
- 1MFC案例:自制工具条(Toolbar)按钮的小程序_mfc创建toolbar
- 2checkbox的大小设置_react 如何设置checkbox按钮大小
- 3基于LBP纹理特征计算GLCM的纹理特征统计量+SVM/RF识别纹理图片_利用纹理特征进行svm分类
- 4BM25算法以及变种算法简介
- 5<软考高项备考>《论文专题 - 13 绩效域(三)》_测量绩效域论文 高项
- 6linux下git的使用_linux git使用
- 7spark学习及环境配置_如何将一个算法部署在spark环境
- 8MySQL-数据操作类型的角度理解 S锁 & X锁
- 9【二】为Python Tk GUI窗口添加一些组件和绑定一些组件事件_python tk 绑定
- 10物体识别桌颠覆传统,创新科技重塑感知体验!
datax的使用以及参数解释,快速入门版_datax 参数
赞
踩
datax的使用以及参数解释
前言
本文我们介绍一下datax的基础用法,让初学者能够实现快速入门,即刻应用
一、datax是什么?
首先,来了解一下datax是什么,datax简单可以理解为数据同步的一个工具,将一个系统中存储的数据存储到另一个系统中。
举例来说,我们将数据存储到了HDFS中,但是现在我们想要使用这些数据来进行可视化分析,那么我们就要用到datax,将HDFS中的数据同步到MYSQL中,便于可视化的使用。
二、文件配置说明
文件安装我们就不多赘述了,直接开始讲解datax如何使用。
1.查看配置文件
{ "job": { "setting": { "speed": { "channel": 3 } }, "content": [ { "reader": { "name": "hdfsreader", "parameter": { "path": "/user/spark_design/output/user_anaylse/", "defaultFS": "hdfs://master:9000", "column": [ { "index": 0, "type": "string" }, { "index": 1, "type": "long" } ], "fileType": "text", "encoding": "UTF-8", "fieldDelimiter": "," } }, "writer": { "name": "mysqlwriter", "parameter": { "writeMode": "insert", "username": "root", "password": "123456", "column": [ "province", "number" ], "preSql": [ "delete from user_anaylse" ], "connection": [ { "jdbcUrl": "jdbc:mysql://127.0.0.1:3306/spark_design?useUnicode=true&characterEncoding=UTF-8", "table": [ "user_anaylse" ] } ] } } } ] } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
2. 配置参数解释
上面的部分的代码是datax使用必须配置的json文件,没有这个文件datax是不能使用的,这个文件规定了数据的来源和同步位置。
首先channel这个数据,规定的是异步的线程数,快速入门的化可以先不管这个参数。
我们主要看content中的reader和writer部分
3. reader参数解释
首先我们要知道,这个配置文件是一个简单的从HDFS中将数据同步到MySQL的json文件
reader部分:顾名思义,reader就是数据原本的位置。
name–起个名字即可
path–就是文件在HDFS中存储的位置,需要的化直接将这个json文件中的路径改为自己文件在HDFS中的路径即可
defaultFS–就是Hadoop主节点的ip+端口
column–就是数据存储的文件中的列数,列数从0开始,在规定列的位置的同时需要规定好该列的数据类型
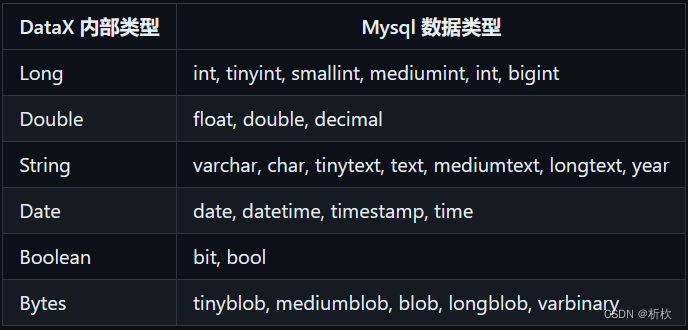
filetype–数据文件的类型,虽然由csv文件这个选项,时间上我们将csv文件进行同步时选择text类型,将fieldDelimiter设置为”,“ 即可即可。
encoding–文件编码格式,就UTF-8即可,无需更改。
fieldDelimiter–数据中的分隔符,类似于hive中的field delimited

4. writer参数解释
name–一样。起个名字即可
writeMode–控制写入数据到目标表采用 insert into 或者 replace into 或者 ON DUPLICATE KEY UPDATE 语句
username–数据库的用户名
password–数据库的密码
column–数据库表中的列名以及数据类型,这个数据类型按照MySQL中的数据类型即可(由于这个的writer的目标是MySQL)
preSql–数据插入之前执行的SQL语句
jdbcUrl–数据库的连接信息
table–要插入的表
总结
本文仅限于datax的快速入门,简单理解为,零时抱佛脚系列文章
具体学习还是看datax官网: 点我跳转

