
热门标签
热门文章
- 1Python使用win32gui.SetWindowPos置顶窗口
- 2https改造-python https 改造
- 3Python学习—Python虚拟环境(pyvenv、virtualenv)_pyvvfv
- 4入职百度-念念不忘,必有回响_百度 面试入职
- 5postgresql导出表结构以及数据到mysql_pg 导出表结构
- 6基于springboot的大学生租房平台的设计与实现论文_基于spring boot的房屋租赁服务平台的毕业论文
- 7时间序列新范式!多尺度+时间序列,刷爆多项SOTA_多尺度的时序信息
- 8灯光秀制作讲解_舞动光线MA2娱乐灯光舞美设计培训毕业展示第五期
- 9IC秋招RTL代码合集
- 10鸿蒙南向开发实战:标准系统-运行(基于RK3568开发板)_开发鸿蒙系统app安装到rk3568平台
当前位置: article > 正文
爬虫爬取百度图片——大量、多张图片_如何爬取百度图片
作者:天景科技苑 | 2024-07-09 02:08:19
赞
踩
如何爬取百度图片
大家好,本文为大家讲解的是使用爬虫爬取百度图片
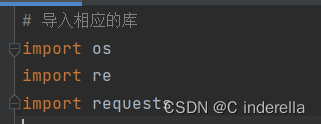
一、导入相应的库
二、获取网站源码
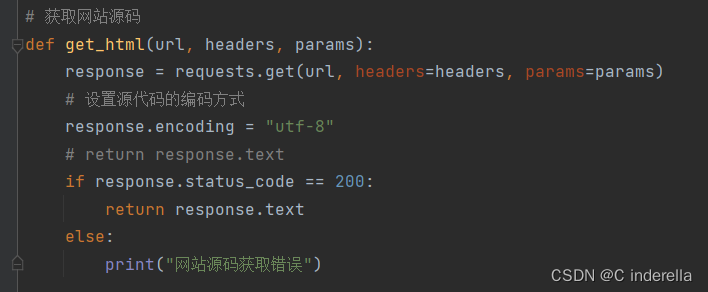
使用"utf-8"的编码方式
三、正则表达式
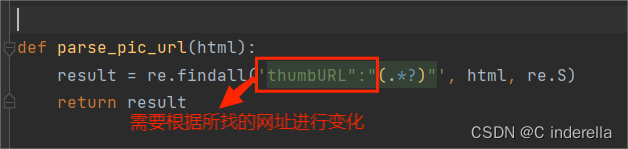
四、获取图片的二进制源码

五、保存图片
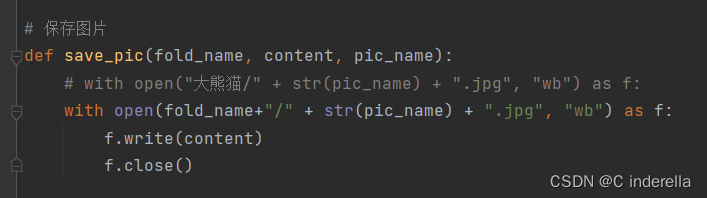
六、定义一个新建文件夹程序

七、定义main函数调用get_html函数
- # 定义main函数调用get_html函数
- def main():
- # 输入文件夹的名字
- fold_name = input("请输入您要抓取的图片名字:")
- # 输入要抓取的图片页数
- page_num = input("请输入要抓取多少页? (0. 1. 2. 3. .....)")
- # 调用函数,创建文件夹
- create_fold(fold_name)
- # 定义图片名字
- pic_name = 0
- # 构建循环,控制页面
- for i in range(int(page_num)):
