
- 1深度学习评价标准:TP、FN、FP、TN、AP、MAP_tp5 fn
- 2【海思SS626 | VB】关于 视频缓存池 的理解
- 3Vue项目通过宝塔部署之后,页面刷新后浏览器404页面。_宝塔面板404
- 4RabbitMQ的四种交换器以及死信队列介绍_rabbitmq多个交换机共享消息队列
- 5Github Copilot 用账号登录,完美支持chat,不妨试试_copilot账号
- 6【开发环境搭建篇】NodeJS版本管理工具NVM的安装和配置_node版本管理工具
- 7基于S3C6410的ARM11学习(三) 核心初始化之设置中断向量表_arm 初始化中断向量
- 8python训练模型报错:BrokenPipeError: [Errno 32] Broken pipe_python print方法 valueerror:
- 9区块链开源的项目有哪些?_开源区块链
- 10如何实现数据库的优化_数据库结构如何优化
AWS生成式AI项目的全生命周期管理
赞
踩
随着人工智能技术的迅速发展,生成式 AI 已成为当今最具创新性和影响力的领域之一。生成式 AI 能够创建新的内容,如文本、图像、音频等,具有广泛的应用前景,如自然语言处理、计算机视觉、创意设计等。然而,构建一个成功的生成式AI项目并非易事,它需要一个系统而全面的生命周期管理过程。本文将从确定用例、实验与选择模型、适配对齐与增强、评估、部署与集成,以及监控等关键阶段,详细阐述AWS生成式AI项目的全生命周期管理。
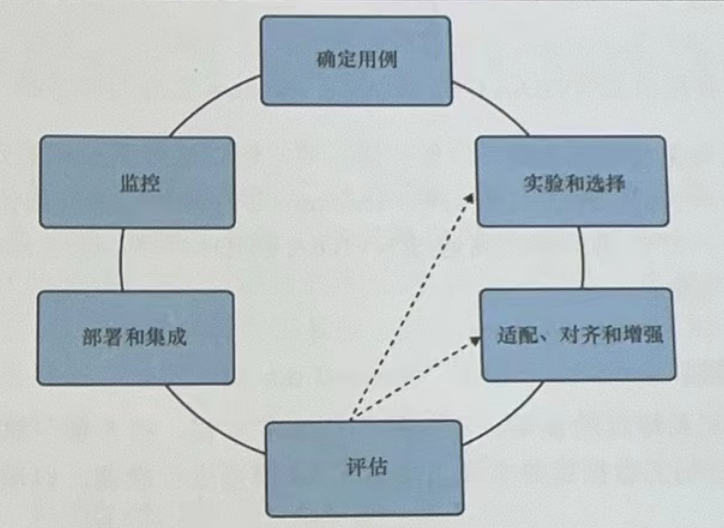
1. 确定用例:明确目标与需求
起始点: 任何项目的第一步都是明确目标和需求。对于生成式AI项目而言,这意味着需要清晰地定义AI系统将要解决的问题、服务的对象以及期望达到的效果。例如,是用于辅助创意写作、自动生成新闻摘要,还是设计个性化的艺术作品?
关键步骤:
- 需求分析:通过市场调研、用户访谈等方式收集需求信息。
- 用例定义:基于需求分析,明确具体的应用场景和用例。
- 目标设定:设定可量化的项目目标,如准确率、响应时间、用户满意度等。
建议从一个单一的、成熟的用例开始。这将帮助你熟悉环境,并了解这些模型的能力和局限性,而不必同时优化模型以适配不同的任务。虽然这些模型能够执行多项任务,但从一开始就在多项任务上评估和优化模型会比较困难。
2. 实验与选择模型
生成式 AI模型能够成功地执行许多不同类型的任务。但是需要决定现有的基础模型是否适合你的应用程序需求。比如:如何使用提示工程(PromptEngineering)和上下文学习(In-ContextLearning),以直接使用已有的基础模型。
从已有的基础模型开始会大幅缩短由开发到投入使用的时间,因为这样可以省去预训练的步骤。预训练是一个资源密集型的过程,通常需要数万亿个单词、图像、视频或音频片段才能开始。运维和管理这种规模的任务需要大量时间、耐心和计算能力--从头开始预训练通常需要数百万GPU计算小时。
还需要考虑使用的基础模型的规模,这将影响模型训练和推理所需的硬件与成本。虽然较大的模型往往能更好地支持更多的任务,但也取决于训练和调优期间使用的数据集。
建议针对生成式用例和任务尝试不同的模型。从已有的、有成熟文档的、规模相对较小(如70亿个参数)的基础模型开始,用较少数量的硬件(与175亿个参数以上的较大模型相比)快速迭代,学习与这些生成式AI模型交互的独特方式。在开发过程中,我们通常会从AmazonSageMakerJumpStart或Amazon Bedrock中的playground开始,可以快速尝试不同的提示和模型。接下来,我们可能会使用 jupyer Notebook、 Visual Studio Code ( Vs Code)或 Amazon SageMaker Studio(IDE)编写 Python 脚本,使用的自定义数据集。做好前期准备工作后,进一步扩展到更大的分布式集群,如迁移到SageMaker分布式训练模块,使用诸如 NVIDIA GPU或 AWs Trainium 进一步加速。
关键步骤:
- 模型调研:研究不同模型的原理、性能、优缺点及在类似任务中的表现。
- 实验设计:设计对比实验,使用不同模型在数据集上进行训练和测试。
