- 1玉米脱粒机说明书_玉米脱机的出料口
- 2如何使用 Victoria 检测并修复硬盘坏道和坏扇区_victoria硬盘检测
- 3大数据技术应用场景_大数据存储和计算用在什么地方
- 4基于(cisco)ACS的mac地址访问控制和telnet,ssh的访问控制
- 5python系列:已解决error: subprocess-exited-with-error_python subprocess-exited-with-error
- 6llama 2 改进之 RMSNorm
- 7测试阶段与测试技术(一)概述_测试阶段技术。
- 85.布隆过滤器_布隆过滤器为什么经历duocihash
- 9通用大模型与垂直大模型:双轨并进的人工智能未来
- 10macOS + Ollama + Enchanted,本地部署最新 Llama3_ollama 后台运行
昇思25天学习打卡营第10天|Vision Transformer图像分类
赞
踩
1. 学习内容复盘
Vision Transformer(ViT)简介
近些年,随着基于自注意(Self-Attention)结构的模型的发展,特别是Transformer模型的提出,极大地促进了自然语言处理模型的发展。由于Transformers的计算效率和可扩展性,它已经能够训练具有超过100B参数的空前规模的模型。
ViT则是自然语言处理和计算机视觉两个领域的融合结晶。在不依赖卷积操作的情况下,依然可以在图像分类任务上达到很好的效果。
模型结构
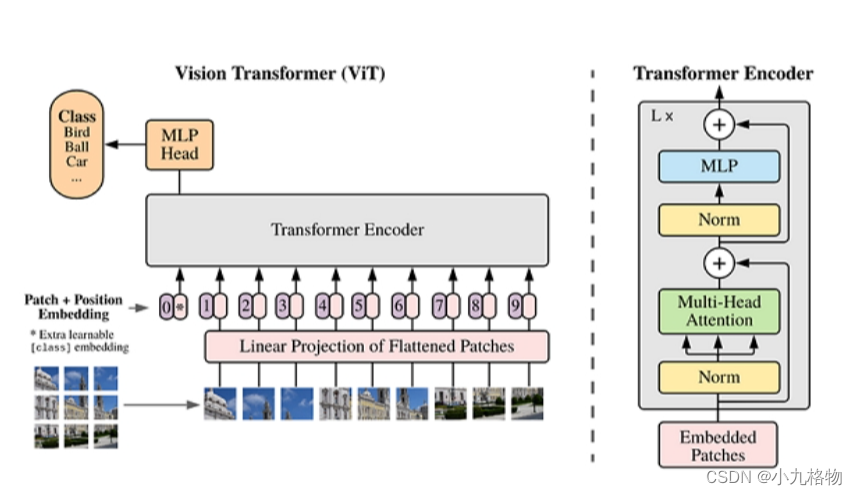
ViT模型的主体结构是基于Transformer模型的Encoder部分(部分结构顺序有调整,如:Normalization的位置与标准Transformer不同),其结构图[1]如下:
