
- 1【AI视野·今日Robot 机器人论文速览 第八十四期】Thu, 7 Mar 2024_机器人驱动与控制前沿研究论文
- 2苹果电脑如何轻松抹掉NTFS格式磁盘 如何将Mac系统下硬盘格式化为NTFS Mac硬盘格式化_mac 格式化ntfs
- 3shell脚本, flink job挂掉自动从上一个checkpoint重启_flink 从checkpoint启动脚本
- 4SQL注入攻击的原理以及如何防止SQL注入_sql注入攻击的原理是什么?
- 5预训练语言模型实践笔记
- 612. 【数据结构】 冒泡插入希尔选择堆快排归并非递归计数基数排序
- 7yolov5源码解析(10)--损失计算与anchor_yolov5损失计算
- 86软硬约束下的轨迹优化_软约束和硬约束
- 9【问题解决】org.springframework.dao.QueryTimeoutException: Redis command timed out; nested exception is io
- 10parallels试用期到了怎么办?parallels试用期到期可继续使用_parallels试用期到了继续用
思路打开!腾讯造了10亿个角色,驱动数据合成!7B模型效果打爆了
赞
踩
世界由形形色色的角色构成,每个角色都拥有独特的知识、经验、兴趣、个性和职业,他们共同制造了丰富多元的知识与文化。
所谓术业有专攻,比如AI科学家专注于构建LLMs,医务工作者们共建庞大的医学知识库,数学家们则偏爱数学公式与定理推导。
LLMs中也是如此,不同的知识是由不同的人类角色创建或者使用。因此在提示中加入角色描述如“你是一个xxx的计算机科学家”会极大提高模型响应准确度。
这一思路也可以用于构建合成数据。腾讯AI lab提出了一种新颖的(基于角色驱动的数据合成方法。即只需在数据合成提示中添加角色描述,就能引导LLM朝着相应的视角生成独特的合成数据。

由于几乎任何LLM的应用场景都可以关联到特定的人格,只要构建一个全面的角色集合,就能实现大规模的全方位合成数据生成。为此作者构建了10亿个角色,创建了Persona Hub(角色仓库),里面包含“搬家公司的司机”、“化学动力学研究员”、“对音频处理感兴趣的音乐家”等多样化的角色。并在大规模数学和逻辑推理问题生成、指令生成、知识丰富的文本生成、游戏NPC以及工具(功能)开发等场景中创建丰富且多样化的合成数据:

通过对合成数据的微调,7B的模型在某些任务上甚至与gpt-4-turbo-preview的性能相当!
论文标题:
Scaling Synthetic Data Creation with 1,000,000,000 Personas
论文链接:
https://arxiv.org/pdf/2406.20094
github链接:
https://github.com/tencent-ailab/persona-hub
构建Persona Hub
作者提出两种可扩展的方法来从海量网络数据中生成多样化的Persona Hub:Text-to-Persona(文本到角色)和Persona-to-Persona(角色到角色)。
文本到角色
具有特定专业经验和文化背景的人在阅读和写作时往往展现出独特的兴趣。
通过分析特定文本,能够推断出可能对某段文本感兴趣或创作该文本的特定人物。鉴于网络上的文本数据极为丰富且多样,因此只需简单地提示LLM,即可从海量的网络文本中提炼出广泛的人物集合。如下图所示:
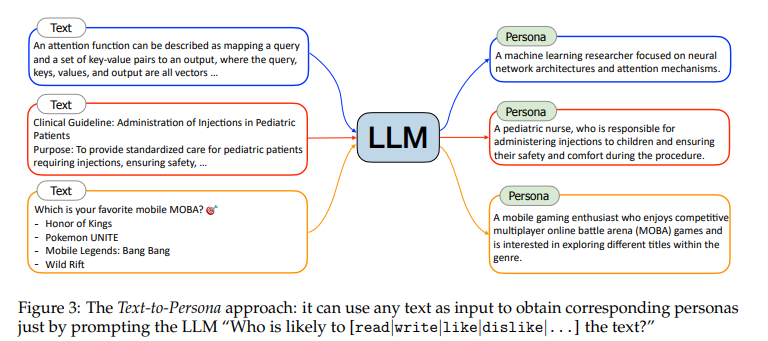
对于"attention函数描述为将查询和一组键-值对映射到输出,其中查询、键、值和输出都是向量…"这样一段文本,“一位计算机科学家”对其感兴趣的可能性较大,而更细粒度人物则可以是“专注于神经网络架构和注意力机制的机器学习研究者”。
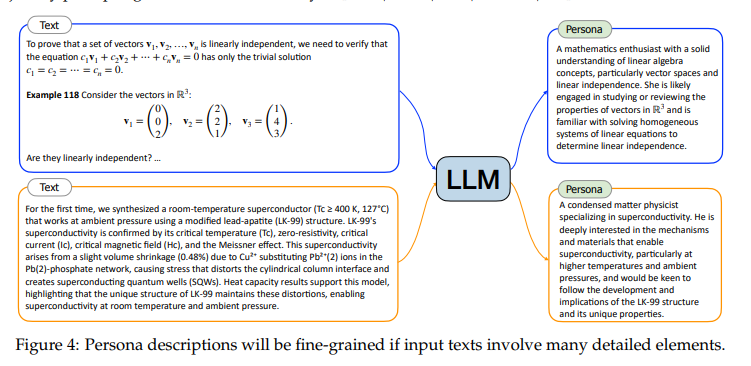
除了通过提示指定人物描述的粒度外,输入文本的内容也会直接影响人物描述的详尽程度。如下图所示,当输入文本包含丰富的细节元素,如数学教科书的内容或关于超导的深入学术论文时,生成的人物描述往往会更加具体和细致。
角色到角色
Text-to-Persona是一种高度可扩展的方法,能够生成几乎涵盖各个领域的角色。但是,对于网络上曝光较少或不易被文本分析捕获的角色,如儿童、乞丐以及电影幕后工作人员,它可能存在局限性。为了弥补这一不足,作者提出从Text-to-Persona生成的角色中衍生出更多元化的新角色。
通过提示““谁与给定的角色关系密切?””,如下图所示,“儿科护士”可能与“患病儿童”、“医药公司代表”等有联系。
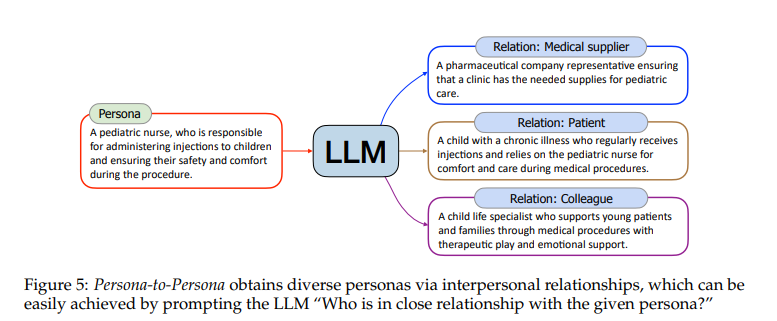
根据六度分隔理论:“你和世界上任何一个陌生人之间,最多只需要通过六个人就能建立联系”。作者对通过Text-to-Persona获取的每个角色进行六轮关系扩展,从而进一步丰富了角色库。
通过以上方式获得在获得数十亿个角色后,通过MinHash(根据角色描述的n-gram特征进行去重)与使用文本嵌入模型计算相似性两种方式去重,过滤低质量的角色描述,最后得1,015,863,523个角色。
角色驱动的数据合成
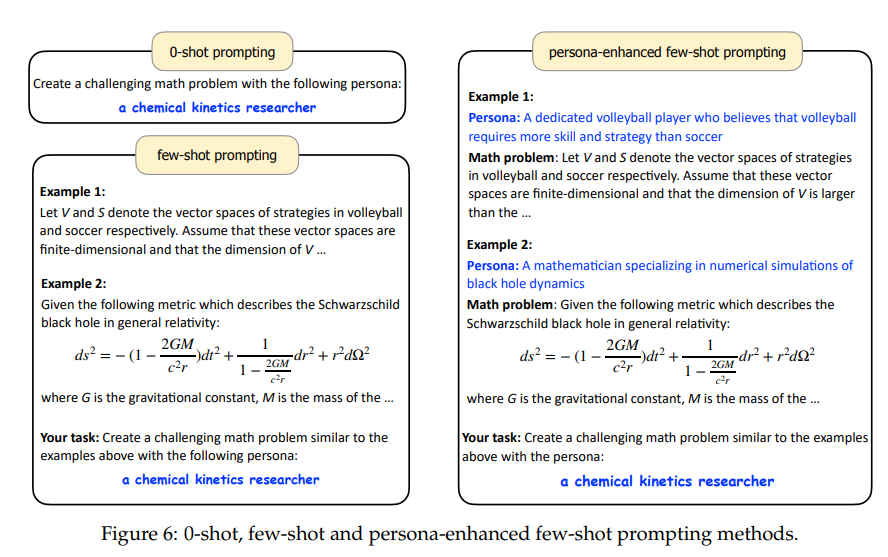
角色仓库构建完毕够,作者将人物角色融入到数据合成提示的适当位置,轻松地生成规模达亿级的多样化合成数据。为此,提出了三种角色驱动的数据合成提示方法:0-shot, few-shot and 角色增强的 few-shot提示,如下图所示:
合成数据创建示例
数学问题
数据创建
当提示LLM创建数学问题时,加入角色会让模型生成与该角色相关的问题。如下图所示:当提供语言学家的人格时,模型会生成与计算语言学相关的数学问题。

