
热门标签
热门文章
- 1RabbitMQ (五) --------- RabbitMQ 集群_rabbitmq数据汇聚
- 2android串口通信——android-serialport-api
- 38254定时/计数器应用_8254aa电路原理
- 4【微信小程序】基础篇 -- WXML & WXSS & JS 逻辑交互介绍(四)_javascript逻辑交互微信小程序开发
- 5基于大数据平台分析前程无忧大数据招聘信息实现数据可视化_招聘可视化文章
- 6初次使用Github_this is a list of ssh keys associated with your ac
- 7AI在创造还是毁掉音乐?
- 8数据库|DR-AUTO-SYNC架构集群搭建及主备切换手册
- 9[NOIP2018 普及组] 对称二叉树 题解_2018noip普及组对称二叉树
- 10Spring系列:Spring6简介和基本使用
当前位置: article > 正文
Hadoop学习总结(Hive的远程服务、数据模型操作、数据操作)_在hadoop集群上启动hive远程服务
作者:天景科技苑 | 2024-07-05 18:57:43
赞
踩
在hadoop集群上启动hive远程服务
在启动hive时要先启动Hadoop。
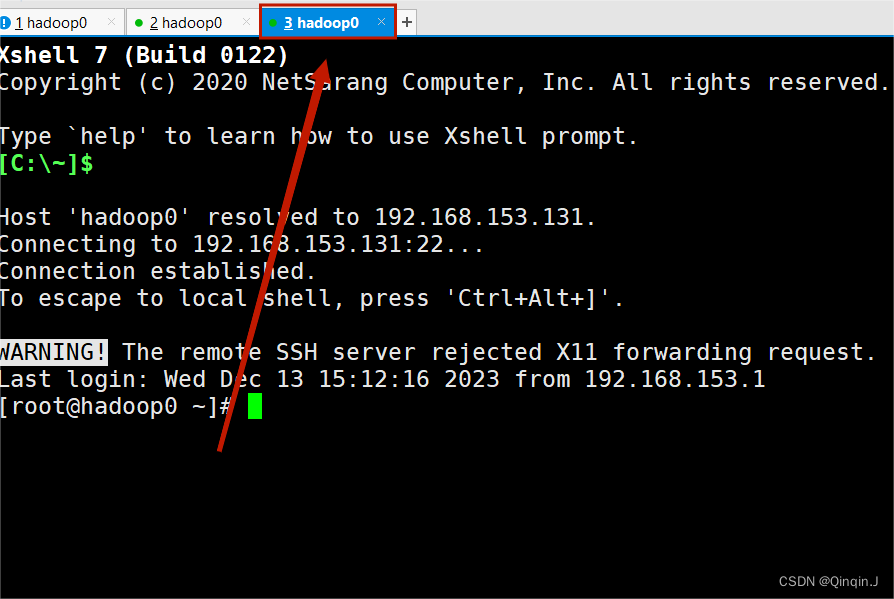
在SecurityCRT 或者在 Xshell 进行虚拟机链接
(这里使用Xshell )
一、Hive 的管理
1、CLI 方式
(1)启动 Hive
直接输入 hive
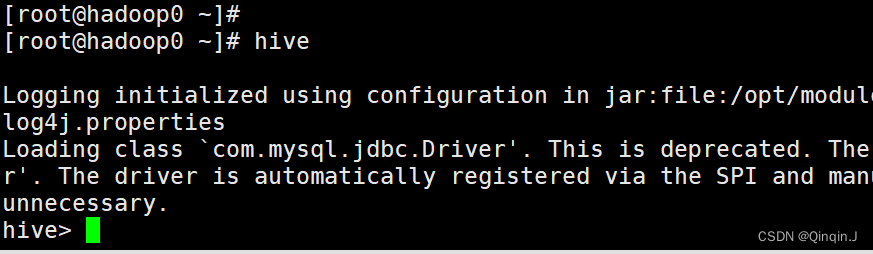
(2)退出
直接输入以下一条命令,命令如下:
- exit;
- quit;
(3)查看数据仓库中的表
命令如下:
show tables;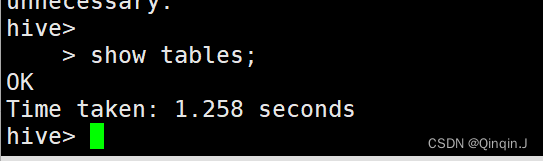
(4)查看数据仓库中的内置函数
命令如下:
show functions;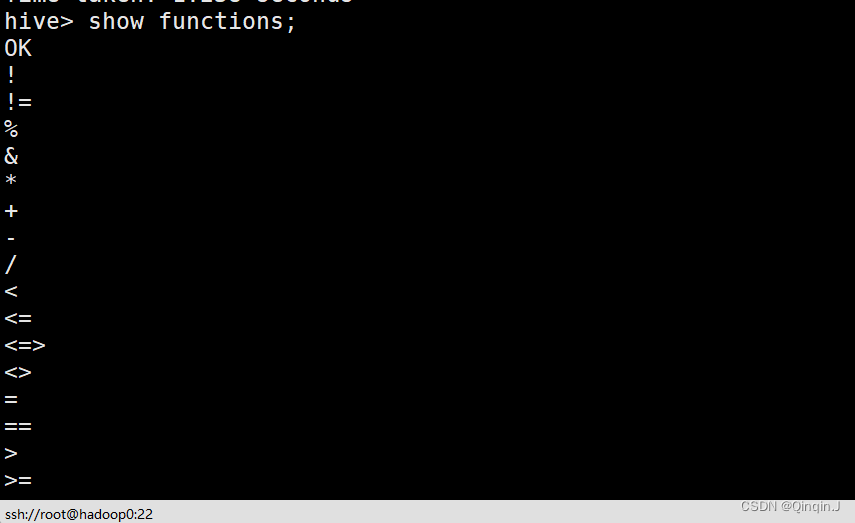
以上结果是还未截图完的
(5)清屏
命令如下:
!clear;2、远程服务
在启动hive时要先启动Hadoop。先启动hive 然后再启动 hiveserver2
输入 hiveserver2 之后不需要在操作,不能关闭当前会话,复制一个会话
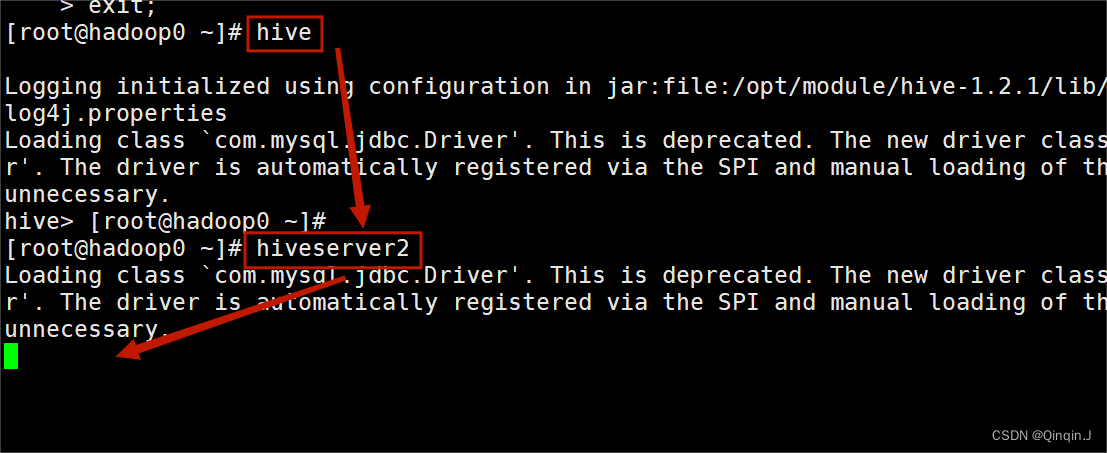
复制新的会话,以下操作在新会话中
在新会话中输入 jps 进行查看,出现图片以下进程,表示启动 hiveserver2 成功
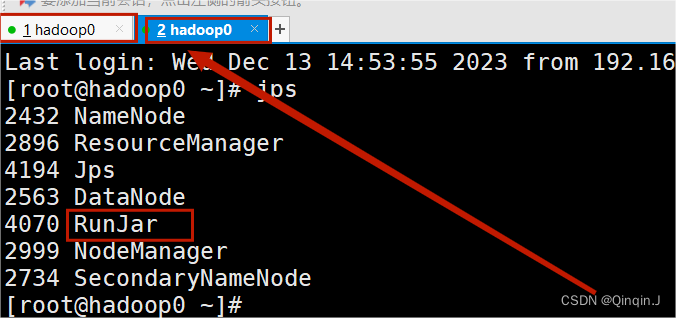
