
热门标签
热门文章
- 1OpenAI大模型实战:翻译应用深度探索与二次开发_开源大模型翻译功能
- 2Python实现数据分析(七)统计学基础_统计学与python实现贾俊平数据
- 3【QT】QT 概述(背景介绍、搭建开发环境、Qt Creator、程序、项目文件解析、编程注意事项)
- 4【科普】一篇搞定发paper基本概念:SCI、EI、会议/期刊、分区、CCF、DOI、IF、h-index、及cs/ee常见会议:CVPR、GlobeCOM等_globecom ccf会议级别
- 5WePY小程序框架实践指南_wepy结构及各个标签使用
- 6搭建完整的IM(即时通讯)应用(1)_im 搭建
- 7django常用命令_django指令
- 8项目 使用HBase进行NOAA OISST 海洋表面温度 数据集存储 数据可视化_js海洋温度热力图
- 9如何使用插件化apk
- 10嵌入式 H.264 BP、EP、MP、HP小结_嵌入式的ep
当前位置: article > 正文
将句子表示为向量:无监督句子表示学习(sentence embedding)
作者:天景科技苑 | 2024-07-14 20:05:54
赞
踩
将句子表示为向量:无监督句子表示学习(sentence embedding)
本文主要是用作自己学习记录笔记使用,如有侵权请联系删除即可。
原文链接:
【上篇】


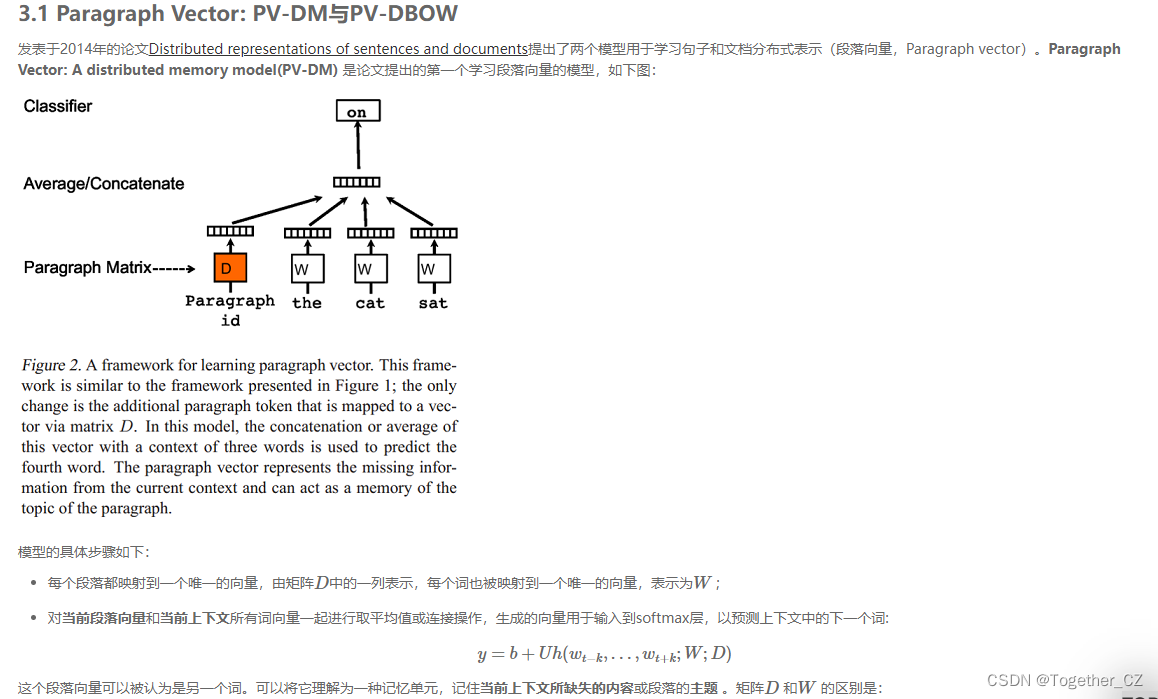
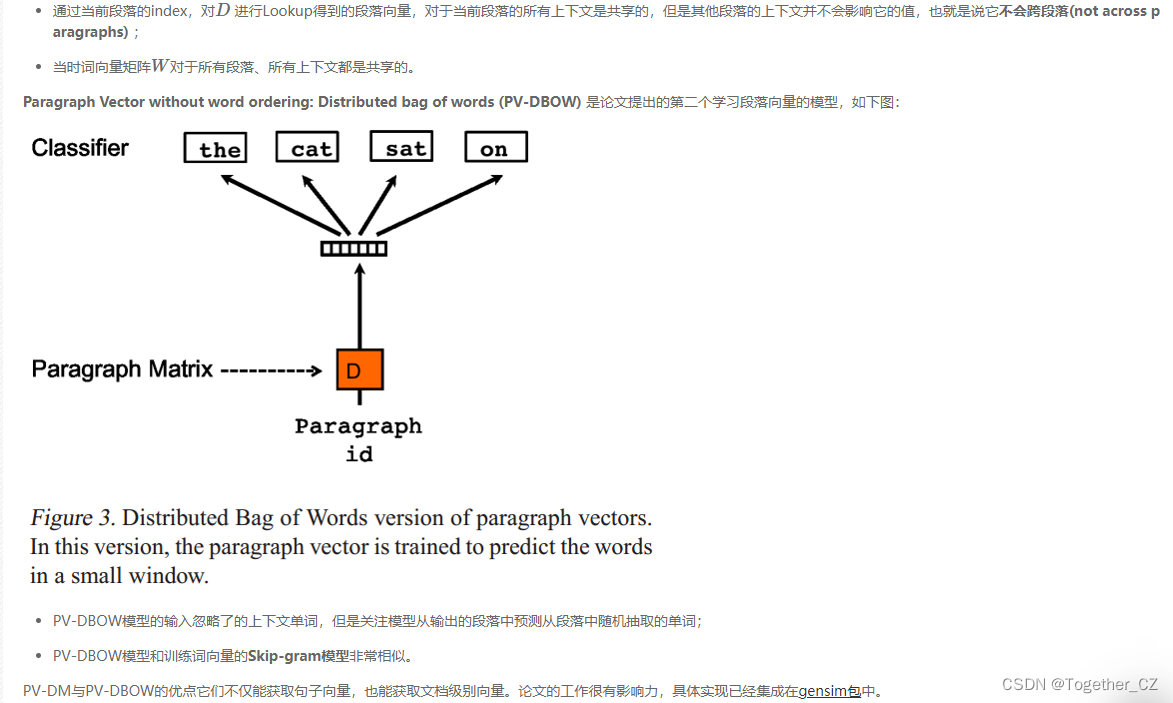





References
- Le and Mikolov - 2014 - Distributed representations of sentences and documents
- Li and Hovy - 2014 - A Model of Coherence Based on Distributed Sentence Representation
- Kiros et al. - 2015 - Skip-Thought Vectors
- Hill et al. - 2016 - Learning Distributed Representations of Sentences from Unlabelled Data
