
热门标签
热门文章
- 1TreeSet详解
- 2(攻防角度)中国人工智能系列白皮书--大模型技术(2023版)之 (2.3.3 语言大模型的提示学习)_中国人工智能大模型技术白皮书(2023版)
- 3黑马程序员前端学习接口变更_黑马接口
- 4io等待为什么引发cpu过高_面试官问我Linux的网络IO模式怎么办?
- 5RT-Thread:在dfs中使用cat、cp等命令时拔掉U盘死机问题_rtthread dfs cat
- 6Hive 窗口函数如何设置窗口大小_hive sum over partition by 窗口大小
- 7opencv实战---对象检测(SSD+DNN)_cv监控dnn
- 8web3开发DApp项目技术入门教程(2022年最新)_web3学习教程
- 9Kafka性能优化_kafka 副本数 对性能
- 10mysql 创建、修改、删除表_mysql create or replace table
当前位置: article > 正文
spark3.0.0单机模式安装_spark单机模式安装
作者:天景科技苑 | 2024-06-28 18:08:42
赞
踩
spark单机模式安装
注:此安装教程基于hadoop3集群版本
下载安装包
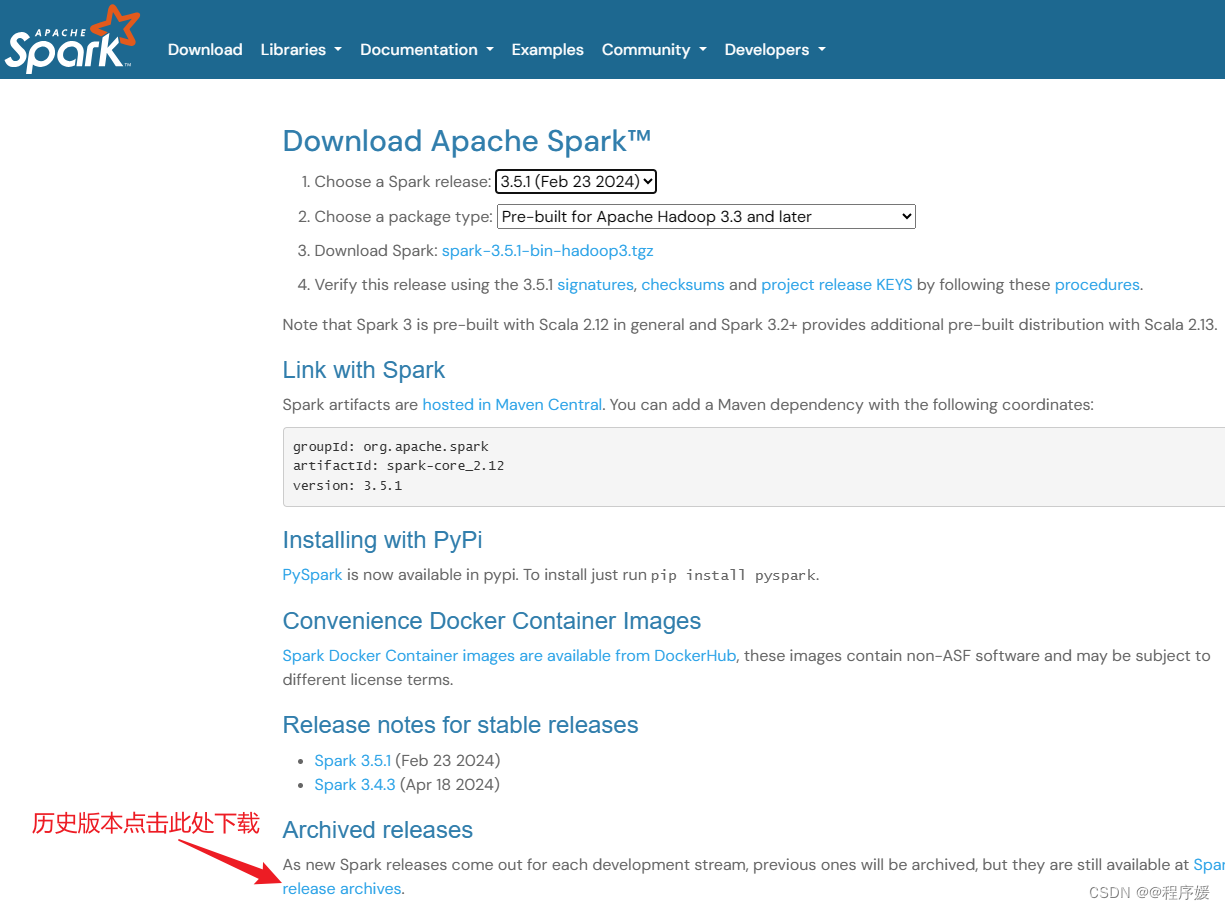
下载spark3.0.0版本,hadoop和spark版本要对应,否则会不兼容
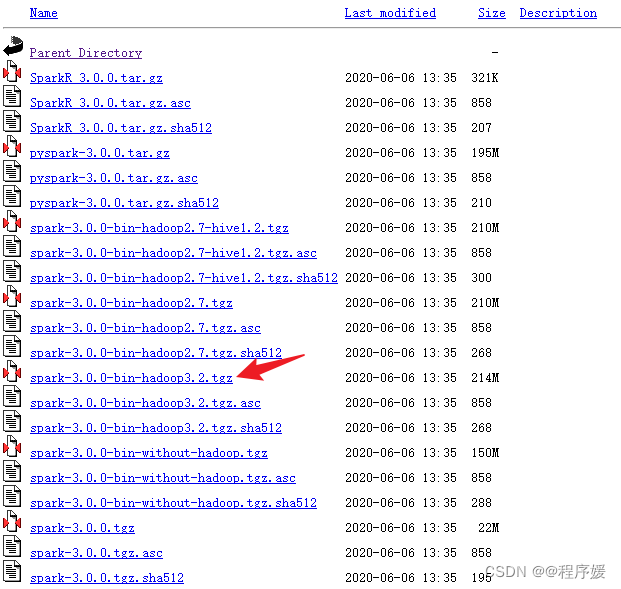
用xftp上传Linux虚拟机,上传目录/bigdata(可修改)