- url = "https://image.baidu.com/search/acjson?tn=resultjson_com&logid=10039095042888395480&ipn=rj&ct=201326592&is=&fp=result&fr=ala&word=%E5%A4%A7%E7%86%8A%E7%8C%AB%E5%9B%BE%E7%89%87&queryWord=%E5%A4%A7%E7%86%8A%E7%8C%AB%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&expermode=&nojc=&isAsync=&pn=60&rn=30&gsm=3c&1695863795803="
- headers = {
- "Accept": "text/plain, */*; q=0.01",
- "Accept-Encoding": "gzip, deflate",
- "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
- "Connection": "keep-alive",
- "Cookie": "BDqhfp=%E5%A4%A7%E7%86%8A%E7%8C%AB%E5%9B%BE%E7%89%87%26%26NaN-1undefined%26%261632%26%263; BIDUPSID=D076CA87E4CD25BA082EA0E9B5B9C82F; PSTM=1663428044; MAWEBCUID=web_fMcFGAgtkEbzDpinjKvUtGFDInsruypyhIDrXDSpxBBJoXftlZ; BAIDUID=D076CA87E4CD25BA568D2D9EF1AD5F5C:SL=0:NR=10:FG=1; indexPageSugList=%5B%22%E7%8C%AB%22%2C%22%26cl%3D2%26lm%3D-1%26ie%3Dutf-8%26oe%3Dutf-8%26adpicid%3D%26st%3D%26z%3D%26ic%3D%26hd%3D%26latest%3D%26copyright%3D%26word%3D%E5%A4%A7%E8%B1%A1%26s%3D%26se%3D%26tab%3D%26width%3D%26height%3D%26face%3D%26istype%3D%26