
- 1【Android Camera简单整理(一)-Camera Android架构(高通)】
- 21.机器学习-机器学习算法分类概述_机器学习 算法怎么分类
- 3uniapp上架苹果APP Store傻瓜式教程_uniapp上架appstore
- 4IDEA提示failed to load JVM DLL的解决办法_idea fail to load jvm dll
- 5思科模拟器安装教程
- 6Xcode设置cocoapods库的最低兼容版本_cocoapods 和 ios工程最低版本不一样
- 7php操作MySQL数据库(一)
- 8ListNode的Python实现_listcode python
- 9如何快速清理已经上传到Git仓库的.DS_Store文件
- 10阿里云CDN- https(设计支付宝春节开奖业务)
SparkStreaming&Kafka——Receiver方式_kafkareceiver 怎么能一直接受消息
赞
踩
SparkStreaming&Kafka——Receiver方式
https://github.com/holdbelief/spark/tree/master/SparkStreaming/SparkStreamingExamples/SparkStreaming_Kafka/Receiver

Kafka生产者向Kafka生产消息
Producer向不同的Broker中生产消息的负载均衡策略有两种:1、轮询的负载均衡策略;2、基于hash的负载均衡策略
-
SparkStreaming作为Kafka的消费者消费Kafka中的消息
Receiver模式会启动一个ReceiverTask线程,每隔BatchInterval时间间隔从Kafka中订阅的Topic中拉取消息。ReceiverTask也会占用一个线程,这就是为什么设置线程数不能设置为1个线程的原因(如果只有一个线程,那么这个线程会被用来执行ReceiverTask,就没有多余的线程执行应用成了)。如下代码所示:
SparkConf.setMaster("local[1]");
或者
SparkConf.setMaster("local");
都不可以。
-
ReceiverTask将消息进行持久化
持久化级别是MEMORY_AND_DISK_SER_2,如果有有3个Executor,那么并不是将消息复制为3个数据副本,而是根据持久化级别复制成2个数据副本
-
ReceiverTask向Driver的ReceiverTracker线程汇报接收到的消息都存放在哪些Executor节点中
-
ReceiverTask向ZK汇报消费消息的消费偏移量
-
Driver分发Task到Executor线程池中执行
Driver知道消息都在哪些Executor节点中之后(第3步),分发task到Executor线程池中执行,从而实现了数据本地化(移动计算而不移动数据)
Receiver方式可能造成的数据丢失:
当SparkStreaming的Driver进程挂掉之后,与Driver同属于一个Application的Executor进程也会挂掉,那么如果在第4步之后Driver进程挂掉,Executor也挂掉,那么会造成Executor中的数据丢失,而在第4步中又已经向ZK汇报完了消息的数据偏移量,那么这部分数据无法重新从Kafka中获取。
解决方案就是在上面第2步之后,增加一步,SparkStreaming将从Kafka中接受来的消息再在HDFS中存储一份。(在Executor中根据持久化级别MEMORY_DISK_SER_E存储过2分消息,但是Executor可能会因为Driver的挂掉而挂掉,导致持久化的消息丢失,所以在HDFS中再存储一份消息),这个机制称作WAL机制(WriteAheadLog-预写日志机制)。
-
-
SparkStreaming作为Kafka的消费者消费Kafka中的消息
-
ReceiverTask将消息进行持久化
-
WAL机制
-
ReceiverTask向Driver的ReceiverTracker线程汇报接收到的消息都存放在哪些Executor节点中
-
ReceiverTask向ZK汇报消费消息的消费偏移量
-
Driver分发Task到Executor
预写日志机制的存在的问题是,需要将数据写入HDFS从而在性能上带来的损失。WAL完成之前,无法继续执行下一步ReceiverTask向Driver汇报消息位置,进而拖慢整个系统运行速度,如果WAL时间超过了BatchInterval时间,那么系统会出问题。
package com.bjsxt.java.spark.streaming;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaPairReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.KafkaUtils;
import scala.Tuple2;
publicclass SparkStreamingOnKafkaReceiver {
publicstaticvoid main(String[] args) {
/*
* 当在Eclipse中运行的时候,去掉setMaster("local[1]")的注释,在yarn或者Standalone中运行的时候,注释掉setMaster("local[1]")
*/
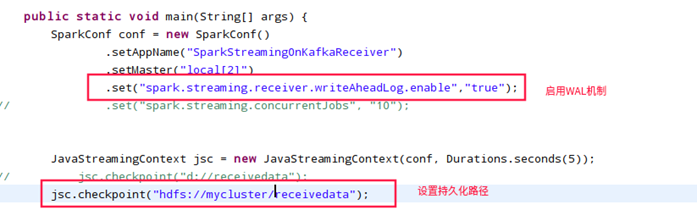
SparkConf conf = new SparkConf().setAppName("SparkStreamingOnKafkaReceiver").setMaster("local[2]")