进行数据库远程连接
- 输入远程连接命令
- beeline
-
- 输入远程连接协议,连接到指定 Hive 服务(hadoop0)的主机名和端口号(默认10000)
- !connect jdbc:hive2://hadoop0:10000
-
- 输入用户名和密码
-
- 查看数据库
- show databases;
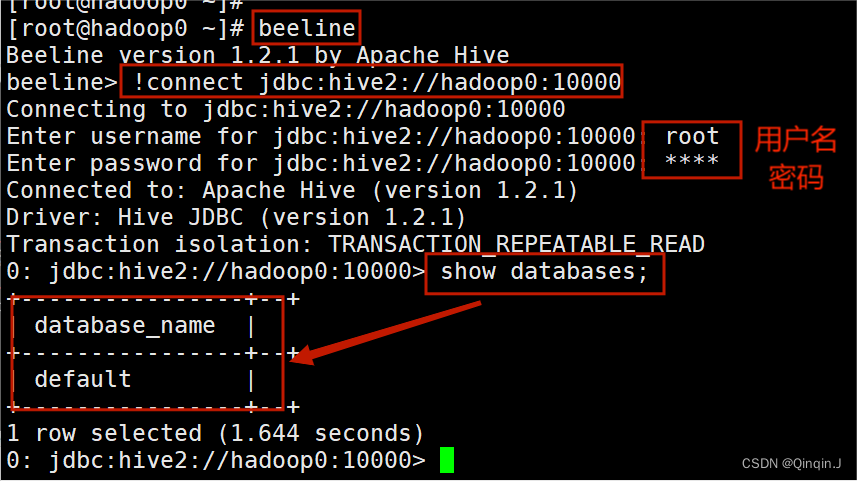
执行 show databases; 命令成功,说明远程连接成功。
二、数据模型操作
1、Hive 数据库操作
(1)创建一个数据库
- 语法:
- create database 数据库名;
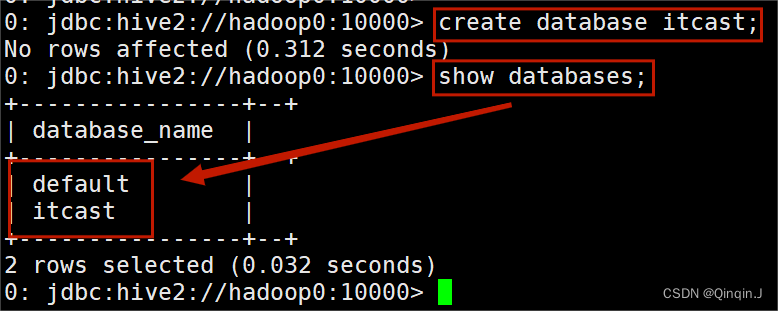
(2)显示数据库
- 语法:
- show databases;
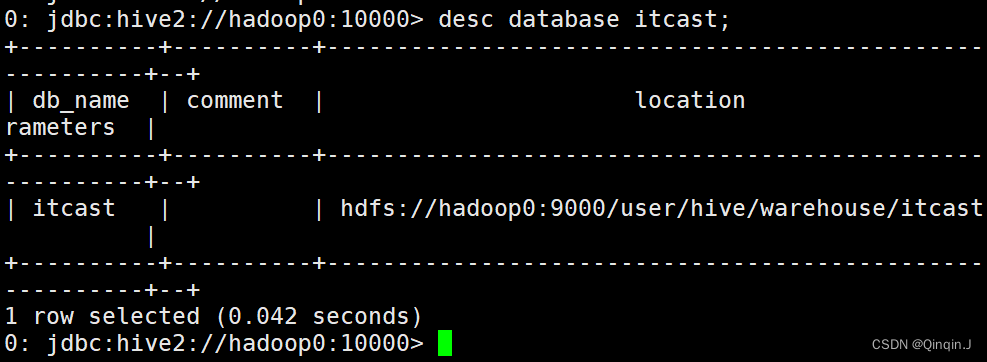
(3)查看数据库详情
- 语法:
- desc database 数据库名;
(4)切换数据库
- 语法:
- use 数据库名;

(5)修改数据库
- 语法:
- alter 数据库名 set dbproperties
- (property_name = property_value,...)
