
- 1python提取pdf文件中的图片并输出到本地_python 提取pdf中图片保存到本地
- 2RNN(LSTM)数据形式及Padding操作处理变长时序序列dynamic_rnn_rnn padding
- 3chatgpt中文设置流程_chatgpt设置中文
- 4腾讯云 - 边缘安全加速平台 EO、内容分发网络 CDN、全站加速网络 ECDN、安全加速 SCDN 等产品对比
- 5git 指定下载文件,目录_git 下载指定文件
- 6Windows下Python安装库的5种常用方法_windows中如何在指定python环境中安装下载好的包安装库
- 7基于深度学习的聚类算法综述_深度学习图像聚类
- 8数据结构题目练习_利用原表的存储空间和利用原有结点是一回事儿吗
- 9perl版本差别引起的异常message_perl 5.14与5.08的区别
- 10数组删除方法
【图解大数据技术】Hive、HBase
赞
踩
Hive
Hive是基于Hadoop的一个数据仓库工具,Hive的数据存储在HDFS上,底层基于MapReduce进行数据计算。Hive将HDFS中结构化的数据文件映射成一张表,然后提供类SQL的查询功能,然后将SQL翻译成MapReduce并执行,可以解决海量结构化日志的统计查询。
数据仓库
数据仓库的作用是存储大量的历史数据,然后给各种BI报表、其他图形化界面或生成各种报告的系统提供数据分析统计的功能。
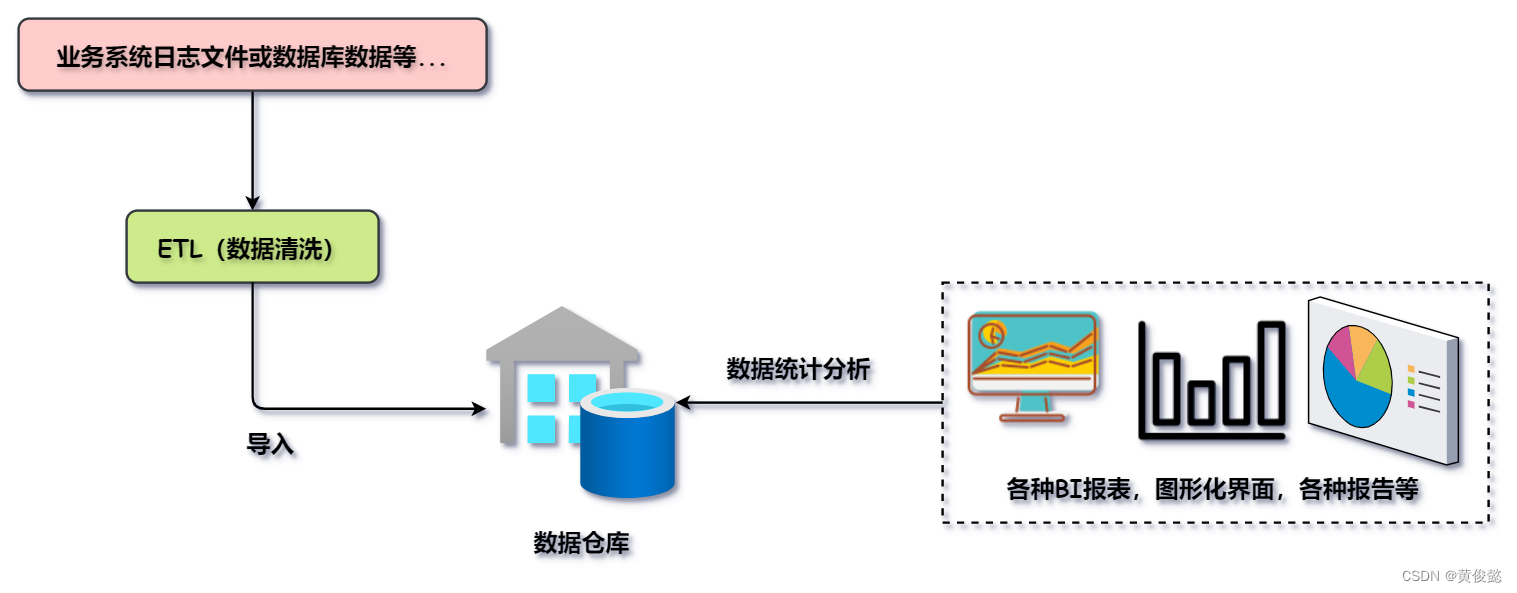
数据仓库的数据来源一般是各种业务系统的日志文件或者数据库的历史数据等,经过数据清洗后到导入到数据仓库。然后使用BI报表等各种非实时性的统计分析应用对数据仓库中的数据做统计分析。
数据仓库本质也是数据库,但是它和传统的关系型数据库还是有区别的。关系型数据库一般给业务系统对数据进行CRUD等OLTP操作,而数据仓库则更多的是给分析型应用进行OLAP操作。
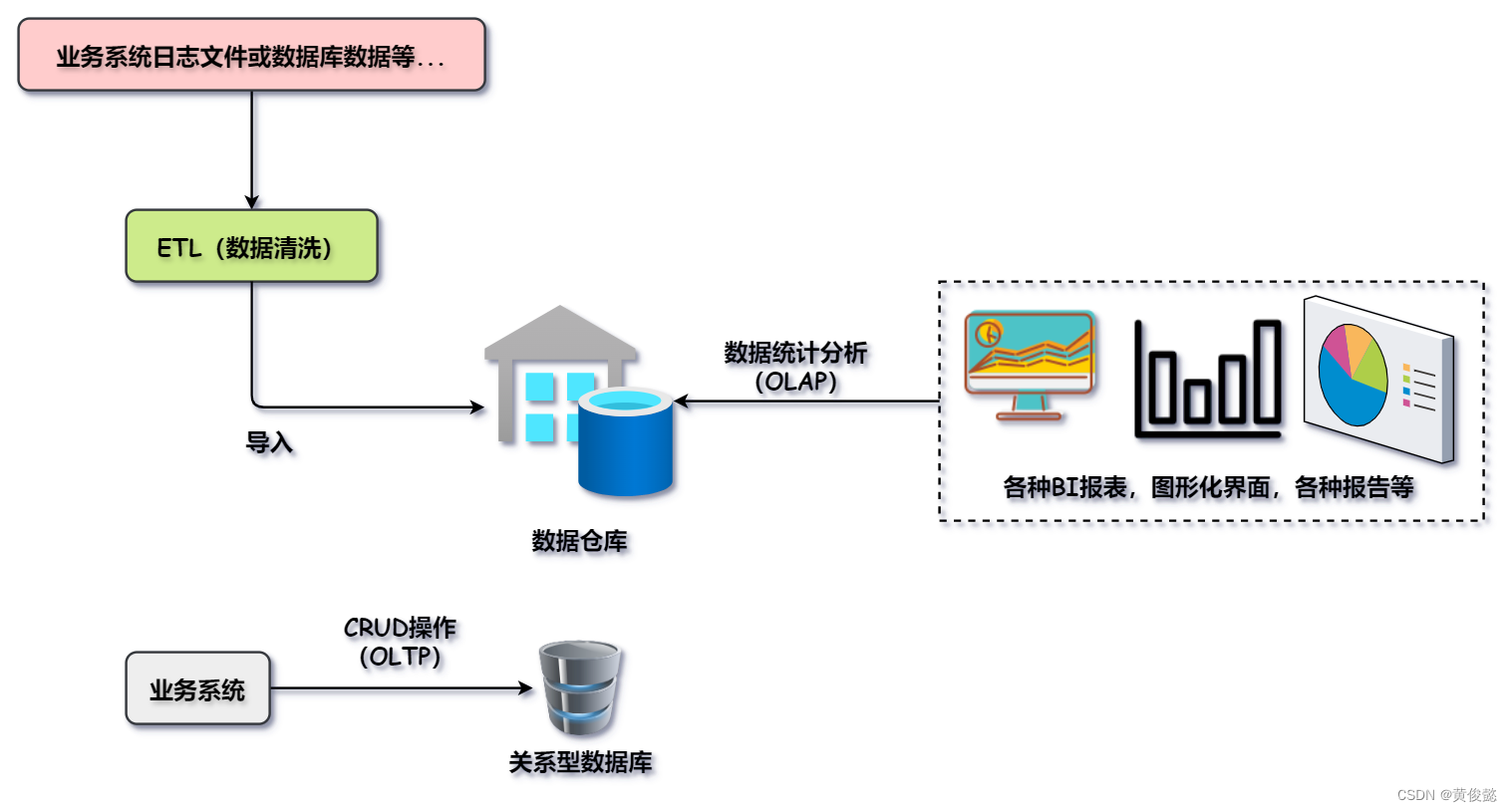
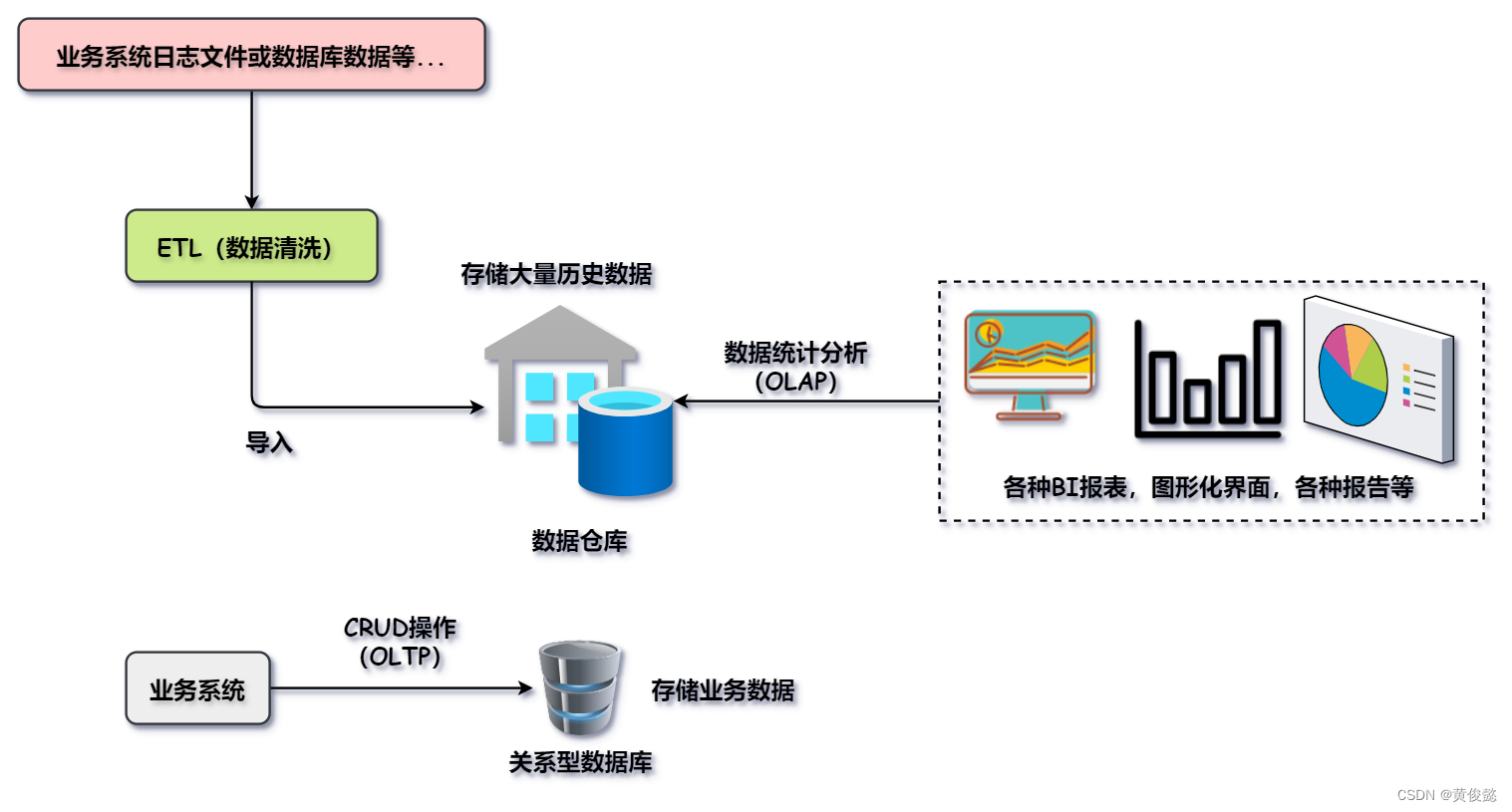