qc%3D%26nc%3D%26fr%3D%26expermode%3D%26force%3D%26pn%3D30%26rn%3D30%22%2C%22%E6%80%A7%E6%84%9F%E7%BE%8E%E5%A5%B3%22%5D; ZFY=JujkjWiLPjOsSz:Ag1v0hFWlSBt4qjPC4L6bB4MDS6Jo:C; BAIDUID_BFESS=D076CA87E4CD25BA568D2D9EF1AD5F5C:SL=0:NR=10:FG=1; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; userFrom=null; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; ab_sr=1.0.1_YTc4N2NiNWIyZWM5NTkzYzQ3MmZlNTI3Y2YyM2RiMTE3YmYwMTBiNzQ0YzhlZmJkZDY4YjJhZWU4NjVmMmQxZmJkYTcxODZkYTgwNjhhZDY5ZWZmYjg4Y2FmMGE5YTBmNjc3M2JhZDEwZTU1MTAyMTA1MjUxN2Y2NDNlMTJiNzhjNTIyYTQwNTg5ODNiMzc1MjRlZDdmNTVkMzdkOGJiOQ==",
- "Host": "image.baidu.com",
- "Referer": "https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gb18030&word=%B4%F3%D0%DC%C3%A8%CD%BC%C6%AC&fr=ala&ala=1&alatpl=normal&pos=0&dyTabStr=MTEsMCwxLDMsNiw1LDQsMiw3LDgsOQ%3D%3D",
- "Sec-Ch-Ua": '"Microsoft Edge";v="117", "Not;A=Brand";v="8", "Chromium";v="117"',
- "Sec-Ch-Ua-Mobile": "?0",
- "Sec-Ch-Ua-Platform": '"Windows"',
- "Sec-Fetch-Dest": "empty",
- "Sec-Fetch-Mode": "cors",
- "Sec-Fetch-Site": "same-origin",