(6)删除数据库
- 语法:
- drop database 数据库名;

2、Hive 内部表的操作
创建一个数据表
- 创建一个数据表
- create table complex(
- col1 array<int>,
- col2 map<int,string>,
- col3 struct<a:string,b:int,c:double>
- );
-
- 查看数据表
- show tables;

(1)基本类型建表
为了方便操作克隆一个新的会话
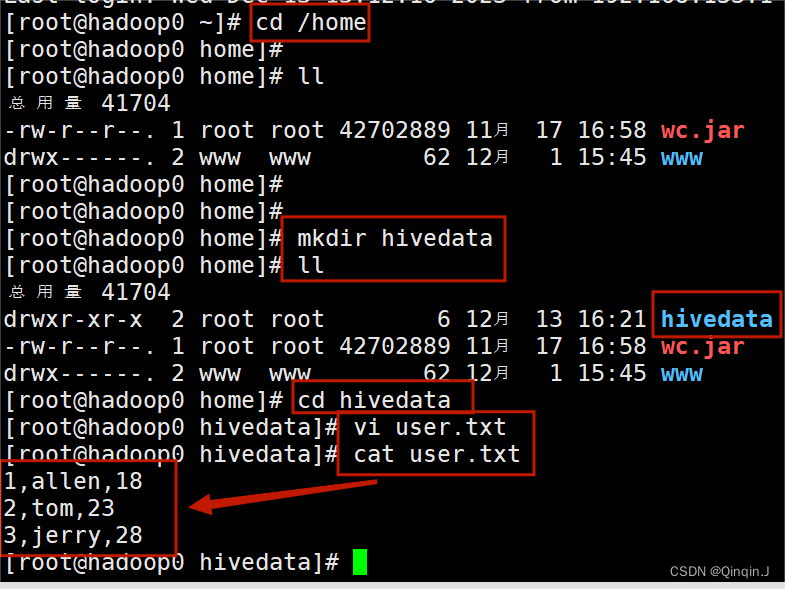
首先在hadoop0的 /home 目录下 创建 hivedata 目录,在该文件下创建 user.txt 文件,并添加以下内容:
| user.txt |
|---|
| 1,allen,18 2,tom,23 3,jerry,28 |
- 进入 /home 目录
- cd /home
-
- 创建 hivedata 目录
- mkdir hivedata
-
- 查看
- ll
-
- 进入 hivedata 目录
- cd hivedata
-
- 创建 user.txt 文件,并添加内容
- vi user.txt
-
- 查看 user.txt 文件内容
- cat user.txt

建表语法:
- create table t_表名(字段1 字段类型, 字段2 字段类型, ...) row format
- delimited fields terminated by '字符分隔符';
法一:
创建数据表
