
- 1自动化办公:openpyxl操作Excel的7个示例_openpyxl应用实例
- 2算法沉淀——动态规划之回文串问题(上)(leetcode真题剖析)_回文串相关算法题
- 3<Rust><GUI>rust语言GUI库tauri体验:前、后端结合创建一个窗口并修改其样式
- 4用 ONLYOFFICE 宏帮你自动执行任务:介绍与教程_onlyoffice宏
- 5Spring源码编译常见问题解决方案_gradle-7.5.1-bin
- 6U盘或者移动硬盘弹出时出现弹窗的解决方法_移动硬盘怎么解除占用并安全弹出
- 7初次使用 uni.chooseLocation 方法时可能会出现延迟或无效果的情况
- 8Mac M1 Pycharm的安装及使用_pycharm mac m1
- 9LittleVGL_lvgl 设计器
- 10Java小抄(二)|Java中字符串占位符替换的多种实现方法_java 字符串占位符替换
橙芯创想:香橙派AIPRO解锁升腾LLM与Stable Diffusion的创意密码
赞
踩
引言
在科技的浪潮中,一场融合智慧与创意的盛会正在启幕,《香橙派AIPRO解锁升腾LLM与Stable Diffusion的创意密码》引领你步入一个全新的维度。握住香橙派AI Pro开发板,如同掌握了一把通往未来的钥匙,不仅驾驭着ChatCLM模型,更将Stable Diffusion的力量纳入掌中,从零开始编织属于自己的智能织锦。
一. 香橙派AI PRO配置以及展示

优秀的扩展能力
香橙派AI Pro,作为一款高性能的边缘计算平台,展现出非凡的扩展能力。它配备了丰富的I/O接口,包括但不限于USB、HDMI、网络接口以及GPIO端口,支持多种传感器、显示器和外部存储设备的直接连接。这种高度的兼容性和灵活性,使得开发者能够根据项目需求轻松扩展硬件配置,无论是构建复杂的机器人系统、智能物联网网关,还是高性能的边缘计算服务器,香橙派AI Pro都能提供坚实的技术支撑。

实物展示


二、Ascend-LLM模型部署
开机
香橙派AI Pro内置镜像,如果没有对高版本镜像的需求可以即插即用。
需要显示器、键盘、鼠标各一份。
默认壁纸还是非常漂亮的。默认密码:Mind@123

xshell连接香橙派
连接网络之后通过ifconfig查看ip地址。

通过ip+账号即可通过shell工具实现远程连接。我们选择xshell作为shell工具。
实战运行部署
我们选择南京大学开源的一套基于香橙派 AIpro部署的Tiny-Llama语言模型。充分释放性能。
gitee地址:[ChatGLM3 ManualReset: chatglm3基于香橙派AIPro部署 (gitee.com)](https://gitee.com/wan-zutao/chatglm3-manual-reset)

本地通过网络下载zip包通过xshell导入香橙派即可。
unzip 命令可以解压文件夹。
后面发现镜像自带git,无需下载,直使用git命名下载。
git clone https://gitee.com/wan-zutao/chatglm3-manual-reset.git

cd inference进入inference目录
bash downlado.sh 下载模型,大概11GB,网速快的几分钟即可。


python3 main.py 启动程序

从打印日志找到访问的url

可以非常愉快的和 Ascend-llm交互了。


通过top命名查看系统情况
- CPU使用率:当前为29.1%,4.1%用于用户空间进程,4.1%用于内核空间,64.1%处于空闲状态。
- 内存使用情况:总物理内存大小是7543.6 MiB,已用5287.6 MiB,剩余1586.9 MiB可用,交换内存总量为2048.0 MiB,已使用163.2 MiB,剩余1884.8 MiB未被使用。

