
- 1黑龙江大学计算机考研资料汇总_黑大909和903的区别
- 2Excel 支持运行 Python 代码,做表格也要学编程了?_excel可以编程代码吗
- 3SFT指令微调大模型后,感觉LLM变傻了_微调 容易 变傻
- 4【算法】隐马尔科夫HMM之Viterbi维特比算法原理_已知观测序列o=(红,黑,红),利用维比特算法试求最优状态序列,即最优路径i*=(i1
- 5AI系统Spark原理与代码实战案例讲解_sparkai系统
- 6汇总大厂-校招/社招 Java面试题_spring大厂面试题
- 7【软件工程笔记3】——需求管理_软件工程需求管理
- 8获取客户端真实IP
- 9ARM处理器有哪些工作模式和寄存器?各寄存器作用是什么?ARM异常中断处理流程?_异常中断 lr寄存器
- 10排序算法之折半插入排序
内行人都在学的大模型黑书 外网爆火的LLM应用手册来了!(文末送)
赞
踩

Transformer模型介绍
Transformer 是工业化、同质化的后深度学习模型,其设计目标是能够在高性能计算机(超级计算机)上以并行方式进行计算。通过同质化,一个Transformer 模型可以执行各种任务,而不需要微调。Transformer 使用数十亿参数在数十亿条原始未标注数据上进行自监督学习。
这些后深度学习架构称为基础模型。基础模型Transformer 是始于 2015年的第四次工业革命的一部分(通过机器-机器自动化将万物互联)。工业4.0(I4.0)的 AI,特别是自然语言处理(NLP)已经远远超越了过往时代,颠覆了以往的开发范式。
Transformer 架构具有革命性和颠覆性,它打破了过往RNN和CNN 的主导地位。BERT 和GPT模型放弃了循环网络层,使用自注意力机制取而代之。Transformer 模型优于RNN和CNN,这是AI历史上划时代的重大变化,Transformer模型标示着AI新时代的开始。
图源《基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理》
掌握Transformer 模型的必读书
在不到4 年的时间里,Transformer 模型以其强大的性能和创新的思想,迅速在NLP 社区崭露头角,打破了过去30 年的记录。BERT、T5 和GPT 等模型现在已成为计算机视觉、语音识别、翻译、蛋白质测序、编码等各个领域中新应用的基础构件。因此,斯坦福大学最近提出了“基础模型”这个术语,用于定义基于巨型预训练Transformer 的一系列大型语言模型。所有这些进步都归功于一些简单的想法。
《基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理》可作为所有对Transformer 工作原理感兴趣的人的参考书。作者在理论和实践两方面都做出了出色的工作,详细解释了如何逐步使用Transformer。阅读完本书后,你将能使用这一最先进的技术集合来增强你的深度学习应用能力。本书在详细介绍BERT、RoBERTa、T5 和GPT-3 等流行模型前,先讲述了Transformer 的架构以便为你的学习奠定坚实基础。本书还讲述了如何将Transformer 应用于许多用例,如文本摘要、图像标注、问答、情感分析和假新闻分析等。如果你对这些主题感兴趣,那么本书绝对是值得一读的。
图源《基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理》
内容简介
Transformer正在颠覆AI领域。市面上有这么平台和Transformer模型,哪些最符合你的需求?本书将引领你进入Transformer的世界,将讲述不同模型和平台的优势,指出如何消除模型的缺点和问题。本书将引导你使用Hugging Face从头开始预训练一个RoBERTa模型,包括构建数据集、定义数据整理器以及训练模型等。
《基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理》分步展示如何微调GPT-3等预训练模型。研究机器翻译、语音转文本、文本转语音、问答等NLP任务,并介绍解决NLP难题的技术,甚至帮助你应对假新闻焦虑(详见第13章)。
从书中可了解到,诸如OpenAI的高级平台将Transformer扩展到语言领域、计算机视觉领域,并允许使用DALL-E 2、ChatGPT和GPT-4生成代码。通过本书,你将了解到Transformer的工作原理以及如何实施Transformer来决NLP问题。
主要内容
• 了解用于解决复杂语言问题的新技术
• 将GPT-3与T5、GPT-2和基于BERT的Transformer的结果进行对比
• 使用TensorFlow、PyTorch和GPT-3执行情感分析、文本摘要、非正式语言分析、机器翻译等任务
• 了解ViT和CLIP如何标注图像(包括模糊化),并使用DALL-E从文本生成图像
