
- 1微信小程序用户手机号授权获取_微信小程序读取授权信息手机号
- 2MySQL 存储过程_mysql使用存储过程后内存会减少吗
- 3JAVA期末速成库(7)第七、八章
- 4Unity VR 开发教程 OpenXR+XR Interaction Toolkit (二) 手部动画_unityxr教程手部动画
- 5使用vue3+ts+vite从零开始搭建bolg(四):登录_vite+vue3+ts登录界面
- 6IT经理、IT总监、CIO的区别
- 7联合主键和复合主键的区别_联合主键和主键的区别
- 8GitLab数据恢复时的问题对应和常见技巧_gitaly got term
- 9ChatGPT-Next-Web一键部署搭建教学:Github开源+Vercel+API 快速部署
- 10【工具类安装教程】IDEA Ui设计器JFormDesigner_jformdesigner注册机
排序算法-选择排序_筛选法调整堆
赞
踩
选择排序
选择排序的基本思想是:每一趟从待排序的记录中选出关键字最小的记录,按顺序放在已排序的记录序列的最后,直到全部排完为止。
简单选择排序
简单选择排序 (SimpleSelection Sort)也称作直接选择排序。
算法步骤
① 设待排序的记录存放在数组r[1 … n]中。第一趟从r[1]开始,通过n-1次比较,从n个记录中选出关键字最小的记录,记为r[k], 交换r[1]和r[k]。
② 第二趟从r[2]开始,通过n-2次比较,从n-1个记录中选出关键字最小的记录,记为r[k],交换r[2]和r[k] 。
③ 依次类推,第 i 趟从r[i]开始,通过n-i次比较,从n-i+1个记录中选出关键字最小的记录,记为r[k], 交换r[i]和r[k]。
④ 经过n-1趟,排序完成。
void SelectSort(SqList &L)
{ // 对顺序表L做简单选择排序
for(i=1;i<L.length;++i){ // 在L.r[i..L.length]中选择关键字最小的记录
k=i;
for (j=i+1; j<=L.length; ++j)
if(L.r[j].key<L.r[k].key) k=j; // k指向此趟排序中关键字最小的记录
if (k!=i)
{t=L.r[i]; L.r[i]=L.r[k]; L.r[k]=t;} // 交换r[i]与r[k]
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
简单选择排序算法分析
时间复杂度:
记录移动次数,最好情况:0,最坏情况:3(n-1)。