- 模型选择:基于实验结果,选择最适合项目需求的模型。
3. 适配对齐与增强
精细化调整: 选定模型后,需要根据具体用例进行适配和优化,确保生成内容与预期目标高度一致。将生成式模型适配到特定的领域、用例和任务非常重要。学习如何使用定制的数据集对多模态生成式 AI模型进行微调,以满足你的业务目标。
此外,随着这些生成式模型变得越来越像人类(重要的是它们要与人类的价值观和偏好对齐,并且输出稳定),基于人类反馈的强化学习(Reinforcement Learning FromHuman Feedback,RLHF)的技术,以使的多模态生成式AI模型有用、诚实、无害(Helpful,Honest,and Harmless,HHH)。RLHF 是更广泛的研究领域--负责任的 AI的一个关键组成部分。
虽然生成式模型包含大量的信息和知识,但它们通常需要使用最新的信息或业务的专有数据进行增强,学习使用外部数据源或API进一步增强生成式模型的方法。
关键步骤:
- 数据预处理:清洗、标注数据集,调整数据分布以符合模型训练需求。
- 模型微调:通过迁移学习或微调技术,使模型更好地适应特定任务。
- 内容对齐:调整模型参数或引入外部知识库,确保生成内容的质量、准确性和合规性。
- 性能增强:采用模型融合、超参数调优等技术,提升模型性能和效率。
4. 评估
评估是验证生成式AI项目效果的重要环节,包括定性和定量两个方面。为了正确地构建生成式AI应用程序,你需要对模型进行大量迭代。所以,建立明确的评估指标和基淮非常重要,这有助于衡量微调的有效性。了解如何评估模型有助于在适配和对齐阶段衡量模型的改进情况,特别是模型与业务目标和人类偏好的契合程度。
关键步骤:
- 自动评估:使用客观指标(如BLEU、ROUGE等)评估生成内容的准确性和流畅性。
- 人工评估:组织专家或用户进行主观评价,评估内容的创意性、相关性和实用性。
- 对比测试:与竞品或传统方法进行比较,验证项目的优势和不足。
5. 部署与集成
落地实施: 将训练好的模型部署到实际环境中,并与现有系统或应用进行集成。当最终拥有一个经过良好调整和对齐的生成式模型时,就可以部署该模型以进行推理,并将其集成到应用程序中。需要了解如何优化模型以进行理,更好地利用计算资源,减少推理延迟,并更好地服务用户

使用 Amazon SageMaker endpoint部署模型,该服务对基于AWS Inferentia 计算实例的生成式模型的推理任务进行了专门优化。SageMaker endpoint具有高度可扩展性、容错性和可定制性,提供了灵活的部署和扩展选项,如 A/B 测试、影子部署和自动伸缩,是服务生成式模型的绝佳选择。
关键步骤:
- 环境搭建:配置服务器、数据库等基础设施,确保满足模型运行要求。
- 模型部署:将模型转换为可部署的格式,并部署到指定位置。
- 系统集成:将AI系统与业务流程、用户界面等集成,确保顺畅交互。
- 性能测试:在真实环境中测试系统的稳定性和性能,确保满足业务需求。
6. 监控
项目上线后,持续的监控和反馈是保持系统高效运行的关键。与任何生产系统一样,应该为生成式AI应用程序的所有组件设置适当的指标收集和监控系统。可以使用Amazon CloudWatch和Amazon CloudTrail 监控在 AWS上运行的生成式 AI应用程序,从 AWS控制台或AWS软件开发工具包(SoftwareDevelopmentKit,SDK)中访问并与每个 AWS 服务集成,包括 Amazon Bedrock,实现生成式 AI的全托管服务。
关键步骤:
- 性能监控:实时监控系统运行状态,包括响应时间、吞吐量、错误率等指标。
- 用户反馈:收集用户反馈,了解系统在实际应用中的表现和用户需求变化。
- 模型迭代:基于监控数据和用户反馈,不断优化模型,提升系统性能和用户体验。
- 安全合规:确保系统符合数据保护、隐私安全等法律法规要求。
总之,生成式AI项目的全生命周期管理是一个复杂而系统的过程,需要跨学科的知识和团队协作。本文详细探讨了生成式 AI 项目的生命周期,包括从项目的启动、规划、执行到监控和收尾的各个阶段,分析了每个阶段的关键活动、技术挑战和解决方案,并以AWS云服务为例介绍,旨在为从事生成式 AI 项目的团队提供全面的指导。

