
- 1【微服务-SpringCloud】详细介绍,搭建一套微服务项目_springcloud搭建一个微服务项目
- 2【华为OD考试真题】快速人名查找【Python版】_快速人名查找算法
- 3Github 疯传!史上最强!BAT 大佬「LeetCode刷题手册」电子书开放下载了!
- 4python课设可视化答辩问题_浅析python 可视化
- 5Flutter 环境搭建问题(win10)_error: unable to find git in your path.
- 6昇思25天学习打卡营第10天|Vision Transformer图像分类
- 7Python程序开发案例教程PDF,python程序开发案例教程_python程序开发案例教程pdf黑马程序员
- 8推荐开源项目:RtspServer - 实时流媒体服务器解决方案
- 9使用 Socket和动态代理以及反射 实现一个简易的 RPC 调用
- 10maven scope 的作用_maven scope作用
每日论文速递 | DeepMind提出SAFE,用LLM Agent作为事实评估器
赞
踩
深度学习自然语言处理 分享
整理:pp
 摘要:大语言模型(LLM)在回答开放式话题的事实搜索提示时,经常会生成包含事实错误的内容。为了对模型在开放域中的长式事实性进行基准测试,我们首先使用 GPT-4 生成了 LongFact,这是一个由跨越 38 个主题的数千个问题组成的提示集。然后,我们提出可以通过一种我们称之为 "搜索增强事实性评估器"(Search-Augmented Factuality Evaluator,SAFE)的方法,将 LLM 代理用作长式事实性的自动评估器。SAFE 利用 LLM 将长式回复分解为一组单独的事实,并通过一个多步骤推理过程来评估每个事实的准确性,该过程包括向谷歌搜索发送搜索查询,并确定搜索结果是否支持某个事实。此外,我们还建议将 F1 分数扩展为长表事实性的综合指标。为此,我们平衡了回复中支持事实的百分比(精确度)和所提供事实相对于代表用户首选回复长度的超参数的百分比(召回率)。根据经验,我们证明了 LLM 代理可以实现超人的评级性能--在一组约 16k 的单个事实上,SAFE 与众包人类注释者的一致率为 72%,而在 100 个分歧案例的随机子集上,SAFE 的胜率为 76%。同时,SAFE 的成本比人类注释者低 20 多倍。我们还在 LongFact 上对四个模型系列(Gemini、GPT、Claude 和 PaLM-2)的 13 个语言模型进行了基准测试,发现较大的语言模型通常能获得更好的长格式事实性。LongFact、SAFE 和所有实验代码开源。
摘要:大语言模型(LLM)在回答开放式话题的事实搜索提示时,经常会生成包含事实错误的内容。为了对模型在开放域中的长式事实性进行基准测试,我们首先使用 GPT-4 生成了 LongFact,这是一个由跨越 38 个主题的数千个问题组成的提示集。然后,我们提出可以通过一种我们称之为 "搜索增强事实性评估器"(Search-Augmented Factuality Evaluator,SAFE)的方法,将 LLM 代理用作长式事实性的自动评估器。SAFE 利用 LLM 将长式回复分解为一组单独的事实,并通过一个多步骤推理过程来评估每个事实的准确性,该过程包括向谷歌搜索发送搜索查询,并确定搜索结果是否支持某个事实。此外,我们还建议将 F1 分数扩展为长表事实性的综合指标。为此,我们平衡了回复中支持事实的百分比(精确度)和所提供事实相对于代表用户首选回复长度的超参数的百分比(召回率)。根据经验,我们证明了 LLM 代理可以实现超人的评级性能--在一组约 16k 的单个事实上,SAFE 与众包人类注释者的一致率为 72%,而在 100 个分歧案例的随机子集上,SAFE 的胜率为 76%。同时,SAFE 的成本比人类注释者低 20 多倍。我们还在 LongFact 上对四个模型系列(Gemini、GPT、Claude 和 PaLM-2)的 13 个语言模型进行了基准测试,发现较大的语言模型通常能获得更好的长格式事实性。LongFact、SAFE 和所有实验代码开源。
