
- 1Spark 获取RDD案例详解_获取rdd的方式
- 2用python编写用户登录界面,python编写登录窗口_python界面设计账号密码登录
- 3动手学深度学习(Pytorch版)代码实践 -深度学习基础-04图片分类数据集
- 4Python-pydub Decoding failed. ffmpeg returned error code: 1_python ffmpeg return error code 1
- 5libevent源码分析之概述_chrome libevent
- 62023年全国青少年信息素养大赛 第9届Python编程挑战赛海南赛区(小学组)复赛试题解析_2023年创新大赛python小学组复赛题目
- 7git版本回退。git reset参数详解,特殊提交情形下的git push操作(CR等常见场景),git reflog和git log的详解。_git reflog git reset
- 8一文搞懂微调技术和RAG技术区别
- 9Linux命令详解(2)ip命令_linux ip命令
- 10RiskSense Spotlight:全球知名开源软件漏洞分析报告
DB-GPT
赞
踩
DB-GPT 简化了这些基于大型语言模型 (LLM) 和数据库的应用程序的创建。专为数据库打造,用私有化LLM技术定义数据库下一代交互方式
2023 年 6 月,蚂蚁集团发起了数据库领域的大模型框架 DB-GPT。DB-GPT 通过融合先进的大模型和数据库技术,能够系统化打造企业级智能知识库、自动生成商业智能(BI)报告分析系统(GBI),以及处理日常数据和报表生成等多元化应用场景。DB-GPT 开源项目发起人陈发强表示,“凭借大模型和数据库的有机结合,企业及开发者可以用更精简的代码来打造定制化的应用。我们期望 DB-GPT 能够构建大模型领域的基础设施,让围绕数据库构建大模型应用更简单,更方便”。据悉,DB-GPT 社区自成立以来,已汇聚了京东、美团、阿里巴巴、唯品会、蚂蚁集团等众多互联网企业的开发者共同参与,短短半年时间便迅速成长为一个近万星的开源社区,受到了行业和开发者的认可。期间也多次登上 GitHub Trending、Hacker News 首页。
如下是 DB-GPT 中的一些演示效果图:
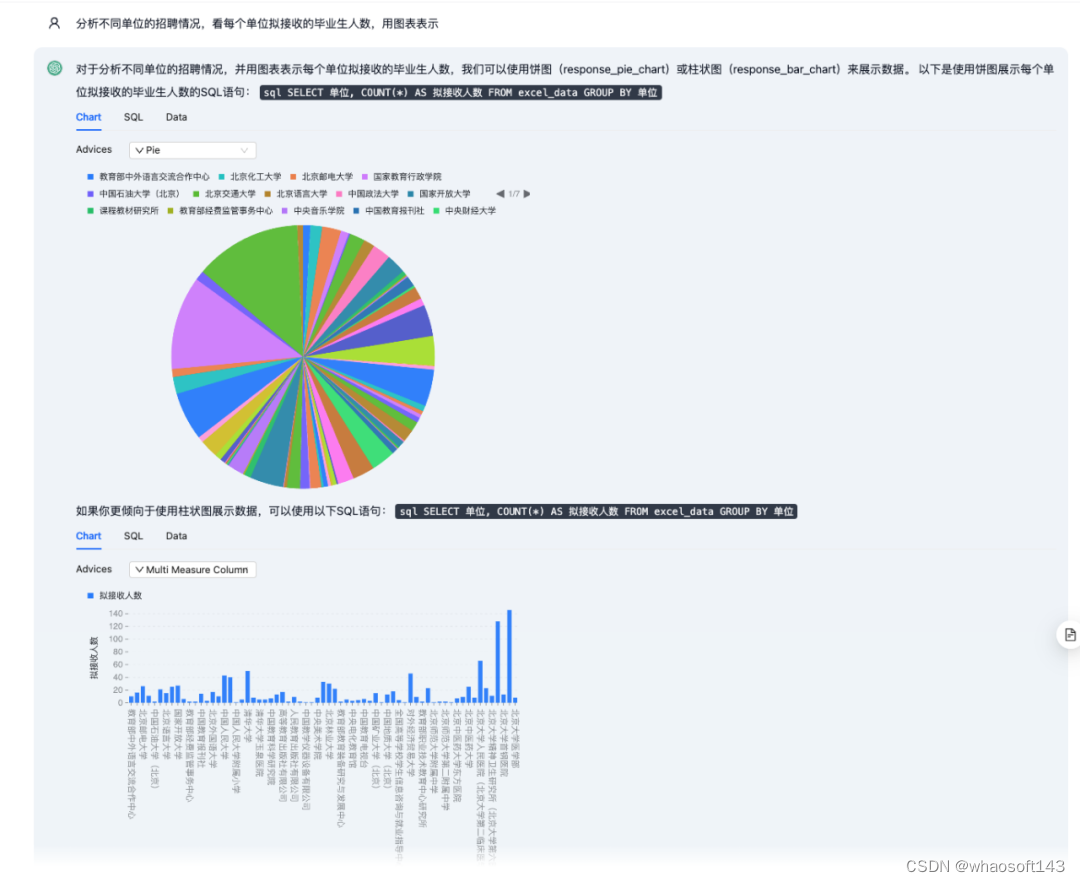
图 1: 通过自然语言与数据库对话生成图表