.set("spark.streaming.receiver.writeAheadLog.enable", "true"); //开启WAL路径设置
JavaStreamingContext jsc = null;
try {
jsc = new JavaStreamingContext(conf, Durations.seconds(5));
/*
* WAL路径设置
*/
jsc.checkpoint("hdfs://mycluster/kafka_spark/receiverdata");
Map<String, Integer> topicConsumerConcurrency = new HashMap<String, Integer>();
/*
* Map的Key:消费的Topic的名字,本例中Topic1,代表消费Topic1这个Topic Map的Value:启动几个线程去执行Receiver
* Task,本例中1,代表使用1个线程执行Receiver Task
* 如果Value设置为1,那么setMaster("local[2]"),就至少要设置为2个线程,一个线程用于执行Receiver
* Task,另一个线程用于执行业务
* 如果Value设置为2,那么setMaster("local[3]"),就至少要设置为3个线程,两个线程用于执行Receiver
* Task,剩下一个线程用于执行业务
*/
topicConsumerConcurrency.put("Topic1", 1);
JavaPairReceiverInputDStream<String, String> lines = KafkaUtils.createStream(jsc,
"faith-openSUSE:2181,faith-Kylin:2181,faith-Mint:2181", "MyFirstConsumerGroup",
topicConsumerConcurrency);
/*
* lines是一个kv格式的 k:offset v:values
*/
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<Tuple2<String, String>, String>() {
privatestaticfinallongserialVersionUID = -1955739045858623388L;
@Override
public Iterable<String> call(Tuple2<String, String> tuple) throws Exception {
return Arrays.asList(tuple._2.split("\t"));
}
});
JavaPairDStream<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
privatestaticfinallongserialVersionUID = -4180968474440524871L;
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
returnnew Tuple2<String, Integer>(word, 1);
}
});
JavaPairDStream<String, Integer> wordsCount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
privatestaticfinallongserialVersionUID = 5167887209365658964L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
returnv1 + v2;
}
});
wordsCount.print();
jsc.start();
} finally {
if (jsc != null) {
jsc.awaitTermination();
}
}
}
}
-
启动集群
分别在faith-openSUSE、faith-Kylin、faith-Mint上执行zkServer.sh start。
在faith-Fedora节点上执行start-dfs.sh
在faith-Kylin节点上执行start-yarn.sh
在faith-Mint节点上执行yarn-daemon.sh start resourcemanager
在faith-openSUSE、faith-Kylin、faith-Mint节点上分别执行下面命令,启动Kafka集群:


启动Producer,并输入一些字符串





填坑
由于本例中使用的Spark版本是1.6.2,与之对应的Scala版本是2.10,在Maven的POM文件中加入SparkStreaming依赖的时候,scala的版本要为2.10,不能是2.11或其他。例如:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.6.2</version>
</dependency>
如果写成2.11,有可能造成一些问题,例如本例中,2.11的时候,当使用yarn-client或者yarn-Client模式下,无法获取BlockManager的问题,程序一直卡在这里,等待获取BlockManager,不继续执行。或者还有可能造成其他各种问题。
总之Spark的版本要和Scala的版本对应上。
参考文章:
https://www.iteblog.com/archives/1322.html

