
- 1android jni Log
- 2基于neo4j的机械设备知识图谱问答展示系统_给电机及拖动基础知识问答网页系统(用python、neo4j做的)画一个主程序流程图和子
- 3我的保研之旅——北京航空航天大学、北理工、南大_北航美赛s加分不
- 4c++ string类构造函数(string变量与字符相结合)_c++如何把一个字符串和一个string变量连接
- 5mysql redis双写_Redis Mysql 双写一致性问题
- 6【数据库】SQL Server 数据库、附加数据库时出错。有关详细信息,请单击“消息”列中的超链接_附加数据库时出错,请单击消息中的超链接
- 7Redis的SCAN命令_setscan
- 8yolov5+Deepsort目标检测加目标跟踪算法(yolo版本更改为6.1版本)_yolov5 6.1 deepsort
- 9Spire.Presentation[PPT/PPTX] 8.1.2 for Java Crack_spire.presentation需要安装office吗
- 10排序算法-选择排序_筛选法调整堆
C++ 从大数据SPARK框架的DAG引擎,再论有向无环图(DAG)的拓扑排序_spark dag
赞
踩
公众号:编程驿站 更多好文等你来
给大学生讲解SPARK时,说spark相比其它的大数据框架,其运行速度更快,是其显著的特点之一。之所以运行速度快,其原因之一因其使用先进的DAG(Directed Acyclic Graph,有向无环图)执行引擎。SPARK提供了名为RDD(弹性分布式数据集(Resilient Distributed Dataset)的简称)抽象的数据集。DAG引擎用来保证RDD数据集之间依赖的有序性、可靠性。
不理解DAG具体为何物以及其底层原理,并不妨碍使用SPARK,使用者只需要调用其提供的API,用于分析处理不同领域的数据便可。但是,如果能理解DAG的底层结构,对理解和学习SPARK将会有质的提升。
对高层建筑和底层地基之间的逻辑关系的理解能建立对事物的新认知。
2.DAG
2.1 基本概念
什么是DAG?
DAG是图结构中的一种,称为有向无环图。有向说明图中节点之间是有方向的,无环指图中没有环(回路),意味着从任一顶点出发都不可能回到顶点本身。如下图:
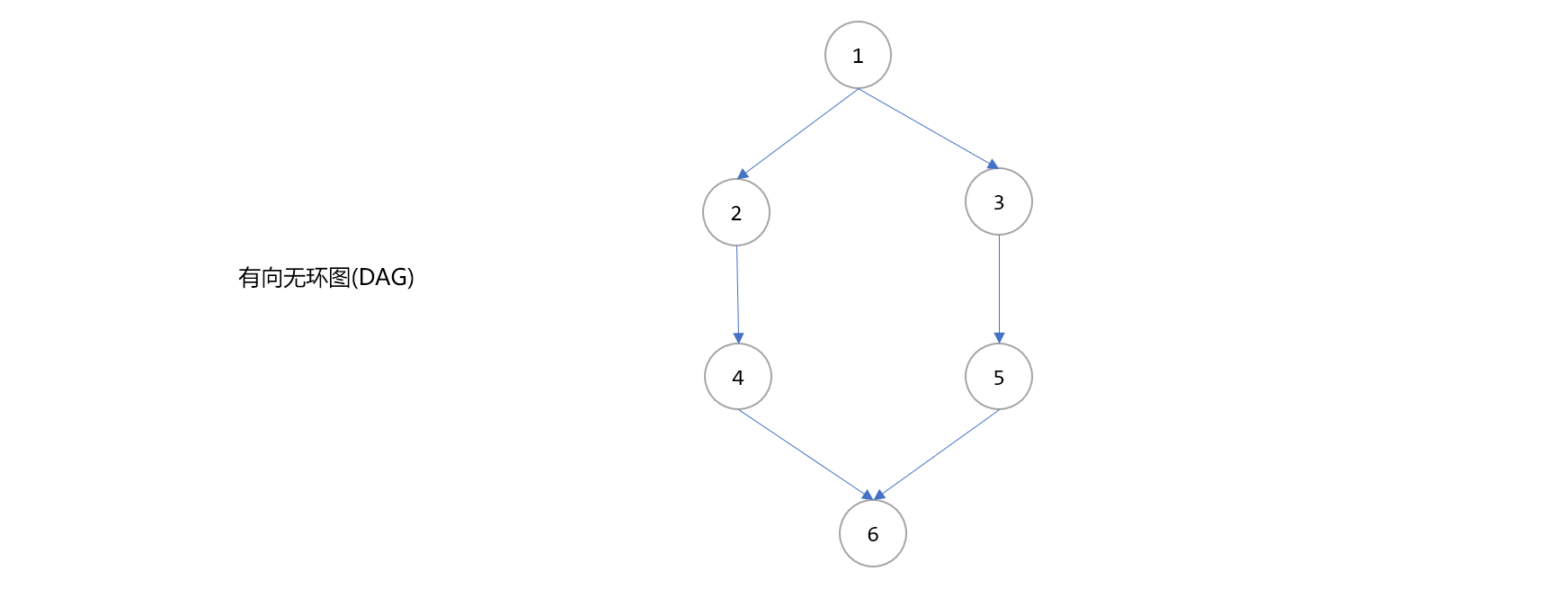
DAG往往用来描述事物之间的依赖关系或工作流中子流程之间的顺序,所以DAG中一定存在入度为0和出度为0的节点。入度为0的节点表示流程的开始,出度为0的节点表示流程的结束。根据工作流的特点,入度为0和出度为0的节点可能不只有一个。