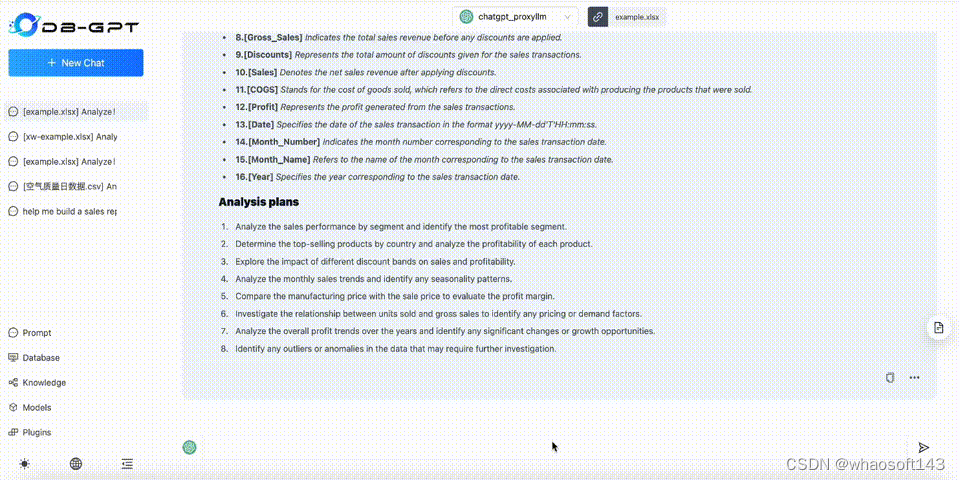
图 2:Excel 对话动态生成分析报表
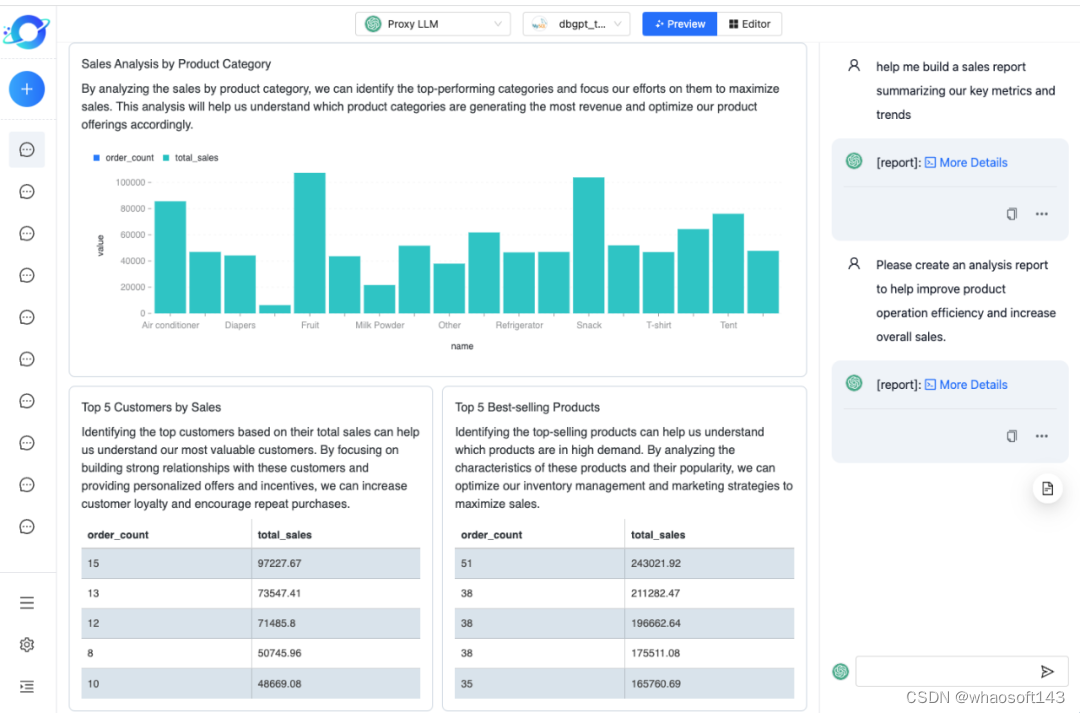
图 3: 自然语言对话生成分析面板
在过去的六个月里,DB-GPT 项目的代码已经从最初提交第一行代码到当前版本 0.4.4,随着项目功能的精细打磨和版本的持续迭代,项目团队也随之发布了一篇关于 DB-GPT 的研究论文,该论文详细介绍了项目的核心技术,包括 RAG、多模型管理框架 SMMF、Text2SQL 的自动化微调以及基于数据驱动的 Multi-Agents 等关键特性的实现架构和实验对比。接下来,让我们了解下 DB-GPT 论文的相关内容:
-
论文地址:https://arxiv.org/pdf/2312.17449.pdf
-
论文代码:https://github.com/eosphoros-ai/DB-GPT
-
论文官网:https://dbgpt.site/
-
英文文档:https://docs.dbgpt.site/docs/overview
-
中文文档:https://www.yuque.com/eosphoros/dbgpt-docs/bex30nsv60ru0fmx
简介
ChatGPT 和 GPT-4 等大型语言模型(LLMs)展示了它们在模拟人类对话和理解复杂查询方面的卓越天赋,同时引领了一个跨领域融合 LLMs 的新趋势。当这些模型和外部工具相结合,它们的能力得到进一步增强,使它们能够搜索互联网上的相关信息,同时可以利用外部工具创建更复杂、功能更丰富的应用程序。
在数据库领域,传统系统往往依赖技术专家的深厚知识和对领域特定的结构化查询语言 (SQL) 的熟练掌握来进行数据访问和操作。而 LLMs 的出现为自然语言接口铺平了道路,使用户能够通过自然语言查询和数据库进行交互,从而实现了数据库交互的简单化和直观化。
即便如此,如何巧妙地运用 LLM 增强数据库的操作性,以便打造功能强大的终端用户应用程序,仍然是一个悬而未决的难题。目前多数研究采用的一种直接方法,即直接使用常用的 LLM(例如 GPT-4)并通过简洁的少量示例提示(few-shot prompting)或交互式上下文学习(ICL)来进行交互。这一方法的优势在于,它不太可能过度拟合训练数据,并且能够灵活适应新数据,然而,其劣势在于与中型 LLM 的微调方案相比,性能可能尚未达到最佳。