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.43",
- "X-Requested-With": "XMLHttpRequest",
- }
- params = {
- "tn": "resultjson_com",
- "logid": "11637882045647848541",
- "ipn": "rj",
- "ct": "201326592",
- "fp": "result",
- "fr": "ala",
- "word": fold_name,
- "queryWord": fold_name,
- "cl": "2",
- "lm": "-1",
- "ie": "utf-8",
- "oe": "utf-8",
- "pn": str(int(i + 1) * 30),
- "rn": "30",
- "gsm": "3c",
- }
- html = get_html(url, headers, params)
- # print(html)
- result = parse_pic_url(html)
-
- # 使用for循环遍历列表
- for item in result:
- # print(item)
- # 调用函数,获取图片的二进制源码
- pic_content = get_pic_content(item)
- # 调用函数保存图片
- save_pic(fold_name, pic_content, pic_name)
- pic_name += 1
- # print(pic_content) # 二进制源码
- print("正在保存" + str(pic_name) + " 张图片")

1、文件夹名字、抓取页数、图片名字

2、url
打开百度图片,点击检查
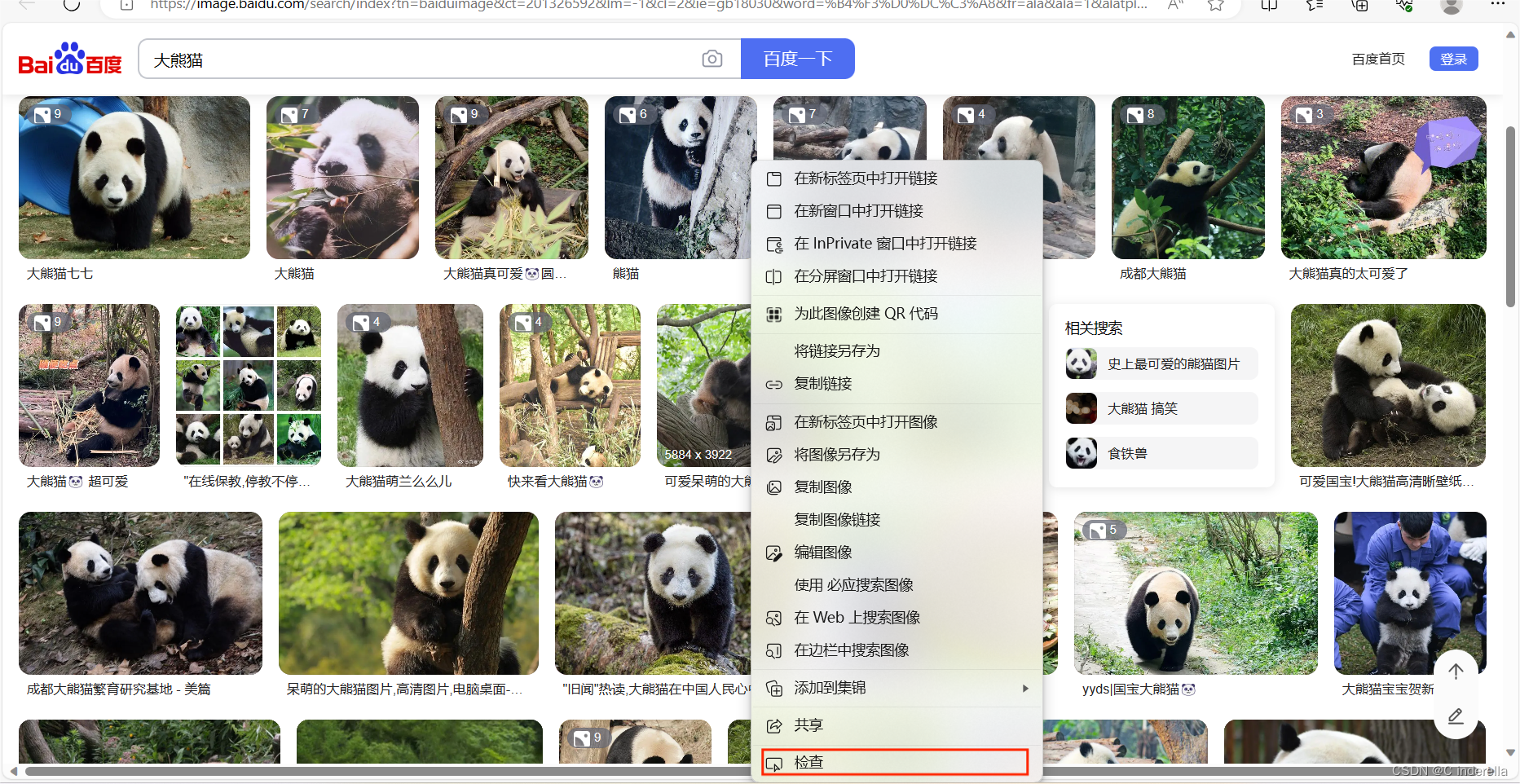
先刷新页面,再点击网络,最后点击Fetch/XHR
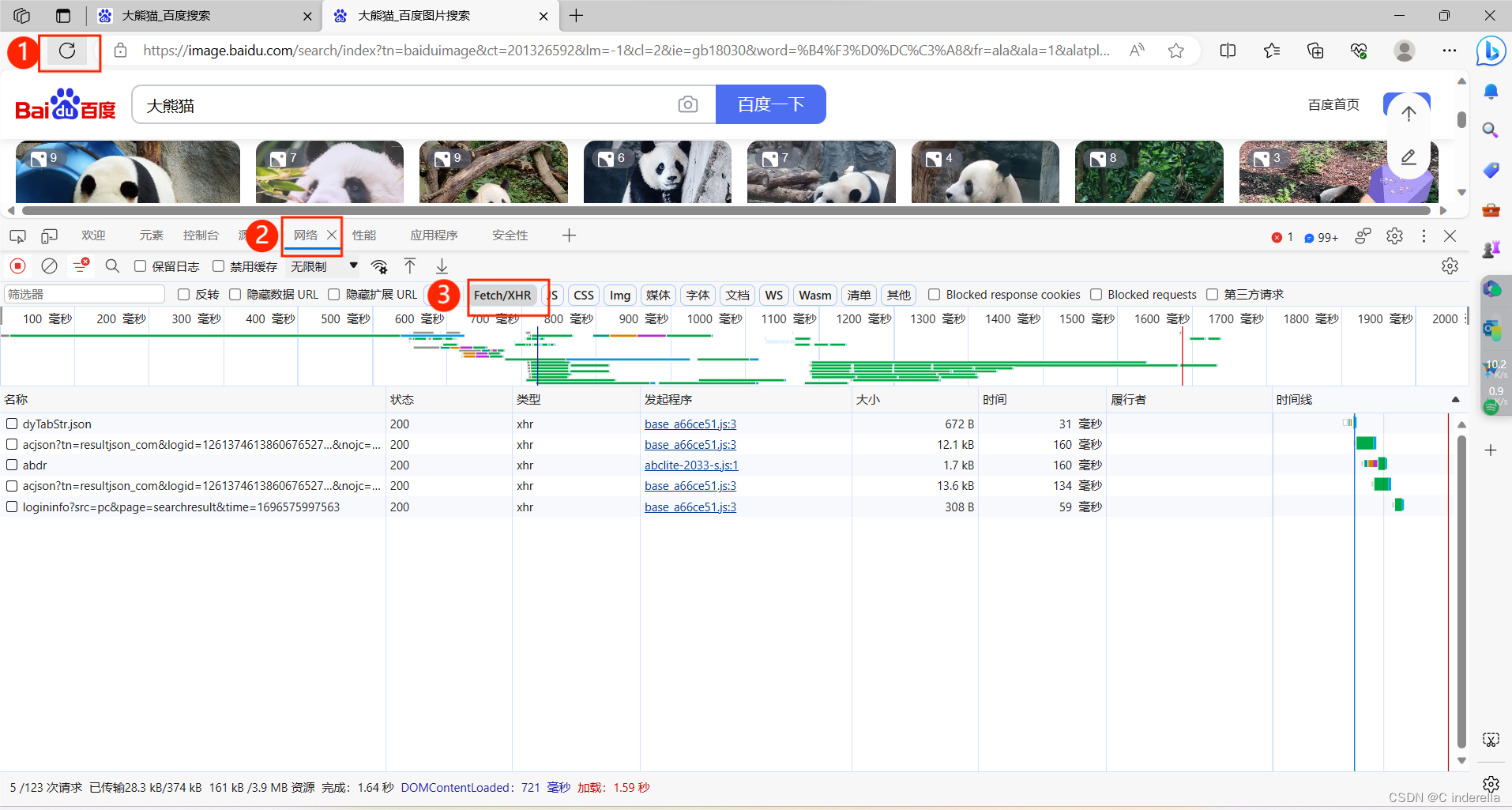
找到acjson
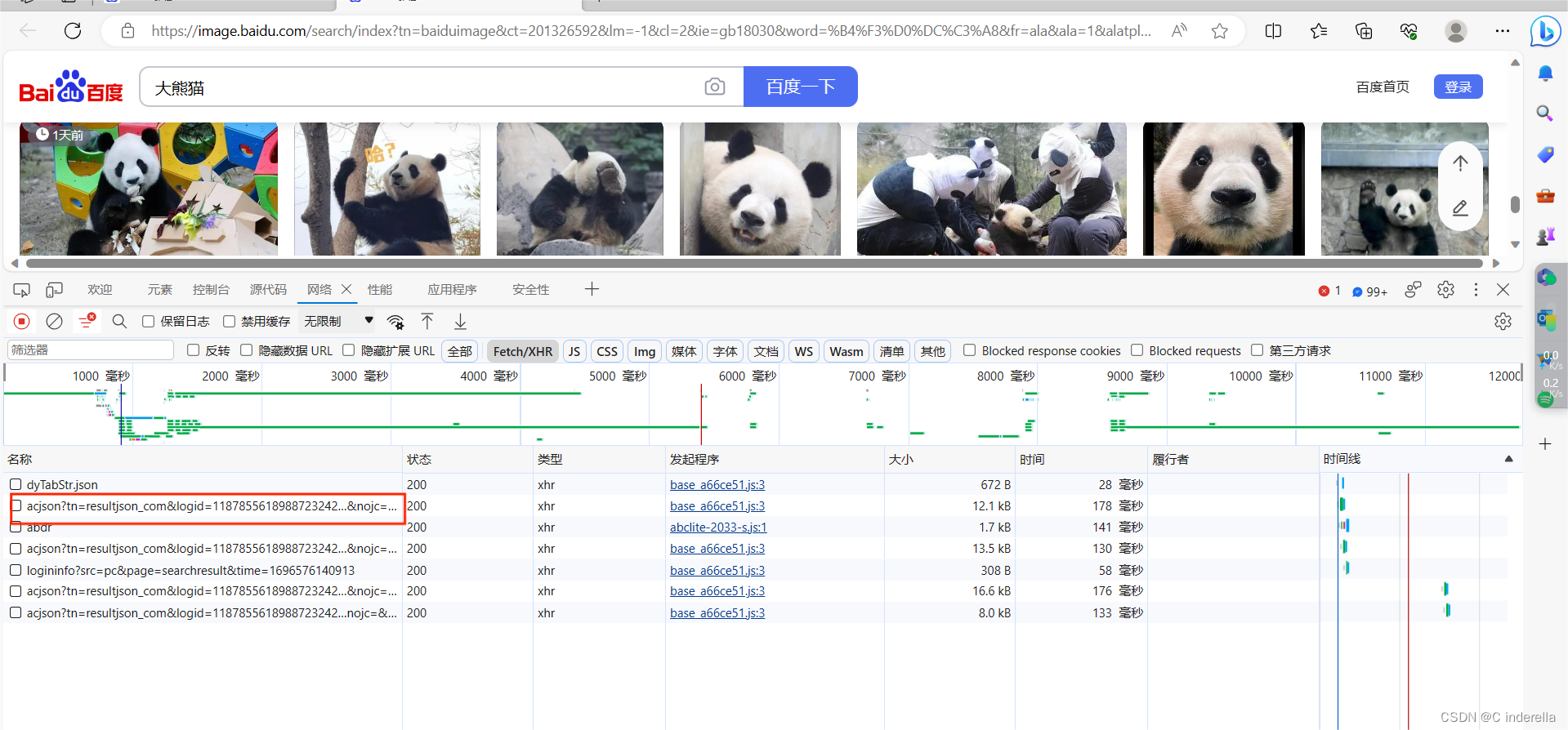
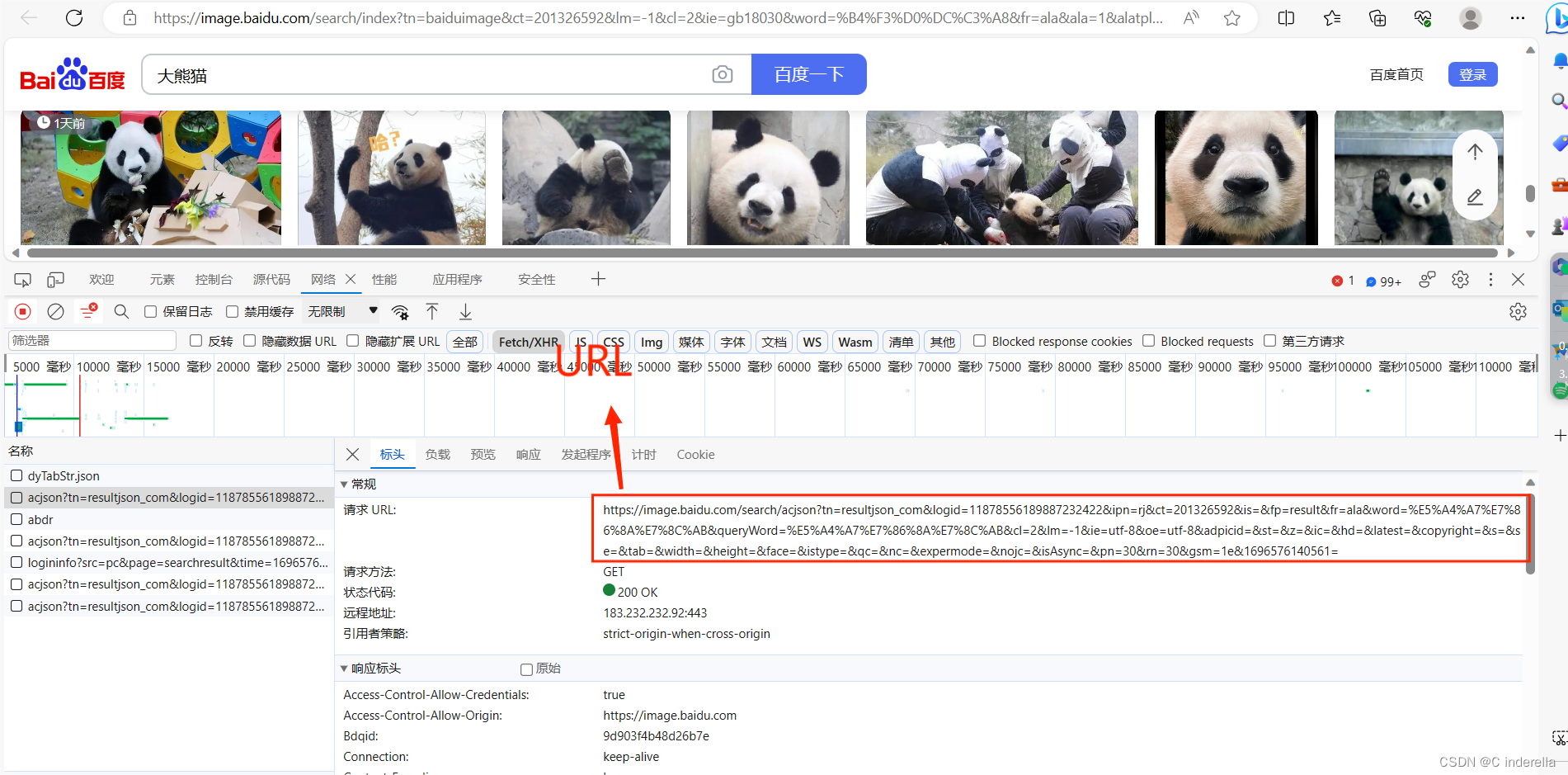
3、headers
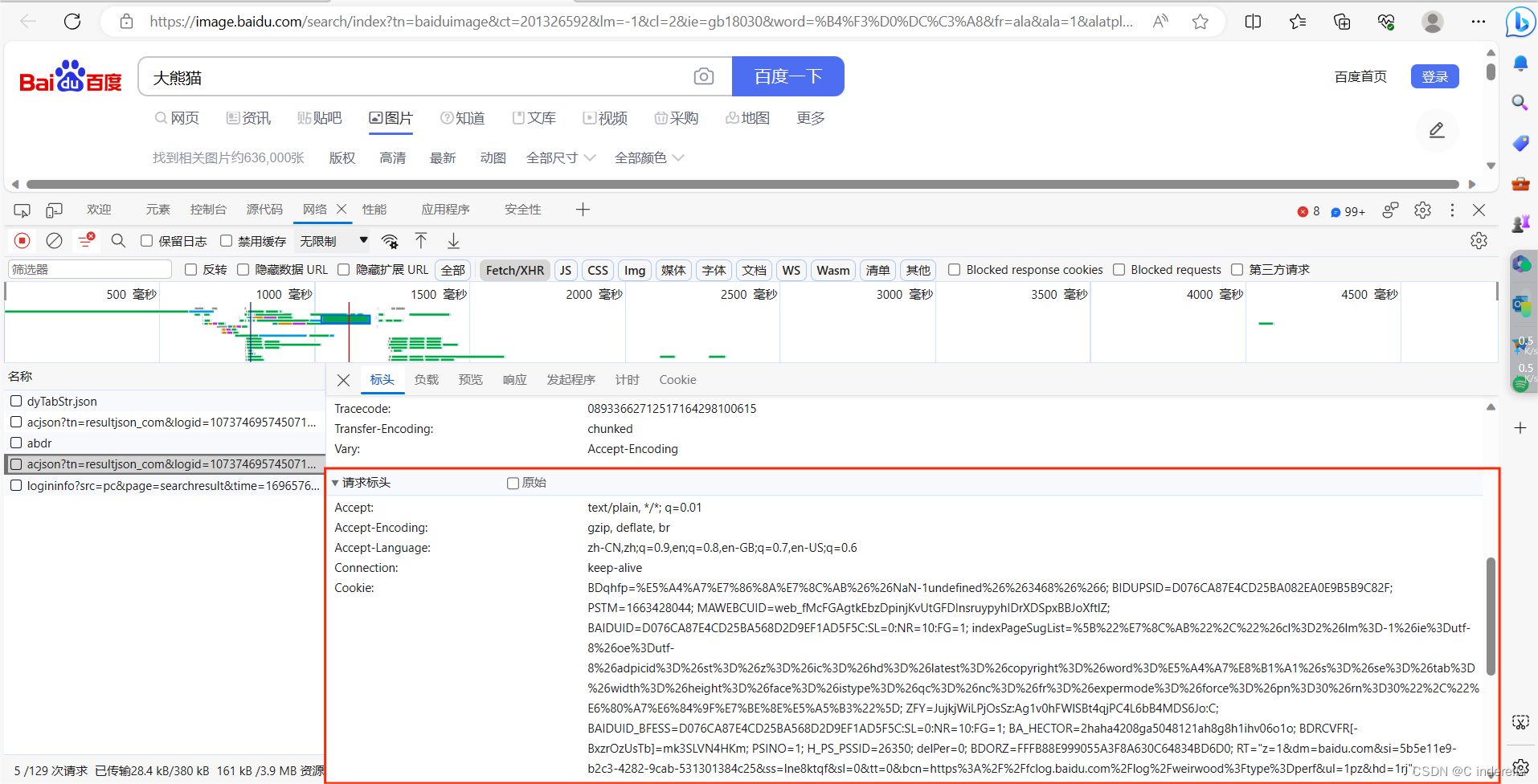
