
- 11024程序员节 | 两场干货满满的技术分享最适合在家也爱学习的你
- 2IT行业近十几年的发展史,从web1.0到3.0,大数据、元宇宙、比特币,区块链、AIGC....到底什么是出路_it 技术的过去与未来
- 3vscode输出中文乱码问题_vscode c task.json args 中文
- 4Android的.so文件及常见问题汇总_android 64位的so少几个会怎么样
- 5Java中List和ArrayList的区别(加入了个人见解)_arraylist和list的区别
- 6配电房轨道式巡检机器人方案_导轨和无轨巡检机器人
- 7ShardSphere算法介绍(实现按年月日分片自定义算法)_时间间隔分片 interval sharding algorithm
- 8复杂的对象数组操作Java_义一个数组,用于存储3个学生对象。学生类的属性为:姓名,性别,年龄。(使用java
- 9【会议征稿,JPCS出版】第四届测量控制与仪器仪表国际学术会议(MCAI 2024,7月19-21)
- 10RabbitMQ系列【13】优先级队列_rabbitmq优先级队列
Java开发者LLM实战——使用LangChain4j构建本地RAG系统
赞
踩
1、引言
由于目前比较火的chatGPT是预训练模型,而训练一个大模型是需要较长时间(参数越多学习时间越长,保守估计一般是几个月,不差钱的可以多用点GPU缩短这个时间),这就导致了它所学习的知识不会是最新的,最新的chatGPT-4o只能基于2023年6月之前的数据进行回答,距离目前已经快一年的时间,如果想让GPT基于近一年的时间回复问题,就需要RAG(检索增强生成)技术了。

此外,对于公司内部的私有数据,为了数据安全、商业利益考虑,不能放到互联网上的数据,因此GPT也没有这部分的知识,如果需要GPT基于这部分私有的知识进行回答,也需要使用RAG技术。

本文将通过实战代码示例,意在帮助没有大模型实战经验的Java工程师掌握使用LangChain4j框架进行大模型开发。
2、基本概念
2.1 什么是RAG
RAG(Retrieval-Augmented Generation)的核心思想是:将传统的信息检索(IR)技术与现代的生成式大模型(如chatGPT)结合起来。
具体来说,RAG模型在生成答案之前,会首先从一个大型的文档库或知识库中检索到若干条相关的文档片段。再将这些检索到的片段作为额外的上下文信息,输入到生成模型中,从而生成更为准确和信息丰富的文本。
RAG的工作原理可以分为以下几个步骤:
1.接收请求:首先,系统接收到用户的请求(例如提出一个问题)。
2.信息****检索(R) :系统从一个大型文档库中检索出与查询最相关的文档片段。这一步的目标是找到那些可能包含答案或相关信息的文档。
3.生成****增强(A) :将检索到的文档片段与原始查询一起输入到大模型(如chatGPT)中,注意使用合适的提示词,比如原始的问题是XXX,检索到的信息是YYY,给大模型的输入应该类似于:请基于YYY回答XXXX。
4.输出****生成(G) :大模型基于输入的查询和检索到的文档片段生成最终的文本答案,并返回给用户。
第2步骤中的信息检索,不一定必须使用向量数据库,可以是关系型数据库(如MySQL)或全文搜索引擎(如Elasticsearch, ES),
但大模型应用场景广泛使用向量数据库的原因是:在大模型RAG的应用场景中,主要是要查询相似度高的某几个文档,而不是精确的查找某一条(MySQL、ES擅长)。
相似度高的两个文档,可能不包含相同的关键词。 例如,句子1: “他很高兴。” 句子2: “他感到非常快乐。” 虽然都是描述【他】很开心快乐的心情,但是不包含相同的关键词;
包含相同的关键词的两个文档可能完全没有关联,例如:句子1: “他喜欢苹果。” 句子2: “苹果是一家大公司。” 虽然都包含相同的关键词【苹果】,但两句话的相似度很低。
