服务的模型,从而更准确地服务用户。
字节跳动的推荐系统使用 Flink SQL 的方式同时处理流式任务和批式任务,实现整个计算链路的流批一体。通过 Flink SQL 实现流批一体后,整个数据链路在计算的速度、特征的迭代,及业务降本增效上都取得了极大的成果。
图片来源:Flink 流批一体在字节跳动的探索与实践 [3]
如上图所示,推荐系统中,特征工程师经常会给模型添加特征进行实验。因此会需要回溯历史的数据,把新的特征计算出来,作为模型训练数据。线上的模型也需要定期的更新,保证在线推荐的准确性。使用 Flink SQL 实现了流批计算一体后,可以用同一套代码去进行实时计算和批式计算,批式计算可以使用与实时计算同样的代码进行历史数据的回溯,这就保证了数据一致。
二、落地情况
Flink 流批一体目前在各个公司都有大规模的落地场景,也为各个公司带来了很多的成本收益。我们从公开途径收集了近些年来,各个公司使用的流批一体的落地情况。
1. 阿里巴巴

图片来源:Flink Forward Asia 2022 - 流批一体在 AI 核心电商领域的探索与实践 [4]
上图列举了 2022 年,阿里巴巴 SARO(Search, Advertisement and Recommendation Offline) 平台上支持的部分业务。到目前为止,平台拥有千级应用规模,日管理万级作业量,PB 级日处理数据量,百万级增量 TPS,秒级增量延时,连续六年成功支持双十一[4]。

图片来源:Flink Forward Asia 2020 - 流批一体技术在天猫双11的应用 [5]
天猫作为 Flink 流批一体最早期的使用者,在 2020 年就有大规模的落地,上图列举了 2022 年,天猫流批一体落地的实践效果[5]。
2. 字节跳动

图片来源:Flink Forward Asia 2023 - 流批一体在字节跳动的大规模落地实践 [6]
随着 Flink 引擎流批一体能力的完善,在字节跳动在 2023 年将离线数据同步场景下的 2.2万多 Spark SQL 作业迁移至 Flink Batch SQL。目前,每日调度的 Flink batch 作业实例数达到 5 万多个。作业整体的运行时间减少了 29%,CPU 使用率也有明显的减少[6]。
3. 快手

图片来源:Flink Forward Asia 2022 - 流批一体架构在快手的实践和思考 [7]
2022 年,在快手内部,Flink 的体量无论从作业规模还是集群规模上,相对于去年都有大幅的提升,上图列了几个关键数据。峰值的 TPS 达到了每秒 13 亿,作业数量上流作业有 6000 多个,其中批作业也到了 3000 个,物理资源上已经有 70 万 Core[7]。
4. Shopee

图片来源:Flink Forward Asia 2022 - Flink 流批一体在 Shopee 的大规模实践 [8]
Shopee 在 2022 年除了流任务,仅从支持的批任务来看,Flink 平台上的作业已经到达了一个比较大的规模。目前 Flink 批任务已经在 Shopee 内部超过 60 个 Project 上使用,作业数量也超过了 1000,这些作业在调度系统的支持下,每天会生成超过 5000 个实例来支持各个业务线[8]。
三、未来展望
Flink 流批一体经过多年的发展,许多企业和用户已经可以十分顺畅地把 Flink 流批一体在他们的生产环境中落地。虽然,Flink 流批一体已经达到生产可用的状态,但是社区也看到仍然有不少需要继续投入的地方。下面我们会简单介绍一些流批一体相关的工作:
- **流批一体 API:**目前 Flink 不论是 SQL 还是 DataStream 的 API 都可以使用同一套 API 进行流批两种不同任务的开发。但是我们发现在一些情况下,这样开发出来的流任务和批任务的代码并不相同,还没有真正做到一次开发,任意切换两种模式运行。目前 Flink 社区在 SQL 领域正在探讨一种新的流批统一的语法语义,通过 Materialized Table 来简化流批一体的数据管道的定义[9]。用户可以不需要手动指定作业是使用流模式还是批模式来运行,只需要通过 Flink SQL materialzed table 定义自己的业务逻辑并且指定需要的数据新鲜度。Flink 会根据作业新鲜度的要求来决定作业执行的模式。
- **Apache Celeborn + Hybrid Shuffle:**大规模批处理往往需要依赖存算分离的 Remote Shuffle Service。 Apache Celeborn 是一个致力于提供通用的大数据 RSS 解决方案的开源项目。并且 Flink 提出了全新的 Hybrid Shuffle 模式,能够结合流跟批两种不同 Shuffle 的优势,可以说是专门面向流批一体的 Shuffle 模式。Flink 社区目前正在和 Celeborn 社区合作,打造 Hybrid Shuffle 模式和 Apache Celeborn 的集成方案。[10]
- JobManager 容错: 目前,Flink 已经可以做到单 task 级别的容错,但是一旦 JM 节点发生故障,仍旧需要重新运行整个作业,包括已经完成计算并且产出结果的任务,代价非常高。目前 Flink 社区通过 JM Failover 方案 [11],使得作业在 JM 发生故障时恢复已经完成的任务的计算结果,从而大幅降低 JM Failover 的代价。目前该功能已经完成了实现,会在 Flink 1.20 版本发布。
- **流批融合:**有了优秀的流、批处理能力之后,Flink 社区还想进一步打破流、批两种模式之间的边界。因此,社区提出了流批融合的概念,希望引擎能够自动识别作业对于高吞吐或低延迟的需求倾向性,自动选择合适的流/批模式执行,并且当作业运行过程中状态和需求倾向性发生变化时能够自动进行动态切换。
四、总结
我们能够看到 Flink 流批融合在很多的企业和用户的生产场景中落地和使用,帮助他们简化了大数据处理的架构以及降低了成本。与此同时,大家在使用过程中也总结出了非常多的最佳实践,很多企业和用户在使用过程中把遇到的问题和需求反馈给社区,还有很多开发者积极地加入了开源社区的开发工作。Flink 流批一体的发展离不开社区用户的投入,我们希望 Flink 流批一体的能力能被更多的用户尝试,同时让更多的人加入到 Flink 流批一体的社区工作中。
[1] https://flink-learning.org.cn/article/detail/84f501725034542a7f41e0670645c714
[2] https://flink-learning.org.cn/article/detail/58e70ce6b228946ceca2e09582ba8e18
[3] https://developer.volcengine.com/articles/7141207081436053517
[4] https://flink-learning.org.cn/article/detail/e7c357aec430739793d626ace569e0b9
[5] https://www.bilibili.com/video/BV1164y1o7yc/
[6] https://developer.aliyun.com/live/253626
[7] https://flink-learning.org.cn/article/detail/110131b6a6c6c707c647459726ef039a
[8] https://flink-learning.org.cn/article/detail/68d50223a5fcd42bc3cc75eb37eb4ea4
[10] https://flink-learning.org.cn/article/detail/a5a8aa8ffb1b711df274cd13b7e29d44
欢迎大家加入 Flink Batch 交流钉钉群。本群旨在为 Flink Batch 爱好者提供一个交流技术和传递资讯的平台,在这里:
- 你可以掌握Flink Batch前沿的资讯,可以与 Flink 开发者及 Committer 面对面交流
- Flink Batch 的问题集中解决,各位开发者及 Committer 及时解决你的 Blocker
“Flink Batch 交流群”群的钉钉群号: 34817520