比较次数:无论待排序处于什么状态,选择排序所需进行的“比较”次数都相同
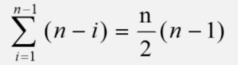
算法稳定性:
简单选择排序时不稳定排序

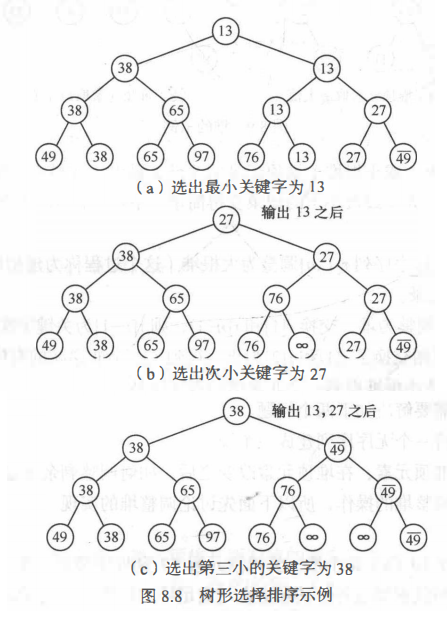
树形选择排序
树形选择排序(Tree Selection Sort), 又称锦标赛排序(Tournament Sort), 是一种按照锦标赛的思想进行选择排序的方法。首先对 n 个记录的关键字进行两两比较,然后在其中 n/2 个较小者之间再进行两两比较,如此重复,直至选出最小关键字的记录为止。
堆排序
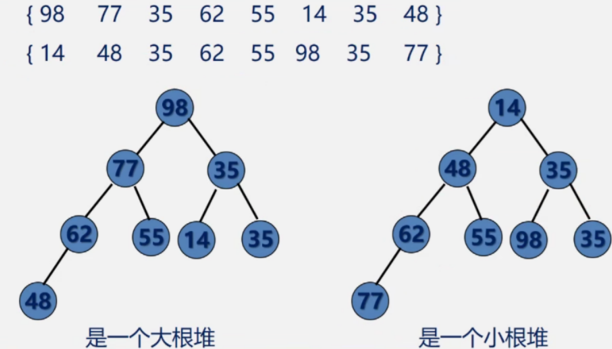
堆的定义
若n个元素的序列{a1 a2 … an}满足

则分别称该序列{a1 a2 … an}为小根堆和大根堆。
从堆的定义可以看出,堆实质是满足如下性质的完全二叉树:二叉树中任一非叶子结点均小于(大于)它的孩子结点。
判断是否是堆
什么是堆排序
若在输出堆顶的最小值(最大值)后,使得剩余n-1个元素的序列重又建成一个堆,则得到n个元素的次小值(次大值)……如此反复,便能得到一个有序序列,这个过程称之为堆排序。
筛选法调整堆
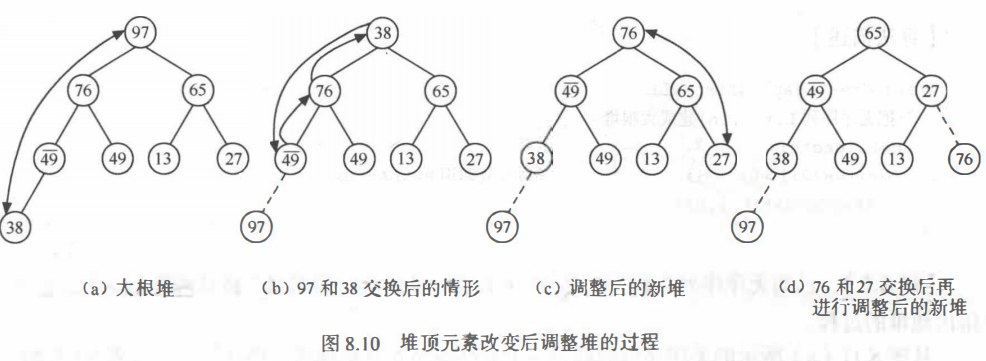
从r[2s]和r[2s+1]中选出关键字较大者,假设r[2s]的关键字较大,比较r[s]和r[2s]的关键字。
① 若r[s].key>= r[2s].key, 说明以r[s]为根的子树已经是堆,不必做任何调整。
② 若r[s].key<r[2s].key, 交换r[s]和r[2s]。交换后,以r[2s+1]为根的子树仍是堆,如果以r(2s]为根的子树不是堆,则重复上述过程,将以 r[2s]为根的子树调整为堆,直至进行到叶子结点为止。
void HeapAdjust(SqList &L,int s,int m)
{ // 假设r[s+1. .m]已经是堆 , 将r[s.. m]调整为以r[s]为根的大根堆
rc=L.r[s];
for(j=2*s; j<=m; j*=2) // 沿key较大的孩子结点向下筛选
{
if(j<m&&L.r[j].key<L.r[j+1].key) ++j; // j为key较大的记录的下标
if(rc.key>=L.r[j].key) break; // rc应插入在位置s上
L.r[s]=L.r[j] ;s=j;
}
L.r[s]=rc; // 插入
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