运行结果分析
Ascend-LLM
部署过程中,香橙派AIPRO的兼容性和易用性得到了充分验证,使得模型能够迅速在边缘设备上实现落地。得益于其内置的NPU加速单元,Ascend-LLM的运行效率得到了显著提升,即使在资源受限的环境中也能保持高效的推理速度。
模型运行效率
得益于内置的NPU加速单元,Ascend-LLM模型在香橙派AI Pro上的运行效率显著提升,即使在资源受限的边缘设备上,也能保持高效的推理速度。
资源消耗
通过top命令监控系统状态,显示CPU使用率为29.1%,其中4.1%用于用户空间进程,4.1%用于内核空间,而64.1%处于空闲状态。内存方面,总物理内存为7543.6MiB,已用5287.6MiB,剩余1586.9MiB可用,交换内存总量为2048.0MiB,已使用163.2MiB,剩余1884.8MiB未被使用。
开发版表现
负载管理
香橙派AI Pro在处理模型时,尽管CPU和内存有一定的使用率,但整体仍有较大的余量,表明其具备良好的资源管理能力,能够在运行复杂模型的同时保持系统的稳定运行。
散热性能
在启动初期,大约10秒钟会有轻微的噪音,这是预热阶段正常现象。之后,开发板运行时几乎无声,风扇运行平稳,没有明显的噪音波动。长时间使用后,散热片温度适中,证明散热设计有效,有助于维持设备长期稳定运行。
三、Stable Diffusion
另外使用香橙派AIPRO部署了Stable Diffusion,来看看算力表现如何。
文生图
文生图是指通过输入文本描述,让Stable Diffusion模型生成与之匹配的图像。这个过程涉及到模型的推理和图像的生成。用户可以通过在工作区输入文本,然后在调参区调整参数,来生成符合自己需求的图像。