创建表中的 ',' 表示在数据中用 , 来间隔
create table t_user(id int,name string,age int) row format delimited fields terminated by ',';
把文件 user.txt上传到 hdfs集群上
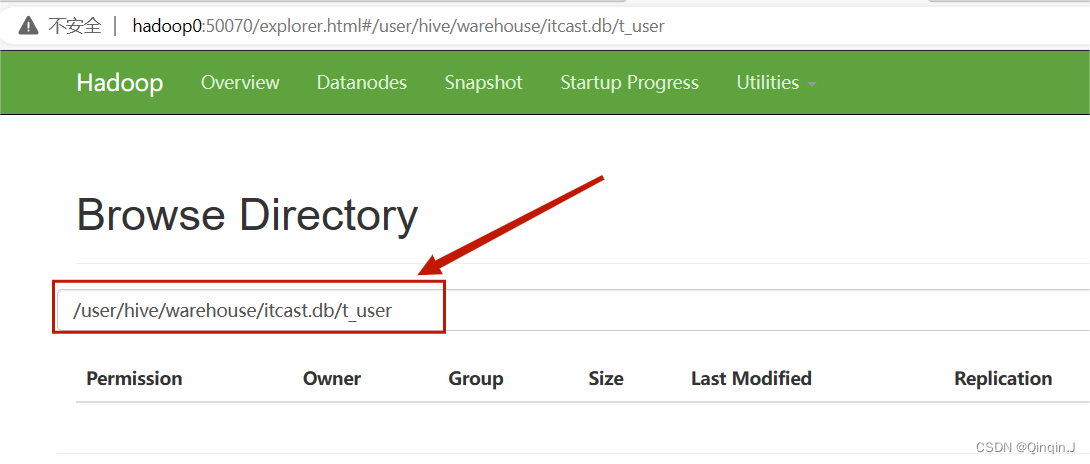
上传命令
hadoop fs -put user.txt /user/hive/warehouse/itcast.db/t_user
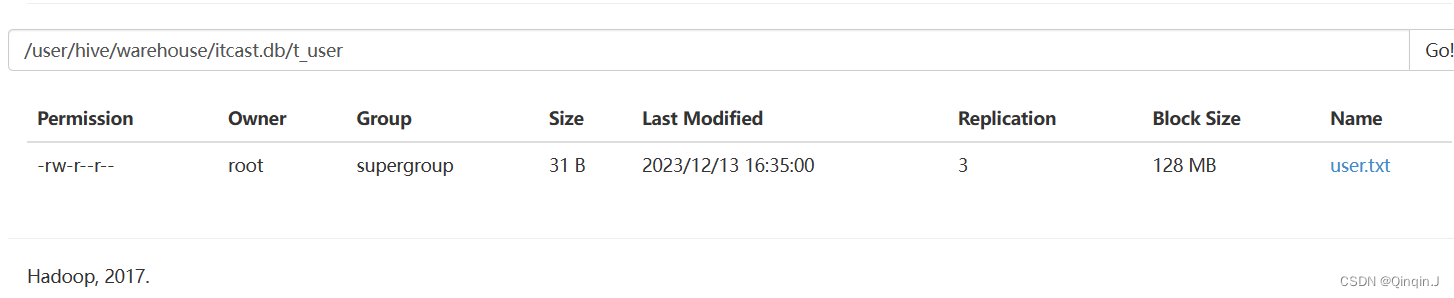
查看数据表,就能看到数据
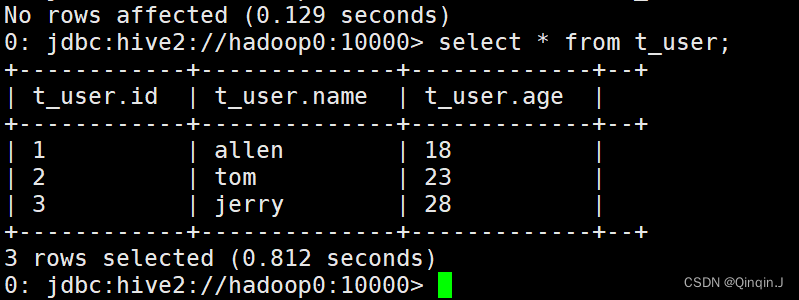
法二:
创建数据表
创建表中的 ',' 表示在数据中用 , 来间隔
create table t_user(id int,name string,age int) row format delimited fields terminated by ',';
将数据加载到 hdfs上
- load data local inpath '/home/hivedata/user.txt/' into table t_user;
- select * from t_user;
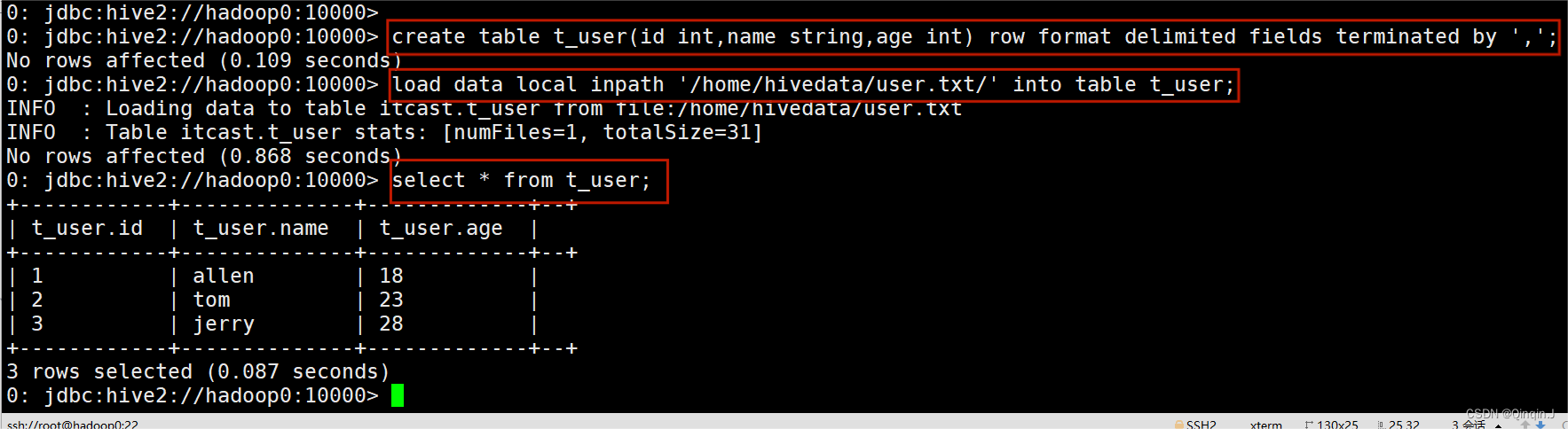
(2)删除数据表
drop table 数据库名;(3)复杂类型建表
建表语句:
- create table t_表名(字段1 字段类型, 字段2 字段类型, ...)