此外,添加角色并不影响提示的灵活性,仍然可以轻松地在提示中指定我们所需数学问题的焦点或难度。
数学能力评估
整个评估过程首先从Persona Hub中选取了31,090,000个角色,并借助GPT-4的0-shot提示方法,根据这些角色生成了1,090,000道全新的数学问题,全程未参考MATH等基准数据集中的实例,仅使用GPT-4为这些问题生成了答案。
测试集分为域内和域外,其中域内为从合成数据中随机抽取20,000道,域外测试集选用经典的评测集MATH。
使用剩下的1,070,000道数学问题微调Qwen2-7B,并在上述两个测试集上评估其贪心解码输出。
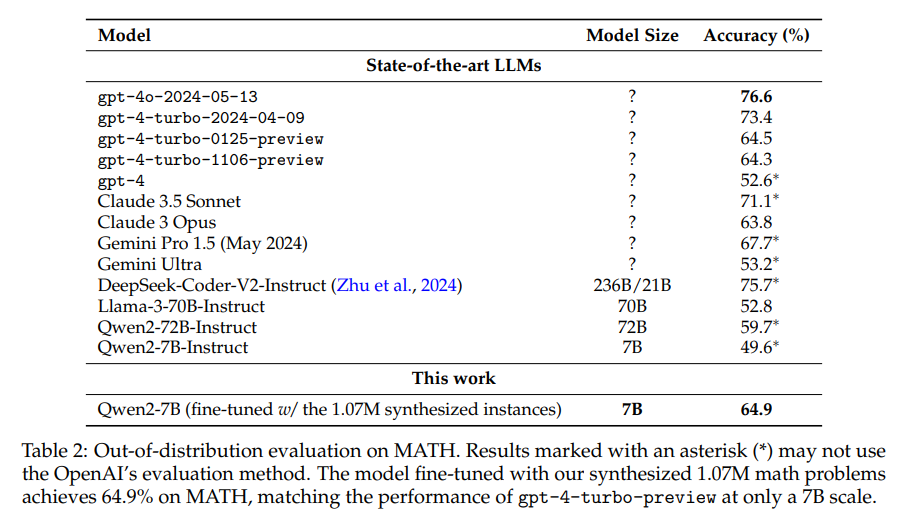
下表展示了域内评估结果。可以看到,借助107万个合成数学问题,微调模型Qwen2-7B实现了近80%的准确率,超越了所有开源大语言模型。

另外再MATH基准上进行评测发现,合成数据微调的7B模型也取得了64.9的好成绩!并超过了超越gpt-4-turbo-preview(1106/0125)的性能! 而且文本在数据合成或训练过程中并未使用MATH数据集的任何实例,显示出该方法的优越性.
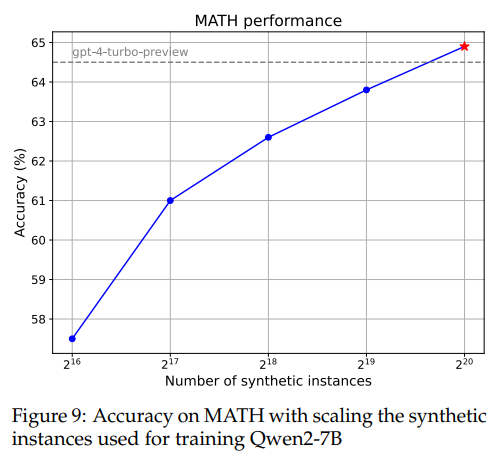
下图还展示了模型在训练不同规模合成数学问题后在MATH数据集上的性能。其性能趋势大体上与规模法则相符。
逻辑推理问题
同样基于角色驱动方法合成的典型逻辑推理问题,如下图所示:

此外,作者还展示了几个以“弱智吧”风格创建的逻辑推理问题。

所有示例都表明,只要能够清晰描述要创建的逻辑推理问题的要求,就可以使用多种角色来引导LLM生成不仅满足要求,而且与角色高度相关的多样化逻辑推理问题,连“弱智吧”风格的问题也能轻松应对。
指令生成任务
还可以利用Persona Hub模拟各种用户,理解他们对LLM的请求,从而生成多样化的指令。如下图所示。这对于提升LLM的指令遵循和对话能力非常有价值。此外甚至可以采用类似的方法,从Persona Hub中选择两个角色,让LLM扮演两个角色,模拟两个真实人之间的对话。

知识丰富文本生成
除了能够生成增强LLMs指令调优的合成指令外,也可以轻松地创建有益于预训练和后训练的丰富知识的纯文本。如下图,提示LLM使用从Persona Hub中采样的角色,撰写Quora文章。

创建游戏NPC
Persona Hub还能大量创建游戏中的NPC。将游戏的背景和世界观信息提供给LLM,LLM就能将Persona Hub中的人物(通常是现实世界中的人物)投影到游戏世界中的角色上。
比如为游戏《魔兽世界》创建游戏NPC:

《天涯明月刀》的NPC:

工具开发
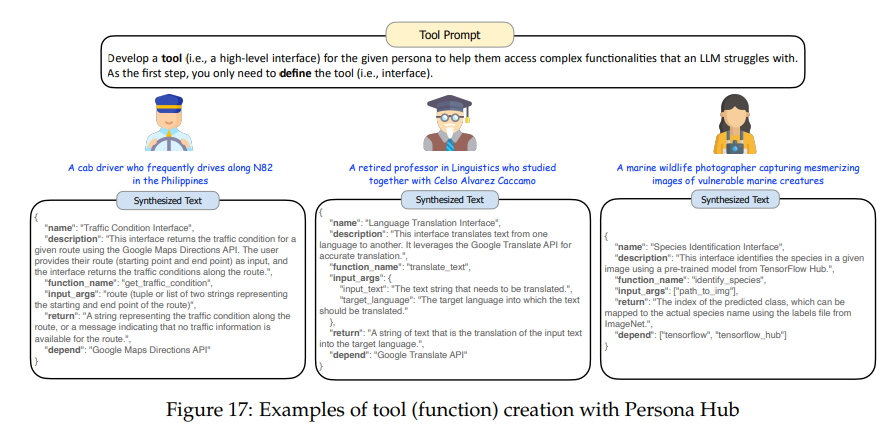
使用Persona Hub来预测用户可能需要的工具,以提前构建这些工具(功能)。当真实用户提出类似请求时,LLM可以直接调用这些预构建的工具来返回结果,而无需每次都从头开始构建工具。
如下图所示,为不同角色需要的工具定义接口,然后轻松转换为代码,(例如,出租车司机需要查看交通状况),从而极大地扩展了LLM提供的服务范围。

Persona Hub的影响与挑战
Persona Hub带来的优势
范式转变:
传统上,LLM主要用于处理数据,而数据创建主要由人类完成。引入Persona Hub后,LLM不仅可以处理数据,还可以从多种角度创建新数据。虽然LLM目前尚不能完全替代人类的数据创建任务,但其能力不断进步,未来可能完全承担数据创建任务。
现实模拟:
Persona Hub可以通过10亿个角色模拟大量现实世界个体的需求和行为。这可以帮助公司预测用户反应、政府预见公众反应,并缓解在线服务中的冷启动问题。角色中心还可以用于虚拟社会的测试,为新政策和社会动态提供无风险的实验场。
全面记忆访问:
-
Persona Hub有助于全面访问LLM的知识,通过多样化的查询生成合成数据。
-
虽然目前Persona Hub和LLM的能力有限,但随着改进,未来可能实现几乎无损地提取LLM的全面记忆。
伦理问题
训练数据的安全性:
-
Persona Hub可能会带来训练数据安全性问题,因为通过LLM合成的数据本质上是其训练数据的一种形式。
-
大规模提取LLM的记忆可能会导致其他LLM的知识、智能和能力被复制,威胁最强大LLM的主导地位。
误导信息和假新闻:
-
合成数据可能会加剧误导信息和假新闻的问题,多样化角色的写作风格增加了检测难度。
-
数据污染问题可能会扭曲研究结果和公众信息。
结论
本文提出了一种新颖的角色驱动数据合成方法,并推出了Persona Hub,一个包含10亿个角色的集合,展示了其在多种场景下促进合成数据创建的潜力,可能为发掘LLM的超级智能提供一种新途径。