而且关系型数据库一般不会存储大量的历史数据,而是存储近期某个时间范围内的业务数据;而数据仓库则会存储大量的历史数据。
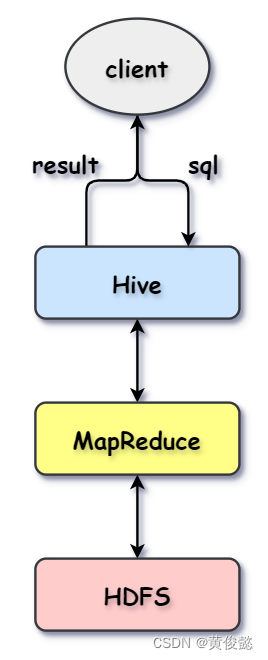
Hive的执行流程
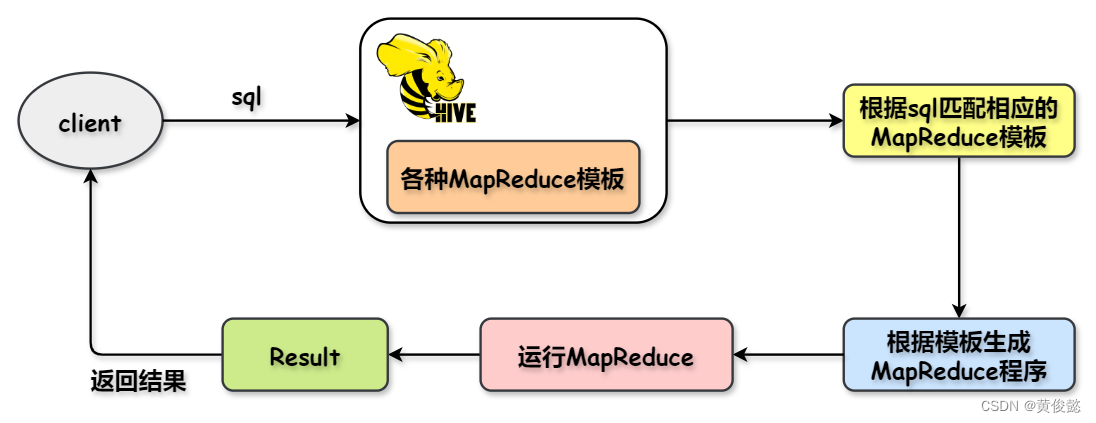
Hive内部封装了各种MapReduce模板,每个MapReduce都与一种SQL类型相对于。当客户端提交sql到hive执行时,hive会根据sql匹配出对应的MapReduce类型,然后执行MapReduce程序,获取返回结果,然后把返回结果返回给客户端。
Hive架构
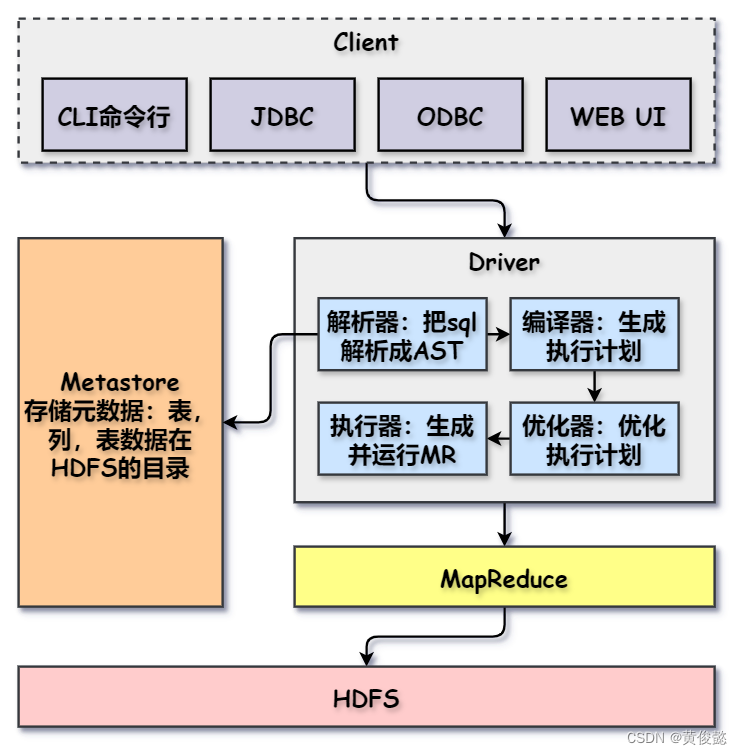
大体架构和MySQL还是有几分相似。
- Client:客户端工具,比如CLI命令行工具,JDBC等。
- Metastore:存储Hive的元数据信息,比如表信息,表的列信息,还有表对应的数据在HDFS中的目录。
- 解析器:解析器解析sql为抽象语法树AST。
- 编译器:根据AST生成执行计划。
- 优化器:对执行计划进行优化。
