
热门标签
热门文章
- 1LeetCode 238. 除自身以外数组的乘积_leetcode 除自身以外的乘积
- 2Deep Metric Learning by Online Soft Mining and Class-Aware Attention阅读总结_class aware attention
- 3【STM32+OPENMV】二维云台颜色识别及追踪_匿名openmv色块追踪
- 4python连续动画制作_manim: 3Blue1Brown创建的基于Python的数学动画制作擎
- 5CrossOver 22版本快速在Mac和Linux上运行Windows软件_crossover for linux
- 6【前端新手小白】学习Javascript的【开源好项目】推荐
- 7【Linux】->初识Linux->Linux简单介绍_最简单的linux
- 8MacBook电脑远程连接window系统的服务器方法_mac远程windows服务器
- 9什么是FineBI?如何为FineBI配置数据源?
- 10Android自定义DataTimePicker(日期选择器_安卓日期选择器datapicker
当前位置: article > 正文
微软大模型phi-3速览-3.7B比llama-3 8B更好?_phi-3-mini rag
作者:天景科技苑 | 2024-07-19 08:18:21
赞
踩
phi-3-mini rag
背景
- 模型发布者:Microsoft
- 模型发布时间:2024年4月23日
- 发布内容:介绍了phi-3系列语言模型,包括phi-3-mini、phi-3-small和phi-3-medium。
- 重点关注:整体性能可与 Mixtral 8x7B 和 GPT-3.5 等模型相媲美,3.8B模型足够小,可以部署再手机上。小模型训练优化的重点是优质数据集,LLM 创建的合成数据可在较小的语言模型中实现通常只在较大模型中才能看到的性能。
- 技术报告信息来源:arXiv:2404.14219
技术规格
-
phi-3-mini:3.8B参数。phi-3-mini使用与Llama-2模型相似的结构和tokenizer,vocabulary大小为32064。3072的维度(hidden dimension,32heads,32layer,基于bf16训练)
-