2.2 LangChain4j简介
LangChain4j是LangChiain的java版本,
LangChain的Lang取自Large Language Model,代表大语言模型,
Chain是链式执行,即把语言模型应用中的各功能模块化,串联起来,形成一个完整的工作流。
它是面向大语言模型的开发框架,意在封装与LLM对接的细节,简化开发流程,提升基于LLM开发的效率。
更多介绍,详见: https://github.com/langchain4j/langchain4j/blob/main/README.md
2.3 大模型开发 vs. 传统JAVA开发
大模型开发——大模型实现业务逻辑:
开发前,开发人员关注数据准备(进行训练)、选择和微调模型(得到更好的效果,更能匹配业务预期),
开发过程中(大多数时候),重点在于如何有效的与大模型(LLM)进行沟通,利用LLM的专业知识解决特定的业务问题,
开发中更关注如何描述问题(提示工程 Propmt Engineering)进行有效的推理,关注如何将大模型的使用集成到现有的业务系统中。
传统的JAVA开发——开发者实现业务逻辑:
开发前,开发人员关注系统架构的选择(高并发、高可用),功能的拆解、模块化等设计。
开发过程中(大多数时候)是根据特定的业务问题,设计特定的算法、数据存储等以实现业务逻辑,以编码为主。
3. 实战经验
3.1 环境搭建
3.1.1 向量库(Chroma)
Windows:
先安装python,参考: https://docs.python.org/zh-cn/3/using/windows.html#the-full-installer
PS:注意需要配置环境变量
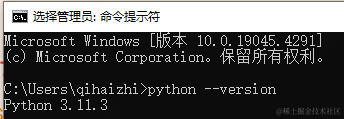
验证-执行:
python --version
- 1
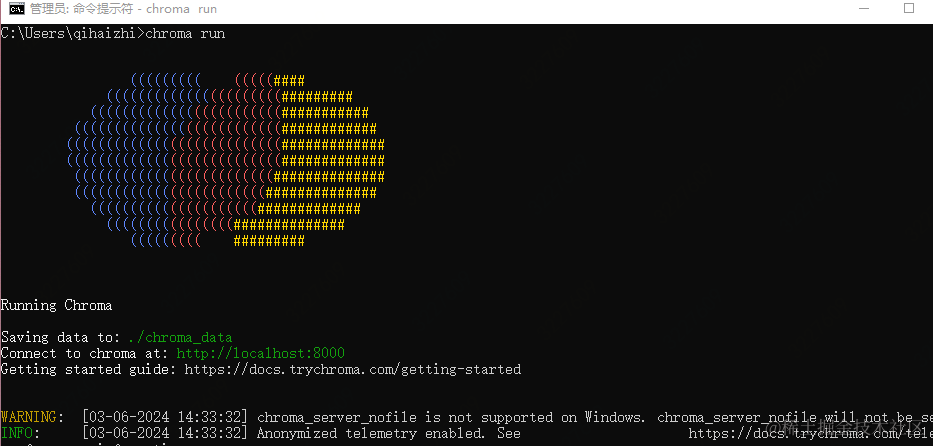
再安装chroma,参考:https://docs.trychroma.com/getting-started
验证-执行:
chroma run
- 1
Mac:
现先安装python
brew install python
- 1
或者下载安装: https://www.python.org/downloads/macos/
验证-执行:
python --version
- 1

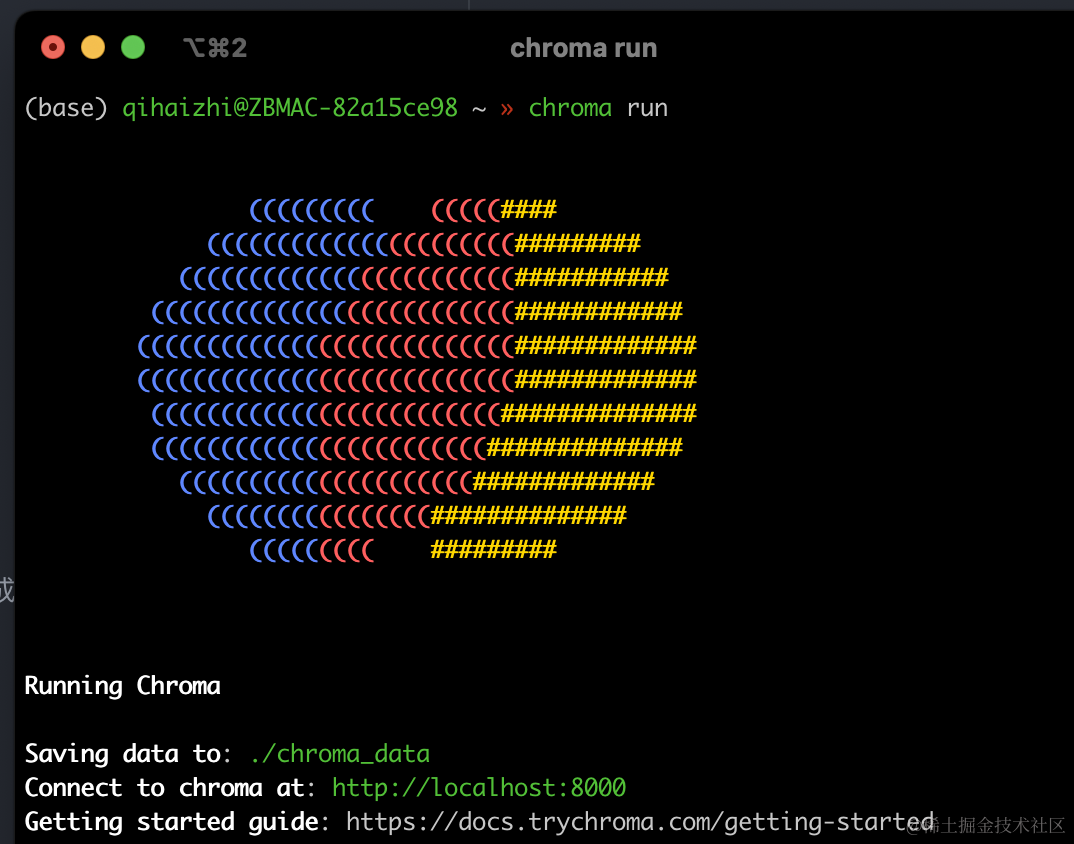
安装chroma(同上),参考:https://docs.trychroma.com/getting-started
验证-执行:
chroma run
- 1
3.1.2 集成LangChain4j
<properties> <langchain4j.version>0.31.0</langchain4j.version> </properties> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-core</artifactId> <version>${langchain4j.version}</version> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j</artifactId> <version>${langchain4j.version}</version> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-open-ai</artifactId> <version>${langchain4j.version}</version> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-embeddings</artifactId> <version>${langchain4j.version}</version> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-chroma</artifactId> <version>${langchain4j.version}</version> </dependency> <dependency> <groupId>io.github.amikos-tech</groupId> <artifactId>chromadb-java-client</artifactId> <version>${langchain4j.version}</version> </dependency>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
3.2 程序编写
3.2.1 项目结构
LangChain ├── core │ ├── src │ │ ├── main │ │ │ ├── java │ │ │ │ └── cn.jdl.tech_and_data.ka │ │ │ │ ├── ChatWithMemory │ │ │ │ ├── Constants │ │ │ │ ├── Main │ │ │ │ ├── RagChat │ │ │ │ └── Utils │ │ │ ├── resources │ │ │ │ ├── log4j2.xml │ │ │ │ └── 笑话.txt │ │ ├── test │ │ │ └── java │ ├── target ├── pom.xml ├── parent [learn.langchain.parent] ├── pom.xml
3.2.2 知识采集
一般是公司内网的知识库中或互联网上进行数据采集,获取到的文本文件、WORD文档或PDF文件,本文使用resources目录下的【笑话.txt】作为知识采集的结果文件
URL docUrl = Main.class.getClassLoader().getResource("笑话.txt");
if(docUrl==null){
log.error("未获取到文件");
}
Document document = getDocument(docUrl);
if(document==null){
log.error("加载文件失败");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
private static Document getDocument(URL resource) {
Document document = null;
try{
Path path = Paths.get(resource.toURI());
document = FileSystemDocumentLoader.loadDocument(path);
}catch (URISyntaxException e){
log.error("加载文件发生异常", e);
}
return document;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.2.3 文档切分
使用dev.langchain4j.data.document.splitter.DocumentSplitters#recursize
它有三个参数:分段大小(一个分段中最大包含多少个token)、重叠度(段与段之前重叠的token数)、分词器(将一段文本进行分词,得到token)
其中,重叠度的设计是为了减少按大小拆分后切断原来文本的语义,使其尽量完整。