• 学习ChatGPT和GPT-4的高级提示工程机制
目录
第1 章 Transformer 模型介绍 1
1.1 Transformer 的生态系统 2
1.1.1 工业4.0 2
1.1.2 基础模型 3
1.2 使用Transformer 优化NLP模型 6
1.3 我们应该使用哪些资源 8
1.3.1 Transformer 4.0 无缝API 的崛起 9
1.3.2 选择即用型API驱动库 11
1.3.3 选择Transformer模型 11
1.3.4 工业4.0 AI 专家的技能要求 12
1.4 本章小结 13
1.5 练习题 14
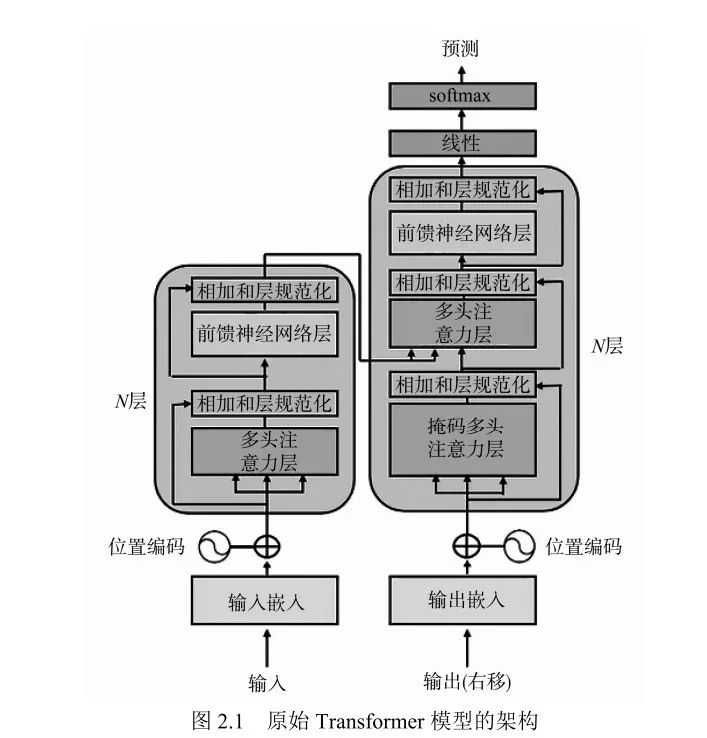
第2 章 Transformer 模型架构入门 15
2.1 Transformer 的崛起:注意力就是一切 16
2.1.1 编码器堆叠 17
2.1.2 解码器堆叠 37
2.2 训练和性能 40
2.3 Hugging Face 的Transformer模型 40
2.4 本章小结 41
2.5 练习题 42
第3 章 微调BERT 模型 43
3.1 BERT 的架构 44
3.2 微调BERT 50
3.2.1 选择硬件 50
3.2.2 安装使用BERT 模型必需的Hugging Face PyTorch接口 50
3.2.3 导入模块 50
3.2.4 指定Torch 使用CUDA 51
3.2.5 加载数据集 51
3.2.6 创建句子、标注列表以及添加[CLS]和[SEP]词元 53
3.2.7 激活BERT 词元分析器 53
3.2.8 处理数据 54
3.2.9 防止模型对填充词元进行注意力计算 54
3.2.10 将数据拆分为训练集和验证集 54
3.2.11 将所有数据转换为torch张量 55
3.2.12 选择批量大小并创建迭代器 55
3.2.13 BERT 模型配置 56
3.2.14 加载Hugging Face BERTuncased base 模型 57
3.2.15 优化器分组参数 59
3.2.16 训练循环的超参数 59
3.2.17 训练循环 60
3.2.18 对训练进行评估 61
3.2.19 使用测试数据集进行预测和评估 62
3.2.20 使用马修斯相关系数进行评估 63
3.2.21 各批量的分数 63
3.2.22 整个数据集的马修斯评估 64
3.3 本章小结 64
3.4 练习题 65
第4 章 从头开始预训练RoBERTa模型 66
4.1 训练词元分析器和预训练Transformer 67
4.2 从头开始构建Kantai BERT 68
4.2.1 步骤1:加载数据集 68
4.2.2 步骤2:安装HuggingFace transformers 库 69
4.2.3 步骤3:训练词元分析器 70
4.2.4 步骤4:将词元化结果保存到磁盘上 72
4.2.5 步骤5:加载预训练词元分析器文件 73
4.2.6 步骤6:检查训练用机器的配置:GPU 和CUDA 74
4.2.7 步骤7:定义模型的配置 75
4.2.8 步骤8:为Transformer模型加载词元分析器 75
4.2.9 步骤9:从头开始初始化模型 75
4.2.10 步骤10:构建数据集 79
4.2.11 步骤11:定义数据整理器 80
4.2.12 步骤12:初始化训练器 80
4.2.13 步骤13:预训练模型 81
4.2.14 步骤14:将最终模型(+词元分析器+配置)保存到磁盘 81
4.2.15 步骤15:使用FillMask-Pipeline 进行语言建模 82
4.3 后续步骤 83
4.4 本章小结 83
4.5 练习题 84
第5 章 使用Transformer 处理下游NLP 任务 85
5.1 Transformer 的转导与感知 86
5.1.1 人类智能栈 86
5.1.2 机器智能栈 88
5.2 Transformer 性能与人类基准 89
5.2.1 评估模型性能的度量指标 89
5.2.2 基准任务和数据集 90
5.2.3 定义SuperGLUE 基准任务 94
5.3 执行下游任务 99
5.3.1 语言学可接受性语料库(CoLA) 99
5.3.2 斯坦福情绪树库(SST-2) 100
5.3.3 Microsoft 研究释义语料库(MRPC) 101
5.3.4 Winograd 模式 102
5.4 本章小结 102
5.5 练习题 103
第6 章 机器翻译 104
6.1 什么是机器翻译 105
6.1.1 人类转导和翻译 105
6.1.2 机器转导和翻译 106
6.2 对WMT 数据集进行预处理 106
6.2.1 对原始数据进行预处理 107
6.2.2 完成剩余的预处理工作 109
6.3 用BLEU 评估机器翻译 112
6.3.1 几何评估 112
6.3.2 平滑技术 114