- 执行器:根据执行计划生成相应的MapReduce并执行。
数据导入Hive

我们需要把数据导入到Hive中,使其在Hive中映射为表,才能通过Hive对数据进行统计分析。
导入的方式有好几种,可以是本地文件,HDFS文件,或者通过sqoop等类似的工具从其他数据源导入。
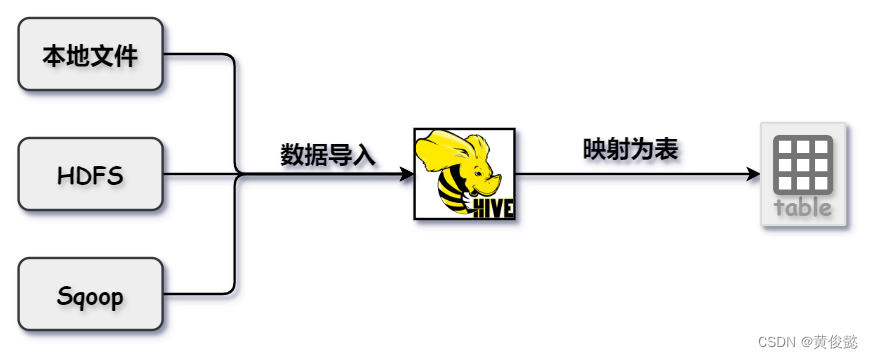
其中Sqoop是Hadoop和关系型数据库间的传输工具,比如可以把Mysql中的数据导入到Hive中。

HBase
HBase简介
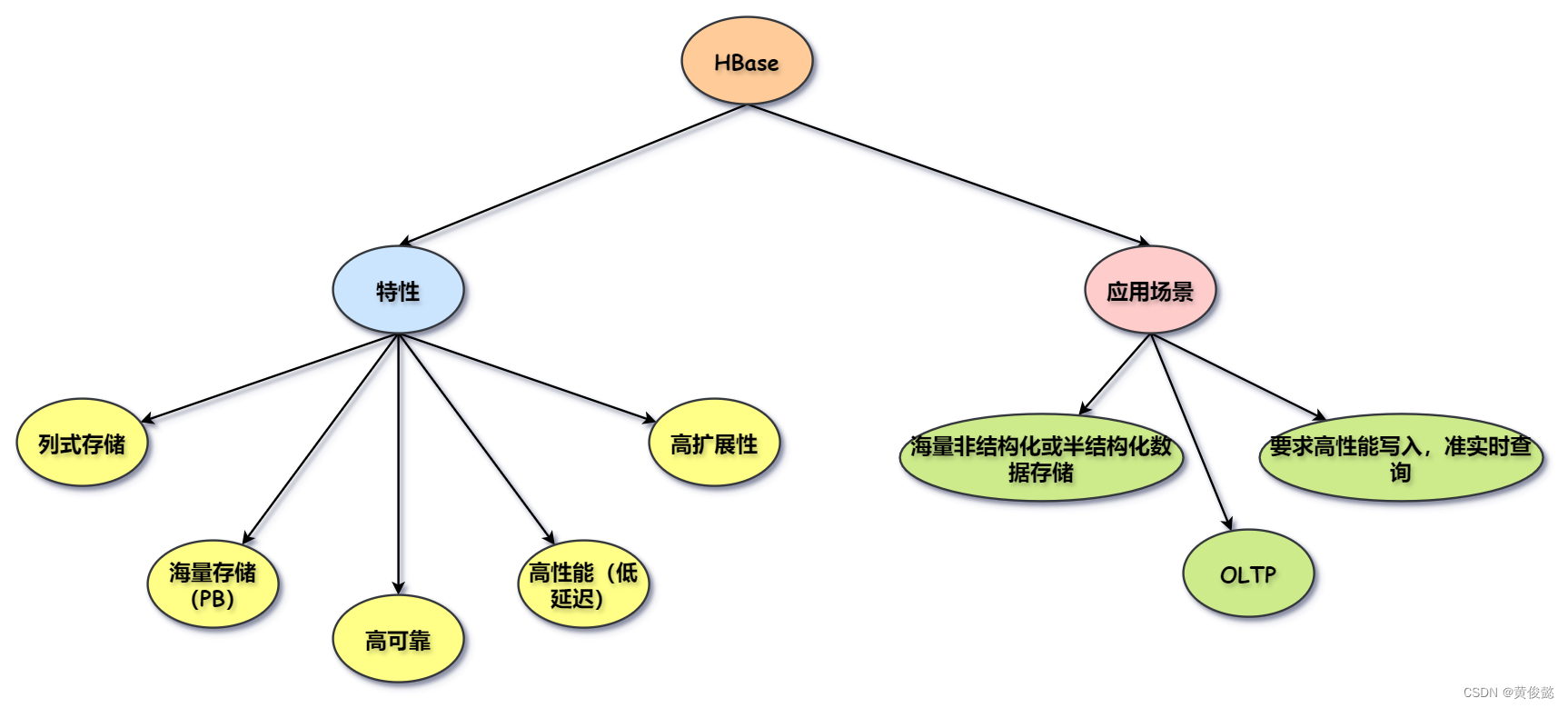
HBase是一个用于存储海量非结构化或半结构化数据的列示存储数据库,支持高性能写入,准实时查询。
- HBase底层基于HDFS实现了PB级别的海量数据存储。
- 通过缓存和预写日志技术实现了高性能写入和低延迟查询。
- 通过Zookeeper的监控通知HMaster故障转移实现了高可靠性。
- 通HMaster接收RegionServer注册以及HMaster的RegionServer集群负载均衡能力实现高扩展性。