模型特点
ViT模型主要应用于图像分类领域。因此,其模型结构相较于传统的Transformer有以下几个特点:
a.数据集的原图像被划分为多个patch(图像块)后,将二维patch(不考虑channel)转换为一维向量,再加上类别向量与位置向量作为模型输入。
b.模型主体的Block结构是基于Transformer的Encoder结构,但是调整了Normalization的位置,其中,最主要的结构依然是Multi-head Attention结构。
c.模型在Blocks堆叠后接全连接层,接受类别向量的输出作为输入并用于分类。通常情况下,我们将最后的全连接层称为Head,Transformer Encoder部分为backbone。
环境准备与数据读取
开始实验之前,请确保本地已经安装了Python环境并安装了MindSpore。
首先我们需要下载本案例的数据集,可通过http://image-net.org下载完整的ImageNet数据集,本案例应用的数据集是从ImageNet中筛选出来的子集。
运行第一段代码时会自动下载并解压,请确保你的数据集路径如以下结构。
.dataset/
├── ILSVRC2012_devkit_t12.tar.gz
├── train/
├── infer/
└── val/
模型解析
下面将通过代码来细致剖析ViT模型的内部结构。
Transformer基本原理
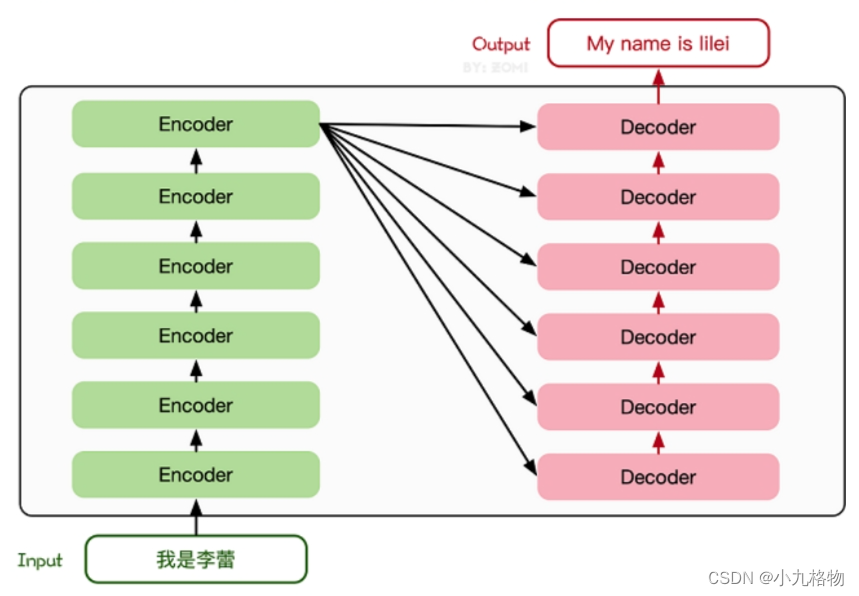
Transformer模型源于2017年的一篇文章[2]。在这篇文章中提出的基于Attention机制的编码器-解码器型结构在自然语言处理领域获得了巨大的成功。模型结构如下图所示:
其主要结构为多个Encoder和Decoder模块所组成,其中Encoder和Decoder的详细结构如下图[2]所示:
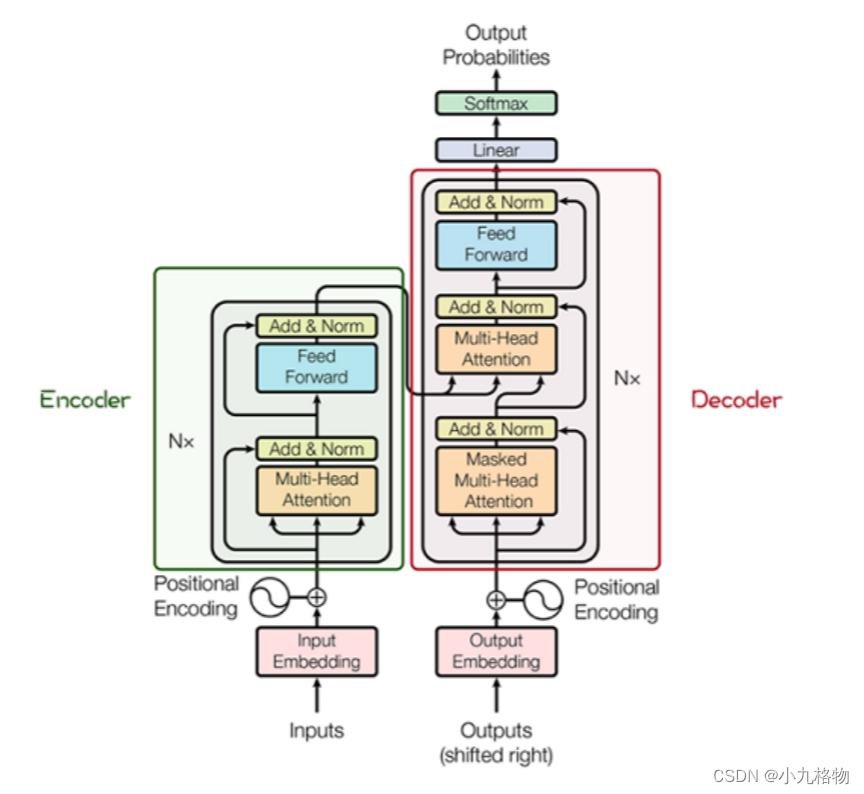
Encoder与Decoder由许多结构组成,如:多头注意力(Multi-Head Attention)层,Feed Forward层,Normaliztion层,甚至残差连接(Residual Connection,图中的“Add”)。不过,其中最重要的结构是多头注意力(Multi-Head Attention)结构,该结构基于自注意力(Self-Attention)机制,是多个Self-Attention的并行组成。
所以,理解了Self-Attention就抓住了Transformer的核心。
Attention模块
以下是Self-Attention的解释,其核心内容是为输入向量的每个单词学习一个权重。通过给定一个任务相关的查询向量Query向量,计算Query和各个Key的相似性或者相关性得到注意力分布,即得到每个Key对应Value的权重系数,然后对Value进行加权求和得到最终的Attention数值。
在Self-Attention中:
最初的输入向量首先会经过Embedding层映射成Q(Query),K(Key),V(Value)三个向量,由于是并行操作,所以代码中是映射成为dim x 3的向量然后进行分割,换言之,如果你的输入向量为一个向量序列( x1 , x2 , x3 ),其中的 x1 , x2 , x3 都是一维向量,那么每一个一维向量都会经过Embedding层映射出Q,K,V三个向量,只是Embedding矩阵不同,矩阵参数也是通过学习得到的。这里大家可以认为,Q,K,V三个矩阵是发现向量之间关联信息的一种手段,需要经过学习得到,至于为什么是Q,K,V三个,主要是因为需要两个向量点乘以获得权重,又需要另一个向量来承载权重向加的结果,所以,最少需要3个矩阵。