此外,为了进一步促进与数据库的智能交互,众多研究和实践中已尝试将 LLM 支持的自动推理和决策过程(又名 agent)融入到数据库应用程序中。然而,知识代理(knowledge agent)往往是为特定场景和任务量身打造的,而非通用型,这一点限制了它们在广泛应用场景下的大规模使用。虽然在以 LLM 为核心的数据库交互中隐私保护措施至关重要,但这方面的深入研究仍显不足。以往的研究大多是普适性目标,而非针对数据库操作而精心设计的。
在此研究中,作者提出了 DB-GPT 框架,这是一个旨在借助 LLM 技术而打造的智能化、生产级的项目,它使用私有化技术提取、构建和访问数据库的数据。DB-GPT 不仅充分发挥了 LLM 的自然语言理解和生成的潜能,而且还通过 agent 代理和插件机制不断优化其数据驱动的引擎。表 1 展示了 DB-GPT 和 LangChain、LlamaIndex、PrivateGPT、ChatDB 等工具在多个维度的综合比较。综上所述,DB-GPT 具有以下明显优点:

隐私和安全保护。DB-GPT 为用户提供了极致的部署灵活性,允许在个人设备或本地服务器上进行安装,并且能够在没有互联网连接的状态下运行。这确保了在任何时刻,数据都没有离开执行环境,彻底杜绝了数据泄露的风险。在数据处理模块,通过模糊数据集中的个人标识符,大幅度降低私人信息被未经授权访问和滥用的风险。
多源知识库问答优化。与传统的知识库问答系统(KBQA)相比,DB-GPT 设计构建了一条灵活、高效、支持双语的数据处理 pipeline,它能够将多源非结构化数据(例如:PDF、网页、图像等)摄取到中间数据中表示,随后将这些数据存储在结构化知识库中,在此基础上,系统能够高效检索和查询最相关的信息片段,并借助于其强大的自然语言生成能力,为用户提供详尽的自然语言回答。
Text-to-SQL 微调。为了进一步增强生成能力,DB-GPT 对 Text-to-SQL 任务的几个常用 LLM(例如 Llama-2、GLM)进行了微调,从而显著降低了非 SQL 专业知识的用户与数据交互的门槛。据作者了解,在同类研究中,有 LlamaIndex、SQLCoder 等集成了此类微调的替代方案,但它并未针对双语查询进行优化。
集成知识代理(knowledge agent)和插件。Agent 是一款自动推理和决策的引擎。DB-GPT 作为一个完全可用于生产环境的成熟项目,它赋能用户通过高级数据分析技术开发并部署应用会话代理,进而促进数据的交互式应用。此外,它还提供一系列查询和检索服务插件,用作与数据交互的工具。