- Arora et al. - 2016 - A simple but tough-to-beat baseline for sentence embeddings
- Pagliardini et al. - 2017 - Unsupervised Learning of Sentence Embeddings using Compositional n-Gram Features
- Logeswaran et al. - 2018 - An efficient framework for learning sentence representations
【下篇】



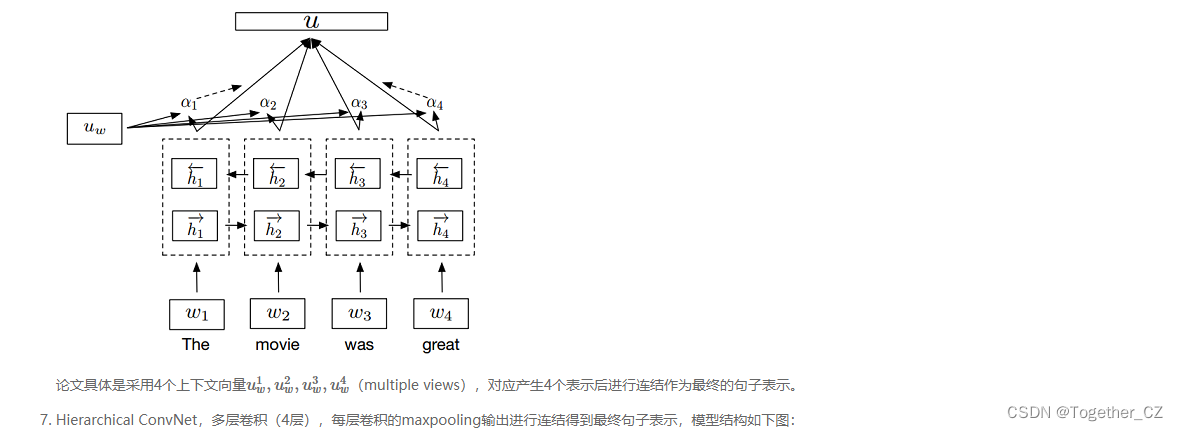
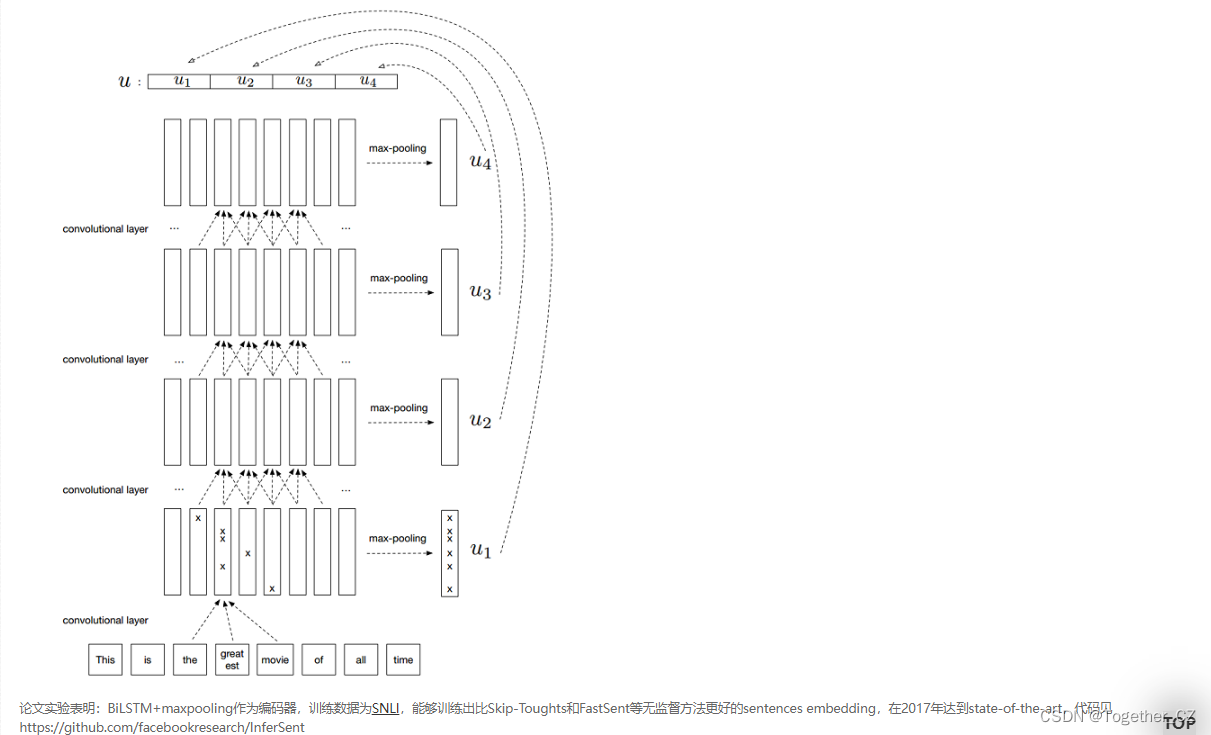
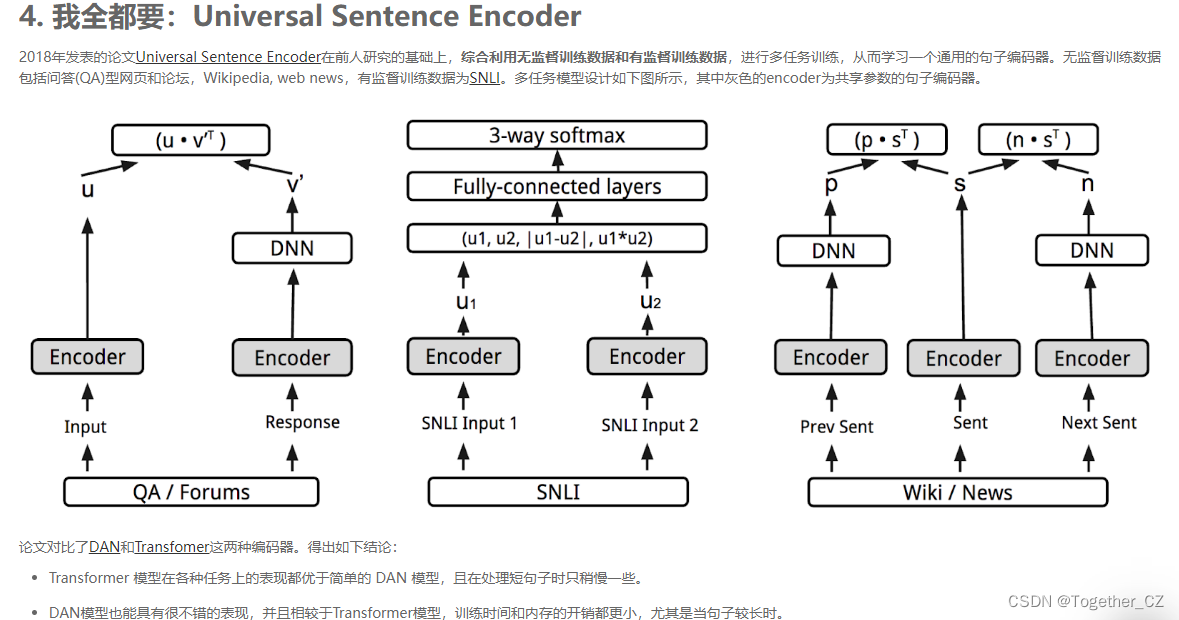
更详细的介绍可以参考论文作者的博客Google AI Blog (中文版)。
5. 总结
- 基于监督学习方法学习sentence embeddings可以归纳为两个步骤:
- 第一步选择监督训练数据,设计相应的包含句子编码器Encoder的模型框架;
- 第二步选择(设计)具体的句子编码器,包括DAN、基于LSTM、基于CNN和Transformer等。
- Sentence Embedding的质量往往由训练数据和Encoder共同决定。Encoder不一定是越复杂越好,需要依据下游任务、计算资源、时间开销等多方面因素综合考虑。
References
- Wieting et al. - 2015 - Towards universal paraphrastic sentence embeddings
- Conneau et al. - 2017 - Supervised Learning of Universal Sentence Representations from Natural Language Inference Data
- Cer et al. - 2018 - Universal Sentence Encoder
- Google AI - 2018 - Advances in Semantic Textual Similarity

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/天景科技苑/article/detail/826158
推荐阅读
相关标签

