
- 1计算机网络经典面试题30问_计算机网络技术面试会问什么
- 2信息系统项目管理笔记_信息系统项目管理中级笔记
- 3【PostgreSQL】在DBeaver中实现序列、函数、视图、触发器设计、数据结构新增(持续更新于20240426)_dbeaver创建触发器
- 4【安全】linux audit审计使用入门_audit权限
- 5【数据库原理及应用】期末复习汇总&高校期末真题试卷10_数据库原理与应用课程设计期末考试题
- 6Android解决报错 superclass access check failed: class_superclass access check failed: 好像在gradle.properti
- 7TCP协议详解(TCP报文、三次握手、四次挥手、TIME_WAIT状态、滑动窗口、拥塞控制、粘包问题、状态转换图)_tcp握手报文
- 8路由器重温——OSPF路由(很重要的协议)-2_type area interarea
- 9Centos8停止更新维护后源失效问题_cendos 维护过期
- 10用python编写用户登录界面,python编写登录窗口_python界面设计账号密码登录
一文搞懂微调技术和RAG技术区别
赞
踩
▼最近直播超级多,预约保你有收获
今晚直播:《大模型ChatGLM3应用案例实战》
—1—
为什么要做微调和RAG的对比?
通用大模型存在一定的幻觉问题,通过把企业私有的领域数据知识喂给通用大模型,从而降低了大模型的幻觉,这就是所谓的企业私有大模型,从技术层面来讲,实现企业私有大模型有2个技术手段:微调(Fine-tuning)、RAG(Retrieval Augmented Generation)检索增强生成。这种技术如何选型?很多同学很困惑,今天我们剖析它们的区别,使得同学们能够真正搞定这两种大模型增强技术的本质。
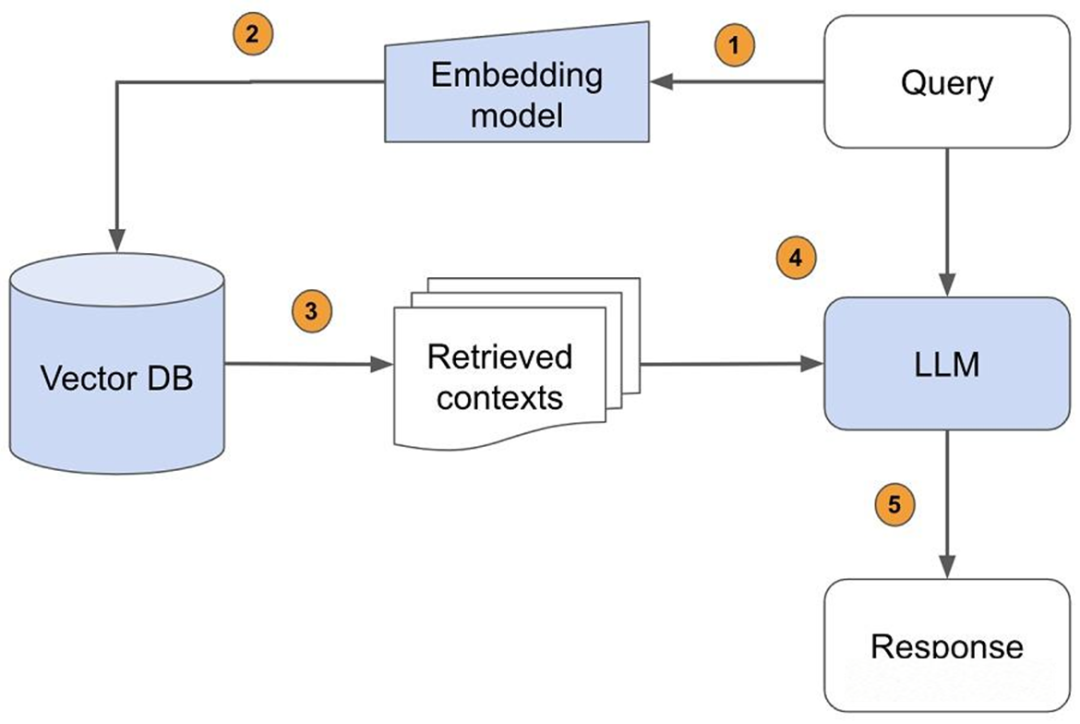

—2—
微调和RAG的区别
第一、知识维度
RAG 对知识的更新时间和经济成本更低。不需要训练,只需要更新数据库即可。
RAG 对知识的掌控力会更强,相比微调更不用担心学不到或者是遗忘的问题。
如果大模型强缺乏某个领域的知识,足量数据的微调才能让模型对该领域有基本的概念,如果不具备领域知识基础,RAG 仍旧无法正确回答。
第二、效果维度
RAG 相比微调能更容易获得更好的效果,突出的是稳定性、可解释性。
对任务模式比较简单的任务,微调能触碰到更高的上限,但是对训练、数据等方面的要求会更苛刻。
幻觉方面,RAG 从各种实测来看,短板基本都在检索模块,只要检索不出大问题,整体效果还是 RAG 比较有优势的。
第三、成本维度
训练方面,RAG 的成本就是更新数据库,但是微调就需要大量的显卡、时间资源。
推理方面,考虑到 RAG 本身需要检索,而且检索层为了确保检索准确,还需要很多额外工作,所以推理的耗时会比微调多,但具体多多少,就要看检索模块的复杂程度了,如果这里面还需要额外调大模型,那成本就会多很多,如果只是小模型之类的,那这个增加可以说是忽略不计。微调后的大模型直接使用,和原本模型的耗时一致。
系统拓展角度。随着项目的发展,大模型训练不一定能支撑多任务,而拿着大模型训好几个,对部署而言并不方便。
通过上述的对比,我们看出,在企业具体的业务场景来看,RAG 技术的综合收益也高于微调技术。但是 RAG 也是不是万能的,RAG 也会存在以下的依赖问题。
RAG 依赖知识库。如果不具备构造知识库的条件,那 RAG 无从谈起,比如:没有具体的业务数据,或者是机器不支持支撑检索之类的。
业务需求并非对知识依赖。比如:某些业务的话术生成,更多是对语言风格的约束,此时要么通过 Prompt 解决,要么就是构造业务数据来进行训练即可,根本没有构造 RAG 的必要。
依赖实时信息而非固有信息。比如:对话摘要是大模型具有的比较强的能力,这种任务更多是依赖收到的对话记录,而非一些固有存储好的内容,此时通过工程手段直接把信息获取导入到模型即可,不需要把对应内容入库了。如果对对话摘要的内容不满意,则应该是通过 Prompt 和微调来解决。当然有人可能会说通过 few-shot 的方式,可以用 RAG,这个当然是可以的,但就不是必须了。
指令不生效或者领域知识完全不具备。大模型此处是短板,那即使是 RAG,把答案摆在面前,也解决不了问题。
内容会受到检索结果局限。有些创造性的任务,本身是想通过大模型获取新的灵感,然而检索结果给到大模型后,大模型往往容易受到限制,这个限制在有些时候是好事,但并非所有时候。
参考链接:https://mp.weixin.qq.com/s/p9QELz-1BZi06HGwcLNnog
—3—
免费领取《AI 大模型技术系列直播》
AI 大模型的知识图谱包括12项核心技能:大模型内核架构、大模型开发 API、开发框架、向量数据库、AI 编程、AI Agent、缓存、算力、RAG、大模型微调、大模型预训练、LLMOps 等。
为了帮助同学们掌握 AI 大模型开发技能,我们准备了一系列免费直播干货,扫码全部领取!

END