如上图,可以理解为对于整个工作流而言,只有当编号为1的子流程完成后,才可以开始2号和3号子流程,当2号完成后,才能是4号,3号完成后才能5,4、5号完成后才能是6号。最终可以用线性结构描述出来。
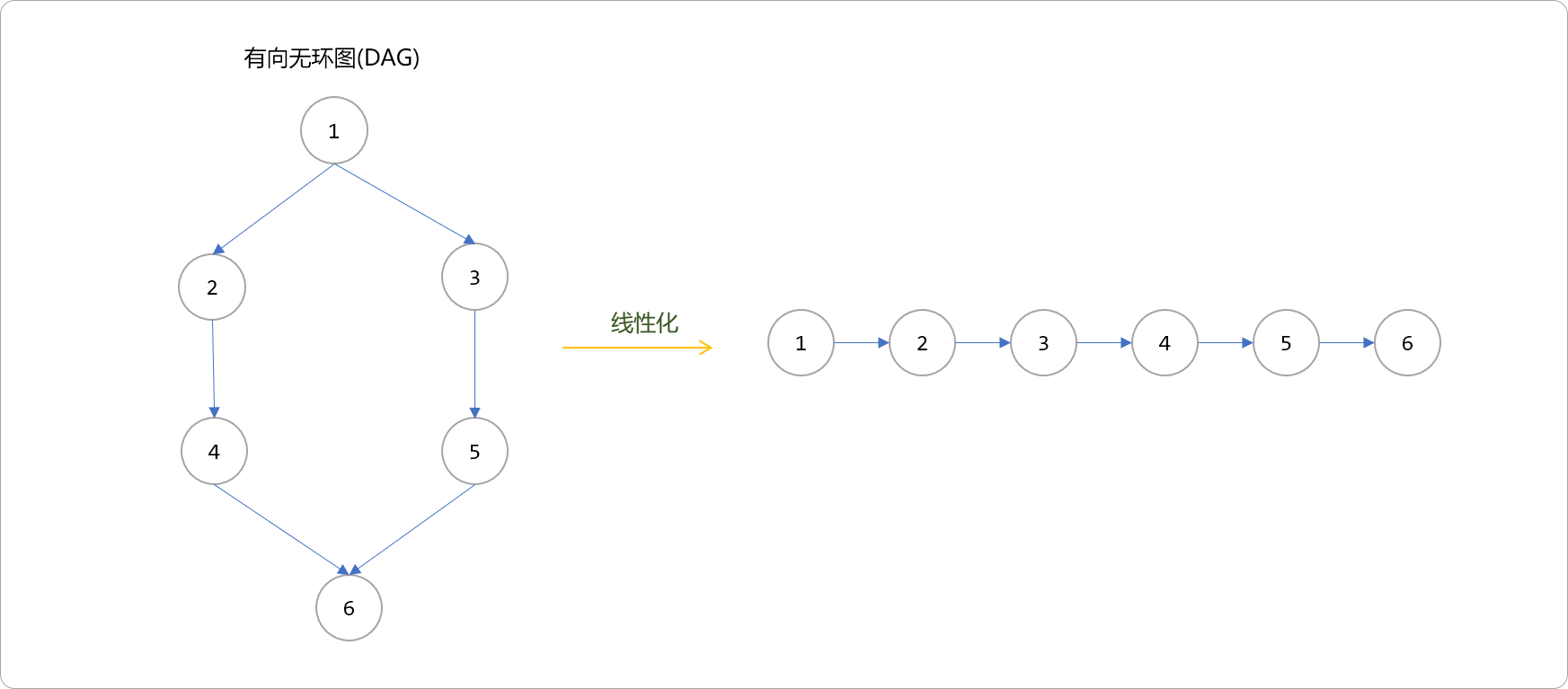
这个过程称为DAG的线性化过程,也称为DAG的拓扑排序,这里的排序并不是指大小上的有序,而是指时间上的有序。因有可能子流程间不存在时间上的依赖性,如上图的2和3以及4和5节点,不存在相互的依赖,所以DAG的拓扑排序并不只有一种可能。如下图中的所有线性化都认为是合法。
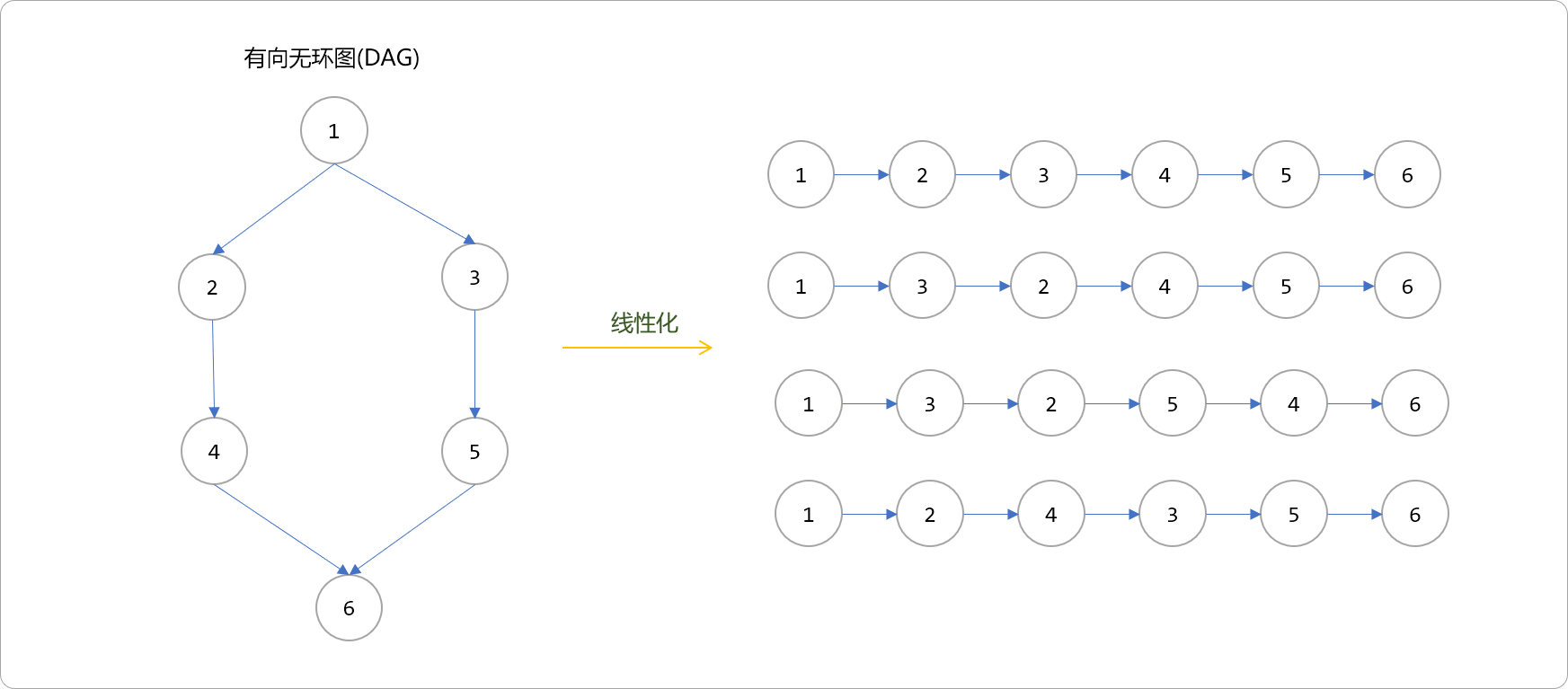
一旦有了工作流的DAG结构图,在设计工作流进程时,则可以引入并行(并发)方案。如上图的2->4和3->5进程可以使用多线程或多进程方案,加快工作流的执行速度,这也是SPARk的DAG引擎能加快处理速度的底层原理。
因是描述工作流中子流程的顺序,显然整个工作流中不能出现环,环的出现,标志着循坏依赖。如下图,2号工作流依赖1号工作流的完成,4号依赖2号工作流的完成,从传递性上讲,

