
- 1计算机网络:IP 协议_计算机网络 ip协议
- 2Android Wifi调试_wifi调试安全吗
- 3ATT&CK红队评估实战靶场(二)_att&ck红队评估实战靶场二
- 4【kali】kali安装docker环境_kali ca
- 51、移动机器人软硬件组成_自主移动机器人包含哪些部分
- 6回溯算法以及其模板_回溯算法模板
- 7c语言中的宏函数及c++的内联函数及auto及NULL
- 8Java中常见的几种数据结构_栈( stack)是限制插入和删除只能在一个位置上进行的表,该位置是表的末端,叫做栈顶
- 9Python爬虫网络实践:去哪儿旅游数据爬取指南_去哪儿旅游数据爬虫
- 10借助免费AI艺术平台生成头像_ai头像生成
【Python学习笔记】:Python爬取音频_python 音频 爬虫
赞
踩
【Python学习笔记】:Python爬取音频
背景前摇(省流可以不看):
人工智能公司实习,好奇技术老师训练语音模型的过程,遂请教,得知训练数据集来源于爬取某网页的音频。
很久以前看B站@同济子豪兄的《两天搞定图像识别毕业设计》系列,见识到了(祖传代码)爬虫爬取大量图片制作训练数据集的能力,然后我就想到,我之前学的BeautifulSoup和Scrapy都是爬网页文本的,我还从来没有写代码成功且专门爬过视频和图片的经验,那正好学一下,以后没准也可以拿来做自己的数据集,这次就先搞定音频的爬取吧。
原理讲解这部分,我认为下面这个视频无懈可击——言简意赅,简明扼要,时长感人,堪称吾辈楷模!!
【python】几分钟教你如何用python爬取音频数据:
https://www.bilibili.com/video/BV1mL4y1N7eV/?spm_id_from=333.1007.top_right_bar_window_custom_collection.content.click&vd_source=cdfd0a0810bcc0bcdbcf373dafdf6a82
传送门












网址后缀只有mp3

————————————————————————————————
原理明白了,下面进入实操细节:我承认我选这个教程的很大原因,是被“突破网站反爬”几个字吸引了。
突破网站反爬-制作简易的音乐播放器【Python】:https://www.bilibili.com/list/watchlater?oid=1556173520&bvid=BV1e1421b73k&spm_id_from=333.1007.top_right_bar_window_view_later.content.click
传送门
老师这个清晰的板书风格,爱了。


意外收获找个歌曲的宝藏网站一枚:歌曲宝,能在线听也能下载
(说真的,感觉有这网站在都不用劳动爬虫大驾,笑死)
https://www.gequbao.com/
传送门————————————————————————————————
思路梳理:




————————————————————————————————
第一部分,单首歌曲采集:
F12/右键——检查,选择”网络“模块,然后点击页面上的刷新按钮,让网页数据重新加载出来。

右边示范的这个链接还是歌曲本身:

下面这个play_url就是我们需要的歌曲播放链接了:
 这个有点难点到,先点play_url下面的数据内容,然后再选Headers。
这个有点难点到,先点play_url下面的数据内容,然后再选Headers。

然后就可以看到数据的标头了——可以得知请求网站,请求方法和请求参数等等都可看到。

数据包地址Request URL: https://www.gequbao.com/api/play_url?id=402856&json=1

————————————————————————————————
思路分析清楚后,就该到代码实践步骤了:


主要使用的是请求标头里面的参数,比如这个User-Agent:
user-agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36
插入代码后要注意写成字典形式:

# 模拟浏览器
headers = {
#User-Agent 用户代理,表示浏览器基本身份信息
'User-Agent' :'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
- 1
- 2
- 3
- 4
- 5

# 请求网址
url = 'https://www.gequbao.com/api/play_url?id=402856&json=1'
- 1
- 2


————————————————————————————————
经过以上步骤,可以成功获取一个格式类似json的结果:

