
- 1OpenAI API 使用指南_openai api使用
- 2词向量中的负采样是什么_词向量负采样
- 3数据类的开题题目,超靠谱不怕找不到数据【推给2025届毕业生】
- 4JavaScript脚本混淆工具javascript-obfuscator使用_jsobfuscator
- 5基于深度学习的环境感知系统
- 6从LLM中完全消除矩阵乘法,效果出奇得好,10亿参数跑在FPGA上接近大脑功耗_llm imatrix
- 7python 提取word文件中信息_Python读取Word(.docx)正文信息的方法
- 8Python的time模块——各种与时间相关的函数_python 时间函数
- 9解决CenOS7自带的yum不能直接使用问题_one of the configured repositories failed (unknown
- 10学习笔记——spring boot(10)数据库关联_springboot主数据源和从数据源的表怎么关联
字节跳动开源多云多集群管理引擎 KubeAdmiral v1.0.0 发布!
赞
踩

KubeAdmiral v1.0.0 的发布源于社区和开发人员在过去一年中取得的成就,感谢所有参与此版本的贡献者。
来源 | KubeWharf 社区
项目 | https://github.com/kubewharf/kubeadmiral
KubeAdmiral 是字节跳动于 2023 年 7 月正式开源的多云多集群管理引擎,它孵化于字节跳动内部,从上线至今一直强力支撑抖音、今日头条等大规模业务的平稳运行,目前管理着超过 21 万台机器、超过 1000 万 Pod。
自正式开源以来,KubeAdmiral 自身也经历了不断发展和完善,在系统功能、扩展性、稳定性和运行效率均有大幅提升,也吸引了业界最终用户的使用和贡献。因此,我们相信 KubeAdmiral 已经准备好在生产环境落地,并很高兴地宣布 1.0.0 版本正式发布。
背景
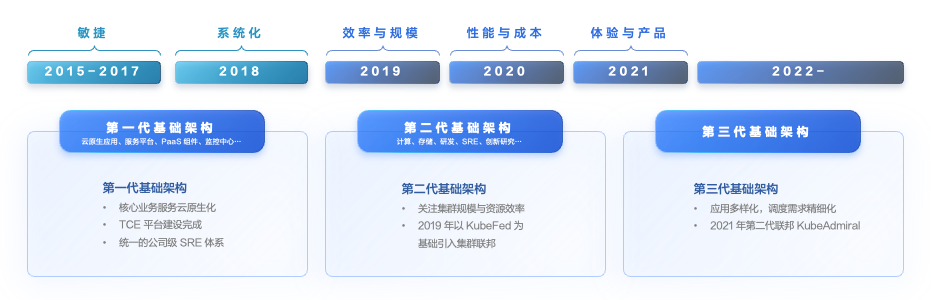
多集群业务背景、KubeAdmiral 在字节的演进
在字节跳动内部,业务的高速发展促使集团在全球多个地区建设了大规模的机房,受限于单集群规模,研发团队在每个机房都部署了多个集群。同时,字节跳动也采购了多家云厂商的公有云资源,多云架构进一步导致了多集群的现状。
这种私有云+多朵公有云的资源配置情况,使得集群横跨物理机、裸金属、虚拟机等基础设施,不同云厂商的标准各异,给运维增加了极大的复杂性。
同样的,出于隔离和安全的考虑,字节跳动内部各业务线独占集群,业务和集群深度绑定,并因此造成了集群资源孤岛。SRE 在运营资源上需要深度感知业务和集群,并在集群之间为应用人肉分配资源,最终导致资源在各个业务线之间的周转慢、自动化效率低以及部署率不够理想。
面对上述因多集群管理带来的挑战,字节跳动基础架构团队在 2019 年以社区 KubeFed V2 为基础开启集群联邦的建设。但在具体落地时,发现 KubeFed 存在以下问题,并不能满足生产环境的要求:
-
资源利用率低:KubeFed 的副本调度策略 RSP 只能为每个成员集群设置静态权重,无法灵活应对集群资源的变化,导致不同成员集群的部署水位不均;
-
变更不够平滑:扩缩容时经常出现实例分布不均的现象,导致容灾能力下降;
-
调度语意局限:只对无状态类资源有较好的支持,对于有状态服务、作业等多样化的资源支持不足,调度扩展性差;
-
接入成本高:需要通过创建联邦对象进行分发,不兼容原生API,用户和上层平台需要完全改变使用习惯。
随着架构的演进,基础架构团队对于效率、规模、性能与成本提出了更高的要求;同时随着在离线融合,存储和机器学习进一步云原生化,支持相应场景的任务跨集群编排调度能力的需求愈发突出。
