
- 1Navicat实现 MYSQL数据库备份图文教程_navicat备份数据库
- 2【FPGA】用Verilog语言实现呼吸灯实验_fpga呼吸灯verilog
- 3Spring Boot打jar包趟过的坑_awd 修复jar
- 4Python爬虫实战(四):利用代理IP爬取某瓣电影排行榜并写入Excel(附上完整源码)_ip代理
- 5Stable Diffusion_为啥尺寸会影响生图是否畸形?
- 6分布式锁全面总结_分布式锁机制
- 7CSS中的动画效果
- 82024抖音矩阵云混剪系统源码 短视频矩阵营销系统_2024抖音矩阵云混剪系统 源码短视频矩阵营销系统
- 9测试用例编写_用例编号怎么写
- 10根本上解决mysql启动失败问题Job for mysqld.service failed because the control process exited with error code_job for dmservicedmserver.service failed because t
超GPT-4o,代码能力超强!Claude 3.5 Sonnet正式发布_一句话生成网页,让前端开发瑟瑟发抖的claude3.5 sonnet #人工智能 #aigc #玩
赞
踩
6月20日晚,著名大模型平台Anthropic在官网正式发布了Claude 3.5 Sonnet。
据悉,这是Sonnet 是Claude 3.5系列中第一个,也是Anthropic目前最强的视觉模型。随后会发布Haiku和Opus版本。
其性能超过了上一代Claude 3旗舰模型Opus,同时也大幅度超过了OpenAI的GPT-4o,谷歌的Gemini1.5 Pro等知名模型。
尤其是代码生成能力以及新引入的可视化“Artifacts”功能,是目前代码生成领域最强的大模型之一。
虽然Claude 3.5的性能很强但成本却与上一代的Claude 3 Sonnet差不多,每100万Tokens输入为3美元,每100万tokens输出为15美元,支持20万tokens上下文窗口。
所以,不少网友对Claude 3.5的优化能力相当吃惊,要知道Anthropic的旗舰模型Claude 3 Opus才刚刚发布了3个月,相比之下Claude 3.5的成本却降低了80%,运行效率提升了2倍。

更恐怖的是Sonnet只是Claude 3.5系列中的低端型号,要是Opus正式发布那性能还能来一次大飞跃。
这不,压力又来到OpenAI这边,GPT-4o的语音功能还没发布呢,视觉理解和文本能力又被Claude 3.5超越了,得抓紧时间追赶啦。


尤其是既发即用,没有什么候补名单,接下来几周内可用,就这一点Anthropic获得了大批用户的喜爱。

所以,按照Anthropic这个产品发布节奏,到年底发布到4.0版本也是有可能的,将进一步给OpenAI施加压力。
超强代码生成和可视化能力
视觉理解是Claude 3.5一大特色功能,并新引入了一种可视化“Artifacts”的交互方式,当用户要求Claude生成代码片段、文本文档或网站设计等内容时,这些组件会出现在对话旁边的专用窗口中。
这创建了一个动态工作空间,可以在其中实时查看、编辑和构建 Claude 的创作,同时可将AI生成的内容无缝集成到开发项目或工作流程中。简单来说,相当于是一个可视化IDE开发器非常方面
对于这项功能,有人认为,Claude 3.5的代码开发效率将是GPT-4o的10倍。

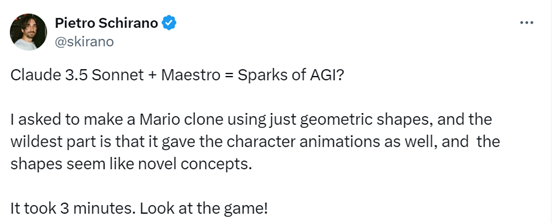
还有人用Claude 3.5+ Maestro直接克隆了一个马里奥小游戏,最惊艳的是连动画图像都帮你直接生成好了,整个流程只花费了3分钟,这离AGI真的很近了。
用Claude 3.5去模仿网站也是没问题的,例如,你看好谁家网站设计的新颖、交互功能、UI不错,直接拷贝就完事了,甚至连开发细节都展示出来了。
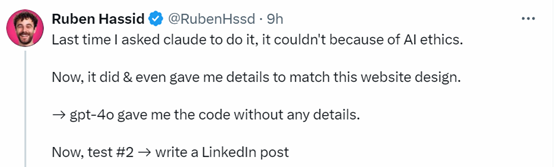
相比之下,虽然GPT-4o也能生成代码,但是细节方面比Claude 3.5差很多。
让你开发一款功能齐全的Mancala应用需要多长时间?一天、三天?Claude 3.5只用了25秒!