论文对 DB-GPT 的性能进行了周密的评估,这不仅涵盖了各种基准任务(例如 Text-to-SQL 和 KBQA),还包括了案例研究和调查来评估其可用性和场景偏好。在多数评价指标上,DB-GPT 展现出了优于竞争对手的性能表现。
系统设计
DB-GPT 的整体流程如图 1 所示。在建立检索增强生成 (RAG) 框架时,DB-GPT 系统集成了新颖的训练和推理技术,显著增强了其整体性能和效率。本节将描述每个阶段的设计,包括模型架构以及训练和推理范式。
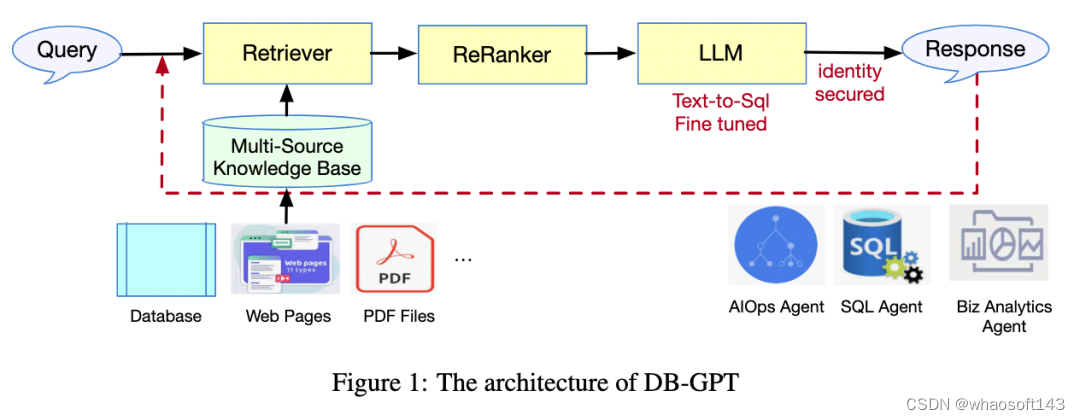
多源 RAG 知识问答
尽管 LLM 通常在大量的开源数据或其他地方的独有数据上训练,但是仍然可以使用 RAG 技术通过额外的私人数据增强 LLM 知识问答能力。如图 2 所示,DB-GPT 的 RAG 系统架构由三个阶段组成:知识构建、知识检索和自适应上下文学习 (ICL)。
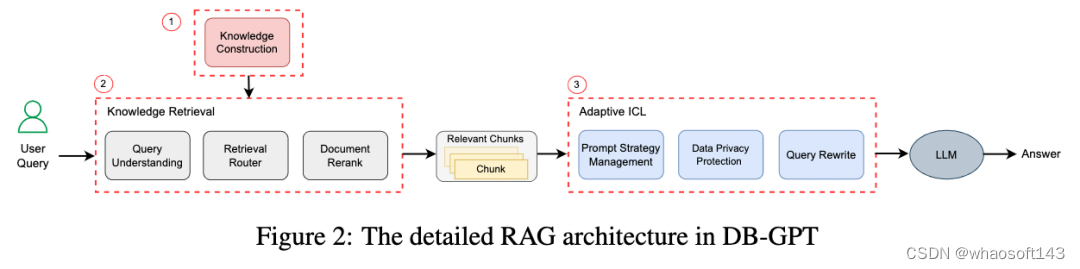
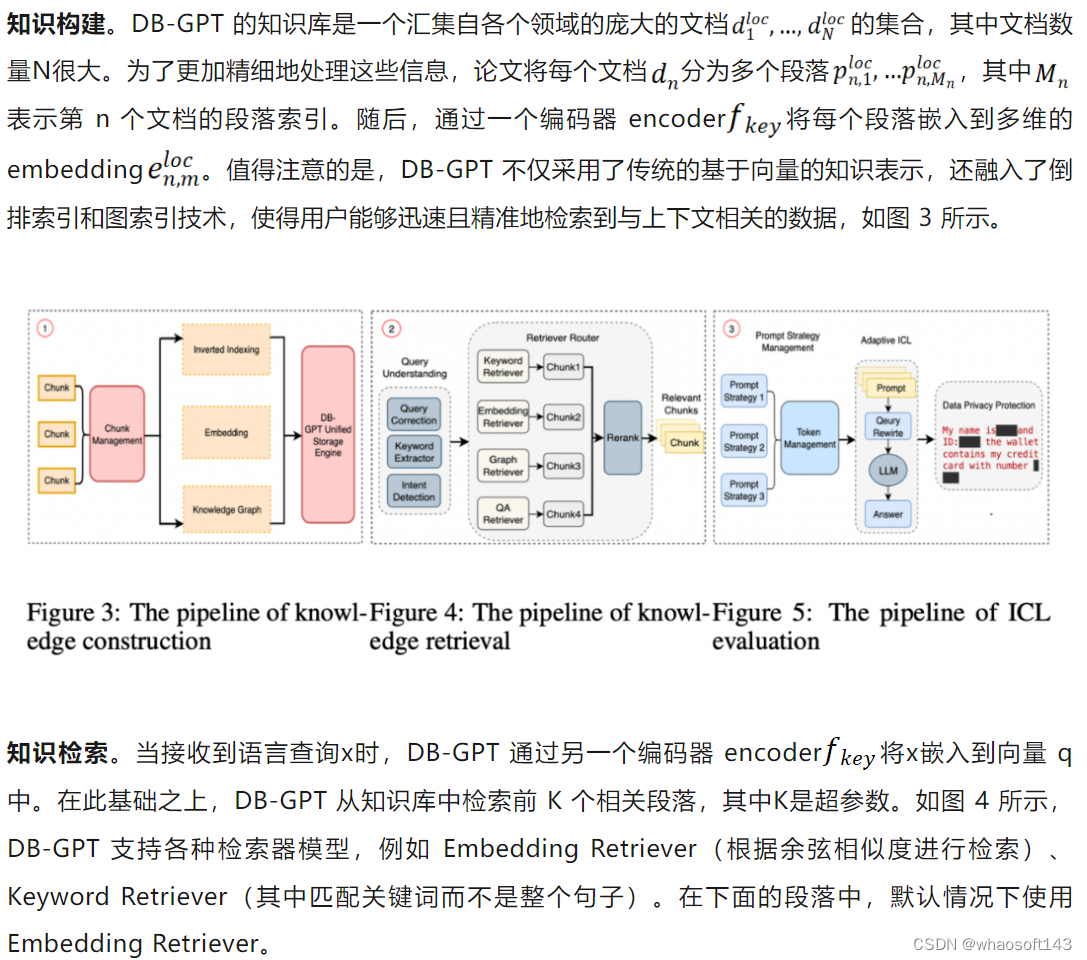

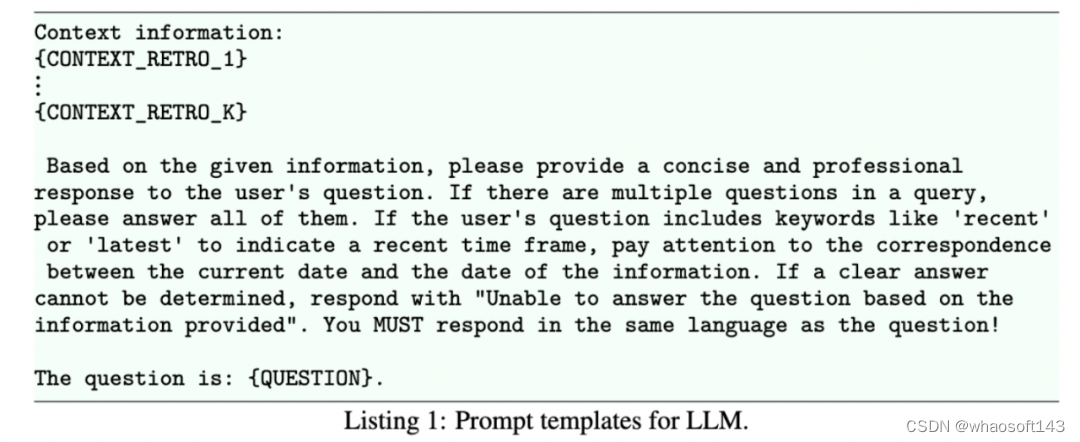
LLM 的自适应 ICL 和生成。在这一阶段,DB-GPT 系统通过执行 ICL 来响应生成。系统首先根据和查询 query 的余弦相似度对 K 个搜索结果进行排序,然后选取排名最前的 J 个(其中 J ≤ K)结果,将这些结果插入到预定义的上下文提示模板中,最后 LLM 生成响应。ICL 是一种在训练或推理阶段通过在处理过程中纳入额外的上下文来提高 LLM 性能的技术。ICL 的引入不仅增强了语言模型对上下文的理解,还提高了模型的可解释和推理技能。值得注意的是,ICL 的性能很大程度上取决于特定的设置,包括提示模板、选择的示例、上下文示例的数量以及示例的顺序。在 DB-GPT 系统中,提供了多种制定提示模板的策略(示例见清单 1)以适应不同的需求。此外,论文采用了相应的隐私保护措施,确保个人信息得到妥善保存。
部署和推理:面向服务的多模型管理框架 SMMF
模型即服务 (MaaS) 是一种云端的人工智能的服务模式,它向开发人员和企业提供即时可用的预配置、预训练的机器学习模型。在 DB-GPT 框架中,为了精简模型的适配流程,提升运作效率,并优化模型部署的性能表现,提出面向服务的多模型框架(SMMF)。该框架旨在为多模型部署和推理提供一个快速和便捷的平台。