https://arxiv.org/abs/2403.18802
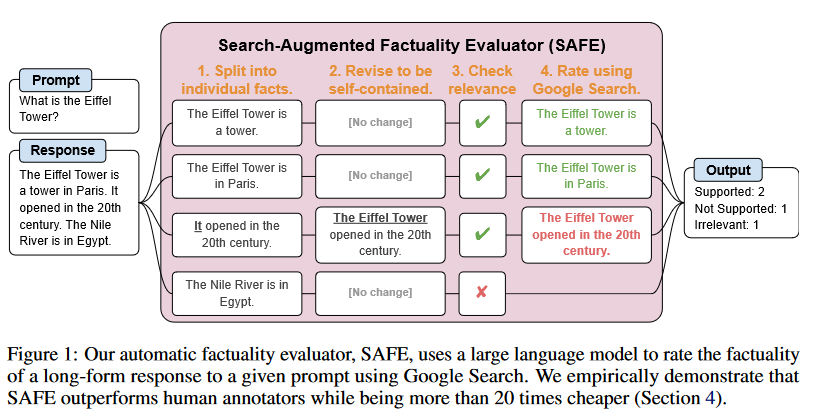
Q1: 这篇论文试图解决什么问题?
A:这篇论文试图解决大型语言模型(LLMs)在开放领域回答事实寻求提示时生成内容的准确性问题。特别是,LLMs在回答深入的事实性问题时经常产生与既定真相知识相矛盾的事实错误。为了评估开放领域中长篇幅回应的准确性,论文提出了一种名为LongFact的提示集,一个名为SAFE(Search-Augmented Factuality Evaluator)的评估方法,以及一个名为F1@K的度量标准来量化长篇幅回应的准确性。此外,论文还对来自四个模型家族(Gemini、GPT、Claude和PaLM-2)的十三种语言模型进行了广泛基准测试,发现更大的语言模型通常在长篇幅事实性方面表现更好。
Q2: 有哪些相关研究?
这篇论文提到了几项相关研究,主要集中在以下几个方面:
事实性评估: 近期的研究提出了多个事实性评估基准,例如FELM (Chen et al., 2023), FreshQA (Vu et al., 2023), 和HaluEval (Li et al., 2023) 等,这些基准主要测试模型对各种事实的了解。另外,像TruthfulQA (Lin et al., 2022) 和HalluQA (Cheng et al., 2023b) 这样的对抗性基准旨在测试语言模型是否会生成从模仿流行误解中学习到的虚假事实。
模型响应中的事实性评估: 为了全面评估模型的事实性,需要存在可靠的方法来量化模型对给定提示的响应的事实性。例如,FActScore (Min et al., 2023) 利用Wikipedia页面作为知识源,供人类和语言模型在评估关于人物传记的长篇幅回应时使用。RAGAS (Es et al., 2023) 评估了检索增强生成系统的回答是否自洽,通过提示大型语言模型检查问题、检索到的上下文、回答以及答案陈述之间的一致性。
量化长篇幅事实性: 长篇幅事实性的量化很困难,因为回应的质量既受到回应事实性(精确度)的影响,也受到回应覆盖范围(召回率)的影响。FActScore (Min et al., 2023) 使用与Wikipedia页面作为知识源的精确度来衡量,并提到了将召回率作为未来工作的难点。Tian et al. (2023) 和Dhuliawala et al. (2023) 也使用精确度作为模型回应事实性的代理。其他指标,如基于标记的F1分数 (Rajpurkar et al., 2016)、句子或段落级别的AUC (Manakul et al., 2023) 和与真实情况的相似度 (Wieting et al., 2022) 可以同时考虑精确度和召回率,但需要人类响应或判断作为真实情况。
自动化评估方法: 论文中提出的SAFE方法灵感来自于相关工作,但将其应用于长篇幅事实性设置中。与其他评估事实性的方法相比,SAFE是自动的,不需要任何模型微调或预设参考答案/知识源,并且比人类注释更可靠,成本也更低。
这些相关研究表明,事实性评估是一个多方面的研究领域,涉及从基准测试的创建到评估方法的开发,以及度量标准的创新。论文提出的LongFact、SAFE和F1@K旨在进一步提高我们对语言模型在长篇幅设置中能力的理解。
Q3: 论文如何解决这个问题?