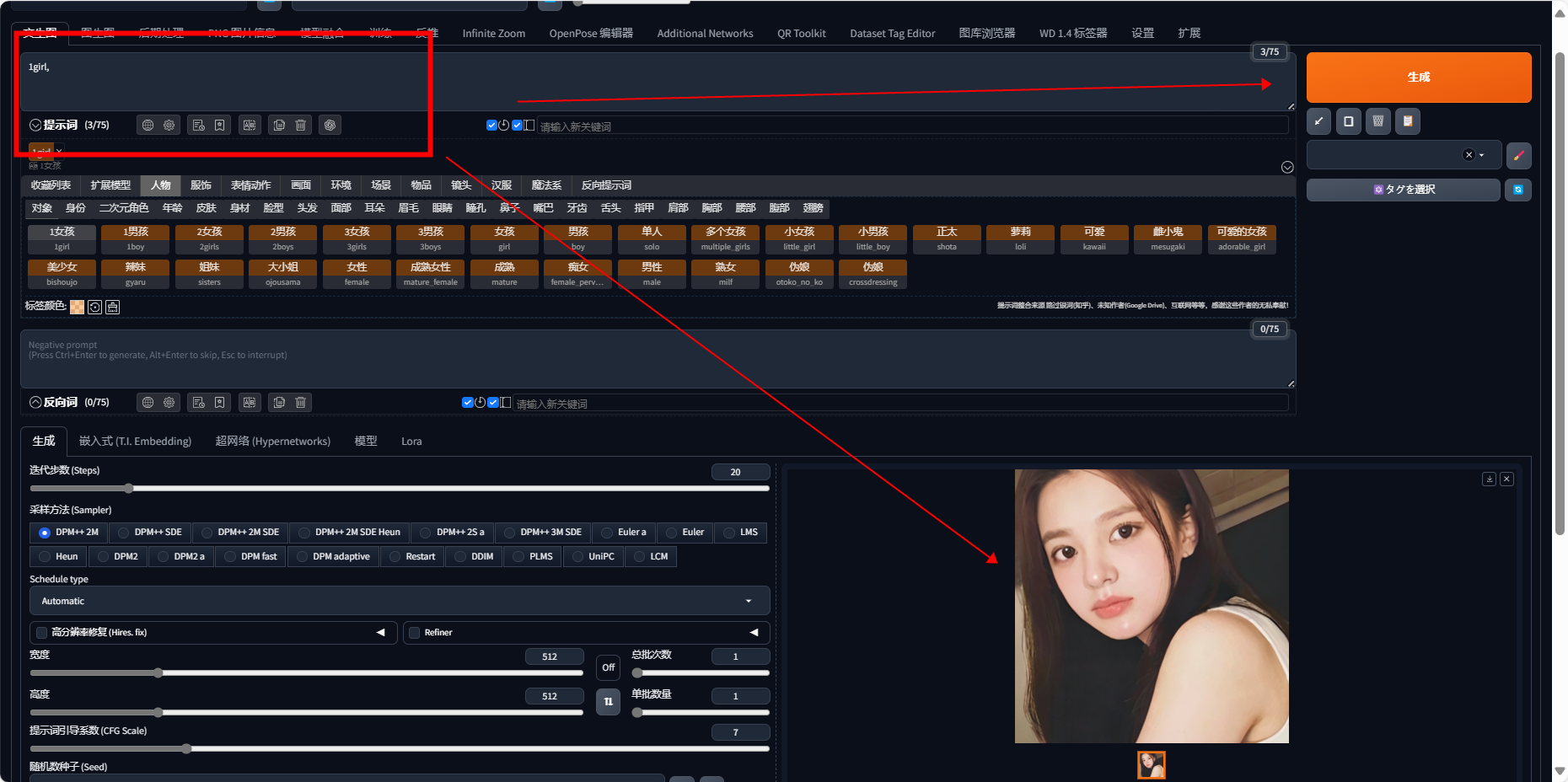
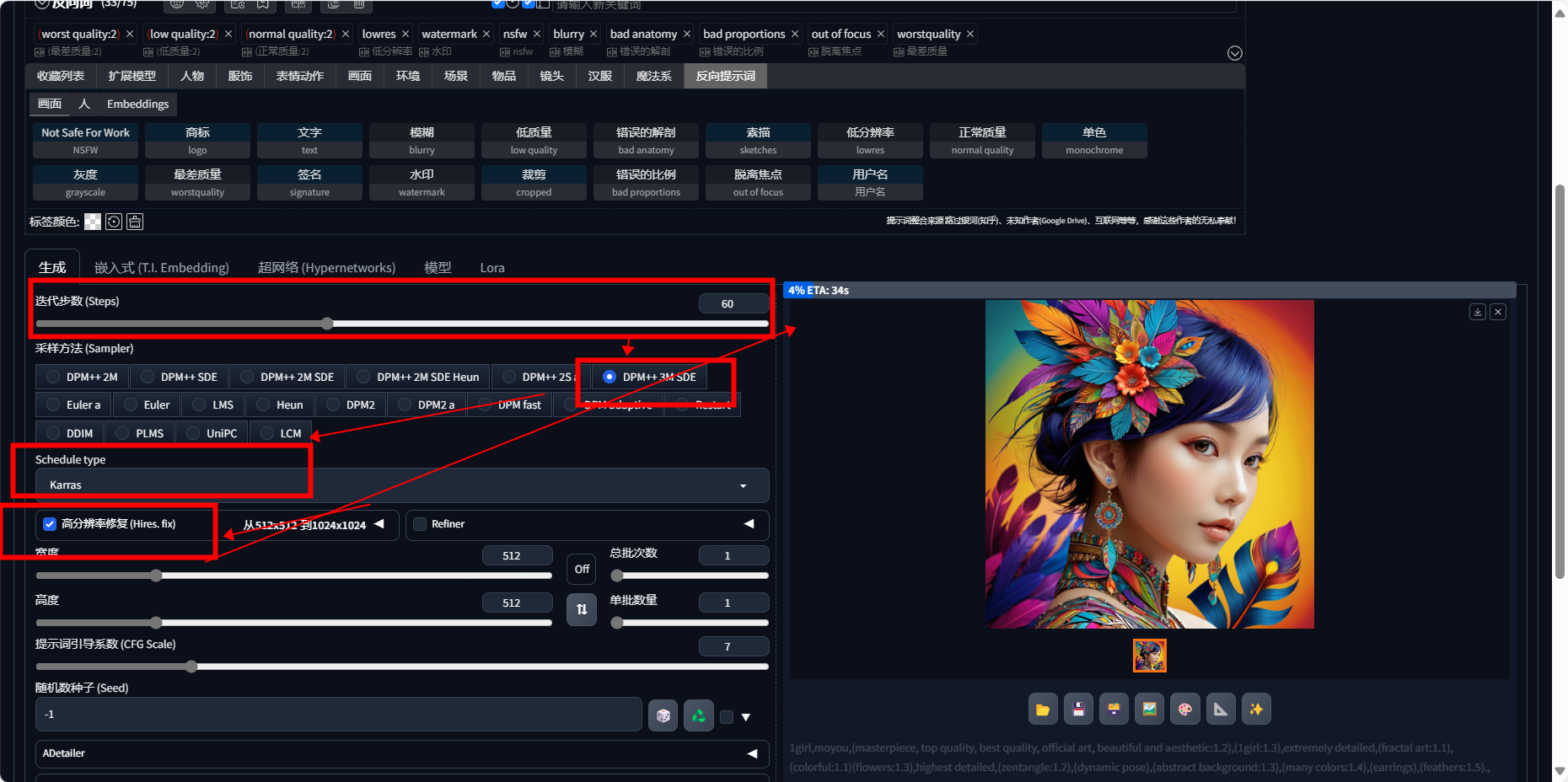
性能表现
Stable Diffusion
对于Stable Diffusion这样的模型,通常在GPU或专用AI加速器上运行,其处理时间可以从几秒到几十秒不等,具体取决于上述因素。由于Stable Diffusion模型较为复杂,即使在高端GPU上,生成一张图像也可能需要几秒到十几秒的时间。但是,由于香橙派AI Pro的AI算力达到了20TOPS,它能够较快地处理此类任务。香橙派AI Pro的AI核心可以加速深度学习任务,但在处理复杂模型时可能不会像高端GPU那样快。在优化良好的条件下,使用香橙派AI Pro开发板生成一张图像的时间可能会在10秒到30秒之间,但这只是一个估计范围,实际时间可能会有所不同,具体取决于模型的具体配置和优化情况。
四、体验总结
性能
配置不输我自己的电脑,在跑AI模型的时候更是拉开了一大段差距。
硬件规格参数
| CPU | 4核64位处理器+ AI处理器 1个DaVinciV300 AI core,主频1.224GHz 4个TAISHANV200M处理器核,主频1.6GHz |
|---|---|
| AI算力 | 20TOPS算力 |
| 内存 | LPDDR4X:12GB/24GB(可选),速率:4266Mbps |
| 存储 | ·支持eMMC模块:32GB/64GB/256GB ·SATA/NVME SSD(M.2接口2280) ·SPI Flash: 32MB ·TF插槽 |