HBase架构
HBase的架构与组件间的关系如下图:
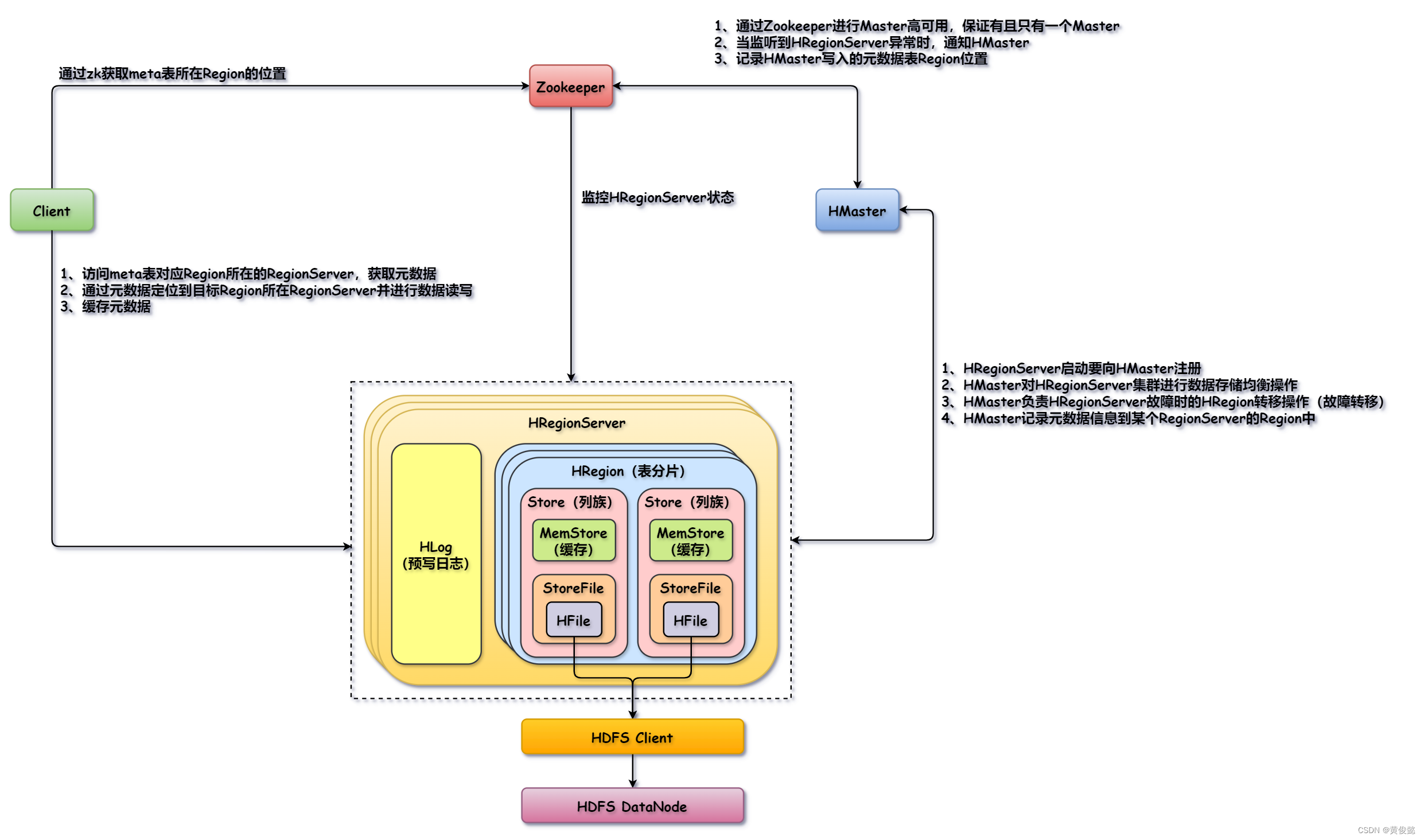
大体由Client、Zookeeper、HMaster、HRegionServer四个角色组成,加上HDFS就是五个。
Client会通过zk读取meta表Region所在的位置,然后请求对应该Region所在RegionServer获取元数据信息,然后通过元数据得知目标Region所在位置,再对目标Region所在RegionServer发起读写操作。
HRegionServer负责数据的存储和处理客户端的读写请求。HRegionServer中有多个HRegion,每个Region对应一个表的一个分片,Region中又有多个Store,每个Stroe对应表中一个列族。然后Stroe中有一个MemStore是Store的缓存,会缓存客户端读写的数据。StoreFile封装了HFile,HFile通过HDFS客户端工具把具有一定格式的文件数据写入到HDFS中。