- row format delimited fields terminated by '字符分隔符'
- collection items terminated by '字符分隔符'
- map keys terminated by '字符分隔符';
例子:
首先创建一个文件名为student.txt添加以下内容
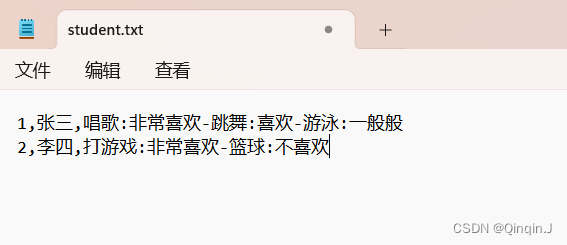
将内容上传到虚拟机上
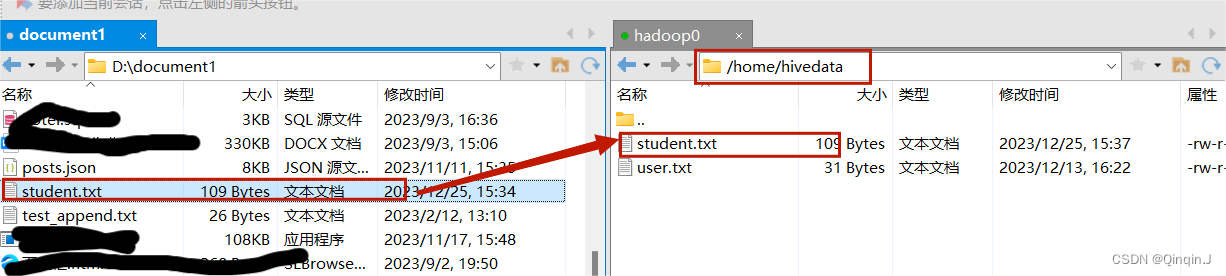
查看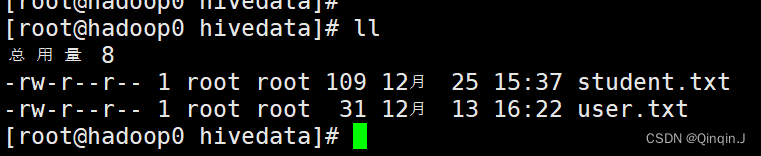
创建表:
- create table t_student(id int, name string, hobby map<string, string>)
- row format delimited fields terminated by ','
- collection items terminated by '-'
- map keys terminated by ':';

加载驱动:
load data local inpath '/home/hivedata/student.txt/' into table t_student;
查询表:
select * from t_student;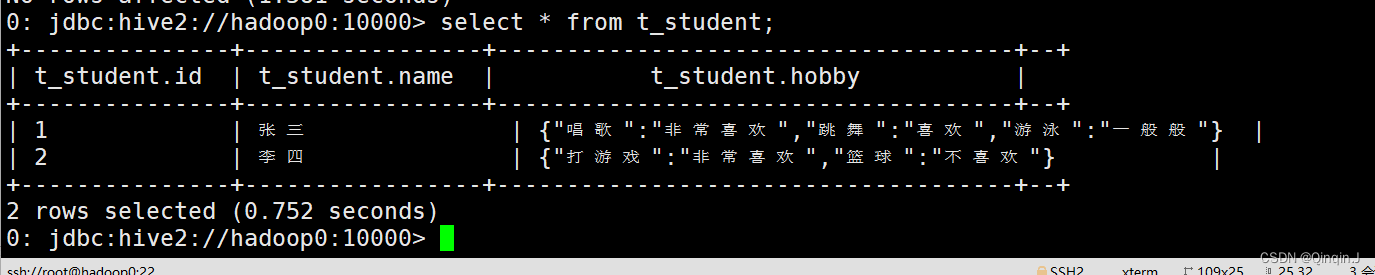
3、Hive 外部表的操作
首先在HDFS上创建文件夹,传输数据到文件夹上
- 创建文件夹
- hadoop fs -mkdir /hivedata
- 传输数据
