
- 1【C语言】-- 数据结构 -- 交换排序类(冒泡排序,快速排序)(超详解+动图+源码)_冒泡排序,优化,逆序,记录发生交换的位置完整c语言代码
- 2Linux云计算之网络基础5——路由及路由配置_思科配置路由器
- 3聚类篇——(三)K-Medoids聚类
- 4基于深度学习网络的5G通信链路信道估计算法matlab仿真_神经网络优化算法5g移动通信功率放大器
- 5小白的最强保姆教学:PicGo + gitee +Typora免费搭建个人图床工具(优秀博文转载)
- 62021EI国际学术会议教给论文投稿小白们去投哪些靠谱的国际学术会议_ei会议poster
- 7Linux 服务器安全技巧_加强 linux 服务器安全的七个步骤
- 8MySQL8.0以上版本(解压版)安装教程_mysql 8.0 解压版
- 9云计算大数据基础知识点_云计算与大数据导论的相关基础知识
- 10安信可Combo固件常见应用示例集合,适用RTL8720系列 / Ai-WB2系列模组_安信可wb2 01s调试
Drone-YOLO_sandwich-fusion(sf)
赞
踩
这是一种有效的无人机图像目标检测, 无人机图像中的目标检测是各个研究领域的重要基础。然而,无人机图像带来了独特的挑战,包括图像尺寸大、检测对象尺寸小、分布密集、实例重叠和照明不足,这些都会影响对象检测的有效性。
这是一系列基于YOLOv8模型的多尺度无人机图像目标检测算法,旨在克服与无人机图像目标检测相关的特定挑战。为了解决大场景大小和小检测对象的问题,我们对YOLOv8模型的颈部组件进行了改进。具体而言,我们采用了三层PAFPN结构,并结合了一个使用大规模特征图为小型目标量身定制的检测头,显著增强了算法检测小型目标的能力。此外,我们将夹层融合模块集成到颈部上下分支的每一层中。这种融合机制将网络特征与低级特征相结合,提供了关于不同层检测头处物体的丰富空间信息。我们使用深度可分离进化来实现这种融合,它平衡了参数成本和大的感受野。在网络主干中,我们使用RepVGG模块作为下采样层,增强了网络学习多尺度特征的能力,并优于传统的卷积层。
所提出的Drone-YOLO方法已在消融实验中进行了评估,并在VisDrone2019数据集上与其他最先进的方法进行了比较。结果表明,我们的Drone-YOLO(L)在目标检测的准确性方面优于其他基线方法。与YOLOv8相比,我们的方法在mAP0.5指标上实现了显著改进,VisDrone2019测试增加了13.4%,VisDrone 2019-val.增加了17.40%。此外,只有5.25M参数的参数高效Drone-YOLO(tiny)在数据集上的性能与9.66M参数的基线方法相当或更好。这些实验验证了Drone-YOLO方法在无人机图像中目标检测任务中的有效性。