SMMF 主要由模型推理层和模型部署层两个部分组成。模型推理层是一个专门为了适配多样化的 LLM 而设计的推理平台,包括 vLLM、文本生成推理 (TGI,HuggingFace 模型推理) 和 TensorRT。而模型部署层则承担着桥梁的角色,充当了底层推理层和上层模型服务功能之间的媒介。
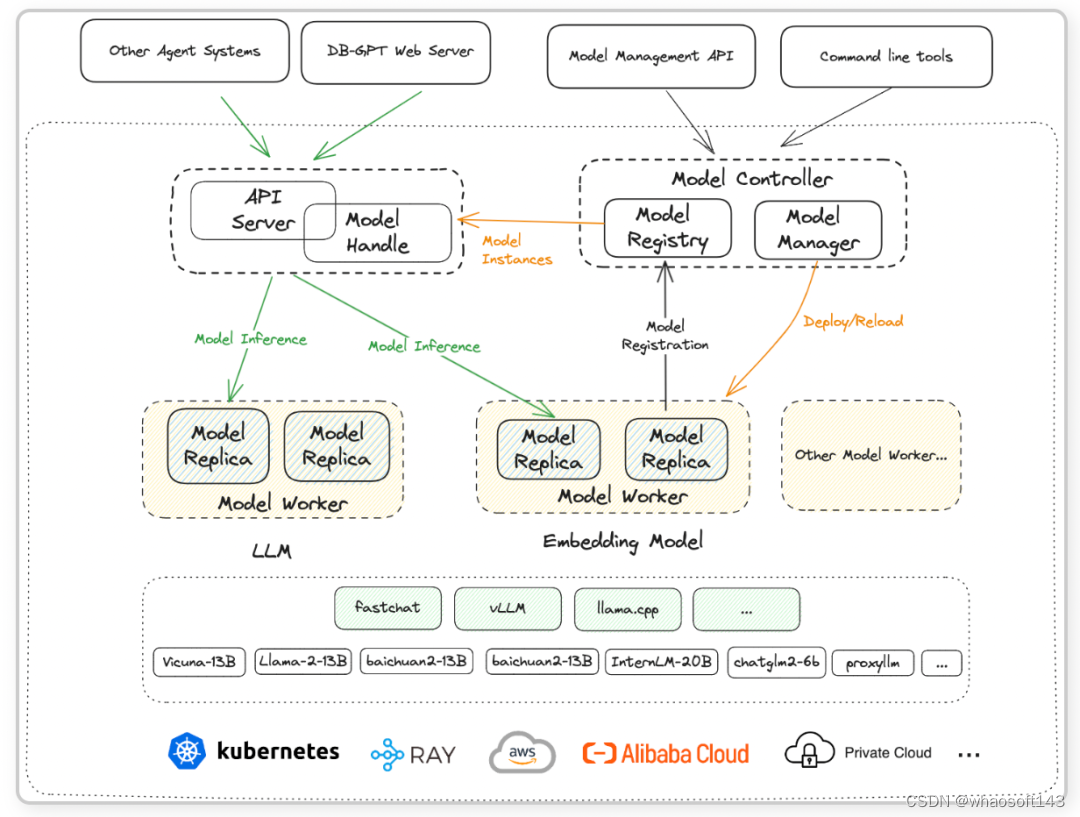
模型部署层:在 DB-GPT 的模型部署框架层内,一系列组件协同工作。由 API server 和 model handler 组成的任务负责向应用程序层提供强大的模型服务功能。model controller 占据中心位置,不仅负责元数据的治理,同时也充当大规模部署架构的纽带。此外,model worker 的作用至关重要,它直接与推理设备和底层基础环境直接连接,确保模型能够发挥最佳的性能。
Multi-agent 策略
DB-GPT 是一个多角色支持的系统,为数据分析师、软件工程师和数据库架构师等用户提供与数据库交互的全流程体验,同时配备了精心编排设计的标准操作程序(SOPs)。受到 MetaGPT 理念的启发,DB-GPT 为不同 agent 分配不同的角色,发挥其独特的优势和专长来解决具有挑战性的任务。通过精准的协调机制,DB-GPT 实现了不同 LLM agents 间的高效协作,促进它们之间沟通、共享信息和集体推理。基于 Text-to-SQL 微调后的 LLM,DB-GPT 可以快速开发和部署具有与数据库高级交互能力的智能 agent。此外,与适用于特定用例且行为受限的 LlamaIndex 组件不同,DB-GPT 使 agent 在更少的约束下具有更强的通用推理能力。
数据库插件
虽然 LLM 具有强大的能力,但它并非在每项任务上都能发挥最佳性能表现。LLM 可以通过合并插件来执行多个步骤,收集相关信息,而非直接回答问题。区别于通用的插件,DB-GPT 的插件专门为数据库交互模式而设计。这种设计有利于通过自然语言查询数据库,简化用户查询表达式,同时增强了 LLM 的查询理解和执行能力。数据库交互模式由模式分析器 (schema analyzer) 和查询执行器 (query executor) 两个组件组成。