
- 1一文弄懂如何创建并使用Kafka生产者_kafka创建生产者not vaild
- 2QT实现一个智能家居系统,包括温湿度、红外遥控、光照全部代码实现
- 3【Spring Cloud】微服务日志收集系统-ELK+Kafka_微服务日志系统
- 4Centos7 docker-machine 部署docker主机 docker服务启动失败_error creating machine: error running provisioning
- 5python基本语法
- 6OpenCV-Python(14):图像几何变换_python opencv 图像变换
- 7信创云转型合集|百家行业用户基于超融合的信创转型实践和方案解读_信创云超融合探讨和实践
- 8c# 窗体应用程序中解析json格式_c#窗体展示json文件数据
- 9PostgreSQL中根据时间段范围查询数据,如19:29:10到20:29:10范围内的数据,排除年月日_pgsql 查询指定时期范围
- 10《动手学ROS2》8.1URDF统一机器人建模语言_ros2 urdf meshes
CosyVoice 实测,阿里开源语音合成模型,3s极速语音克隆,5分钟带你部署实战_cosyvoice 合成语音 速度慢
赞
踩
前段时间给大家介绍了阿里最强语音识别模型:
SenseVoice 实测,阿里开源语音大模型,识别效果和效率优于 Whisper
今天,它的姊妹篇来了:语音合成模型 CosyVoice,3秒极速复刻声音。
这两,堪称语音对话的完美搭档:
- SenseVoice 专注语音识别、情感识别和音频事件检测
- CosyVoice 专注语音合成,支持多语言、音色和情感控制。
能干什么?
只要是人机交互的应用场景,它都能顶。比如语音翻译、语音对话、互动播客、有声读物等。
本次分享,就带大家来体验一番,并在本地部署起来,方便随时调用。
1. CosyVoice 简介
CosyVoice 的亮点总结:
- 只需3到10秒的音频样本,便能够复刻出音色,包括语调和情感等细节;
- 支持富文本和自然语言输入实现对情感和韵律的精细控制,使得合成语音充满感情色彩;
- 可以实现跨语种的语音合成。
官方共提供了三个版本的模型:
- 基座模型 CosyVoice-300M,支持 3s 声音克隆;