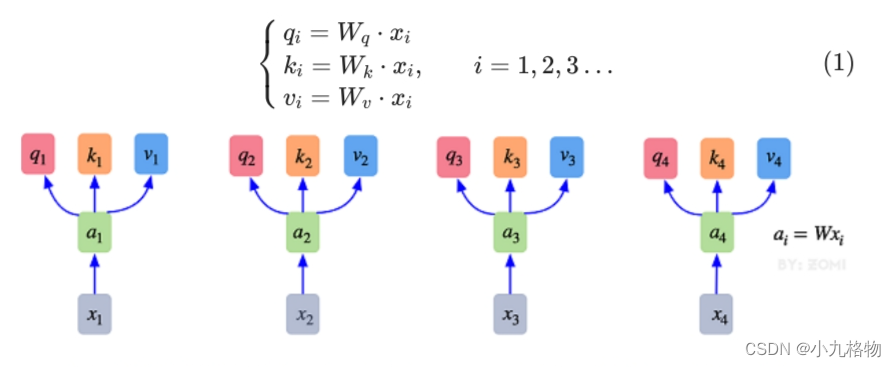
自注意力机制的自注意主要体现在它的Q,K,V都来源于其自身,也就是该过程是在提取输入的不同顺序的向量的联系与特征,最终通过不同顺序向量之间的联系紧密性(Q与K乘积经过Softmax的结果)来表现出来。Q,K,V得到后就需要获取向量间权重,需要对Q和K进行点乘并除以维度的平方根,对所有向量的结果进行Softmax处理,通过公式(2)的操作,我们获得了向量之间的关系权重。
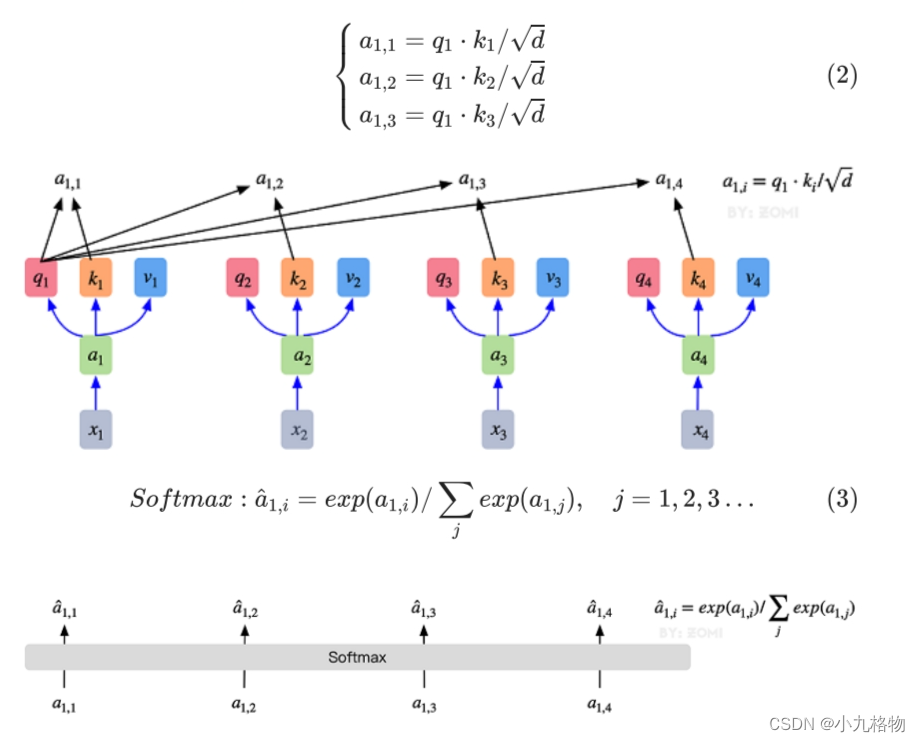
其最终输出则是通过V这个映射后的向量与Q,K经过Softmax结果进行weight sum获得,这个过程可以理解为在全局上进行自注意表示。每一组Q,K,V最后都有一个V输出,这是Self-Attention得到的最终结果,是当前向量在结合了它与其他向量关联权重后得到的结果。
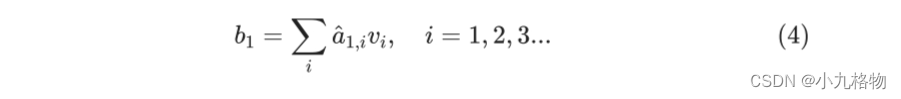
通过下图可以整体把握Self-Attention的全部过程。
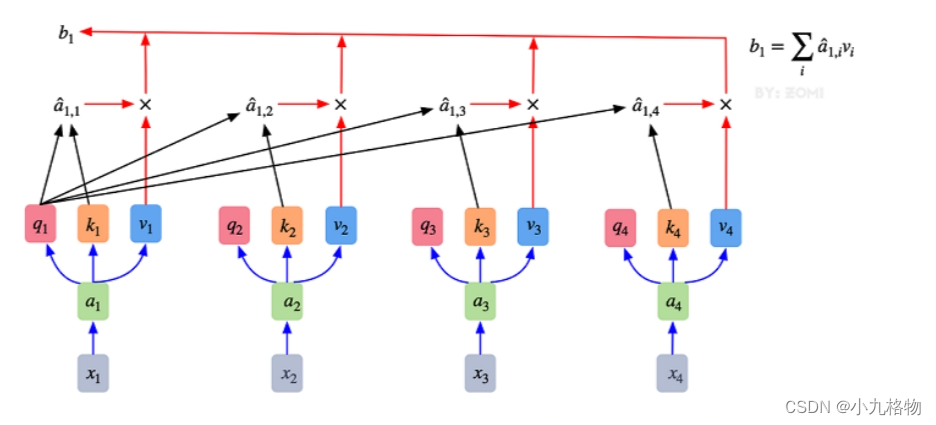
多头注意力机制就是将原本self-Attention处理的向量分割为多个Head进行处理,这一点也可以从代码中体现,这也是attention结构可以进行并行加速的一个方面。