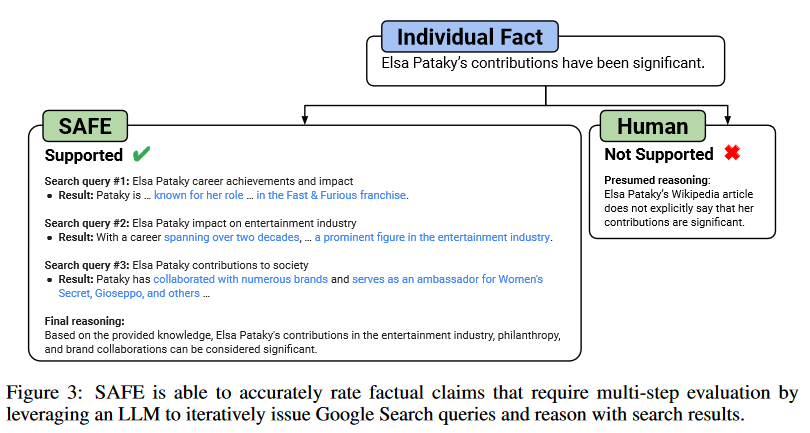
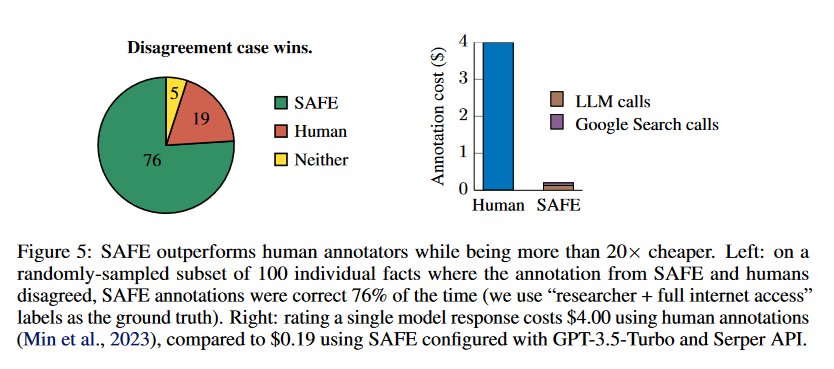
论文通过以下几个关键步骤来解决大型语言模型在长篇幅事实性评估方面的问题:
生成LongFact提示集:使用GPT-4生成了一个新的提示集LongFact,该提示集包含针对38个主题的2,280个事实寻求提示,旨在评估模型在长篇幅回应中的事实性。
提出SAFE评估方法:提出了一种名为Search-Augmented Factuality Evaluator (SAFE) 的方法,该方法利用语言模型将长篇幅回应分解为单个事实,并通过发送搜索查询到Google Search来评估每个事实的准确性。SAFE通过多步推理过程来确定事实是否得到搜索结果的支持。
引入F1@K度量标准:为了量化长篇幅回应的事实性,论文提出了扩展F1分数的方法,引入了一个超参数K来估计用户偏好的“理想”事实数量。F1@K在测量回应的精确度(支持事实的比例)的同时,通过变量K来衡量召回率(提供的支持事实与所需支持事实数量的比率)。
广泛基准测试:对来自四个模型家族(Gemini、GPT、Claude和PaLM-2)的十三种大型语言模型进行了广泛基准测试,使用SAFE评估模型回应,并使用F1@K量化性能。研究发现,更大的语言模型通常在长篇幅事实性方面表现更好。
证明SAFE的超人性能:通过与人类注释的比较,证明了SAFE在评估事实性方面的超人性能,与人类注释的一致率达到72%,并在100个随机抽样的分歧案例中,SAFE正确率为76%,同时比人类注释便宜20倍以上。
通过这些步骤,论文不仅提出了评估长篇幅事实性的有效方法,而且还通过实验验证了这些方法的有效性,并通过基准测试展示了不同模型的性能。
Q4: 论文做了哪些实验?