在上述背景下,我们在 2021 年底基于 KubeFed v2 研发了新一代集群联邦系统 KubeAdmiral,重点包括兼容原生 API、丰富调度策略和扩展能力、支持混合云边一体的超大规模多云多集群应用编排调度能力。
项目介绍
架构、核心功能
KubeAdmiral 命名引申自 Admiral(读音[ˈædm(ə)rəl]),本意为舰队司令,加上 Kube(rnetes) 前缀,寓意该工具具有强大的 Kubernetes 多集群编排调度能力。
项目架构
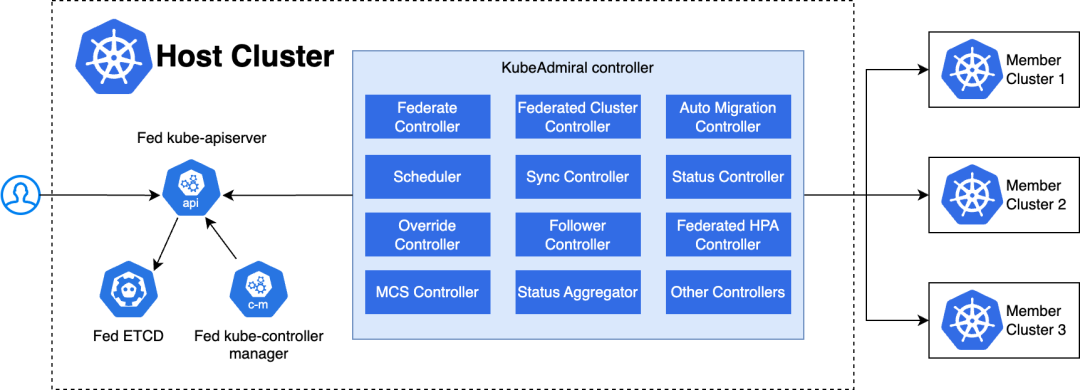
KubeAdmiral 控制面运行在 Host 集群中,包括以下组件:
-
Fed ETCD:存储联邦层 Kubernetes 资源;
-
Fed Kube Apiserver:原生Kubernetes API Server,联邦层 Kubernetes 资源对象的唯一操作入口;
-
Fed Kube Controller Manager:原生 Kubernetes 控制器,但只按需开启部分controller,比如 namespace controller 和 gc controller,用于完成资源的垃圾回收工作;
-
KubeAdmiral Controller:KubeAdmiral 自研组件,为整个系统提供核心控制逻辑,完成诸如成员集群管理,资源调度与分发,故障迁移,状态汇聚等核心功能。
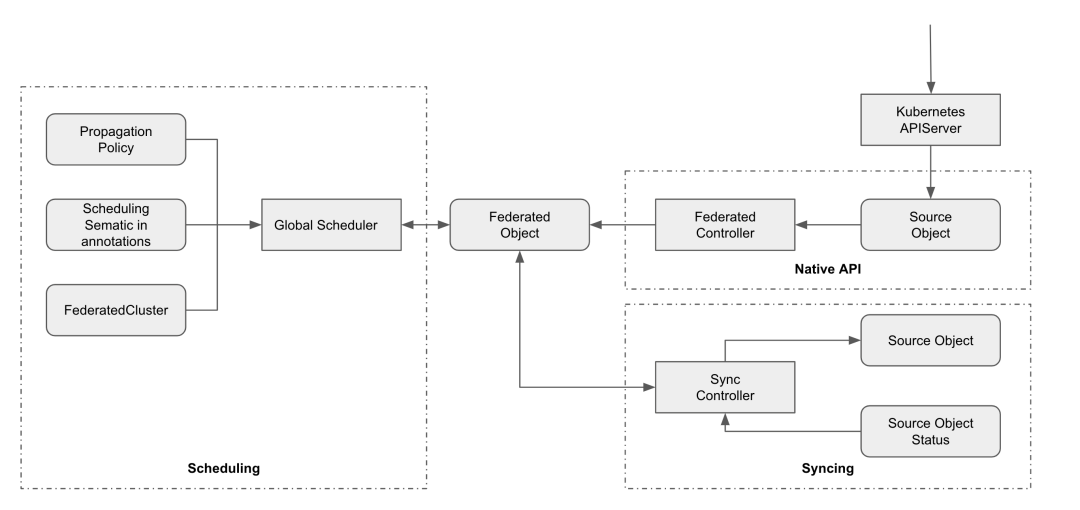
KubeAdmiral Controller 由调度器和各种控制器组成,下面列出了几个核心的组件:
-
Federated Cluster Controller:监听 FederatedCluster 对象,负责管理成员集群的生命周期,包括成员集群的添加,移除,状态采集等;
-
Federate Controller:监听 Kubernetes 资源,并为每个单独的资源对象创建 FederatedObject 对象;
-
Scheduler:负责把资源调度到成员集群中,在副本调度场景也负责计算每个集群中应得的副本;
-
Sync Controller:监听 FederatedObject 对象,负责将联邦资源分发到各个成员集群中;
-
Status Controller:负责采集联邦下发到各个成员集群里的资源的状态。
核心功能
KubeAdmiral v1.0.0 版本支持如下核心功能:
多集群统一管理
-
支持纳管公有云服务商 Kubernetes 集群,如火山引擎、阿里云、华为云等;
-
支持纳管私有云厂商 Kubernetes 集群;
-
支持纳管用户自建 Kubernetes 集群。
多集群应用分发
-
应用类型兼容
-
Kubernetes 原生资源,如 Deployment、StatefulSet、ConfigMap 等;
-
CRD 资源,支持自定义状态字段收集、启用副本模式调度等;
-
Helm Chart。
-
-
跨集群调度模式
-
多集群复制分发;
-
静态权重副本模式分发;
-
动态权重副本模式分发。
-
-
集群选择方式
-
指定成员集群;
-
所有成员集群;
-
集群标签选择。
-
-
关联资源跟随分发
-
内置跟随资源,如工作负载引用 ConfigMap、Secret 等;
-
指定跟随资源,工作负载可通过标签指定跟随资源,如 Service、Ingress 等。
-
-
重调度策略配置
-
支持关闭/开启重调度行为;
-
支持配置重调度触发条件,如部署策略语义修改、成员集群添加等。
-
-
存量单集群资源无缝接管
-
差异化策略覆写成员集群资源配置
-
封装覆写语法:包括:Image、Command、Args、Labels、Annotations 等。
-
-
资源状态采集
-
用户可以自定义资源状态采集字段;
-
支持部分资源的成员集群资源的状态聚合到原生资源。
-
故障迁移
-
