
- 1Windows Terminal配置美化 + Git配置 + 管理员配置_windows terminal 梅花
- 2C#调用oracle存储过程 最简单的实例
- 32023HW红队作战工具
- 4阿里 Nacos 惊爆,安全漏洞以绕过身份验证,附修复建议
- 5Anroid-Sqlite 数据存储、查询_android sqlite查询
- 6Alex 的 Hadoop 菜鸟教程: 第16课 Pig 安装使用教程_pig 教程
- 7大数据开发学习:MapReduce基本组件_mapreduce计算架构的组件
- 8【java】数组相关知识点汇总_arrays.setall byte
- 9CF Round 944 (div.4)ABCDEFG
- 10Studio One 6.6.2中文破解版+Studio One 6激活安装教程「支持m1 m2」
OFA-Chinese:中文多模态统一预训练模型_多模态中文模型
赞
踩
OFA是阿里巴巴发布的多模态统一预训练模型,基于官方的开源项目,笔者对OFA在中文任务上进行了更好的适配以及简化,并且在中文的Image Caption任务上进行了实践验证,取得了非常不错的效果。本文将对上述工作进行分享。
在此之前,笔者也曾尝试过基于CLIP模型进行Image Caption任务,详见文章ClipCap:让计算机学会看图说话
在公众号后台回复【006】可以获取本项目的数据、代码和模型权重,仅供学术交流,请勿用于商业用途。
首先展示一下笔者使用电商数据进行Image Caption训练之后的生成效果。示例中的图片均是从电商网站中随机下载的,仅做展示使用。其中第一列ours为笔者训练的模型的效果。
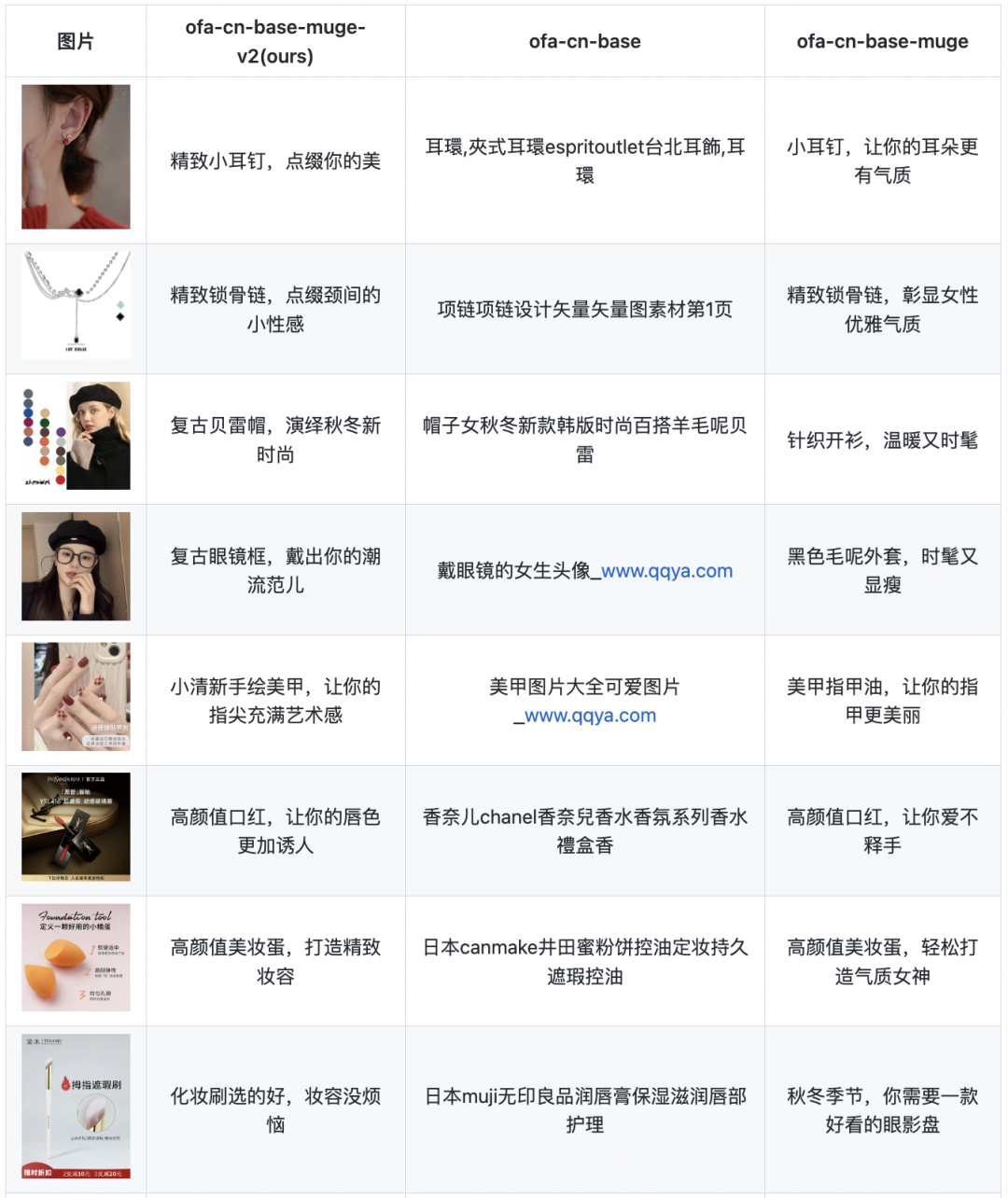
项目地址:
https://github.com/yangjianxin1/OFA-Chinese
论文标题:
Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
模型权重:
模型权重 | 简介 | 权重地址 |
YeungNLP/ofa-cn-base-muge-v2 | 笔者加载ofa-cn-base权重,使用muge数据集进行image caption任务finetune得到的权重 | |
YeungNLP/ofa-cn-base | 由官方OFA-CN-Base转换而来的权重 | |
YeungNLP/ofa-cn-large | 由官方OFA-CN-Large转换而来的权重 | |
YeungNLP/ofa-cn-base-muge | 由官方OFA-CN-Base-MUGE转换而来的权重 | |