解压
tar -zxvf /bigdata/spark-3.0.0-bin-hadoop3.2.tgz 添加软链接(可选)
ln -s /bigdata/spark-3.0.0-bin-hadoop3.2.tgz /bigdata/spark修改环境变量
- sudo vim /etc/profile
-
- export SPARK_HOME=/bigdata/spark
- export $PATH:$SPARK_HOME/bin
别忘记source /etc/profile
修改spark配置文件
- cd /bigdata/spark
- cp ./conf/spark-env.sh.template ./conf/spark-env.sh
- vim ./conf/spark-env.sh
添加以下内容,/bigdata/hadoop就是hadoop的路径,可根据自己的实际情况修改
export SPARK_DIST_CLASSPATH=$(/bigdata/hadoop/bin/hadoop classpath)验证是否安装成功
run-example SparkPi 2>&1 | grep "Pi is" 这是一个求Π的示例程序,输出如下
![]()
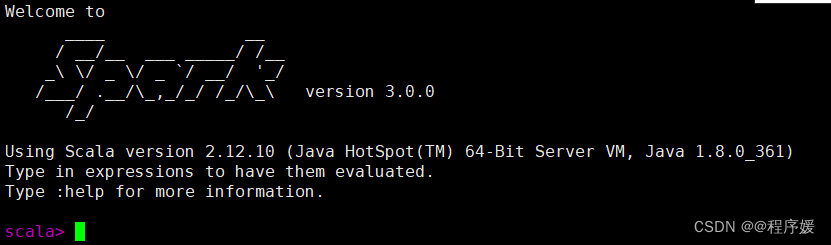
打开spark shell终端
spark-shell如下图
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/天景科技苑/article/detail/766828
推荐阅读
相关标签