在过去的15年里,随着无人机控制技术的逐渐成熟,无人机遥感图像以其成本效益和易获取性成为低空遥感研究领域的重要数据源。在此期间,深度神经网络方法得到了广泛的研究,并逐渐成为图像分类、目标检测和图像分割等任务的最佳方法。然而,目前应用的大多数深度神经网络模型,如VGG、RESNET、U-NET、PSPNET,主要是使用手动收集的图像数据集开发和验证的,如VOC2007、VOC2012、MS-COCO,如下图所示。 与人工拍摄的真是图像相比,从无人机获得的图像显示出显著差异。这些无人机拍摄的图像如下:
与人工拍摄的真是图像相比,从无人机获得的图像显示出显著差异。这些无人机拍摄的图像如下: 除了这些图像数据特征外,无人机遥感目标检测方法还有两种常见的应用场景。第一个涉及使用大型台式计算机进行飞行后数据处理。无人机飞行后,捕获的数据在台式计算机上进行处理。第二个涉及飞行过程中的实时处理,无人机上的嵌入式计算机实时同步处理航空图像数据。该应用程序通常用于无人机飞行期间的避障和自动任务规划。因此,应用神经网络的目标检测方法需要满足每个场景的不同要求。对于适用于台式计算机环境的方法,需要高检测精度。对于适用于嵌入式环境的方法,模型参数需要在一定范围内才能满足嵌入式硬件的操作要求。在满足操作条件后,该方法的检测精度也需要尽可能高。
除了这些图像数据特征外,无人机遥感目标检测方法还有两种常见的应用场景。第一个涉及使用大型台式计算机进行飞行后数据处理。无人机飞行后,捕获的数据在台式计算机上进行处理。第二个涉及飞行过程中的实时处理,无人机上的嵌入式计算机实时同步处理航空图像数据。该应用程序通常用于无人机飞行期间的避障和自动任务规划。因此,应用神经网络的目标检测方法需要满足每个场景的不同要求。对于适用于台式计算机环境的方法,需要高检测精度。对于适用于嵌入式环境的方法,模型参数需要在一定范围内才能满足嵌入式硬件的操作要求。在满足操作条件后,该方法的检测精度也需要尽可能高。
因此,无人机遥感图像中目标检测的神经网络方法需要能够适应这些数据的特定特征。它们的设计应满足飞行后数据处理的要求,可以提供高精度和召回率的结果,或者它们应设计为具有较小规模参数的模型,可以部署在嵌入式硬件环境中,用于无人机上的实时处理。
下图显示了我们提出的Drone-YOLO(L)网络模型的架构。该网络结构是对YOLOv8-l模型的改进。在网络的主干部分,我们使用RepVGG结构的重新参数化卷积模块作为下采样层。在训练过程中,这种卷积结构同时训练3×3和1×1卷积。在推理过程中,两个卷积核被合并为一个3×3卷积层。这种机制使网络能够在不影响推理速度或扩大模型大小的情况下学习更稳健的特征。在颈部,我们将PAFPN结构扩展到三层,并附加了一个小尺寸的物体检测头。通过结合所提出的三明治融合模块,从网络主干的三个不同层特征图中提取空间和信道特征。