phi-3-small:7亿参数。vocabulary为100352,context length8K,hidden dimension4096,使用GQA,4个query共享1个key。10%多语言数据。dense attention和blocksparse attention结合,来节省10%的kv cache。
-
phi-3-medium:14亿参数。40head,40layer,hidden dimension 5120。这个模型反而不是微软主推的,因为还“没找到14B下的最佳方案”。
-
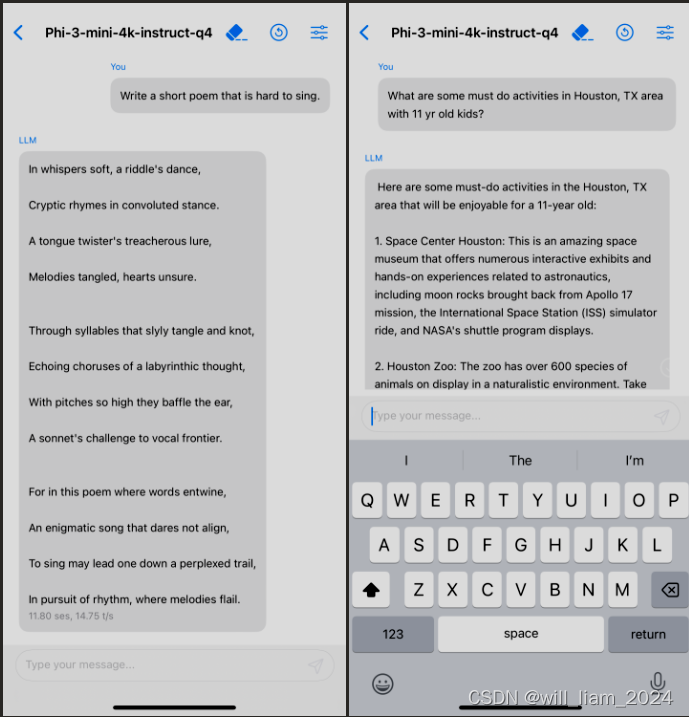
mini版本手机应用:量化成4bits的时候,占用1.8GB内存,因此可以部署到iphone 14上,在A16上运行,12tokens/s:
训练过程
训练数据
- 重点说一下训练数据
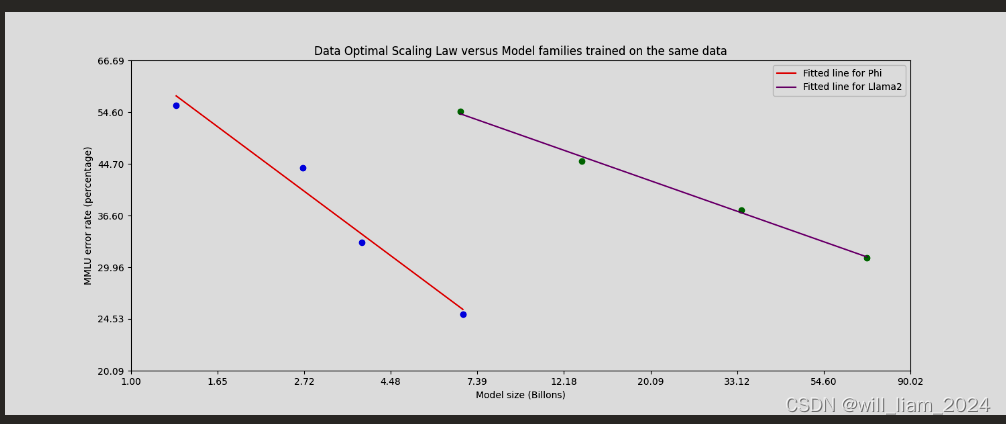
- 根据“Textbooks Are All You Need”,利用高质量的训练数据来提高小语言模型的性能,并偏离标准的缩放定律
。(也就是小模型+优质数据,达到大模型的效果) - 训练数据由来自各种开放互联网来源的经过严格过滤的网络数据(根据“教育水平”)以及合成的LLM生成的数据组成。
- pre-training分成两个阶段:1.第一阶段主要使用通用的网络数据,目的在让模型学习通用的知识和语言理解能力。2.第二个阶段用严格过滤的数据+大模型合成的数据,这些数据可以提升模型的逻辑推理能力。
数据最优机制
- 这块是说删除一些数据,使得模型的更接近最优状态。
- 这里的最优,可能是推理能力的最优,因为报告中提到一个例子,某一天英超联赛的比赛结果就被删除了,这使得模型没有记住更多的“通用知识”,但是留下了更多推理能力。
- 这里可以理解成phi-3 mini,可能更适合用于RAG等场景。
Post-training
- phi-3-mini的后期训练经历了两个阶段,包括监督微调(SFT)和直接偏好优化(DPO)。
- SFT 利用跨不同领域的精心策划的高质量数据,例如数学、编码、推理、对话、模型身份和安全性。
- DPO 数据涵盖聊天格式数据、推理、RAI 工作。我们使用 DPO 将这些输出用作“拒绝”响应,从而引导模型远离不需要的行为。除了数学、编码、推理、鲁棒性和安全性方面的改进之外,训练后还将语言模型转变为用户可以高效、安全地交互的人工智能助手。