YeungNLP/ofa-cn-large-muge | 由官方OFA-CN-Large-MUGE转换而来的权重 |
01
模型简介
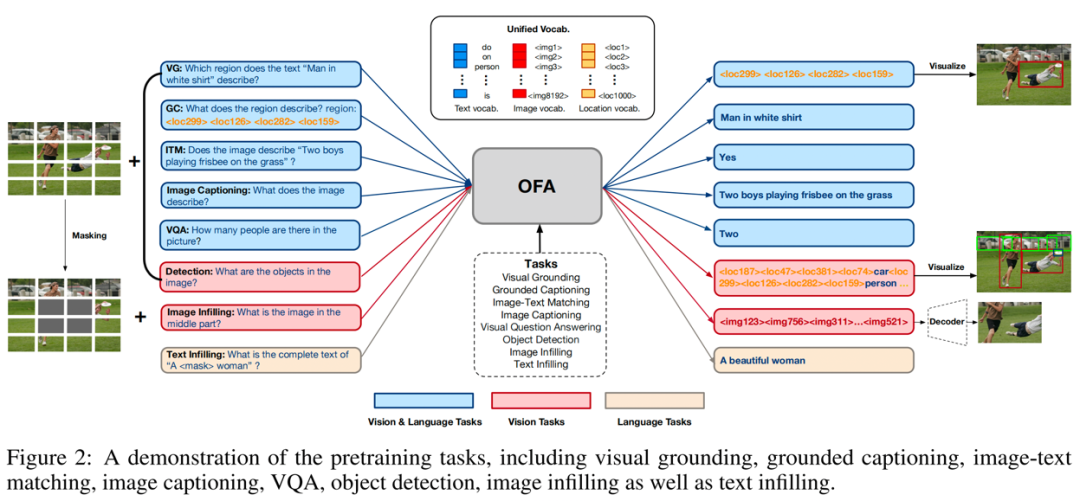
OFA是由阿里达摩院发布的多模态预训练模型,OFA将各种模态任务统一于Seq2Seq框架中。如下图所示,OFA支持的下游任务包括但不限于Image Caption、Image Classification、 Image genaration、Language Understanding等等。
02
项目介绍
项目动机 & 主要工作
本项目旨在以HuggingFace的transformers框架,实现中文OFA模型的训练和推理。并且希望将官方开源的fairseq版本的中文预训练权重,转化为transformers版本,以便用于下游任务进行finetune。
在OFA官方项目中,同时实现了fairseq和transformers两套框架的模型结构,并且分别开源了中文和英文的模型权重。基于下列原因,笔者开发了本项目:
由于笔者对transformers框架更熟悉,所以希望基于transformers框架,使用域内中文数据对OFA模型进行finetune,但OFA的中文预训练权重只有fairseq版本,没有transformers版本。
如何将fairseq版本的OFA预训练权重转换为transformers版本,从而便于下游任务进行finetune。
官方代码库中,由于需要兼容各种实验配置,所以代码也比较复杂冗余。笔者希望能够将核心逻辑剥离出来,简化使用方式。
基于上述动机,笔者的主要工作如下:
阅读分析OFA官方代码库,剥离出核心逻辑,包括训练逻辑、model、tokenizer等,以transformers框架进行下游任务的训练和推理,简化使用方式。
将官方的fairseq版本的中文预训练权重,转化为transformers版本,用于下游任务进行finetune。
基于本项目,使用中文多模态MUGE数据集中的Image Caption数据集,以LiT-tuning的方式对模型进行finetune,验证了本项目的有效性。
开源五个transformers版本的中文OFA模型权重,包括由官方权重转化而来的四个权重,以及笔者使用MUGE数据集finetune得到的权重。
训练细节
笔者使用MUGE数据集中的Image Caption数据,将其中的训练集与验证集进行合并,作为本项目的训练集。其中图片共5.5w张,每张图片包含10个caption,最终构成55w个图文对训练数据。关于MUGE数据集的说明详见官方网站。
caption数据,jsonl格式:
{"image_id": "007c720f1d8c04104096aeece425b2d5", "text": ["性感名媛蕾丝裙,尽显优雅撩人气质", "衣千亿,时尚气质名媛范", "80后穿唯美蕾丝裙,绽放优雅与性感", "修身连衣裙,女人就该如此优雅和美丽", "千亿包臀连衣裙,显出曼妙身姿", "衣千亿包臀连衣裙,穿的像仙女一样美", "衣千亿连衣裙,令人夺目光彩", "奔四女人穿气质连衣裙,高雅名媛范", "V领包臀连衣裙,青春少女感", "衣千亿包臀连衣裙,穿出曼妙身姿提升气质"]}{"image_id": "00809abd7059eeb94888fa48d9b0a9d8", "text": ["藕粉色的颜色搭配柔软舒适的冰丝面料,满满的时尚感,大领设计也超级好看,露出性感锁骨线条,搭配宽腰带设计,优雅温柔又有气质", "传承欧洲文化精品女鞋,引领风尚潮流设计", "欧洲站风格女鞋,演绎个性时尚装扮", "高品质原创凉鞋,气质与华丽引领春夏", "欧洲风格站艾莎女鞋经典款式重新演绎打造新一轮原创单品优雅鞋型尽显女人的柔美,十分知性大方。随意休闲很显瘦,不仅显高挑还展现纤细修长的腿型,休闲又非常潮流有范。上脚舒适又百搭。", "阳春显高穿搭,气质单鞋不可缺少", "冰丝连衣裙,通勤优雅范", "一身粉色穿搭,梦幻迷人", "艾莎女性,浪漫摩登,演绎角色转换", "超时尚夏季凉鞋,一直“走”在时尚的前沿"]}图片数据,tsv格式(img_id, '\t', img_content)(base64编码):
007c720f1d8c04104096aeece425b2d5/9j/4AAQSkZJRgABAgAAAQA...00809abd7059eeb94888fa48d9b0a9d8/9j/2wCEAAEBAQEBAQEBAQE...训练时,笔者使用LiT-tuning(Locked-image Text tuning)策略,也就是将encoder的权重进行冻结,仅对decoder的权重进行训练。加载ofa-cn-base预训练权重,使用55w的中文图文对, batch size=128,开启混合精度训练,warmup step为3000步,学习率为5e-5,使用cosine衰减策略,训练10个epoch,大约42500个step,最终训练loss降到0.47左右。
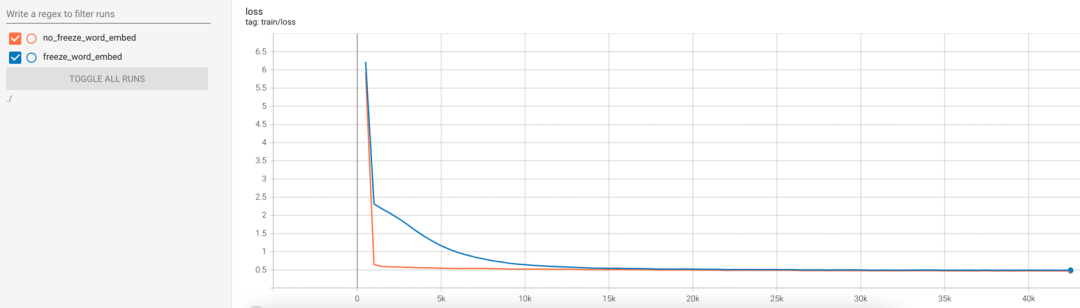
由于encoder与decoder共享词向量权重,笔者还分别尝试了冻结与不冻结词向量两种训练方式,两者的训练loss的变化趋势如下图所示。可以看到,训练时不冻结词向量权重,模型的收敛速度提升非常显著, 但相应地也需要更多显存。在训练时冻结词向量权重,可以节省显存并加快训练速度,将freeze_word_embed设为true即可。
使用方法
模型的使用方法非常简单,首先将项目clone到本地机器上,并且安装相关依赖包。