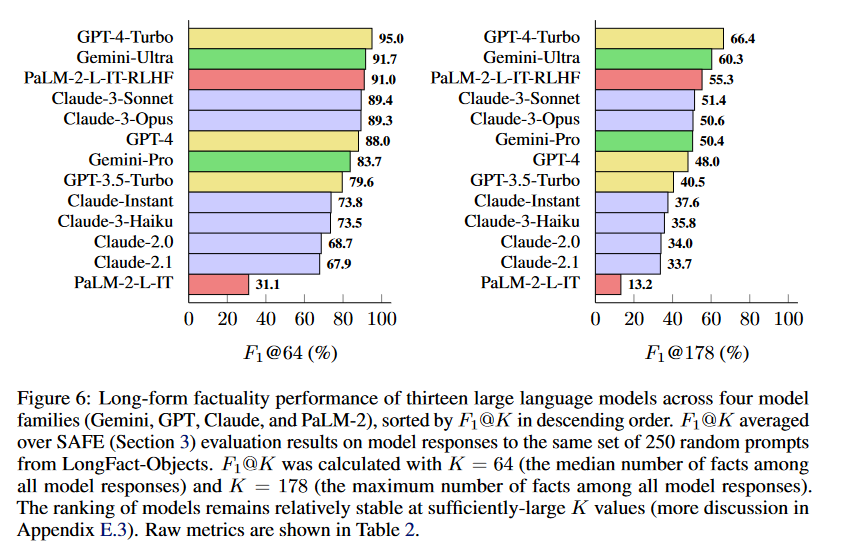
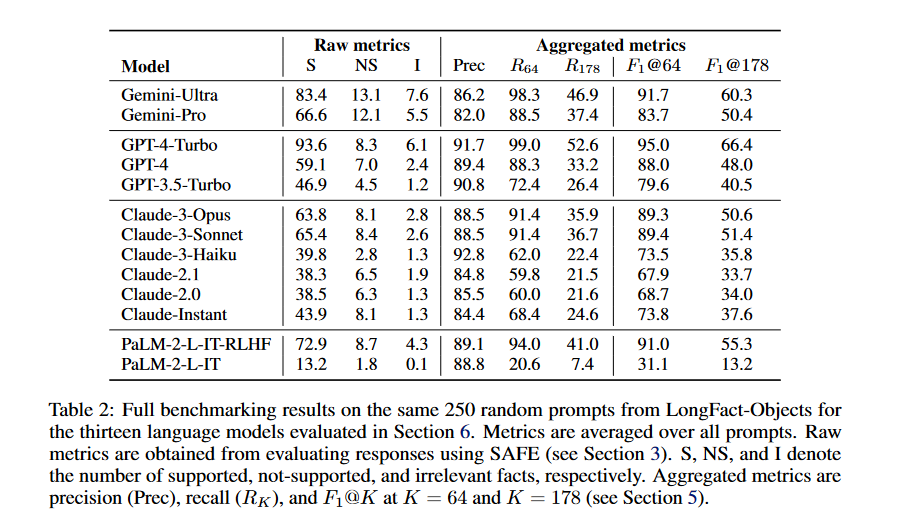
A:论文中进行了以下主要实验:
SAFE的性能评估:
使用来自Min et al. (2023)的人类注释数据集,该数据集包含496个提示-响应对,每个响应已被手动分解为单个事实,并且每个事实已被标记为支持、不相关或不支持。
比较SAFE的注释与人类注释,发现SAFE在72%的单个事实上与人类注释一致。
在SAFE和人类注释不一致的100个随机样本中,发现SAFE在76%的情况下是正确的,而人类注释仅在19%的情况下是正确的。
模型基准测试:
使用LongFact提示集对来自四个模型家族(Gemini、GPT、Claude和PaLM-2)的十三个不同的大型语言模型进行评估。
使用SAFE评估每个模型对随机抽取的250个LongFact-Objects提示的响应。
计算每个模型响应的原始指标(支持事实、不支持事实和不相关事实的数量),并使用F1@K(K=64和K=178)聚合这些指标。
模型性能与K值的关系:
分析不同K值(代表用户期望的响应中支持事实的数量)对模型性能的影响。
展示在足够大的K值下,模型排名相对稳定。
人类注释错误分析:
分析并举例说明人类注释者在标注事实性时犯的错误,以及这些错误的潜在原因。
模型性能与模型规模的关系:
探讨通过模型缩放(即增加模型大小)如何影响长篇幅事实性。
比较同一模型家族中不同规模的模型,并分析RLHF(Reinforcement Learning from Human Feedback)对长篇幅事实性的影响。
这些实验旨在全面评估和比较不同大型语言模型在长篇幅事实性方面的表现,并验证了SAFE作为一种自动评估工具的有效性和优越性。
Q5: 有什么可以进一步探索的点?