复制后像下方那样处理,":"前后的文本都要加双引号"",文本中有双引号的就加单引号''
- "Accept": "text/plain, */*; q=0.01",
- "Accept-Encoding": "gzip, deflate",
- "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
- "Connection": "keep-alive",
- "Cookie": "BDqhfp=%E5%A4%A7%E7%86%8A%E7%8C%AB%E5%9B%BE%E7%89%87%26%26NaN-1undefined%26%261632%26%263; BIDUPSID=D076CA87E4CD25BA082EA0E9B5B9C82F; PSTM=1663428044; MAWEBCUID=web_fMcFGAgtkEbzDpinjKvUtGFDInsruypyhIDrXDSpxBBJoXftlZ; BAIDUID=D076CA87E4CD25BA568D2D9EF1AD5F5C:SL=0:NR=10:FG=1; indexPageSugList=%5B%22%E7%8C%AB%22%2C%22%26cl%3D2%26lm%3D-1%26ie%3Dutf-8%26oe%3Dutf-8%26adpicid%3D%26st%3D%26z%3D%26ic%3D%26hd%3D%26latest%3D%26copyright%3D%26word%3D%E5%A4%A7%E8%B1%A1%26s%3D%26se%3D%26tab%3D%26width%3D%26height%3D%26face%3D%26istype%3D%26qc%3D%26nc%3D%26fr%3D%26expermode%3D%26force%3D%26pn%3D30%26rn%3D30%22%2C%22%E6%80%A7%E6%84%9F%E7%BE%8E%E5%A5%B3%22%5D; ZFY=JujkjWiLPjOsSz:Ag1v0hFWlSBt4qjPC4L6bB4MDS6Jo:C; BAIDUID_BFESS=D076CA87E4CD25BA568D2D9EF1AD5F5C:SL=0:NR=10:FG=1; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