模式分析器 (schema analyzer),负责将模式解析为 LLM 可以理解的结构化表达;查询执行器 (query executor),则负责根据 LLM 的自然语言响应在数据库上执行相应的 SQL 查询。另外,DB-GPT 还与第三方服务集成,例如 WebGPT 中提出的 web search,用户无需离开聊天即可在另一个平台上执行任务。借助这些插件,DB-GPT 能够以强大的生成能力(论文将其称为生成数据分析)来执行多个端到端数据分析问题。具体详情可以参阅论文的说明性示例。
模型训练
RAG 的实现代码参考了开源项目 LangChain 的代码。Web 端的 UI 实现细节,可以参考作者的另一个开源项目:https://github.com/eosphoros-ai/DB-GPT-Web。其余的训练细节请参考原论文,或者访问 DB-GPT 开源项目地址:https://github.com/eosphoros-ai/DB-GPT,来获取更加全面准确的信息。
实验
论文中提出了旨在评估 DB-GPT 系统性能的实验,包括 Text-to-SQL 响应的生成质量和 MS-RAG 的 QA 性能,并提供生成数据分析的定性结果。
Text-to-SQL 验证
在公有数据集 Spider 上,本项目采用了 Text-to-SQL 的技术进行评估,其中训练使用 train 集,评估使用 dev 集。评估指标使用的是执行准确率(Execution Accuracy, 简称 EX)。该指标通过对比预测的 SQL 查询结果与特定数据库实例中的真实 SQL 查询结果来衡量。EX 越高,代表模型性能越好。考虑到双语文本支持需求,在 DB-GPT 框架实验中选取了 Qwen 系列和 Baichuan 系列作为基础的 LLM,实验结果如表 2 所示。
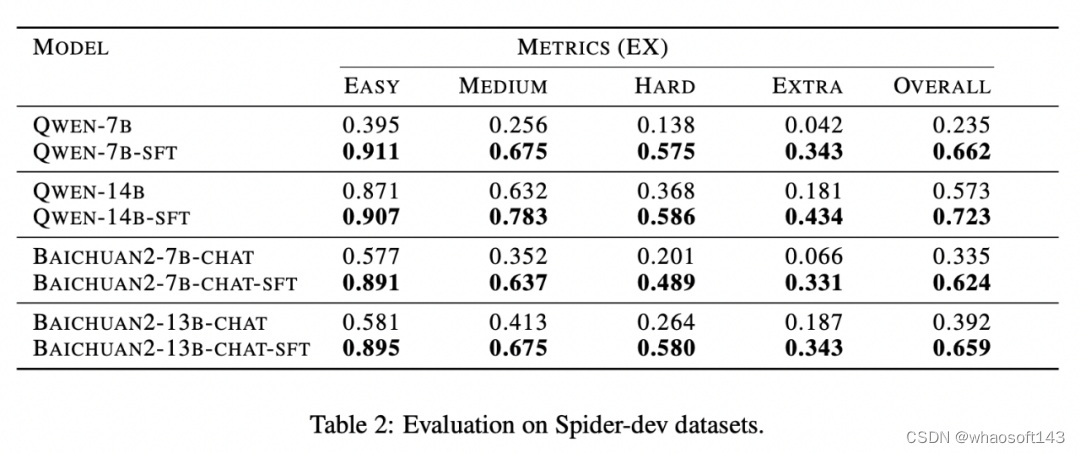
表 2 显示了 DB-GPT 系统在 Text-to-SQL 微调 pipeline 的有效性,无论是通义千问模型还是百川模型,微调后模型 EX 指标都有显著提升。
RAG 验证
论文在多种开放域问答(open-domain QA)任务中对 RAG 框架进行了实验。作者专门构建了两个 QA 数据集,分别聚焦于数据库领域和金融领域:DatabaseQA 和 FinancialQA。在构建 DatabaseQA 时,作者从三个代表性数据库系统(OceanBase、MySQL 和 MongoDB)中收集了 1000 个 PDF 形式的公开教程作为素材。而 FinancialQA 的素材则是从研究机构出版的文档样本中抽取了 1000 个。对于每个数据集,论文构建 100 个测试问题,这些问题均由专家根据难易程度进行注释。有关数据集的更多详细信息,请参阅论文附录。