这种优化增强了多尺度检测头收集待检测对象的空间定位信息的能力。 如下图所示,我们提出了sandwich-fusion(SF),这是一种三尺寸特征图的新融合模块,它优化了目标的空间和语义信息,用于检测头。该模块应用于颈部自上而下的层。该模块的灵感来自YOLOv6 3.0【YOLOv6 v3.0: A Full-Scale Reloading】中提出的BiC模型。SF的输入如图所示,包括主干较低阶段、相应阶段和较高阶段的特征图。目标是平衡低级特征的空间信息和高级特征的语义信息,以优化网络头部对目标位置的识别和分类。
如下图所示,我们提出了sandwich-fusion(SF),这是一种三尺寸特征图的新融合模块,它优化了目标的空间和语义信息,用于检测头。该模块应用于颈部自上而下的层。该模块的灵感来自YOLOv6 3.0【YOLOv6 v3.0: A Full-Scale Reloading】中提出的BiC模型。SF的输入如图所示,包括主干较低阶段、相应阶段和较高阶段的特征图。目标是平衡低级特征的空间信息和高级特征的语义信息,以优化网络头部对目标位置的识别和分类。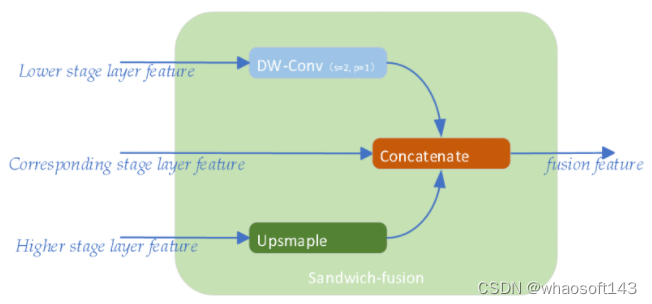
项目中,我们使用Ubuntu 20.04作为操作系统,Python 3.8、PyTorch 1.16.0和Cuda 11.6作为软件环境。实验采用NVIDIA 3080ti图形卡作为硬件。神经网络的实现代码是在Ultralytics 8.0.105版本的基础上修改的。在项目中的训练、测试和验证过程中使用的超参数保持一致。训练epoch被设置为300,并且输入到网络中的图像被重新缩放到640×640。在下面列出的一些结果中,所有YOLOv8和我们提出的Drone-YOLO网络都具有来自我们检测结果。在这些落地中,这些网络都没有使用预训练参数。whaosoft aiot http://143ai.com
在嵌入式应用实验中,我们使用NVIDIA Tegra TX2作为实验环境,该环境具有256核NVIDIA Pascal架构GPU,提供1.33 TFLOPS的峰值计算性能和8GB的内存。软件环境为Ubuntu 18.04 LTS操作系统、NVIDIA JetPack 4.4.1、CUDA 10.2和cuDNN 8.0.0。
在VisDrone2019-test测试效果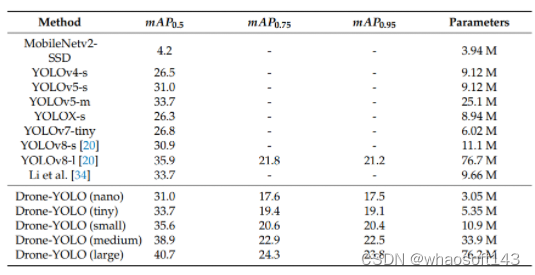
基于NVIDIA Tegra TX2的结果 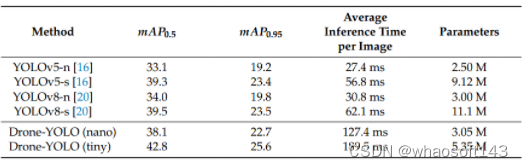
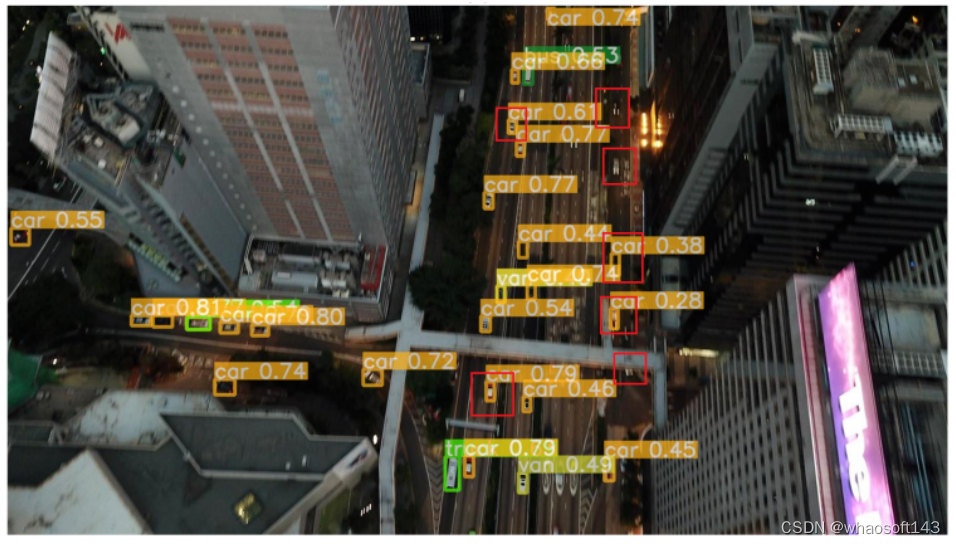 Drone-YOLO实际效果
Drone-YOLO实际效果

左边是Yolov8的结果,可以看出红色框中大部分目标没有检测出来