- 经过SFT微调的模型 CosyVoice-300M-SFT,内置了多个训好的音色;
- 支持细粒度控制的模型 CosyVoice-300M-Instruct,支持支持富文本和自然语言输入。
从模型架构图上,可以看出,文本输入侧,支持三种类型的输入。
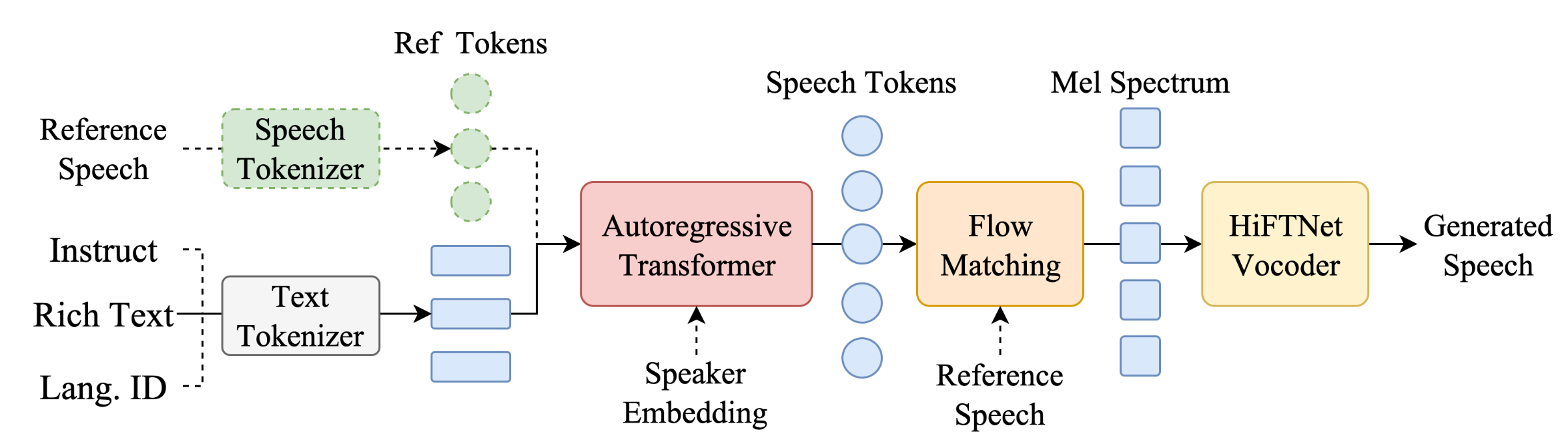
最近大火的 ChatTTS 对比,CosyVoice 在内容一致性上更优,且少有幻觉、额外多字。不得不说,CosyVoice 很好地建模了文本中的语义信息,达到了与人类发音相当的水平。
2. 在线体验
操作比较简单,多点一点就熟悉了~
对于开发者而言,一个好的工具,自然是要能够随时调用的,接下来我们就聊聊如何把它部署成一个服务,方便集成到的你的应用中去。
3.本地部署
本打算采用 ModelScope 的 GPU 实例进行演示,不过安装conda环境出现各种问题,最终还是弃用了。
今天给大家推荐一个云 GPU 厂商,新人注册送 100 点算力,还没使用过的小伙伴赶紧去薅羊毛:驱动云注册
virtaicloud 不仅是新人福利诚意满满,而且远程连接非常方便。此外,不用担心你的数据丢失:
- 项目空间中,
/gemini/code中的文件,会持久保存; - 只要将当前环境采用 dockerfile 构建为新镜像,项目依赖就会持久保存。
3.1 申请云实例
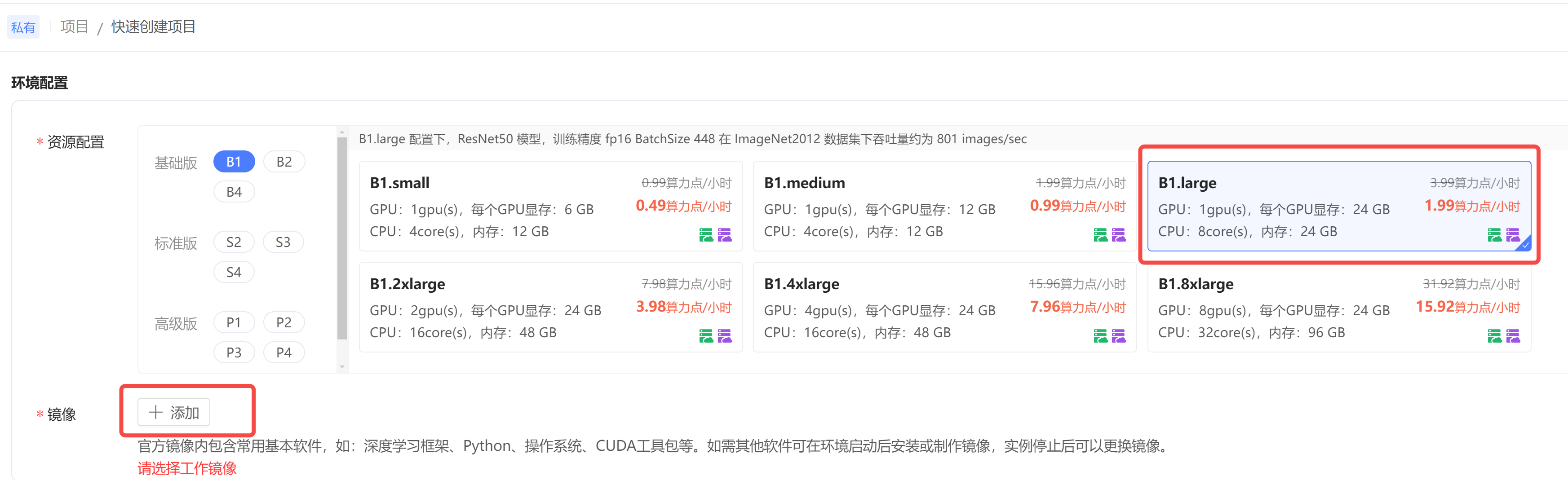
注册成功后,点击快速创建项目。
step1: 资源配置:选择一张 6G 的显卡就够
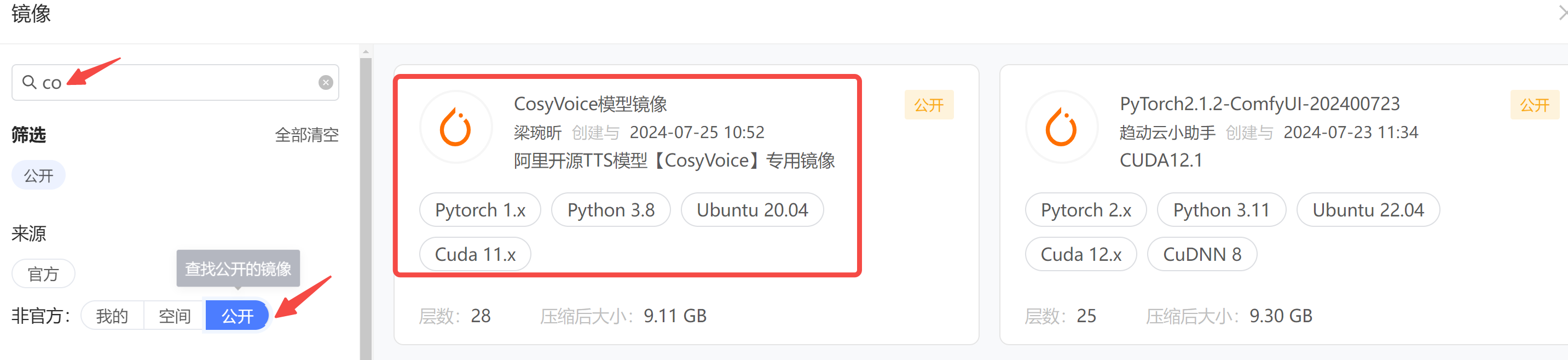
step2: 选择镜像,社区已有小伙伴做好了 CosyVoice 的镜像,拿来用就行,搜索框输入 cosy,从公开镜像中查找。
step3: 数据配置,社区已有小伙伴上传了 CosyVoice 的模型,赶紧挂载进来,否则接下来下载模型你会很痛苦(太慢了 本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/天景科技苑/article/detail/967261
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