; userFrom=null; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; ab_sr=1.0.1_YTc4N2NiNWIyZWM5NTkzYzQ3MmZlNTI3Y2YyM2RiMTE3YmYwMTBiNzQ0YzhlZmJkZDY4YjJhZWU4NjVmMmQxZmJkYTcxODZkYTgwNjhhZDY5ZWZmYjg4Y2FmMGE5YTBmNjc3M2JhZDEwZTU1MTAyMTA1MjUxN2Y2NDNlMTJiNzhjNTIyYTQwNTg5ODNiMzc1MjRlZDdmNTVkMzdkOGJiOQ==",
- "Host": "image.baidu.com",
- "Referer": "https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gb18030&word=%B4%F3%D0%DC%C3%A8%CD%BC%C6%AC&fr=ala&ala=1&alatpl=normal&pos=0&dyTabStr=MTEsMCwxLDMsNiw1LDQsMiw3LDgsOQ%3D%3D",
- "Sec-Ch-Ua": '"Microsoft Edge";v="117", "Not;A=Brand";v="8", "Chromium";v="117"',
- "Sec-Ch-Ua-Mobile": "?0",
- "Sec-Ch-Ua-Platform": '"Windows"',
- "Sec-Fetch-Dest": "empty",
- "Sec-Fetch-Mode": "cors",
- "Sec-Fetch-Site": "same-origin",
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.43",
- "X-Requested-With": "XMLHttpRequest",
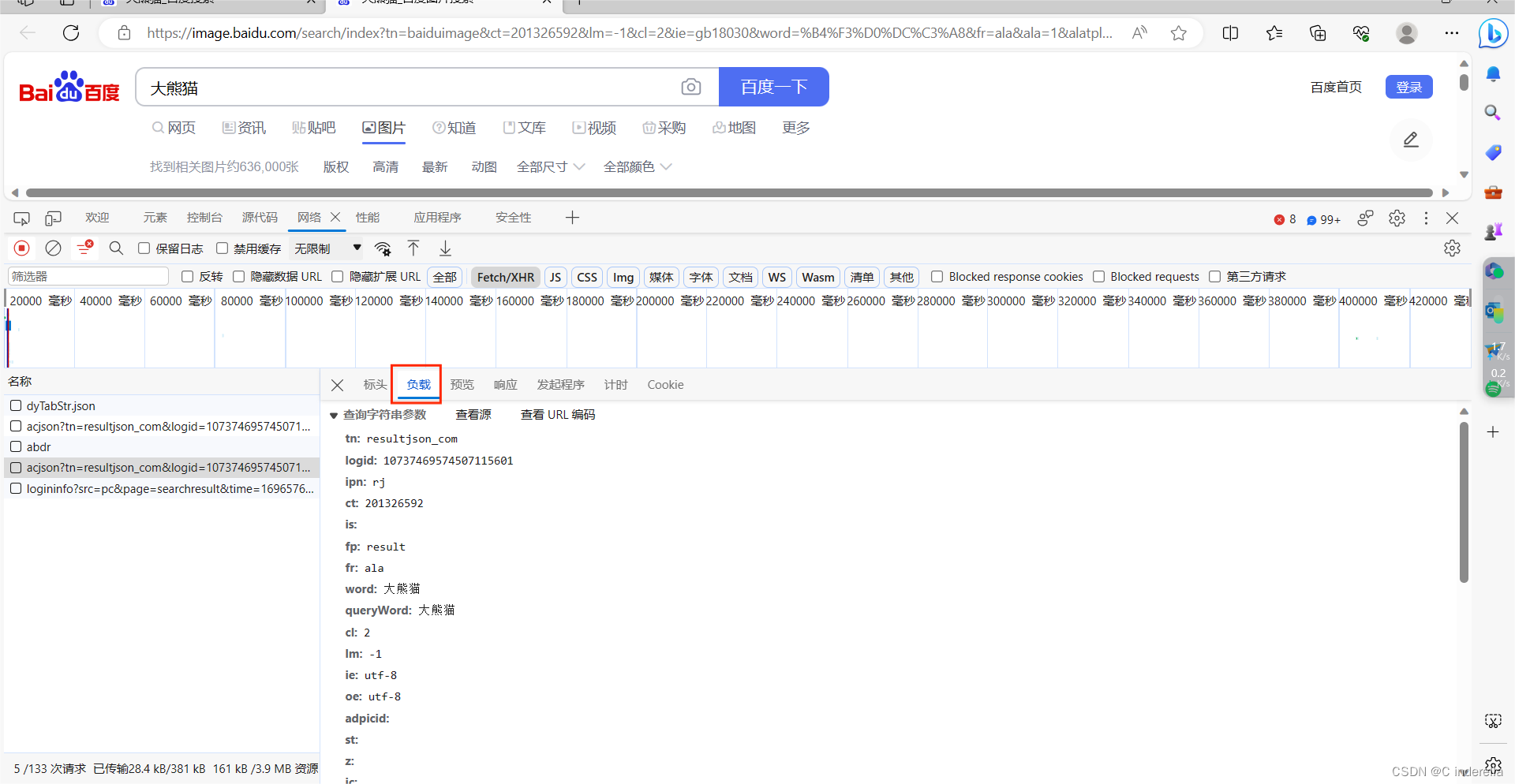
4、params
点击负载,复制所有的文本,然后在代码中删除冒号后面没有数据的行
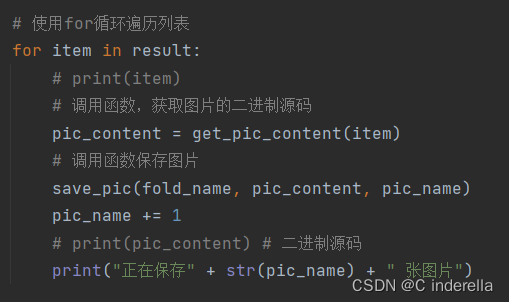
5、使用for循环遍历列表
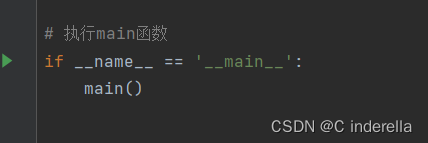