总结来说,多头注意力机制在保持参数总量不变的情况下,将同样的query, key和value映射到原来的高维空间(Q,K,V)的不同子空间(Q_0,K_0,V_0)中进行自注意力的计算,最后再合并不同子空间中的注意力信息。
所以,对于同一个输入向量,多个注意力机制可以同时对其进行处理,即利用并行计算加速处理过程,又在处理的时候更充分的分析和利用了向量特征。下图展示了多头注意力机制,其并行能力的主要体现在下图中的 a1 和 a2 是同一个向量进行分割获得的。
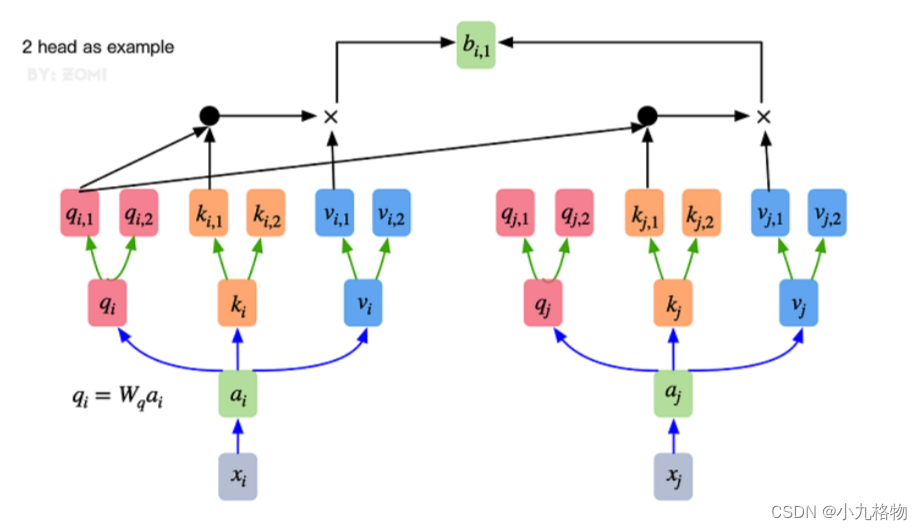
Transformer Encoder
在了解了Self-Attention结构之后,通过与Feed Forward,Residual Connection等结构的拼接就可以形成Transformer的基础结构,下面代码实现了Feed Forward,Residual Connection结构。
接下来就利用Self-Attention来构建ViT模型中的TransformerEncoder部分,类似于构建了一个Transformer的编码器部分,如下图[1]所示:
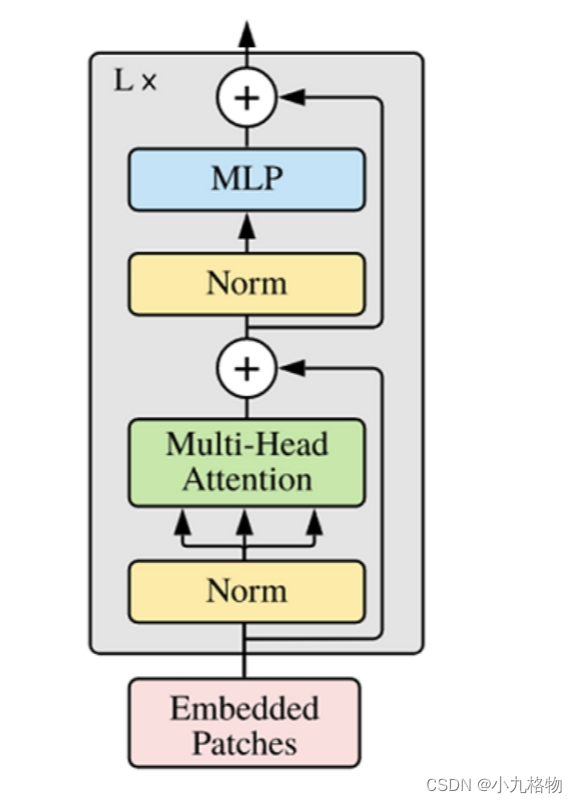
ViT模型中的基础结构与标准Transformer有所不同,主要在于Normalization的位置是放在Self-Attention和Feed Forward之前,其他结构如Residual Connection,Feed Forward,Normalization都如Transformer中所设计。
从Transformer结构的图片可以发现,多个子encoder的堆叠就完成了模型编码器的构建,在ViT模型中,依然沿用这个思路,通过配置超参数num_layers,就可以确定堆叠层数。