#导入数据请求模块 import requests '''发送请求''' # 模拟浏览器 headers = { #User-Agent 用户代理,表示浏览器基本身份信息 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36' } # 请求网址 url = 'https://www.gequbao.com/api/play_url?id=402856&json=1' # 发送请求 response = requests.get(url=url, headers=headers) '''获取数据''' #获取响应json数据——字典数据 json_data = response.json() print(json_data)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
输出:
{'code': 1, 'data': {'url': 'https://sy-sycdn.kuwo.cn/edde772eaab20af3f141ec9f2561df44/66912c2a/resource/n2/70/55/756351052.mp3?bitrate$128&from=vip'}, 'msg': '操作成功'}
- 1
通过键值对取值的方式,一层一层获得歌曲的播放链接:

'''获取数据'''
#获取响应json数据——字典数据
json_data = response.json()
'''解析数据'''
#提取歌曲链接(键值对取值)
play_url = json_data['data']['url']
print(json_data)
print(play_url)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
 ————————————————————————————————
————————————————————————————————
下一步是保存数据,现在我们拿到的只是一个链接地址,要想保存到本地,要向这个链接发出请求获取音频内容。
写入数据这部分要用到os这个包,并且写之前要判断是否存在目标路径,如果没有的话会报错。

UP老师为了直观省事(毕竟这个程序很简单)直接指定文件夹的名字并且把存在与否的逻辑判断放在了最开头,但我见的更多的写法是和文件操作放在一起写,比如执行读写操作之前判断一下有无此目录,如果没有的话再建立。

#导入数据请求模块 import requests #导入文件操作模块 import os '''自动创建保存音频的文件夹''' file = 'music' #判断文件夹是否存在 if not os.path.exists(file): #创建文件夹 os.mkdir(file) '''发送请求''' # 模拟浏览器 headers = { #User-Agent 用户代理,表示浏览器基本身份信息music 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36' } # 请求网址 url = 'https://www.gequbao.com/api/play_url?id=402856&json=1' # 发送请求 response = requests.get(url=url, headers=headers) '''获取数据''' #获取响应json数据——字典数据 json_data = response.json() '''解析数据''' #提取歌曲链接(键值对取值) play_url = json_data['data']['url'] print('json_data = ',json_data) print('play_url = ',play_url) '''保存数据''' #对于音频链接发送请求,获取音频内容 music_content = requests.get(url = play_url, headers = headers).content #数据保存 with open('music\\晴天.mp3', mode = 'wb') as f: #写入数据 f.write(music_content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
执行完这一步以后,打开本地文件夹可以看到《晴天》这首歌已经顺利存到本地了,并且点击可以电脑上播放:


到这里单首歌曲的采集就结束了,可以说是给了我很大信心,但我还不够满意,因为要做人工智能音频数据集的话需要大量爬取音频数据,之前问过做分布式Python的技术老师用的是Scrapy,但我一下子没找到用Scrapy或者其他框架大规模深度爬取数据的好例子,先把手上这个学完吧。
截至第一步的完整代码内容:
#导入数据请求模块 import requests #导入文件操作模块 import os '''自动创建保存音频的文件夹''' file = 'music' #判断文件夹是否存在 if not os.path.exists(file): #创建文件夹 os.mkdir(file) '''发送请求''' # 模拟浏览器 headers = { #User-Agent 用户代理,表示浏览器基本身份信息music 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36' } # 请求网址 url = 'https://www.gequbao.com/api/play_url?id=402856&json=1' # 发送请求 response = requests.get(url=url, headers=headers) '''获取数据''' #获取响应json数据——字典数据 json_data = response.json() '''解析数据''' #提取歌曲链接(键值对取值) play_url = json_data['data']['url'] print('json_data = ',json_data) print('play_url = ',play_url) '''保存数据''' #对于音频链接发送请求,获取音频内容 music_content = requests.get(url = play_url, headers = headers).content #数据保存 with open('music\\晴天.mp3', mode = 'wb') as f: #写入数据 f.write(music_content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
————————————————————————————————
第二部分:搜索下载:
老师讲到这部分已经有点批量采集的意思了,要分析链接的变化规律,要说这个我可就不困了。
选择另一首歌曲《稻香》,如法炮制,播放歌曲,刷新检查界面的Network下属Media栏,一样的办法找到url。(如果发现没有歌曲的链接出现的话,应该是没有播放歌曲)