6.4 Google 翻译 115
6.5 使用Trax 进行翻译 116
6.5.1 安装Trax 116
6.5.2 创建原始Transformer模型 117
6.5.3 使用预训练权重初始化模型 117
6.5.4 对句子词元化 117
6.5.5 从Transformer解码 118
6.5.6 对翻译结果去词元化并展示 118
6.6 本章小结 119
6.7 练习题 119
第7 章 GPT-3 120
7.1 具有GPT-3 Transformer模型的超人类NLP 121
7.2 OpenAI GPT Transformer模型的架构 122
7.2.1 10 亿参数Transformer模型的兴起 122
7.2.2 Transformer 模型扩大的历史 123
7.2.3 从微调到零样本 125
7.2.4 解码器堆叠 126
7.2.5 GPT 引擎 127
7.3 使用GPT-2 进行文本补全 127
7.4 训练自定义GPT-2 语言模型 129
7.5 使用OpenAI GPT-3 131
7.5.1 在线运行NLP 任务 131
7.5.2 GPT-3 引擎入门 133
7.6 比较GPT-2 和GPT-3 的输出 138
7.7 微调GPT-3 139
7.7.1 准备数据 139
7.7.2 微调GPT-3 140
7.8 工业4.0 AI 专家所需的技能 141
7.9 本章小结 142
7.10 练习题 143
第8 章 文本摘要(以法律和财务文档为例) 144
8.1 文本到文本模型 145
8.1.1 文本到文本Transformer模型的兴起 145
8.1.2 使用前缀而不是任务格式 146
8.1.3 T5 模型 147
8.2 使用T5 进行文本摘要 149
8.2.1 Hugging Face 149
8.2.2 初始化T5-large模型 150
8.2.3 使用T5-large 进行文本摘要 153
8.3 使用GPT-3 进行文本摘要 158
8.4 本章小结 159
8.5 练习题 160
第9 章 数据集预处理和词元分析器 161
9.1 对数据集进行预处理和词元分析器 162
9.1.1 最佳实践 162
9.1.2 Word2Vec 词元化 165
9.2 深入探讨场景4 和场景5 174
9.2.1 使用GPT-2 生成无条件样本 174
9.2.2 生成条件样本 176
9.2.3 控制词元化数据 177
9.3 GPT-3 的NLU 能力 180
9.4 本章小结 181
9.5 练习题 181
第10 章 基于BERT 的语义角色标注 183
10.1 SRL 入门 184
10.1.1 语义角色标注的定义 184
10.1.2 使用基于BERT 的预训练模型进行SRL 185
10.2 基于BERT 模型的SRL
实验 186
10.3 基本示例 187
10.3.1 示例1 187
10.3.2 示例2 189
10.3.3 示例3 191
10.4 复杂示例 193
10.4.1 示例4 193
10.4.2 示例5 195
10.4.3 示例6 196
10.5 SRL 的能力范围 197
10.5.1 谓语分析的局限性 198
10.5.2 SRL 局限性的根本原因 199
10.6 本章小结 200
10.7 练习题 201
第11 章 使用Transformer 进行问答 202
11.1 方法论 203
11.2 方法0:试错法 204
11.3 方法1:NER 206
11.4 方法2:SRL 211
11.4.1 使用ELECTRA 进行问答 213
11.4.2 项目管理约束 214
11.4.3 通过SRL 查找问题 215
11.5 后续步骤 219
11.5.1 使用RoBERTa 模型探索Haystack 220
11.5.2 使用GTP-3 引擎探索问答 221
11.6 本章小结 222
11.7 练习题 222
第12 章 情绪分析 224
12.1 入门:使用Transformer进行情绪分析 225
12.2 斯坦福情绪树库(SST) 225
12.3 通过情绪分析预测客户行为 229
12.3.1 使用DistilBERT 进行情绪分析 229
12.3.2 使用Hugging Face 的其他模型进行情绪分析 231
12.4 使用GPT-3 进行情绪分析 235
12.5 工业4.0 依然需要人类 236
12.5.1 使用SRL 进行调查 237
12.5.2 使用Hugging Face进行调查 238
12.5.3 使用GPT-3 playground进行调查 240
12.6 本章小结 242
12.7 练习题 243
第13 章 使用Transformer 分析假新闻 244
13.1 对假新闻的情绪反应 245
13.2 理性处理假新闻的方法 250
13.2.1 定义假新闻解决路线图 251