- 长文本:上文提到,用LongRope方法提升到128K。包含在mid-training和SFT、DPO过程中。
评测指标
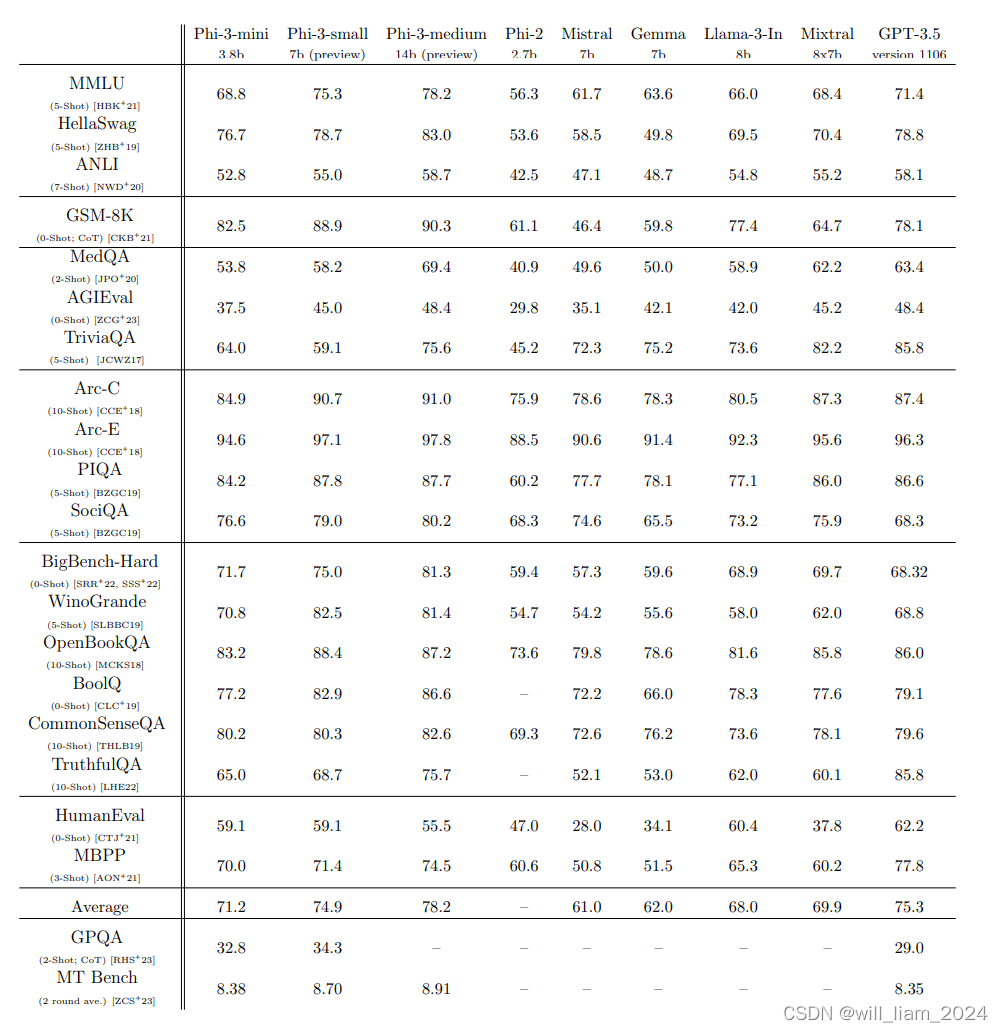
- MMLU:phi-3-mini得分68.8%,phi-3-small得分75.3%,phi-3-medium得分78.2%。
- HumanEval:phi-3-mini得分59.1%,phi-3-small得分59.1%,phi-3-medium得分55.5%。
- GSM8K:phi-3-mini得分82.5%,phi-3-small得分88.9%,phi-3-medium得分90.3%。
- 可以看到,跟前几天发布的llama-3 8b的模型不相上下,但是有一些明显低的领域,例如TriviaQA(TriviaQA 是一个现实的基于文本的问答数据集,其中包括来自维基百科和网络的 662K 文档中的 950K 问答对),这里的原因上面英超的例子有提到,为了更好的训练曲线,微软放弃了一些事实性数据。
其他特性
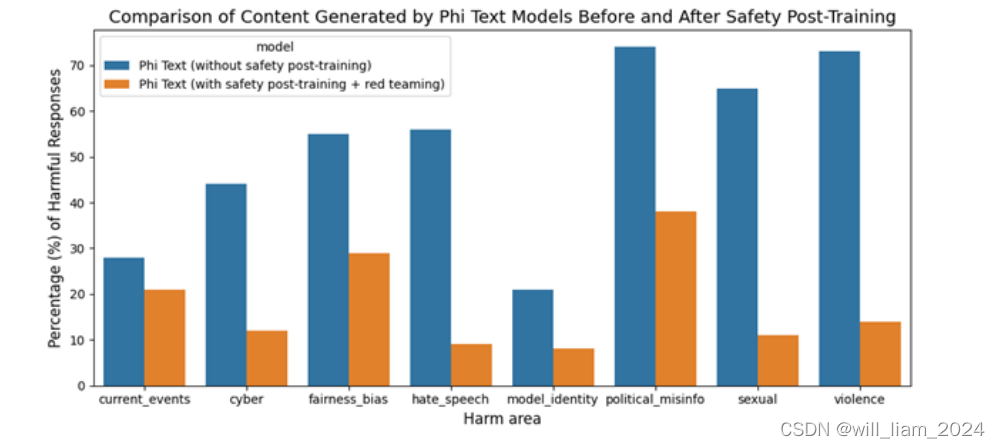
- 安全性:phi-3-mini在后训练阶段进行了安全对齐,使用了帮助性和无害性偏好数据集,并经过了红队测试。
总结
- 推理能力与事实trade-off:、虽然 phi-3-mini 模型实现了与大型模型相似的语言理解和推理能力水平,但它在某些任务中仍然受到其大小的根本限制。该模型根本没有能力存储太多的“事实知识”,例如,在 TriviaQA 上的性能较低时就可以看出这一点。
- 多语言限制:与模型容量相关的另一个弱点是,我们主要将语言限制为英语。探索小型语言模型的多语言功能是重要的下一步,通过包含更多的多语言数据,在phi-3-small上取得了一些初步的有希望的结果。
- 安全、幻觉、偏见问题待解决:尽管我们努力地进行 RAI 工作,但与大多数LLMs公司一样,在事实不准确(或幻觉)、偏见的复制或放大、不适当的内容生成和安全问题方面仍然存在挑战。使用精心策划的培训数据、有针对性的培训后以及红队见解的改进,可以在各个方面显着缓解这些问题。然而,要充分应对这些挑战,还有大量工作要做。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/天景科技苑/article/detail/850371?site
推荐阅读
相关标签