正好老师的视频也在讲这个播放一下出链接的解决办法,甚至还让不出来就拉进度条,哈哈:

再故技重施找链接:

通过对比,发现不同的歌曲主要是id不同。只要能把所有的歌曲ID都拿到,那就可以采集全部的歌曲。(好耶!音频训练数据集不是梦?!)
————————————————————————————————

那么关键的id该怎么找呢?老师告诉我们,和浏览器上方网址导航栏里面是一样的:

而导航栏这个链接,是搜索出的集合页面“下载”按钮点进来的:

在搜索页面搜一下单首歌曲的id:


发现这一页歌名,作者,id都有:

那么要抓取的请求网址自然也是这个页面的Request URL了:

Request URL: https://www.gequbao.com/s/%E5%91%A8%E6%9D%B0%E4%BC%A6


————————————————————————————————
老师的总结:三种获取内容的方式



前面我们根据链接直接下载歌曲文件的时候,就用的content方法,直接获取歌曲的二进制文件并保存。


最开始获取歌曲链接的时候就是返回的json格式:
json_data = {'code': 1, 'data': {'url': 'https://sy-sycdn.kuwo.cn/6dafd418ad3ba5d48a41948554b060df/669147fa/resource/n2/70/55/756351052.mp3?bitrate$128&from=vip'}, 'msg': '操作成功'
- 1
(另外提一句,我实习做内容安全方向的AI训练数据标注师的时候,每天审核的文本训练集就是json文件,所有数据都有整齐划一的格式,主题、回答什么的排得清清楚楚,甚至还是放在VSCode里打开删改。然后根据技术老师的答疑这些训练数据很多也是爬虫得到的,所以response.json()在文本数据集制作应该会很常用,但如果是训练语音模型、图像识别模型的话,应该response.content会更吃香。)
————————————————————————————————
具体选择用哪种方法呢?要根据获取的目标网页内容决定:
1.这种网页前端,HTML的格式就用获取文本response.text

2.这种花括号包起来的用response.json()

3.二进制音频/视频/图片/文件链接,用response.content

保存代码不是固定的,要看保存成什么样子。
————————————————————————————————




切到元素分栏,鼠标选择找到CSS标签:


看一下查到的84条row标签,发现首尾几条代表的并不是我们想要的歌曲,所以要对返回的列表做切片。
————————————————————————————————
找到a标签并且提取歌名文字内容以后,发现歌名的后面还跟着很多空格:

使用**strip()**方法,去掉歌名左右两边的空格。
 ————————————————————————————————
————————————————————————————————
提取歌曲id要注意,id并不是文字内容,而是标签里面的属性,要用 attr(属性名称) 来获取。

这块是有一点绕,一会是文字一会是属性的,对HTML比较熟的看起来要容易一些,或者对着老师的教程多看几遍,自己多尝试,不懂的问问Kimi。


歌手也如法炮制——找到标签,提取文本信息:

将之前请求网址的格式更换为通用匹配id的形式:

保存的格式也换成歌名和歌手通用的形式:

————————————————————————————————
批量采集的思路捋一捋:先通过单首歌曲的链接和浏览器网址对比,发现每首歌曲有id作为唯一辨识符,那么只要知道所有id,就可以爬取所有歌曲。
(我想如果对网页很熟了,知道要找歌曲id来下载,应该可以直接进行批量爬取,不需要再拿单首歌曲测试)
于是就去搜索页面这种有大量id的网页,通过检查HTML代码的方法,找到了要薅羊毛的这个大集合目标网址的HTML代码,然后写爬虫获取网页源代码,通过CSS解析出当中隐藏的一大堆歌名、id等信息,最后再拿这一大堆id组合成完整歌曲链接,去爬想要的一大堆歌曲并且保存到本地。
————————————————————————————————
不知道为什么,我下着下着就报了一个bug,看原网页这也不是当前目录的最后一首歌(而且似乎也不是按顺序下载的)。


仔细看老师的下载列表,跟我一样也是到这首歌就停了。

询问了一下Kimi,我感觉可能是有的歌曲解析失败无法提供播放链接造成的,之前在这个网站试着搜了一些想听的歌,结果有好几首无法播放,说《解析失败》。

加上Kimi提供的这段代码以后,确实程序容错性变高了,下载到本地的歌曲明显多了,也不会因为中间出问题而中断。

而且我们还能看到,出bug的是这首《霍元甲》:

这首歌到网站里面点开发现是能正常播放的,那就不是音源找不到的问题,我们把错误给Kimi看一下——原来是歌曲名太刁钻了。


按照Kimi的提示改一下:

但我试过以后还是报这个刁钻古怪的问题……看网页源代码也看不出bug

那看来是不得不使用Kimi建议的另一个方法——清理一下文件名了:

这次奏效了!成功把《霍元甲》这首歌爬下来了,而且爬取效果比我想得要好,甚至电影题目都还在!!


这段代码成功顺利跑完了爬取流程,再没有报错!起立欢呼!!

#导入数据请求模块 import requests #导入文件操作模块 import os #导入数据解析模块 import parsel import re def clean_filename(filename): # 替换文件名中的特殊字符为下划线 return re.sub(r'[<>:"/\\|?*\r\n]', '_', filename) '''自动创建保存音频的文件夹''' file = 'music' #判断文件夹是否存在 if not os.path.exists(file): #创建文件夹 os.mkdir(file) '''发送请求''' # 模拟浏览器 headers = { #User-Agent 用户代理,表示浏览器基本身份信息music 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36' } #搜索网址 link = 'https://www.gequbao.com/s/%E5%91%A8%E6%9D%B0%E4%BC%A6' # 发送请求 link_response = requests.get(url=link, headers=headers) #获取响应文本数据 html = link_response.text '''解析数据''' #把html字符串数据转换为可解析对象 selector = parsel.Selector(html) #第一次提取,提取所有歌曲信息所在div标签类名row rows = selector.css('.row')[2:-1] #for循环遍历,提取列表里面元素 for row in rows: '''提取每一条歌曲具体信息''' #提取歌名 SongName = clean_filename(row.css('a.text-primary::text').get().strip()) #提取id SongId = row.css('a.text-primary::attr(href)').get().split('/')[-1] #提取歌手 singer = row.css('.text-success::text').get().strip() print(SongName, SongId, singer) # 请求网址 url = f'https://www.gequbao.com/api/play_url?id={SongId}&json=1' # 发送请求 response = requests.get(url=url, headers=headers) # 检查响应状态码 if response.status_code == 200: try: '''获取数据''' # 尝试获取响应json数据 json_data = response.json() print('json_data = ', json_data) except ValueError: # 如果解析JSON失败,打印原始响应文本 print('Failed to parse JSON from response text:') print(response.text) else: print('Failed to retrieve data, status code:', response.status_code) '''解析数据''' #提取歌曲链接(键值对取值) play_url = json_data['data']['url'] print('json_data = ',json_data) print('play_url = ',play_url) '''保存数据''' #对于音频链接发送请求,获取音频内容 music_content = requests.get(url = play_url, headers = headers).content #数据保存 # 使用原始字符串来避免转义字符问题 with open(f'music\\{SongName}-{singer}.mp3', mode='wb') as f: #写入数据 f.write(music_content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
————————————————————————————————————————————
接下来就进入第三部分:搜索歌曲
老师使用了一个比较陌生的新库prettytable,这会打印出很整齐的表格:
(操作过程比较零碎,要多看慢慢跟)
这个prettytable我在命令行里装了好几回,明明都requirements satisfied了,一跑还是报没有这个module,在jupyter里面单独又装了一次,这回正常了。


(老师给的建议是最好把这块代码重构写成函数,不然很麻烦。)
能实现输入汉字找到对应歌曲的原因我猜测应该是和这个网页链接有关,能匹配上歌曲的搜索界面网页关键词,然后获取这个网页的HTML代码,有了歌曲id就能指哪打哪:
这次我们就可以随心所欲输入关键字和目标序号,随心所欲下载自己喜欢的歌曲啦:

搜索部分完整代码:
#导入数据请求模块 import requests #导入文件操作模块 import os #导入数据解析模块 import parsel #导入制表模块 from prettytable import PrettyTable import re def clean_filename(filename): # 替换文件名中的特殊字符为下划线 return re.sub(r'[<>:"/\\|?*\r\n]', '_', filename) '''自动创建保存音频的文件夹''' file = 'music' #判断文件夹是否存在 if not os.path.exists(file): #创建文件夹 os.mkdir(file) '''发送请求''' # 模拟浏览器 headers = { #User-Agent 用户代理,表示浏览器基本身份信息music 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36' } #输入搜索内容 key = input('请输入搜索内容:') #搜索网址 link = f'https://www.gequbao.com/s/{key}' # 发送请求 link_response = requests.get(url=link, headers=headers) #获取响应文本数据 html = link_response.text '''解析数据''' #把html字符串数据转换为可解析对象 selector = parsel.Selector(html) #第一次提取,提取所有歌曲信息所在div标签类名row rows = selector.css('.row')[2:-1] #实例化对象 tb = PrettyTable() #添加字段名 tb.field_names = ['序号', '歌名', '歌手'] #自定义变量 page = 0 #创建空列表 info_list = [] #for循环遍历,提取列表里面元素 for row in rows: '''提取每一条歌曲具体信息''' #提取歌名 SongName = clean_filename(row.css('a.text-primary::text').get().strip()) #提取id SongId = row.css('a.text-primary::attr(href)').get().split('/')[-1] #提取歌手 singer = row.css('.text-success::text').get().strip() #print(SongName, SongId, singer) #添加数据存在字典中 dit = { '歌名':SongName, '歌手':singer, 'ID':SongId, } #给info_list添加元素 info_list.append(dit) #添加内容 tb.add_row([page, SongName, singer]) page += 1 print(tb) num = input('请输入你要下载的歌曲序号:') #获取歌曲ID music_id = info_list[int(num)]['ID'] # 请求网址 url = f'https://www.gequbao.com/api/play_url?id={music_id}&json=1' # 发送请求 response = requests.get(url=url, headers=headers) # 检查响应状态码 if response.status_code == 200: try: '''获取数据''' # 尝试获取响应json数据 json_data = response.json() print('json_data = ', json_data) except ValueError: # 如果解析JSON失败,打印原始响应文本 print('Failed to parse JSON from response text:') print(response.text) else: print('Failed to retrieve data, status code:', response.status_code) '''解析数据''' #提取歌曲链接(键值对取值) play_url = json_data['data']['url'] print('json_data = ',json_data) print('play_url = ',play_url) '''保存数据''' #对于音频链接发送请求,获取音频内容 music_content = requests.get(url = play_url, headers = headers).content #数据保存 # 使用原始字符串来避免转义字符问题 with open(f'music\\{info_list[int(num)]["歌名"]}-{info_list[int(num)]["歌手"]}.mp3', mode='wb') as f: #写入数据 f.write(music_content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
效果如图所示:

————————————————————————————————————————————
然后我想试着爬取一个某知名的有声书网站,但发现很难搜到搜索界面的Request URL。


为了解决这个问题我也查了一些教程:
Python爬虫实战案例之爬取喜马拉雅音频数据详解:https://www.jb51.net/article/201564.htm
传送门
在观看老师的操作,和我自己的操作结果对比发现,现在的网址跟以前有些不一样了。

老师的视频是23年上传的,看下面截图,他找到的播放链接和上面歌曲宝一样,只有id不同。

但等我真正自己(今天是2024年7月15日)去找的时候,发现现在链接大不一样了:

Request URL: https://a.xmcdn.com/download/1.0.0/group30/M02/3F/2A/wKgJXlmBkw2zg0LjAKntzSZLubI803-aacv2-48K.m4a?sign=132430e114a56804799c6cc645b6d251&buy_key=www2_e039a2bf-161311236×tamp=1721007591951000&token=8248&duration=1377
现在的链接看起来要复杂的多,变化也更多,不仅仅是一个简单的id替换就能搞定的。
然后问了一下Kimi,发现可能用到了动态生成:

目前我还只知道怎么爬简单的换id的网址,这种动态的问题对我来说有点太复杂了,不过可以作为以后一个进阶的学习方向。
本次我跟着视频教程写的代码也会发到CSDN资源库上,有需要的读者可以下载:

