
热门标签
热门文章
- 1解读:DUSt3R: Geometric 3D Vision Made Easy
- 2基于springboot实现社区智慧养老监护管理平台系统项目【项目源码+论文说明】_基于springboot的养老院管理系统
- 3Failed to build gevent Could not build wheels for gevent which use PEP 517 ... ...
- 4SparkStreaming的案例及应用_sparkstreaming案例
- 5阿里终于开源数字人技术!!
- 6warning: LF will be replaced by CRLF问题解决方法_warning lf will be replaced by crlf
- 7Time-LLM :超越了现有时间序列预测模型的学习器
- 8LeetCode:242.有效字母的异位词
- 9STM32第二十二课:LVGL的移植和屏幕创建(7.11版本)_移植lvgl教程
- 10Java项目:基于SSM框架实现的健康综合咨询问诊平台【ssm+B/S架构+源码+数据库+毕业论文】
当前位置: article > 正文
【模型架构】学习RNN、LSTM、TextCNN和Transformer以及PyTorch代码实现_textcnn lstm
作者:在线问答5 | 2024-08-04 13:38:46
赞
踩
textcnn lstm
一、前言
在自然语言处理(NLP)领域,模型架构的不断发展极大地推动了技术的进步。从早期的循环神经网络(RNN)到长短期记忆网络(LSTM)、Transformer再到当下火热的Mamba(放在下一节),每一种架构都带来了不同的突破和应用。本文将详细介绍这些经典的模型架构及其在PyTorch中的实现,由于我只是门外汉(想扩展一下知识面),如果有理解不到位的地方欢迎评论指正~。
个人感觉NLP的任务本质上是一个序列到序列的过程,给定输入序列 ,要通过一个函数实现映射,得到输出序列
,这里的x1、x2、x3可以理解为一个个单词,NLP的具体应用有:
-
机器翻译:将源语言的句子(序列)翻译成目标语言的句子(序列)。
-
文本生成:根据输入序列生成相关的输出文本,如文章生成、对话生成等。
-
语音识别:将语音信号(序列)转换为文本(序列)。
-
文本分类:尽管最终输出是一个类别标签,但在一些高级应用中,也可以将其看作是将文本序列映射到某个特定的输出序列(如标签序列)。
二、RNN和LSTM
2.1 RNN
循环神经网络(RNN)是一种适合处理序列数据的神经网络架构。与传统的前馈神经网络(线性层)不同,RNN具有循环连接,能够在序列数据的处理过程中保留和利用之前的状态信息。网络结构如下所示:
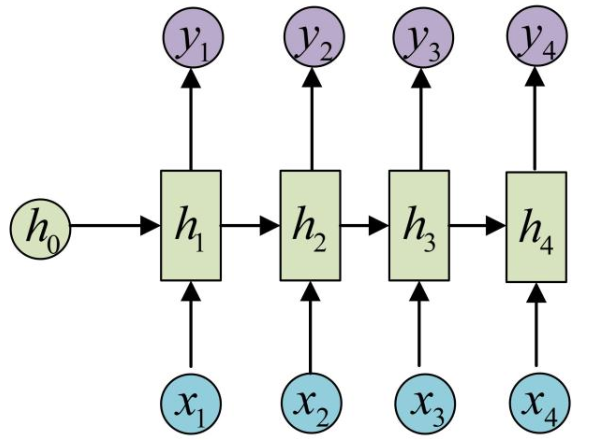
RNN的网络结构
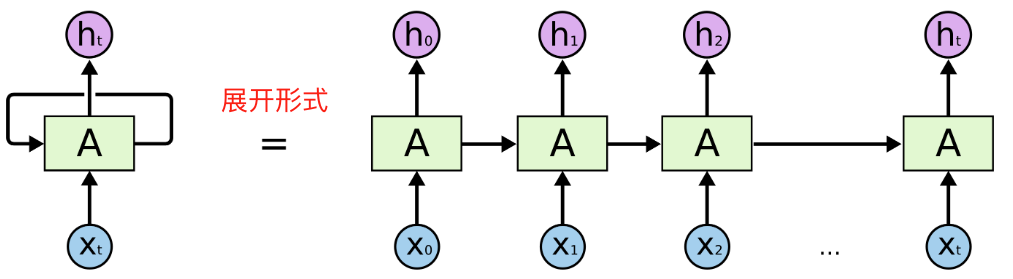
x和隐藏状态h的计算过程
RNN通过在网络中引入循环连接,将前一个时间步的输出作为当前时间步的输入之一,使得网络能够记住以前的状态。具体来说,RNN的每个时间步都会接收当前输入和前一个时间步的隐藏状态,并输出新的隐藏状态。其核心公式为:
- 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/在线问答5/article/detail/928047
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