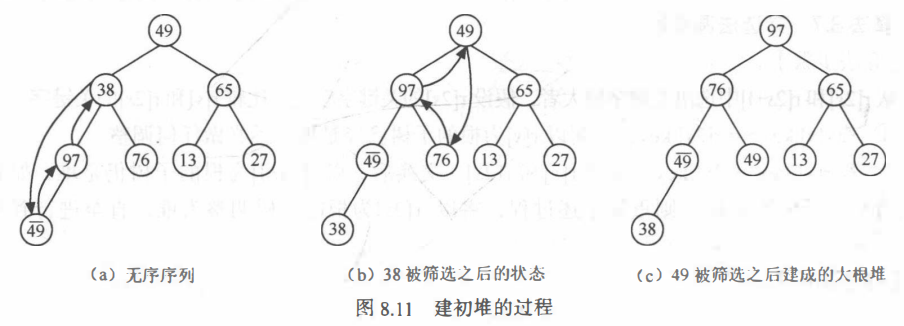
建初堆
对于无序序列 r[1…n] , 从i= n/2开始,反复调用筛选法HeapAdjust (L,i,n), 依次将以r[i],r[i-1], …,r[1]为根的子树调整为堆。
void CreatHeap(SqList &L)
{ // 把无序序列L.r[1..n]建成大根堆
n=L.length;
for(i=n/2;i>O; --i) // 反复调用HeapAdjust
HeapAdjust(L,i,n);
}
- 1
- 2
- 3
- 4
- 5
- 6
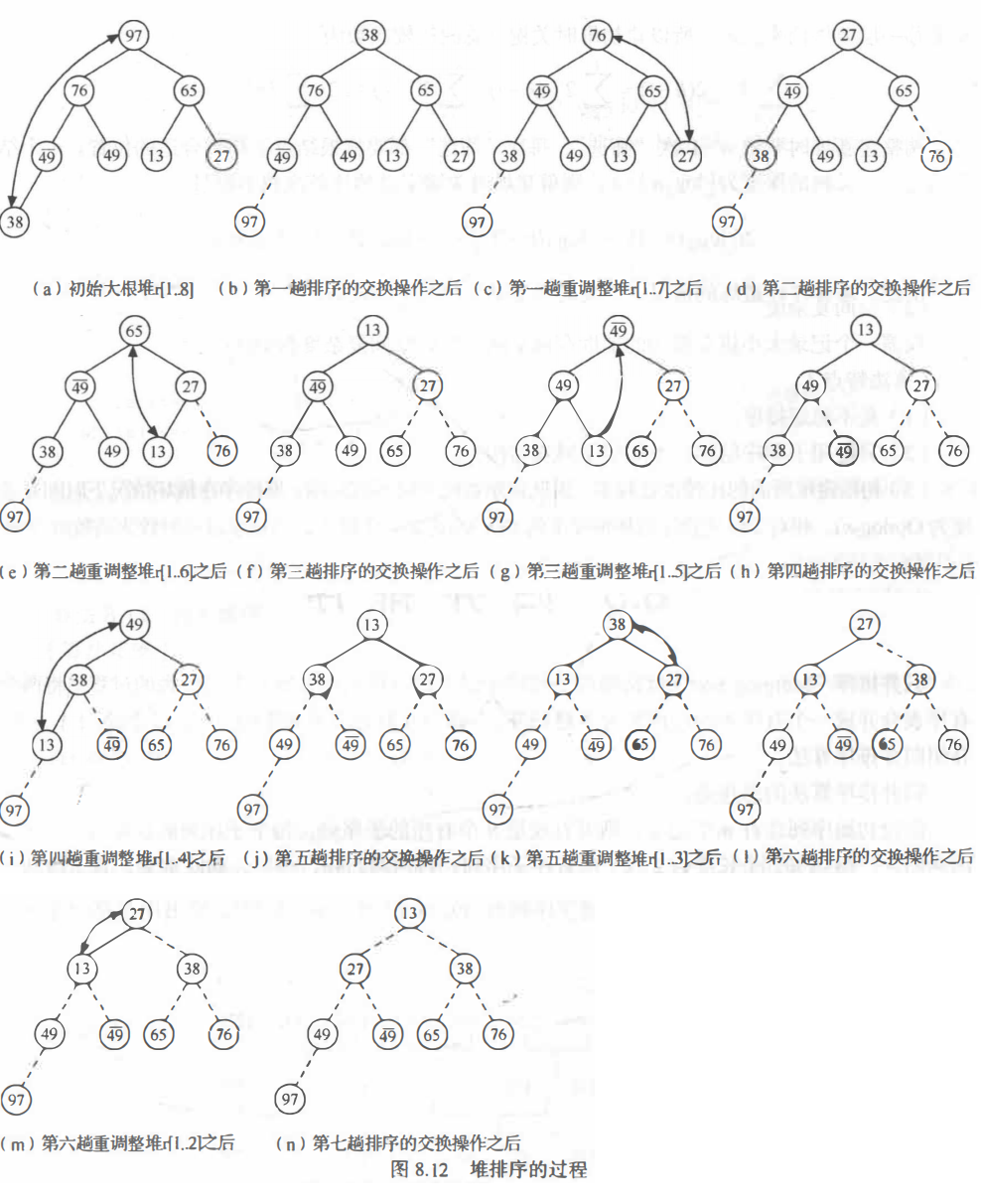
堆排序
若对一个无序序列建堆,然后输出根;重复该过程就可以由一个无序序列输出有序序列。
实质上,堆排序就是利用完全二叉树中父结点与孩子结点之间的内在关系来排序的。
void HeapSort(SqList &L)
{ // 对顺序表L进行堆排序
CreatHeap(L); // 把无序序列L.r[1.. L.length]建成大根堆
for(i=L.length;i>1;--i)
{
x=L.r[1]; // 将堆顶记录和当前未经排序子序列L.r[1..i]中最后一个记录互换
L.r[1] =L.r[i];
L.r[i]=x;
HeapAdjust(L, 1, i-1); // 将L.r[1..1-1]重新调整为大根堆
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
算法性能分析
初始堆化所需时间不超过O(n)
排序阶段(不含初始化)
一次重新堆化所需时间不超过O(logn);n-1次循环所需时间不超过O(nlogn)。
Tw(n)=O(n)+O(nlogn)=O(nlogn)
堆排序的时间主要耗费在建初始堆和调整建新堆时进行的反复筛选上。堆排序在最坏情况下,其时间复杂度也为O(nlog2n),这是堆排序的最大优点。无论待排序列中的记录是正序还是逆序排列,都不会使堆排序处于“最好”或“最坏”的状态。
另外,堆排序仅需一个记录大小供交换用的辅助存储空间。
然而堆排序是一种不稳定的排序方法,它不适用于待排序记录个数n较少的情况,但对于n较大的文件还是很有效的。
算法特点
① 是不稳定排序。
② 只能用于顺序结构,不能用于链式结构。
③ 初始建堆所需的比较次数较多,因此记录数较少时不宜采用。堆排序在最坏情况下时间复杂度为O(nlog2n),相对于快速排序最坏情况下的O(n2)而言是一个优点,当记录较多时较为高效。