应用副本无法调度故障自动迁移
-
应用故障副本恢复迁回
-
集群故障应用手动驱逐;
-
应用故障跨集群自动迁移。
-
跨云/集群弹性伸缩
-
支持应用副本在多集群场景下的 HPA 弹性伸缩能力;
-
兼容原生及自定义 HPA 资源。
项目特点
Kubernetes 原生支持
KubeAdmiral 提供符合 Kubernetes 单集群用户使用习惯的设计,用户可以通过 Kubernetes API 管理和操作Kubernetes原生资源。用户创建原生资源(如Deployment)后,由 Federate Controller 将其自动转化为联邦内部对象(FederatedObject)供其他 controller 使用。
同时,KubeAdmiral 也提供无缝接管存量单集群资源的能力,可以帮助用户平滑地将现有的单集群部署转变为多集群架构,以实现更高的可扩展性和弹性。
全局资源状态汇聚
在单 Kubernetes 集群环境中,原生的 controller 负责更新资源的状态(status),这为用户提供了关于部署和健康状态等关键信息。然而,在多集群部署中,这些状态信息分散于不同的集群,导致用户在获取全局视图时面临碎片化和运维效率低下的挑战。
KubeAdmiral 通过以下优化功能解决了这一问题,提供了全面的多集群资源状态管理和监控:
-
集中式状态采集:KubeAdmiral 的 Status Controller 允许用户指定关心的自定义资源字段,并集中收集各成员集群中的资源状态,这些状态信息被汇总至一个统一的 CollectedStatus 对象;
-
全局状态聚合:Status Aggregator 负责将来自不同成员集群的资源状态进行综合和协调,然后将聚合后的状态信息反馈至原生资源,让用户无需感知多集群拓扑,就可以一目了然地观测到资源在整个联邦中的状态;
-
实时状态监控:KubeAdmiral 持续监控所有成员集群的资源状态,提供实时的运行状态、可用性和健康状态更新,使用户能够及时获取资源的最新情况;
-
故障检测与恢复:利用状态监控,KubeAdmiral 能够迅速识别资源故障或异常,自动执行故障转移等恢复措施,以维护集群的稳定性和可用性;
-
统一视图和报告:用户现在可以在单一界面上查看跨集群的资源状态,并利用生成的报告来支持决策制定和深入分析。
丰富的调度能力
KubeAdmiral 提供丰富的开箱即用的调度策略,包括:
灵活的调度策略:KubeAdmiral 支持灵活的调度策略和规则定义。用户可以根据资源需求、地理位置、成本、集群标签、污点、权重等因素,自定义调度策略,以满足特定的业务需求和优化目标。
跨集群资源分配:KubeAdmiral 可以根据用户的配置和策略,在多个成员集群之间动态分配和调度工作负载。它可以根据集群的负载和资源使用情况,智能地进行资源调度,以确保每个集群的资源得到充分利用,并避免过度或不足的资源分配。
依赖资源跟随调度:确保负载依赖的配置资源在同一集群中调度,简化应用程序的部署和管理。
高效的差异化配置:对于调度到不同集群中的资源,支持通过差异化策略进行覆写,为了方便用户使用,KubeAdmiral 也封装了常见的 Overrider,包括:Image、Command、Args、Labels、Annotations 等。
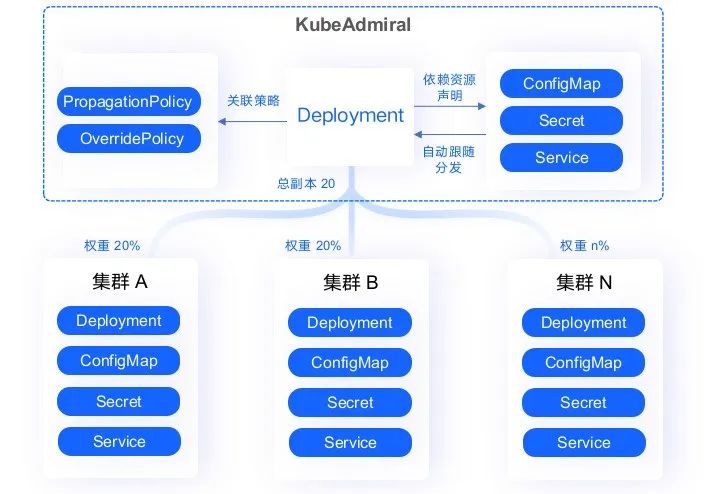
KubeAdmiral 调度的语意可以通过 PropagationPolicy 对象配置:
apiVersion: core.kubeadmiral.io/v1alpha1kind: PropagationPolicymetadata: name: mypolicy namespace: defaultspec: # 提供多种集群选择方式,最终结果取交集 placement: # 手动指定集群与权重 - cluster: Cluster-01 preferences: weight: 40 - cluster: Cluster-02 preferences: weight: 30 - cluster: Cluster-03 preferences: weight: 40 clusterSelector: # 类似Pod.Spec.NodeSelector,通过label过滤集群 IPv6: "true" clusterAffinity: # 类似Pod.Spec.NodeAffinity,通过label过滤集群,语法比clusterSelector更加灵活 - matchExpressions: - key: region operator: In values: - beijing tolerations: # 通过污点过滤集群 - key: "key1" operator: "Equal" value: "value1" effect: "NoSchedule" schedulingMode: Divide # 是否为副本数调度 reschedulePolicy: disableRescheduling: true # 仅在首次调度,适合有状态服务或作业类服务 maxClusters: 1 # 最多可分发到多少个子集群,适合有状态服务或作业类服务 disableFollowerScheduling: false # 是否开启依赖调度
KubeAdmiral 差异化策略可以通过 OverridePolicy 对象配置:
apiVersion: core.kubeadmiral.io/v1alpha1kind: OverridePolicymetadata: name: example namespace: defaultspec: # 最终匹配的集群是所有rule匹配集群的交集 overrideRules: - targetClusters: # 通过名称匹配集群 clusters: - member1 - member2 # 通过标签selector匹配集群 clusterSelector: region: beijing az: zone1 # 通过基于标签的affinity匹配集群 clusterAffinity: - matchExpressions: - key: region operator: In values: - beijing - key: provider operator: In values: - volcengine # 在匹配的集群中,使用jsonpatch语法修改第一个容器的镜像 overriders: jsonpatch: - path: "/spec/template/spec/containers/0/image" operator: replace value: "nginx:test" image: - imagePath: "/spec/templates/0/container/image" operations: - imageComponent: Registry operator: addIfAbsent value: cluster.io - targetClusters: clusters: - member1 overriders: command: - containerName: "server-1" operator: append value: - "/bin/sh" - "-c" - "sleep 10s" - containerName: "server-2" operator: overwrite value: - "/bin/sh" - "-c" - "sleep 10s" - containerName: "server-3" operator: delete value: - "sleep 