Residual Connection,Normalization的结构可以保证模型有很强的扩展性(保证信息经过深层处理不会出现退化的现象,这是Residual Connection的作用),Normalization和dropout的应用可以增强模型泛化能力。
ViT模型的输入
传统的Transformer结构主要用于处理自然语言领域的词向量(Word Embedding or Word Vector),词向量与传统图像数据的主要区别在于,词向量通常是一维向量进行堆叠,而图片则是二维矩阵的堆叠,多头注意力机制在处理一维词向量的堆叠时会提取词向量之间的联系也就是上下文语义,这使得Transformer在自然语言处理领域非常好用,而二维图片矩阵如何与一维词向量进行转化就成为了Transformer进军图像处理领域的一个小门槛。
在ViT模型中:
通过将输入图像在每个channel上划分为16*16个patch,这一步是通过卷积操作来完成的,当然也可以人工进行划分,但卷积操作也可以达到目的同时还可以进行一次而外的数据处理;例如一幅输入224 x 224的图像,首先经过卷积处理得到16 x 16个patch,那么每一个patch的大小就是14 x 14。
再将每一个patch的矩阵拉伸成为一个一维向量,从而获得了近似词向量堆叠的效果。上一步得到的14 x 14的patch就转换为长度为196的向量。
输入图像在划分为patch之后,会经过pos_embedding 和 class_embedding两个过程。
class_embedding主要借鉴了BERT模型的用于文本分类时的思想,在每一个word vector之前增加一个类别值,通常是加在向量的第一位,上一步得到的196维的向量加上class_embedding后变为197维。