八、执行main()函数
全部代码
- # 导入相应的库
- import os
- import re
- import requests
-
-
- # 获取网站源码
- def get_html(url, headers, params):
- response = requests.get(url, headers=headers, params=params)
- # 设置源代码的编码方式
- response.encoding = "utf-8"
- # return response.text
- if response.status_code == 200:
- return response.text
- else:
- print("网站源码获取错误")
-
-
- def parse_pic_url(html):
- result = re.findall('thumbURL":"(.*?)"', html, re.S)
- return result
-
-
- # 获取图片的二进制源码
- def get_pic_content(url):
- response = requests.get(url)
- # 设置源代码的编码方式
- return response.content
-
-
- # 保存图片
- def save_pic(fold_name, content, pic_name):
- # with open("大熊猫/" + str(pic_name) + ".jpg", "wb") as f:
- with open(fold_name+"/" + str(pic_name) + ".jpg", "wb") as f:
- f.write(content)
- f.close()
-
-
- # 定义一个新建文件夹程序
- def create_fold(fold_name):
- # 加异常处理
- try:
- os.mkdir(fold_name)
- except:
- print("文件夹已存在")
-
-
- # 定义main函数调用get_html函数
- def main():
- # 输入文件夹的名字
- fold_name = input("请输入您要抓取的图片名字:")
- # 输入要抓取的图片页数
- page_num = input("请输入要抓取多少页? (0. 1. 2. 3. .....)")