- hadoop fs -put /home/hivedata/user.txt /hivedata

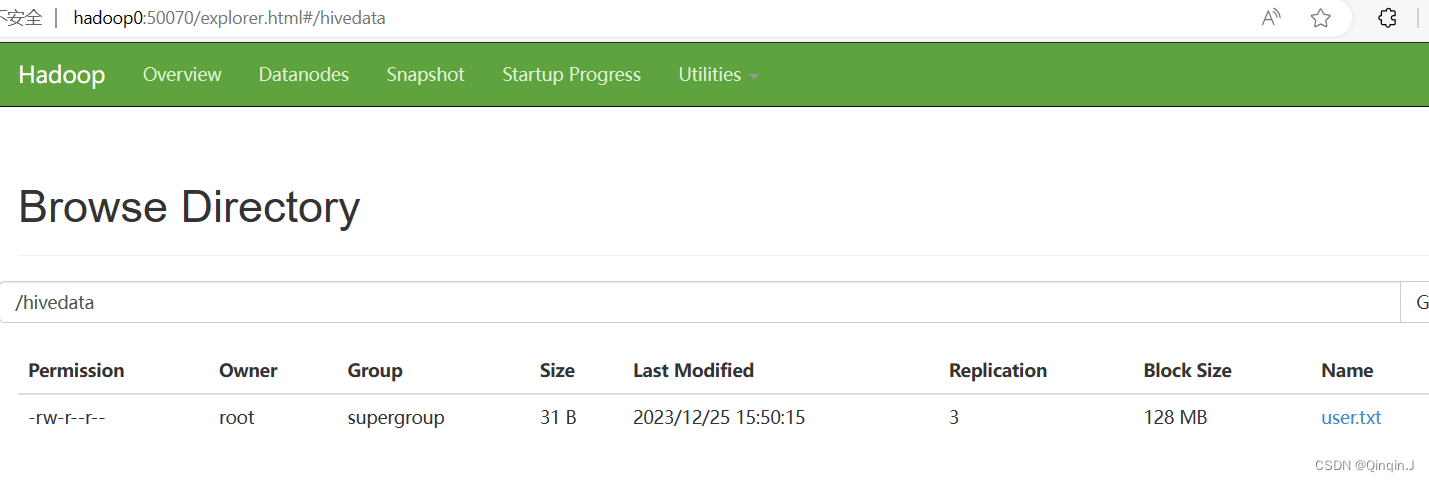
建表语句:
- create external table t_表名(字段1 字段类型, 字段2 字段类型, ...) row format
- delimited fields terminated by '字符分隔符' location 'hdfs上的文件路径'
- 1、创建表
- create external table t_表名(字段1 字段类型, 字段2 字段类型, ...) row format
- delimited fields terminated by '字符分隔符' location 'hdfs上的文件路径'
-
- 2、装载数据(上传到HDFS) /home/hivedata/student.txt --> 表所在的文件夹(/user/hive/warehouse/itcast.db/t_student)
创建表:
create external table t_student2(id int,name string ,age int) row format delimited fields terminated by ',' location '/hivedata';
查询表:
select * from t_student2;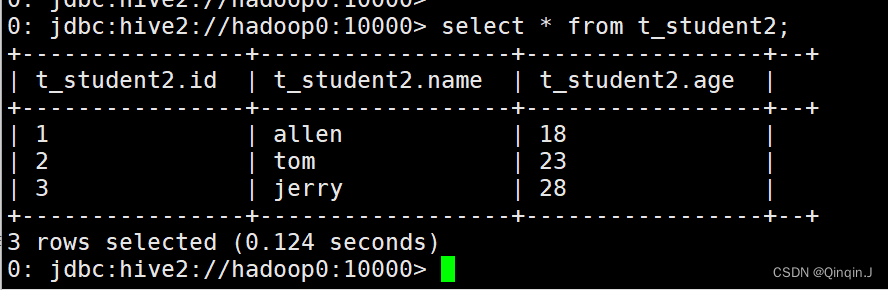
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/天景科技苑/article/detail/790762
推荐阅读
相关标签