13.2.2 枪支管控辩论 252
13.2.3 美国前总统特朗普的推文 260
13.3 在我们继续之前 262
13.4 本章小结 262
13.5 练习题 263
第14 章 可解释AI 264
14.1 使用BertViz 可视化Transformer 265
14.2 LIT 268
14.2.1 PCA 269
14.2.2 运行LIT 269
14.3 使用字典学习可视化Transformer 271
14.3.1 Transformer 因子 271
14.3.2 LIME 272
14.3.3 可视化界面 273
14.4 探索我们无法访问的模型 276
14.5 本章小结 277
14.6 练习题 278
第15 章 从NLP 到计算机视觉 279
15.1 选择模型和生态系统 280
15.2 Reformer 281
15.3 DeBERTa 283
15.4 Transformer 视觉模型 285
15.4.1 ViT – Vision Transformer 285
15.4.2 CLIP 289
15.4.3 DALL-E 294
15.5 不断扩大的模型宇宙 297
15.6 本章小结 298
15.7 练习题 299
第16 章 AI 助理 300
16.1 提示工程 301
16.1.1 具有有意义上下文的非正式英语 302
16.1.2 转喻和多义 303
16.1.3 省略 303
16.1.4 模糊上下文 304
16.1.5 引入传感器 305
16.1.6 有传感器但没有可见上下文 305
16.1.7 没有上下文的正式英语会话 306
16.1.8 提示工程训练 306
16.2 Copilot 307
16.3 可以执行领域特定任务的GPT-3 引擎 309
16.3.1 为ML 算法提供嵌入 309
16.3.2 生成一系列操作指示 315
16.3.3 内容过滤器 316
16.4 基于Transformer 的推荐系统 317
16.4.1 通用序列 317
16.4.2 使用MDP 和RL 生成的数据集模拟消费者行为 319
16.5 计算机视觉 323
16.6 数字人和元宇宙 325
16.7 本章小结 326
16.8 练习题 326
第17 章 ChatGPT 和GPT-4 327
17.1 超越人类NLP 水平的Transformer 模型:ChatGPT和GPT-4 328
17.1.1 如何充分理解本章 328
17.1.2 谁拥有AI 生成内容的版权 329
17.2 ChatGPT API 332
17.3 使用ChatGPT Plus 编写程序并添加注释 334
17.3.1 设计提示 334
17.3.2 使用ChatGPT Plus编写代码 335
17.3.3 ChatGPT Plus 绘制输出结果 336
17.4 GPT-4 API 337
17.4.1 示例1:使用GPT-4帮助解释如何编写代码 337
17.4.2 示例2:GPT-4 创建一个函数来展示Greg Brockman 于2023 年3月14 日的GPT-4 的YouTube 演示 338
17.4.3 示例3:GPT-4 创建一个用于展示WikiArt 图像的应用程序 338
17.4.4 示例4:GPT-4 创建一个用于展示IMDb 评论的应用程序 339
17.4.5 示例5:GPT-4 创建一个用于展示新闻源的应用程序 340
17.4.6 示例6:GPT-4 创建一个k-means 聚类(kmc)算法 341
17.4.7 示例7:GPT-4 关于GPT-4 和GPT 模型架构的对话 341
17.5 高级示例 342
17.5.1 步骤1:为ChatGPT和GPT-4 构建知识库 343
17.5.2 步骤2:添加关键词和解析用户请求 343
17.5.3 步骤3:构建引导ChatGPT 的提示 344
17.5.4 步骤4:内容审核和质量控制 344
17.6 可解释AI(XAI)和Whisper语音模型 345
17.7 使用DALL-E 2 API入门 349
17.7.1 创建新图像 349
17.7.2 创建图像的变体 350
17.8 将所有内容整合在一起 351
17.9 本章小结 352
17.10 练习题 353
——以下资源可扫描封底二维码下载——
附录A Transformer 模型术语 354
附录B Transformer 模型的硬件约束 356
附录C 使用GPT-2 进行文本补全 362
附录D 使用自定义数据集训练GPT-2 模型 371
附录E 练习题答案 380
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/在线问答5/article/detail/907698?site
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