A:论文提出了几个可以进一步探索的点:
改进语言模型的长篇幅事实性:探索如何通过更好的预训练/微调或通过使用外部工具来提高语言模型的长篇幅事实性。
改进SAFE方法:研究如何减少SAFE对搜索启用的语言模型代理的依赖,并提高其在评估长篇幅事实性方面的性能。
探索事实性与幻觉的区分:论文主要关注事实性(即与世界知识相关的正确性),但如何在长篇幅设置中可靠地衡量幻觉(即与模型内部知识相关的正确性)仍然是一个开放的问题。
探索K值的选择:研究如何更好地选择F1@K中的K值,以更准确地反映用户对响应长度的偏好,并进一步优化度量标准。
探索不同领域的适用性:研究SAFE和F1@K在其他长篇幅领域(如创造性任务)的适用性和潜在调整。
探索模型输出的重复性:研究如何更好地处理模型输出中事实的重复性,这可能会影响事实性评估的准确性。
探索不同模型的偏见:研究不同语言模型在执行SAFE步骤时是否表现出对自己输出的偏见,并探索如何减少这种偏见。
探索更广泛的主题适用性:虽然SAFE在具有Wikipedia传记的一般主题上表现良好,但探索其在更多主题上的适用性和性能。
这些探索点为未来的研究提供了方向,旨在提高语言模型在长篇幅事实性方面的表现,并进一步改进评估方法和度量标准。
Q6: 总结一下论文的主要内容?
A:这篇论文主要探讨了大型语言模型(LLMs)在生成长篇幅内容时的事实性问题,并提出了相应的解决方案。主要内容可以总结如下:
问题陈述:LLMs在回答开放式问题时经常产生包含事实错误的内容,这降低了它们在现实世界应用中的可靠性。
LongFact提示集:使用GPT-4生成了一个包含38个主题、2280个问题的LongFact提示集,用于评估模型在长篇幅回应中的事实性。
SAFE评估方法:提出了一种名为SAFE的自动评估方法,该方法利用LLM将长篇幅回应分解为单个事实,并通过Google Search查询来评估每个事实的准确性。
F1@K度量标准:引入了F1@K度量标准,结合了精确度和召回率,通过一个超参数K来估计用户期望的响应长度,从而更全面地评估长篇幅回应的事实性。
实验验证:通过实验,证明了SAFE在评估事实性方面超越了人类注释者,并且在13种不同模型上的基准测试中发现,更大的模型通常具有更好的长篇幅事实性。
可扩展性和成本效益:SAFE不仅在评估长篇幅事实性方面表现出超人的性能,而且比人类注释者便宜20倍以上。
未来研究方向:论文最后提出了一系列未来研究方向,包括改进模型的长篇幅事实性、改进SAFE方法、探索不同领域的适用性等。
总体而言,这篇论文提出了一种新的长篇幅事实性评估框架,并通过对现有大型语言模型的基准测试,展示了该框架的有效性和实用性。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