10s" - targetClusters: clusters: - member2 overriders: args: - containerName: "server-1" operator: append value: - "-v=4" - "--enable-profiling" - targetClusters: clusters: - kubeadmiral-member-1 overriders: labels: - operator: addIfAbsent value: app: "chat" - operator: overwrite value: version: "v1.1.0" - operator: delete value: action: ""
应用故障迁移
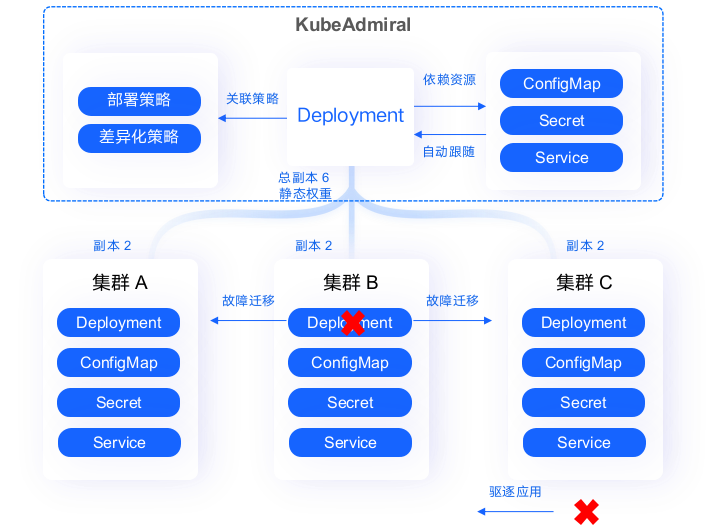
KubeAdmiral 可以帮助用户实现多集群应用的故障迁移,确保应用程序的连续性和可用性。对于副本调度的资源,KubeAdmiral 通过联邦调度计算出每个成员集群的应得副本数,并将副本数字段覆盖后下发到各成员集群;资源下发后,通过各成员集群的 kube-scheduler 把资源对应的pod分配给相应的node。
资源下发后,有时会出现因为节点下线、资源不足、节点亲和性无法满足等等情况造成单集群调度失败的情况,如果不做处理,业务可用实例会低于预期。KubeAdmiral 提供调度失败自动迁移的功能,开启后可以识别成员集群中不可调度的副本并迁移到可容纳多余副本的集群,实现多集群资源周转。
如 A、B、C 三集群相等权重分发 6 个副本,初次联邦调度后每个集群分到 2 个副本。如果 C 集群中的 2 个副本在单集群调度失败,则 KubeAdmiral 会自动将其迁移到 A 和 B 中。
当集群发生故障(不健康或失联),或是不希望在某个集群上继续运行工作负载(如集群下线、升级)时,KubeAdmiral 支持自动/手动进行集群应用驱逐,被驱逐的工作负载将被调度至其他健康的集群中。
调度能力可扩展
KubeAdmiral 具备可扩展的调度能力,可以有效地管理和调度大规模的多集群环境。KubeAdmiral 通过以下方式对调度能力进行扩展。
调度器插件架构:
KubeAdmiral 参考 kube-scheduler 的设计,提供了可拓展的调度框架,将调度逻辑抽象成 Filter、Score、Select 和 Replica 四个步骤,并由多个相对独立的插件各自实现其在每个步骤的逻辑。应用分发策略 PropagaionPolicy 中支持的策略都由独立的内置调度插件负责实现,各插件之间互不干扰,由调度器调用需要的插件进行全局的编排。
调度插件生态系统:
KubeAdmiral 的插件生态系统提供了丰富的内置插件,同时也支持通过 HTTP 协议与外部插件交互。用户可以自行编写并部署定制化的调度逻辑,满足接入公司内部系统进行调度等需求。内置的插件实现较为通用的能力,与外部插件相辅相成,用户可以以最小成本、不需要改动联邦控制面的方式实现调度逻辑的拓展,并依赖 KubeAdmiral 强大的多集群分发能力将调度结果生效。
总结
在生态合作方面,KubeAdmiral 和火山引擎云原生团队达成合作,其分布式云原生使用 KubeAdmiral 为核心引擎,提供多云集群运维、多云容灾、跨云迁移和混合部署等能力,在金融、互联网等行业实现多场景应用。火山引擎云原生团队在实践中积累的一些能力,也已经通过开源贡献的形式反哺回社区。
KubeAdmiral v1.0.0 反映了社区和开发人员在过去一年中取得的成就,感谢所有参与此版本的贡献者。我们非常期待更多开发者和用户能加入到 KubeAdmiral 开源社区中,和我们一起交流和探讨多云多集群联邦的相关话题。如需开源交流,添加字节跳动云原生小助手,加入云原生社群:

- END -