为了确保答案质量评估准确性,论文指定三位专家对每个回复进行打分,评分范围为 0 – 5 分,其中较高分数代表更为优质的答案。评分结果取三位专家评分的平均值,以此作为最终得分。论文选取 4 个 LLM 作为基础模型,分别是:Qwen、Baichuan、ChatGLM 和 ChatGPT3.5。由于 ChatGPT3.5 并非开源模型,作者无法在框架中对其进行 Text-to-SQL 的微调。RAG 在两个数据集上的实验结果如表 3 和表 4 所示,在所有测试的数据集上,并没有一个模型能够在所有的情况下都胜出:ChatGPT-3.5 在 DatabaseQA 数据集上表现最佳,而 ChatGLM 在 FinancialQA 数据集上获得最佳性能。DB-GPT 集成了大部分流行的开源和商业 LLM,用户可以根据自己的 RAG 任务需求自由选择最适合的模型。
 SMMF 验证
SMMF 验证
DB-GPT 集成了 vLLM 作为主要推理框架,实验过程中,为了保持一致性,论文将每一个输入提示(prompt)的长度固定为 8 个 token,并将输出的最大长度设置为 256 个 token。实验采用了以下三个评价指标:
-
首字延迟 First Token Latency (FTL):以毫秒为单位,代表 DB-GPT 模型部署框架收到请求时该时刻开始,到进行推理解码第一个 token 所花费的时间。
-
推理延迟 Inference Latency(IL):以秒为单位测量,表示从 DB-GPT 模型部署框架接收到模型推理请求到生成完整的响应的时间。
-
吞吐量:DB-GPT 模型部署框架每秒中处理的所有用户和所有请求的 token 数量。
Qwen 和 Baichuan 模型在 SMMF 方法上的实验结果如表 5 和表 6 所示,结果表明使用 vLLM 模型推理框架显著提高了模型的吞吐量,同时大幅度降低了首字延迟和推理延迟。值得注意的是,随着数量并发用户数增加,使用 vLLM 框架推理带来的性能提升变得特别明显。因此,DB-GPT 选择将 vLLM 集成为 SMMF 使用的默认推理框架。
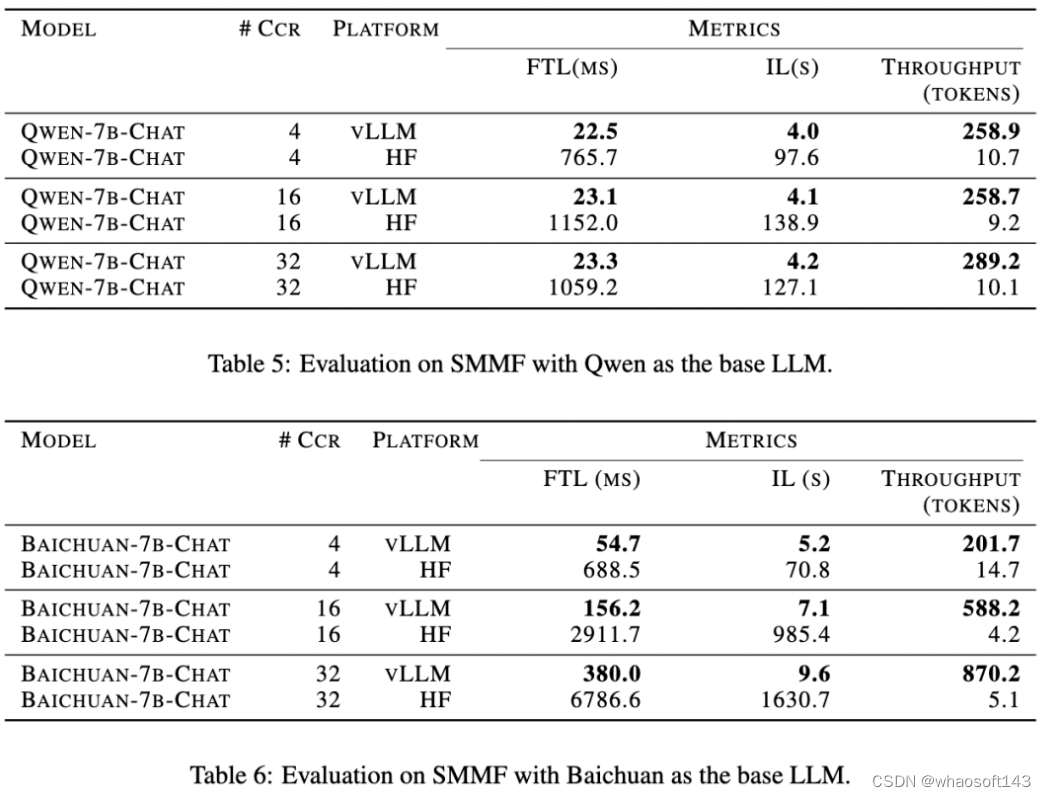