你只需要向Claude 3.5提供一张游戏说明的图片,它就能完成从功能设计到代码开发的所有流程,是不是很疯狂~
开发一款原创小游戏,把你的功能需求,游戏规则告诉Claude 3.5即可,几分钟就能进行demo测试。
Claude 3.5 Sonnet架构和测试数据
目前,Anthropic还没有公开Claude 3.5的论文,只放出了模型报告,「AIGC开放社区」就为大家解读一下重要内容。
架构方面,Claude 3.5 Sonnet在Claude 3 Opus的基础上进行了大幅度优化,推理效率提升2倍,成本却只有其5分之一。
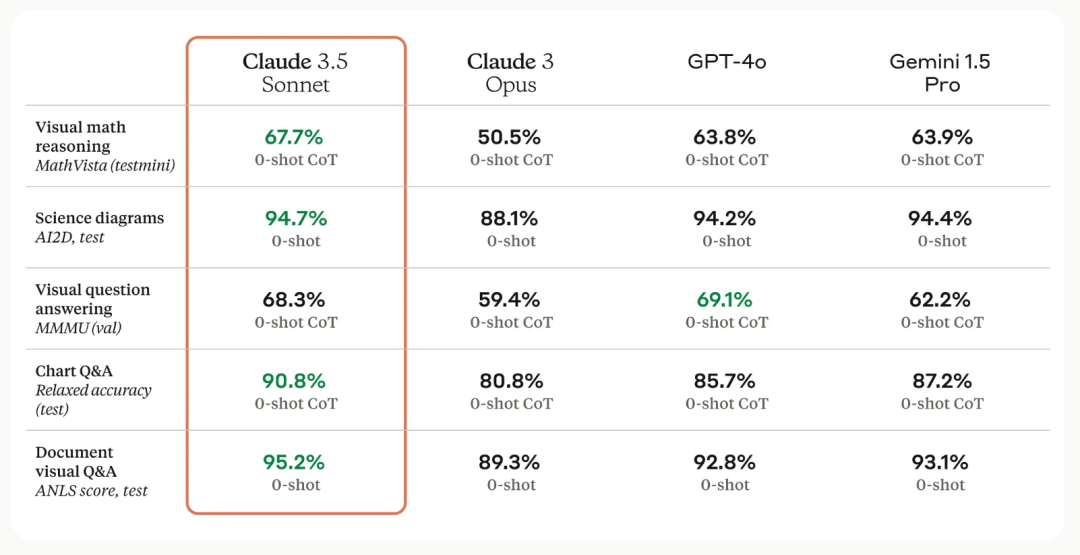
多模态能力得到增强,特别是在视觉处理方面取得了显著提升,能够更好地理解和分析图像、图表、文档等多种形式的视觉信息。使得模型在处理复杂的多模态任务时更高效,例如,视觉数学推理、图表问答、文档理解等。
代码能力是Claude 3.5 Sonnet本次的一大亮点,不仅能够生成高质量的代码,还能够理解和修改现有的代码库。在内部代理编码评估中的表现大幅提升,解决问题的能力从Claude 3 Opus的38%提高到了64%。
这意味着Claude 3.5 Sonnet能够更好地理解复杂的代码结构,实现更复杂的编程任务,例如,理解开源代码库并实现拉取请求等。
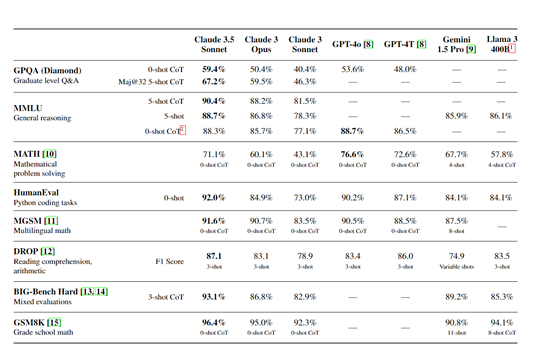
测试数据方面, Claude 3.5 Sonnet在GPQA、MMLU的零样本链式思考、五样本链式思考,均高于Claude 3 Opus、GPT-4o、GPT-4等知名模型。
在MathVista、Human、MGSM、DROP等测试中,Claude 3.5 Sonnet均以高测试评分领先其他模型。
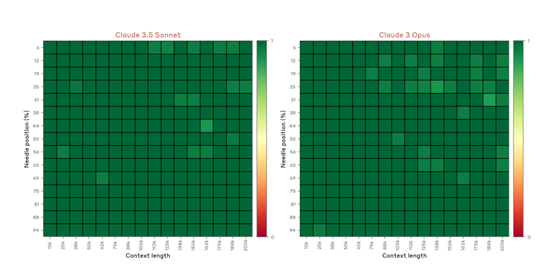
在“大海捞针”测试中,要求模型在海量的上下文中进行精准信息检索,主要考研模型在庞大的数据中准确找到并回忆出特定的信息。
结果显示,Claude 3.5 Sonnet无论是在所有上下文长度的总体表现,还是在特定200k上下文长度的挑战中,都达到了99.7%的召回率,这是一个几乎完美的测试成绩,大幅度超过了之前的Claude 3Opus。
目前,Claude 3.5 Sonnet已全面开放,可以在Anthropic官网或者移动应用程序中免费使用。
本文素材来源Anthropic官网,如有侵权请联系删除
END