增加的class_embedding是一个可以学习的参数,经过网络的不断训练,最终以输出向量的第一个维度的输出来决定最后的输出类别;由于输入是16 x 16个patch,所以输出进行分类时是取 16 x 16个class_embedding进行分类。
pos_embedding也是一组可以学习的参数,会被加入到经过处理的patch矩阵中。
由于pos_embedding也是可以学习的参数,所以它的加入类似于全链接网络和卷积的bias。这一步就是创造一个长度维197的可训练向量加入到经过class_embedding的向量中。
实际上,pos_embedding总共有4种方案。但是经过作者的论证,只有加上pos_embedding和不加pos_embedding有明显影响,至于pos_embedding是一维还是二维对分类结果影响不大,所以,在我们的代码中,也是采用了一维的pos_embedding,由于class_embedding是加在pos_embedding之前,所以pos_embedding的维度会比patch拉伸后的维度加1。
总的而言,ViT模型还是利用了Transformer模型在处理上下文语义时的优势,将图像转换为一种“变种词向量”然后进行处理,而这样转换的意义在于,多个patch之间本身具有空间联系,这类似于一种“空间语义”,从而获得了比较好的处理效果。
整体构建ViT
以下代码构建了一个完整的ViT模型(见平台实验结果图)。
整体流程图如下所示:
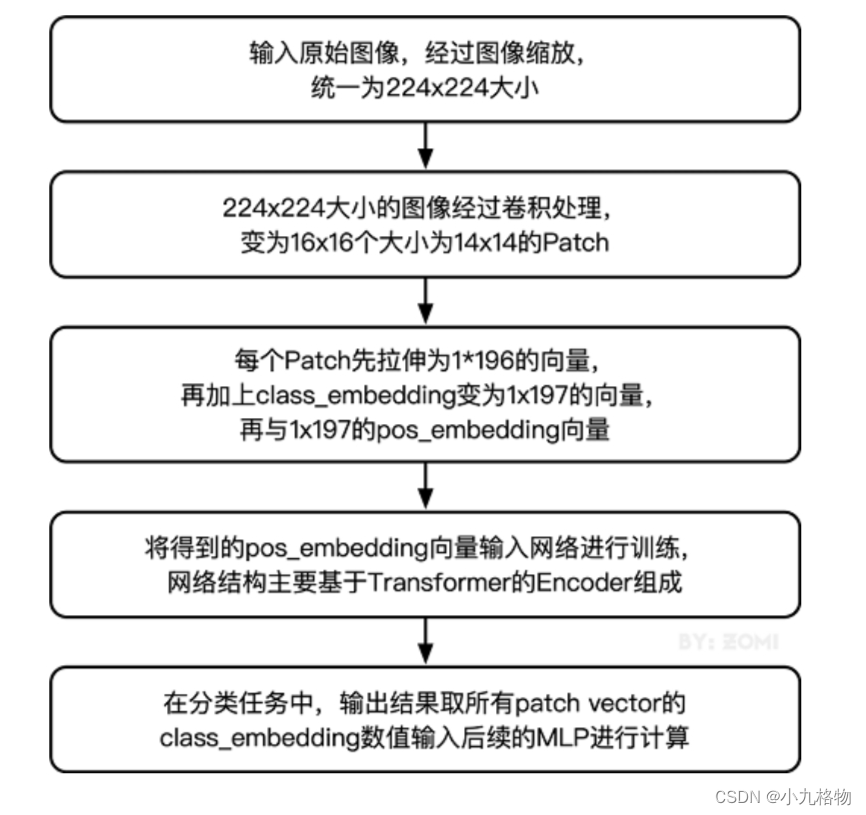
模型训练与推理
模型训练
模型开始训练前,需要设定损失函数,优化器,回调函数等。