DocumentSplitter splitter = DocumentSplitters.recursive(150,10,new OpenAiTokenizer());
splitter.split(document);
- 1
- 2
关于Token(标记) :
Token是经过分词后的文本单位,即将一个文本分词后得到的词、子词等的个数,具体取决于分词器(Tokenizer),
比如:我喜欢吃苹果,可以拆分成我/喜欢/吃/苹果,token数量=4, 也可以拆分成我/喜/欢/吃/苹果,token数量=5
chatGPT使用的是BPE(Byte Pair Encoding)算法进行分词,参见: https://en.wikipedia.org/wiki/Byte_pair_encoding
对于上面文本的分词结果如下:
18:17:29.371 [main] INFO TokenizerTest - 待分词的文本:我喜欢吃苹果
18:17:30.055 [main] INFO cn.jdl.tech_and_data.ka.Utils - 当前的模型是:gpt-4o
18:17:31.933 [main] INFO TokenizerTest - 分词结果:我 / 喜欢 / 吃 / 苹果
- 1
- 2
- 3
关于token与字符的关系:GPT-4o的回复:

关于文档拆分的目的:
由于与LLM交互的时候输入的文本对应的token长度是有限制的,输入过长的内容,LLM会无响应或直接该报错,
因此不能将所有相关的知识都作为输入给到LLM,需要将知识文档进行拆分,存储到向量库,
每次调用LLM时,先找出与提出的问题关联度最高的文档片段,作为参考的上下文输入给LLM。
入参过长,LLM报错:

虽然根据响应,允许输入1048576个字符=1024K个字符=1M个字符,
但官网文档给的32K tokens,而一般1个中文字符对应1-2个Token,因此字符串建议不大于64K,实际使用中,为了保障性能,也是要控制输入不要过长。
如下是常见LLM给定的token输入上限:
| 模型名称 | Token 输入上限(最大长度) |
|---|---|
| GPT-3 (davinci) | 4096 tokens |
| GPT-3.5 (text-davinci-003) | 4096 tokens |
| GPT-4 (8k context) | 8192 tokens |
| GPT-4 (32k context) | 32768 tokens |
| LLaMA (7B) | 2048 tokens |
| LLaMA (13B) | 2048 tokens |
| LLaMA (30B) | 2048 tokens |
| LLaMA (65B) | 2048 tokens |
| 讯飞星火(SparkDesk) | 8192 tokens |
| 文心一言(Ernie 3.0) | 4096 tokens |
| 智源悟道(WuDao 2.0) | 2048 tokens |
| 阿里巴巴 M6 | 2048 tokens |
| 华为盘古(Pangu-Alpha) | 2048 tokens |
| 言犀大模型(ChatJd) | 2048 tokens |
文档拆分的方案langchain4j中提供了6种:
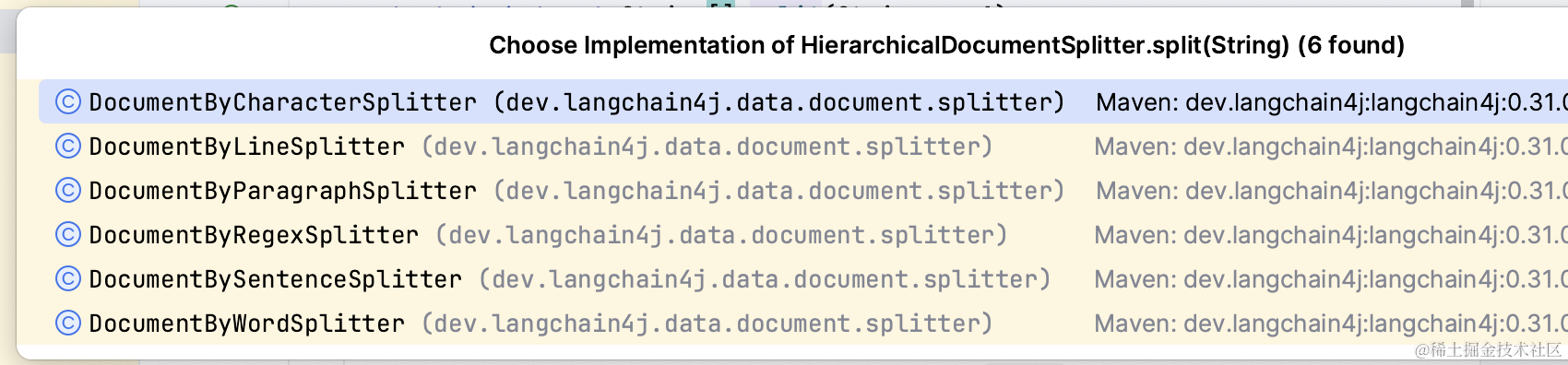
1、基于字符的:逐个字符(含空白字符)分割
2、基于行的:按照换行符(\n)分割
3、基于段落的:按照连续的两个换行符(\n\n)分割
4、基于正则的:按照自定义正则表达式分隔
5、基于句子的(使用Apache OpenNLP,只支持英文,所以可以忽略
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