HLog是预写日志,当HRegionServer接收到客户端的写请求时,把数据存储到MemStore中,然后在HLog中记录日志,由于HLog是顺序写,速度很快。
HRegionServer启动时向HMaster注册,HMaster接收HRegionServer的注册并进行HRegionServer的数据存储的负载均衡;HMaster接收到Zookeeper发来的某个HRegionServer故障的通知后,负责HRegionServer的故障转移;HMaster接收到Client的建表请求后,写入元数据到meta表对应的Region,然后记录Region所在位置的HRegionServer到Zookeeper。
Zookeeper负责监控HMaster和HRegionServer,保证它们的高可用;当HRegionServer故障时会通知HMaster;Zookeeper还存储meta表Region的位置,Client可以通过Zookeeper得知meta表Region所在的HRegionServer。
HBase的列式存储
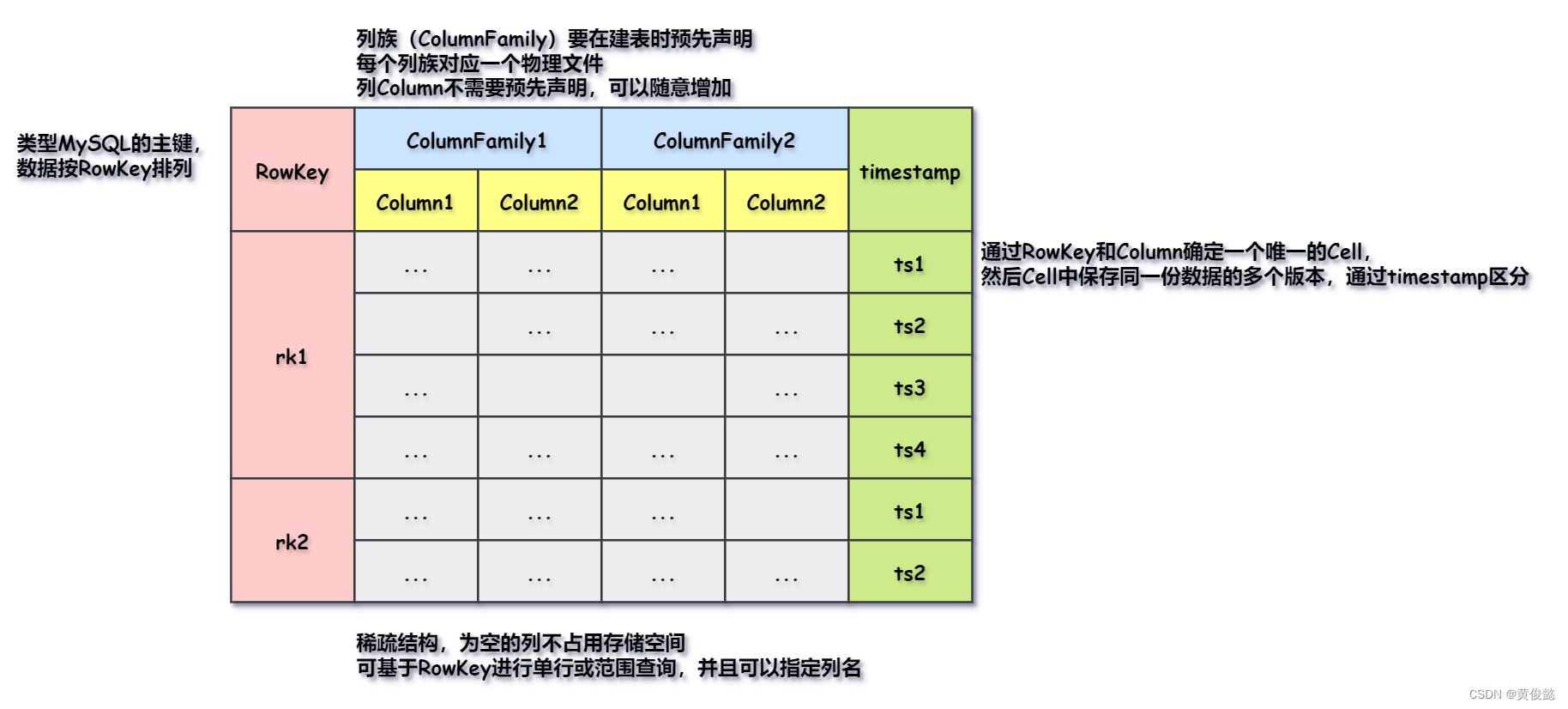
- RowKey:相当于是MySQL中的主键,表中的数据根据RowKey进行排序;我们可以通过RowKey查询指定的某一行或进行范围查询。
- ColumnFamily:列族,在建表的时候需要预先声明列族,一个列族对应一个物理文件。
- Column:列,列无需在建表的时候预先指定,可以随意增加;并且查询的时候可以指定列名进行查询。
timestamp:时间戳,同一个RowKey的不同版本的数据。
HBase建表流程
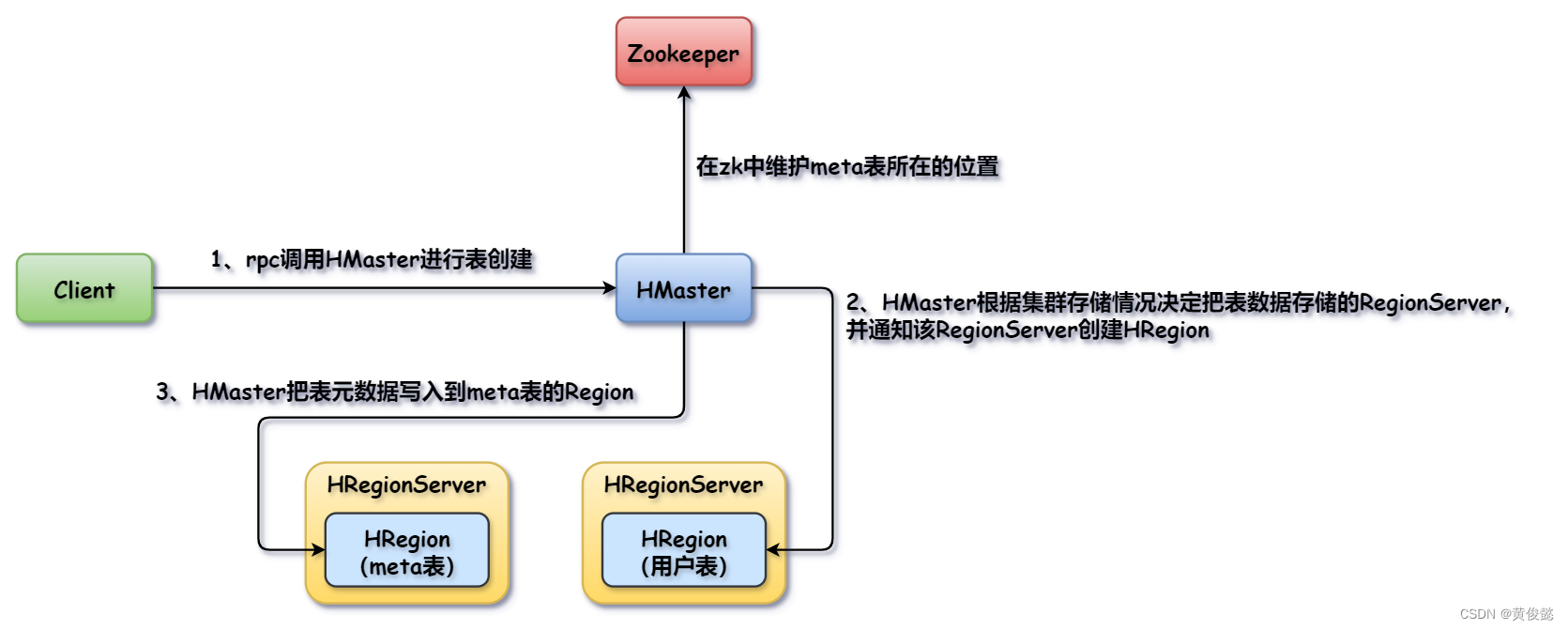
- Client通过rpc调用HMaster进行表创建。
- HMaster根据集群存储情况确定一个RegionServer存储新建表的数据,然后通知该RegionServer创建Region。
- HMaster把表的元数据信息写入meta表对应的Region中;同时如果该Region是新建的话,会在zk中更新meta表所在位置的信息。
HBase数据写入流程