————————————————————————————————————————————
一些搜索过程中遇到的其他好帖子也发在这里一起分享出来:
解析Python爬虫常见异常及处理方法:https://zhuanlan.zhihu.com/p/650309507
添加链接描述

Python常见问题-如何爬取动态网页内容:https://www.bilibili.com/video/BV1of4y15736/?spm_id_from=333.337.search-card.all.click&vd_source=cdfd0a0810bcc0bcdbcf373dafdf6a82
添加链接描述
这个视频主要教授的是动态网页的爬取,和之前找的Media栏目不同,这次主要找的是JS和Fetch/XHR目录下的内容。
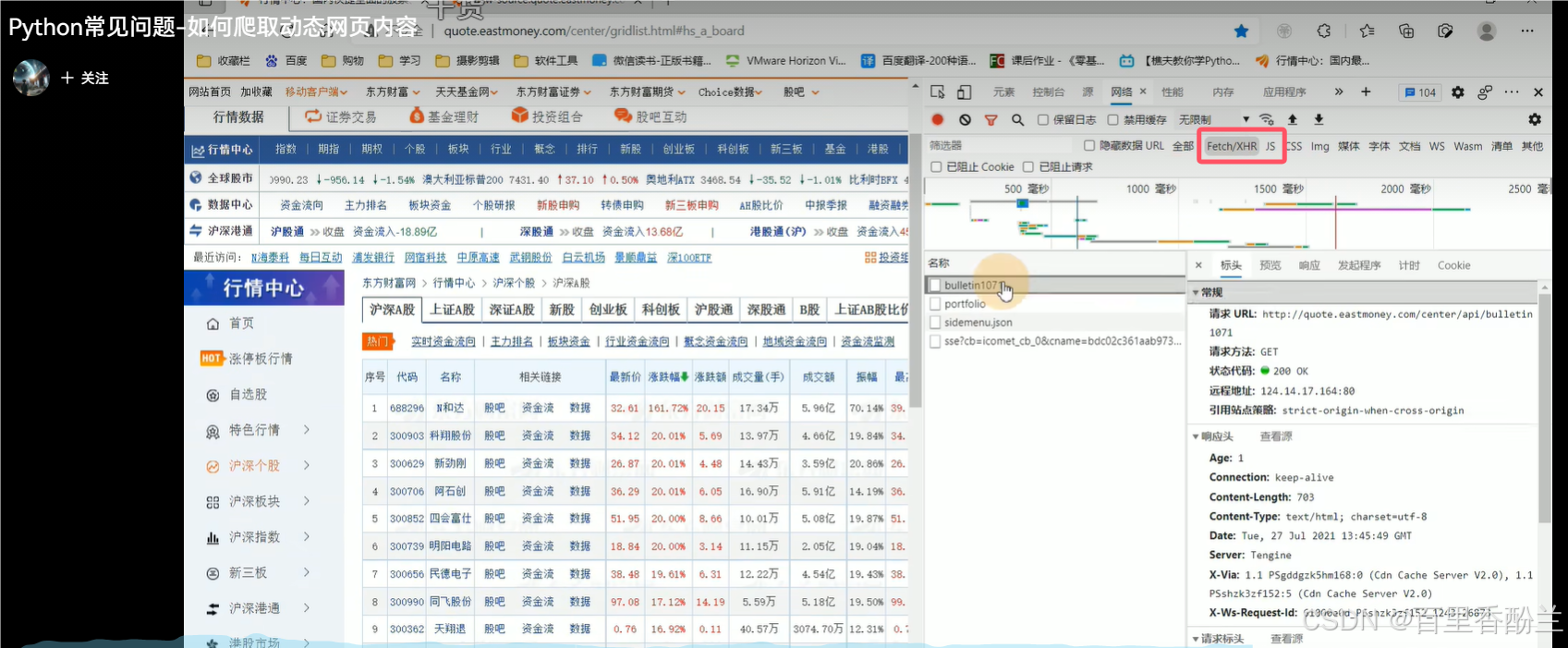
有个弹幕说的好:找数据在那个包里不难 难的是找出数据包链接的规律从而一次爬多页的数据