其他实验细节可以参考原论文附录。
面向未来
经过这一年的实践与抽象,为了具备更广泛的生产级应用能力,DB-GPT 对架构进行了分层。如下图所示,主要分为以下 7 层,自上而下以此为:
-
可视化层:可视化层主要的工作是对话、交互、图表显示、可视化编排等能力。
-
应用层:基于底层能力的应用构建,如 GBI 应用、ChatDB 类应用、ChatData 类应用、ChatExcel 类应用等。
-
服务层:服务层主要是对外暴露的服务,比如 LLMServer、APIServer、RAGServer、dbgptserver 等。 whaosoft aiot http://143ai.com
-
核心模块层:核心模块主要有三个分别是,SMMF、RAGs、Agents。
-
协议层:协议层主要是指 AWEL (Agentic Workflow Expression Language), 即智能体编排语言,是专门为大模型应用开发设计的智能体工作流表达式语言。
-
训练层:训练层主要关注 Text2SQL、Text2DSL、Text2API 方向的微调,提供标准的微调脚手架。
-
运行环境:运行环境是指整个框架的运行在什么环境当中,我们后期会优先支持基于 Ray 与 Kubernetes 的环境。
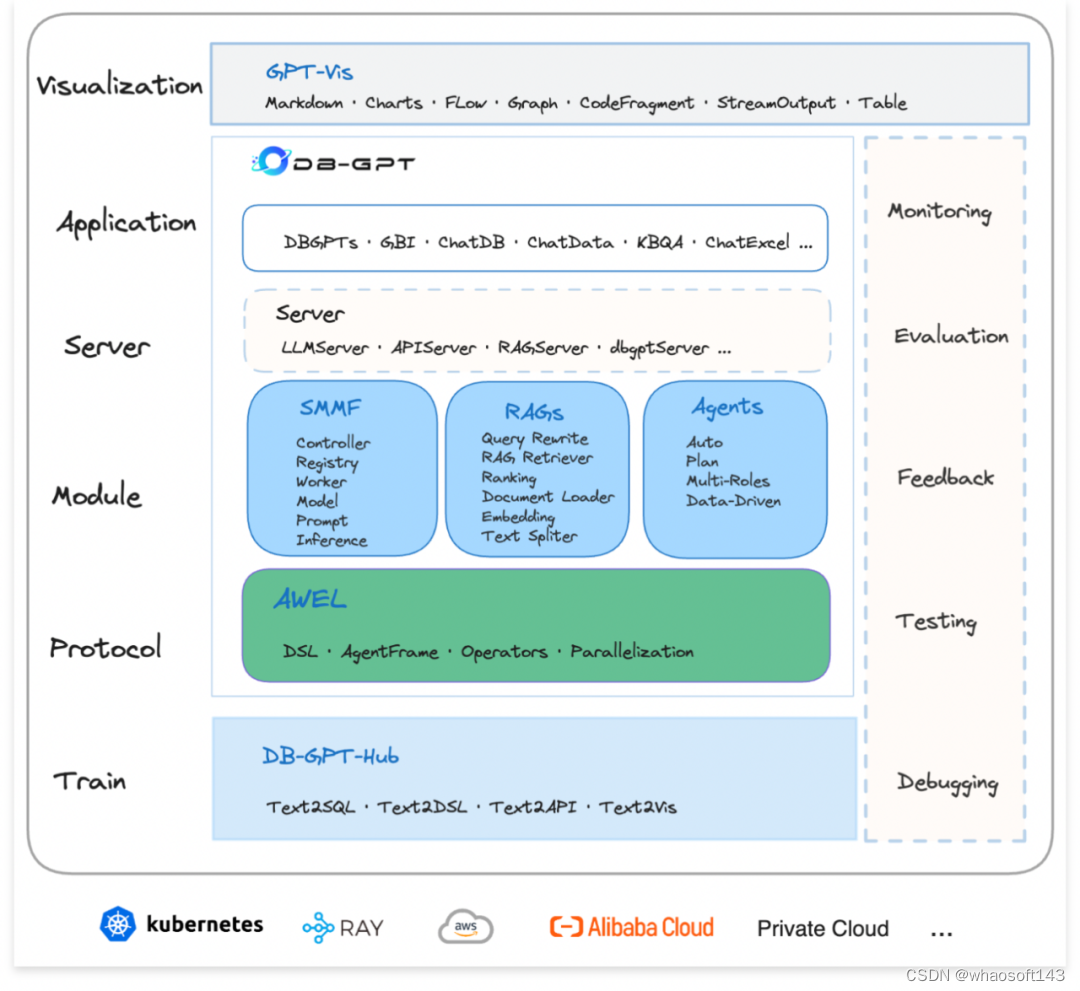
DB-GPT 整体架构设计图
用户可以基于这些基础框架能力,更好的打造生产级应用。更多关于 DB-GPT 的进展可以关注其社区。
附录
-
DB-GPT 论文:DB-GPT: Empowering Database Interactions with Private Large Language Models.
-
DB-GPT 框架开源项目:https://github.com/eosphoros-ai/DB-GPT
-
DB-GPT 前端可视化项目:https://github.com/eosphoros-ai/DB-GPT-Web
-
DB-GPT Text2SQL 微调项目: https://github.com/eosphoros-ai/DB-GPT-Hub
-
DB-GPT 插件仓库: https://github.com/eosphoros-ai/DB-GPT-Plugins
-
Text2SQL 学习资料与前沿跟踪: https://github.com/eosphoros-ai/Awesome-Text2SQL