| WIFI+蓝牙 | Wi-Fi 5双频+BT 4.2,BLE |
| 以太网收发器 | 双2.5G以太网 |
| 显示 | ·2 * HDMI TX 2.0输出,最大支持4K@60FPS ·1 * MIPI DSI 4-Lane 输出 |
| 摄像头 | 2 * MIPI CSI 4-Lane摄像头接口 |
| USB | 3 * USB 3.0 HOST 1 * USB Type-C 3.0 HOST/Device(兼容USB2.0) 1 * Type-C串口打印功能 |
| 音频 | 3.5mm耳机孔音频输入/输出 |
| 按键 | 1开机键、1RESET键、1启动拨动键、1BOOT键 |
| 40PIN | 40PIN 功能扩展接口,支持以下接口类型: GPIO、UART、I2C、SPI、PWM |
| 风扇 | 风扇接口*1 |
| 预留接口 | 预留2PIN电池接口 |
| 电源 | Type-C PD 20V IN ,标准65W |
| 支持的操作系统 | Ubuntu、openEuler |
| 产品尺寸 | 115.23mm83.26mm1.6mm |
| 重量 | 120.5g |
噪音
启动时,会经历大概十秒钟的轻微噪音,这是预热阶段。之后,就几乎听不到声音了。在处理模型的过程中,风扇的响声很平稳,没什么起伏。我用了好几个小时,这期间,风扇一直很安静。而且,散热片摸着不烫,说明设备散热做得挺好。
便捷性
仅需配备鼠标、键盘与显示器,即可实现全面操作。此板体积精巧,工艺细致,便携特性显著,轻而易举纳入随身口袋,随时随地展开工作或学习,移动性极佳。