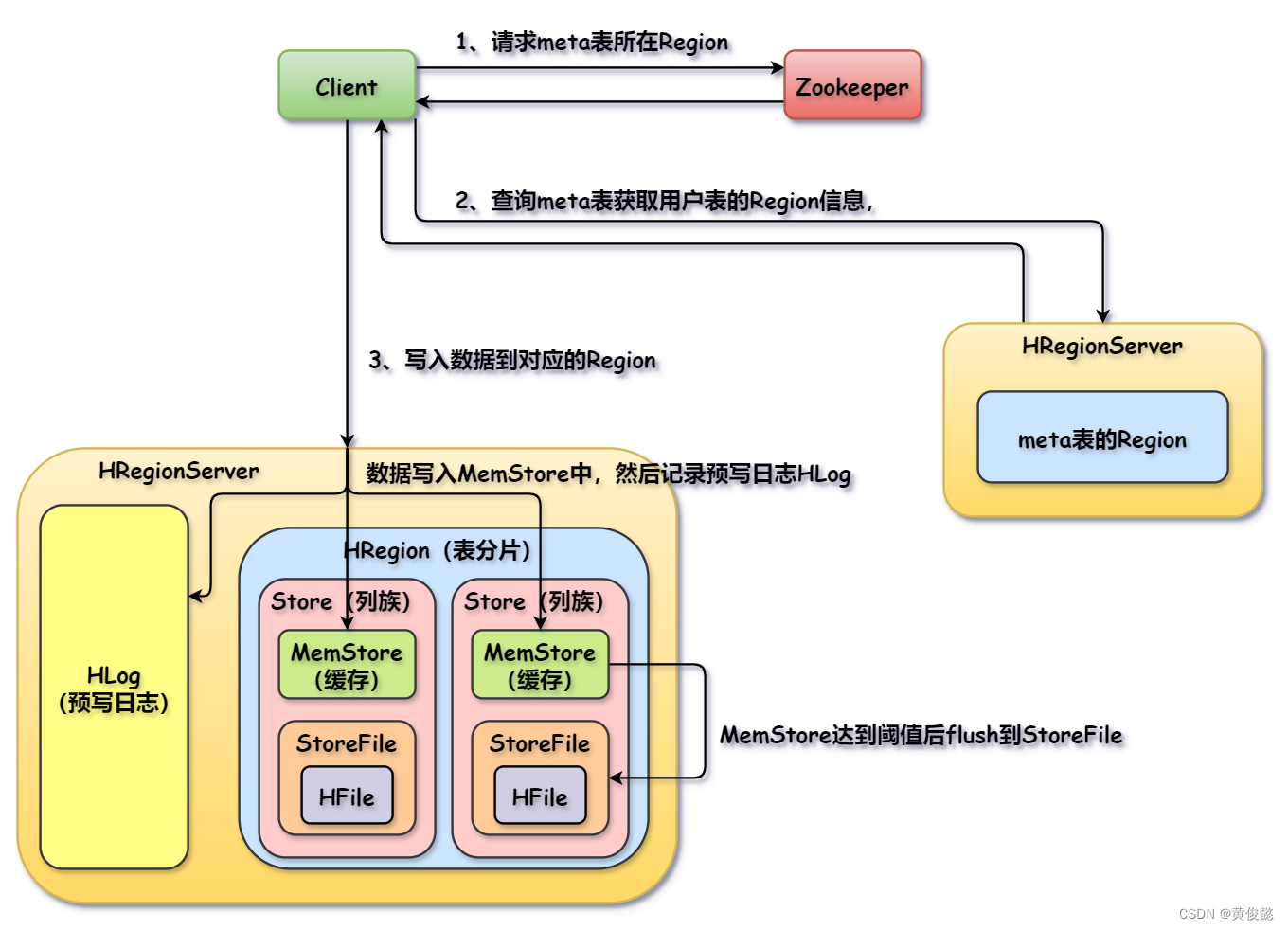
- Client通过ZK得知meta表所在位置。
- Client访问meta表对应的Region,获取目标用户表的元数据,得知该表数据存储在哪个Region上。
- Client访问目标Region写入数据。
- 数据写入MemStore并记录HLog日志,当MemStore达到阈值后才会flush到StoreFile中,StoreFile通过HFile把数据写入到HDFS。
HBase数据读取流程
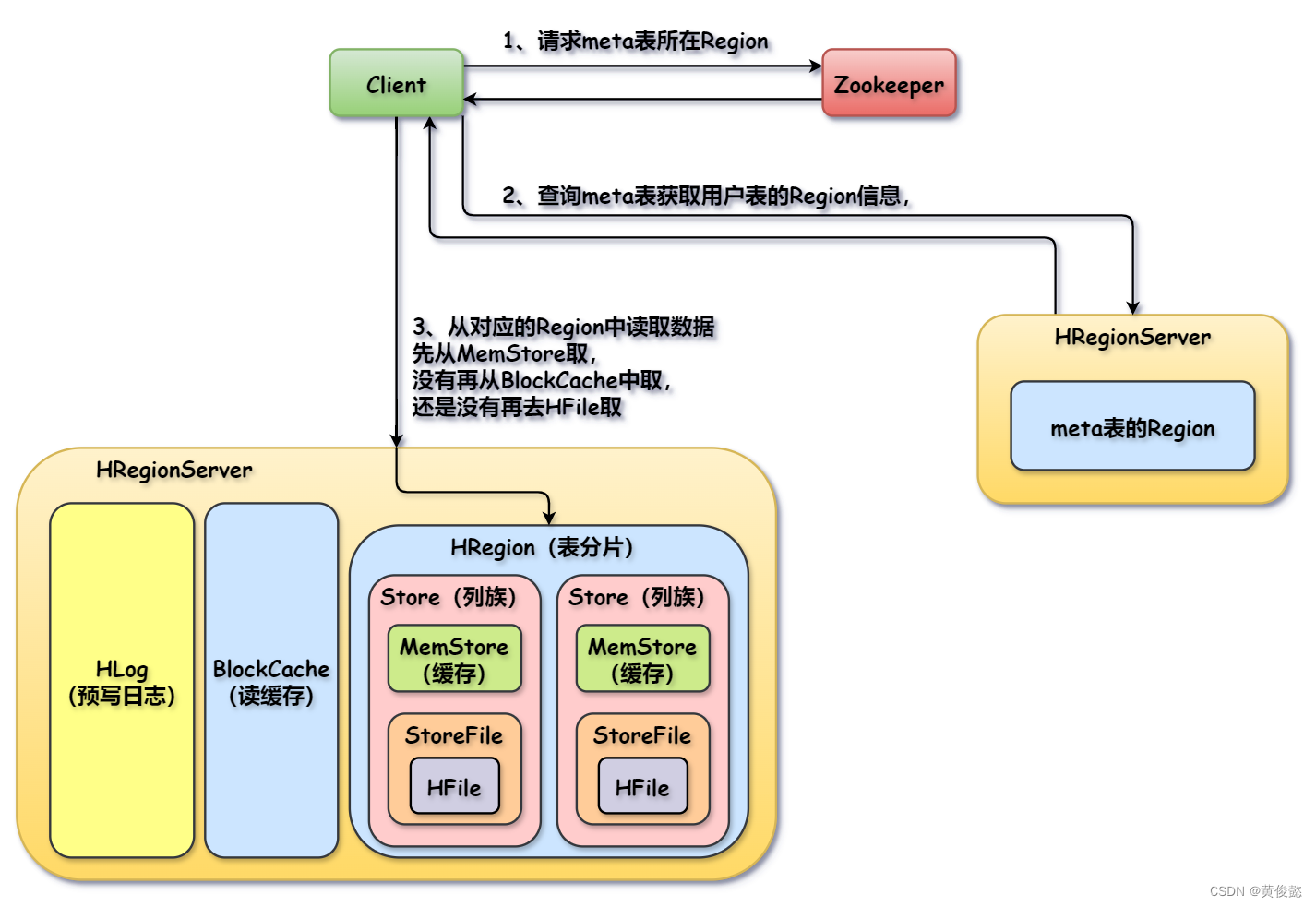
- Client通过ZK得知meta表所在位置。
- Client访问meta表对应的Region,获取目标用户表的元数据,得知该表数据存储在哪个Region上。
- Client访问目标Region读取数据,先尝试从MemStore中读取要查询的数据,如果没有再从BlockCache中读取(BlockCache存储了之前查询返回的数据),还是没有那就要通过HFile从HDFS中取了。