完整训练ViT模型需要很长的时间,实际应用时建议根据项目需要调整epoch_size,当正常输出每个Epoch的step信息时,意味着训练正在进行,通过模型输出可以查看当前训练的loss值和时间等指标。
模型验证
模型验证过程主要应用了ImageFolderDataset,CrossEntropySmooth和Model等接口。
ImageFolderDataset主要用于读取数据集。
CrossEntropySmooth是损失函数实例化接口。
Model主要用于编译模型。
与训练过程相似,首先进行数据增强,然后定义ViT网络结构,加载预训练模型参数。随后设置损失函数,评价指标等,编译模型后进行验证。本案例采用了业界通用的评价标准Top_1_Accuracy和Top_5_Accuracy评价指标来评价模型表现。
在本案例中,这两个指标代表了在输出的1000维向量中,以最大值或前5的输出值所代表的类别为预测结果时,模型预测的准确率。这两个指标的值越大,代表模型准确率越高。
模型推理
在进行模型推理之前,首先要定义一个对推理图片进行数据预处理的方法。该方法可以对我们的推理图片进行resize和normalize处理,这样才能与我们训练时的输入数据匹配。
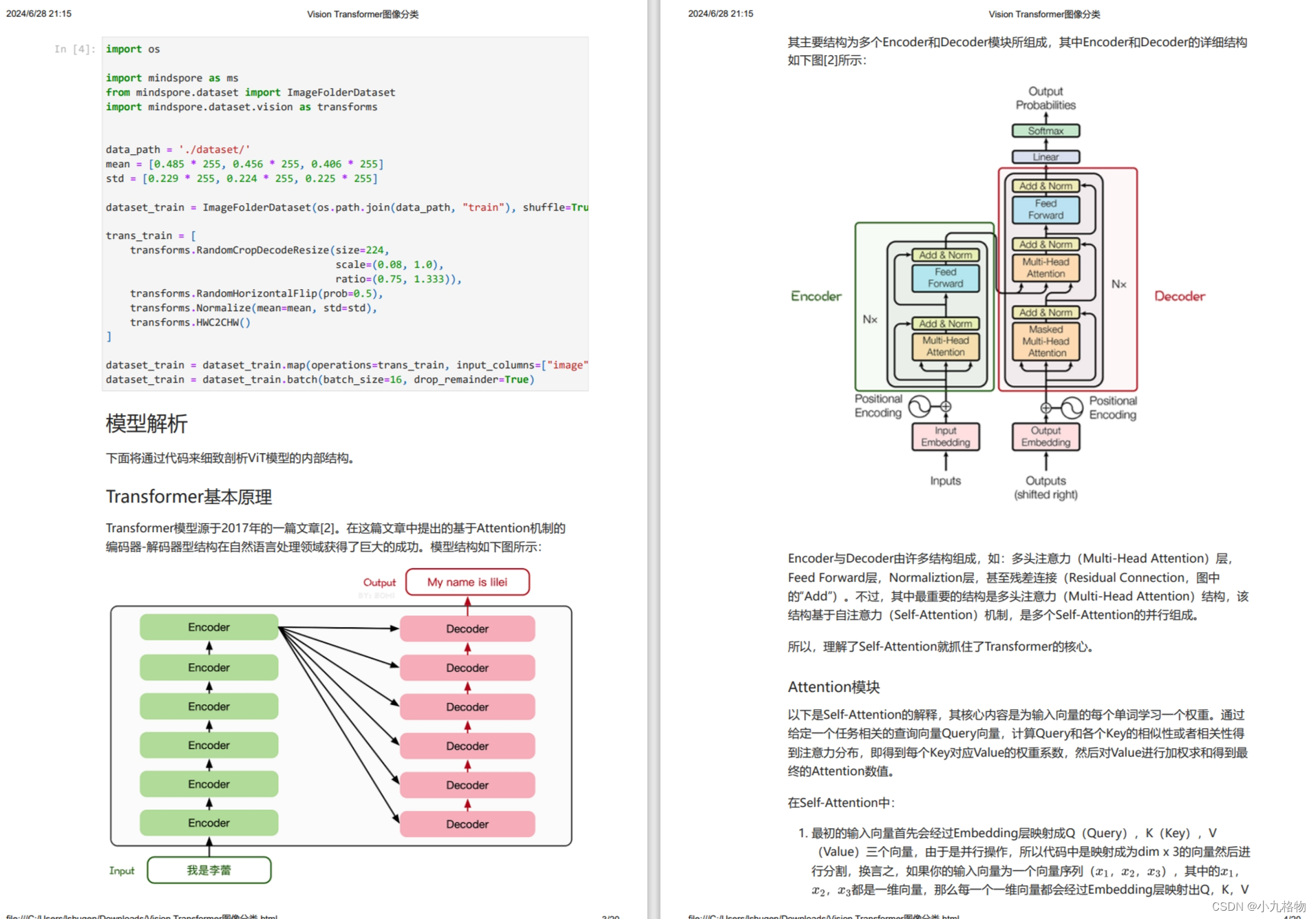
本案例采用了一张Doberman的图片作为推理图片来测试模型表现,期望模型可以给出正确的预测结果。

总结
本案例完成了一个ViT模型在ImageNet数据上进行训练,验证和推理的过程,其中,对关键的ViT模型结构和原理作了讲解。通过学习本案例,理解源码可以帮助用户掌握Multi-Head Attention,TransformerEncoder,pos_embedding等关键概念,如果要详细理解ViT的模型原理,建议基于源码更深层次的详细阅读。
2.平台实验结果