- # 调用函数,创建文件夹
- create_fold(fold_name)
- # 定义图片名字
- pic_name = 0
- # 构建循环,控制页面
- for i in range(int(page_num)):
- url = "https://image.baidu.com/search/acjson?tn=resultjson_com&logid=10039095042888395480&ipn=rj&ct=201326592&is=&fp=result&fr=ala&word=%E5%A4%A7%E7%86%8A%E7%8C%AB%E5%9B%BE%E7%89%87&queryWord=%E5%A4%A7%E7%86%8A%E7%8C%AB%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&expermode=&nojc=&isAsync=&pn=60&rn=30&gsm=3c&1695863795803="
- headers = {
- "Accept": "text/plain, */*; q=0.01",
- "Accept-Encoding": "gzip, deflate",
- "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
- "Connection": "keep-alive",
- "Cookie": "BDqhfp=%E5%A4%A7%E7%86%8A%E7%8C%AB%E5%9B%BE%E7%89%87%26%26NaN-1undefined%26%261632%26%263; BIDUPSID=D076CA87E4CD25BA082EA0E9B5B9C82F; PSTM=1663428044; MAWEBCUID=web_fMcFGAgtkEbzDpinjKvUtGFDInsruypyhIDrXDSpxBBJoXftlZ; BAIDUID=D076CA87E4CD25BA568D2D9EF1AD5F5C:SL=0:NR=10:FG=1; indexPageSugList=%5B%22%E7%8C%AB%22%2C%22%26cl%3D2%26lm%3D-1%26ie%3Dutf-8%26oe%3Dutf-8%26adpicid%3D%26st%3D%26z%3D%26ic%3D%26hd%3D%26latest%3D%26copyright%3D%26word%3D%E5%A4%A7%E8%B1%A1%26s%3D%26se%3D%26tab%3D%26width%3D%26height%3D%26face%3D%26istype%3D%26qc%3D%26nc%3D%26fr%3D%26expermode%3D%26force%3D%26pn%3D30%26rn%3D30%22%2C%22%E6%80%A7%E6%84%9F%E7%BE%8E%E5%A5%B3%22%5D; ZFY=JujkjWiLPjOsSz:Ag1v0hFWlSBt4qjPC4L6bB4MDS6Jo:C; BAIDUID_BFESS=D076CA87E4CD25BA568D2D9EF1AD5F5C:SL=0:NR=10:FG=1; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; userFrom=null; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; ab_sr=1.0.1_YTc4N2NiNWIyZWM5NTkzYzQ3MmZlNTI3Y2YyM2RiMTE3YmYwMTBiNzQ0YzhlZmJkZDY4YjJhZWU4NjVmMmQxZmJkYTcxODZkYTgwNjhhZDY5ZWZmYjg4Y2FmMGE5YTBmNjc3M2JhZDEwZTU1MTAyMTA1MjUxN2Y2NDNlMTJiNzhjNTIyYTQwNTg5ODNiMzc1MjRlZDdmNTVkMzdkOGJiOQ==",
- "Host": "image.baidu.com",
- "Referer": "https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gb18030&word=%B4%F3%D0%DC%C3%A8%CD%BC%C6%AC&fr=ala&ala=1&alatpl=normal&pos=0&dyTabStr=MTEsMCwxLDMsNiw1LDQsMiw3LDgsOQ%3D%3D",
- "Sec-Ch-Ua": '"Microsoft Edge";v="117", "Not;A=Brand";v="8", "Chromium";v="117"',
- "Sec-Ch-Ua-Mobile": "?0",
- "Sec-Ch-Ua-Platform": '"Windows"',
- "Sec-Fetch-Dest": "empty",
- "Sec-Fetch-Mode": "cors",
- "Sec-Fetch-Site": "same-origin",
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.43",
- "X-Requested-With": "XMLHttpRequest",
-
-
- }
- params = {
- "tn": "resultjson_com",
- "logid": "11637882045647848541",
- "ipn": "rj",
- "ct": "201326592",
- "fp": "result",
- "fr": "ala",
- "word": fold_name,
- "queryWord": fold_name,
- "cl": "2",
- "lm": "-1",
- "ie": "utf-8",
- "oe": "utf-8",
- "pn": str(int(i + 1) * 30),
- "rn": "30",
- "gsm": "3c",
- }
- html = get_html(url, headers, params)
- # print(html)
- result = parse_pic_url(html)
-
- # 使用for循环遍历列表
- for item in result:
- # print(item)
- # 调用函数,获取图片的二进制源码
- pic_content = get_pic_content(item)
- # 调用函数保存图片
- save_pic(fold_name, pic_content, pic_name)
- pic_name += 1
- # print(pic_content) # 二进制源码
- print("正在保存" + str(pic_name) + " 张图片")
-
-
- # 执行main函数
- if __name__ == '__main__':
- main()
本文到这里就结束了,谢谢观看!
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