git clone https://github.com/yangjianxin1/OFA-Chinese.gitpip install -r requirements.txt使用如下代码,即可加载笔者分享的模型权重(代码会将模型权重自动下载到本地),根据图片生成对应的文本描述。
from component.ofa.modeling_ofa import OFAModelForCaptionfrom torchvision import transformsfrom PIL import Imagefrom transformers import BertTokenizerFastmodel_name_or_path = 'YeungNLP/ofa-cn-base-muge-v2'image_file = './images/test/lipstick.jpg'# 加载预训练模型权重model = OFAModelForCaption.from_pretrained(model_name_or_path)tokenizer = BertTokenizerFast.from_pretrained(model_name_or_path)# 定义图片预处理逻辑mean, std = [0.5, 0.5, 0.5], [0.5, 0.5, 0.5]resolution = 256patch_resize_transform = transforms.Compose([ lambda image: image.convert("RGB"), transforms.Resize((resolution, resolution), interpolation=Image.BICUBIC), transforms.ToTensor(), transforms.Normalize(mean=mean, std=std) ])txt = '图片描述了什么?'inputs = tokenizer([txt], return_tensors="pt").input_ids# 加载图片,并且预处理img = Image.open(image_file)patch_img = patch_resize_transform(img).unsqueeze(0)# 生成captiongen = model.generate(inputs, patch_images=patch_img, num_beams=5, no_repeat_ngram_size=3)print(tokenizer.batch_decode(gen, skip_special_tokens=True))在项目中,笔者还上传了模型训练、推理、权重转化等脚本,更多细节可参考项目代码。
03
效果展示
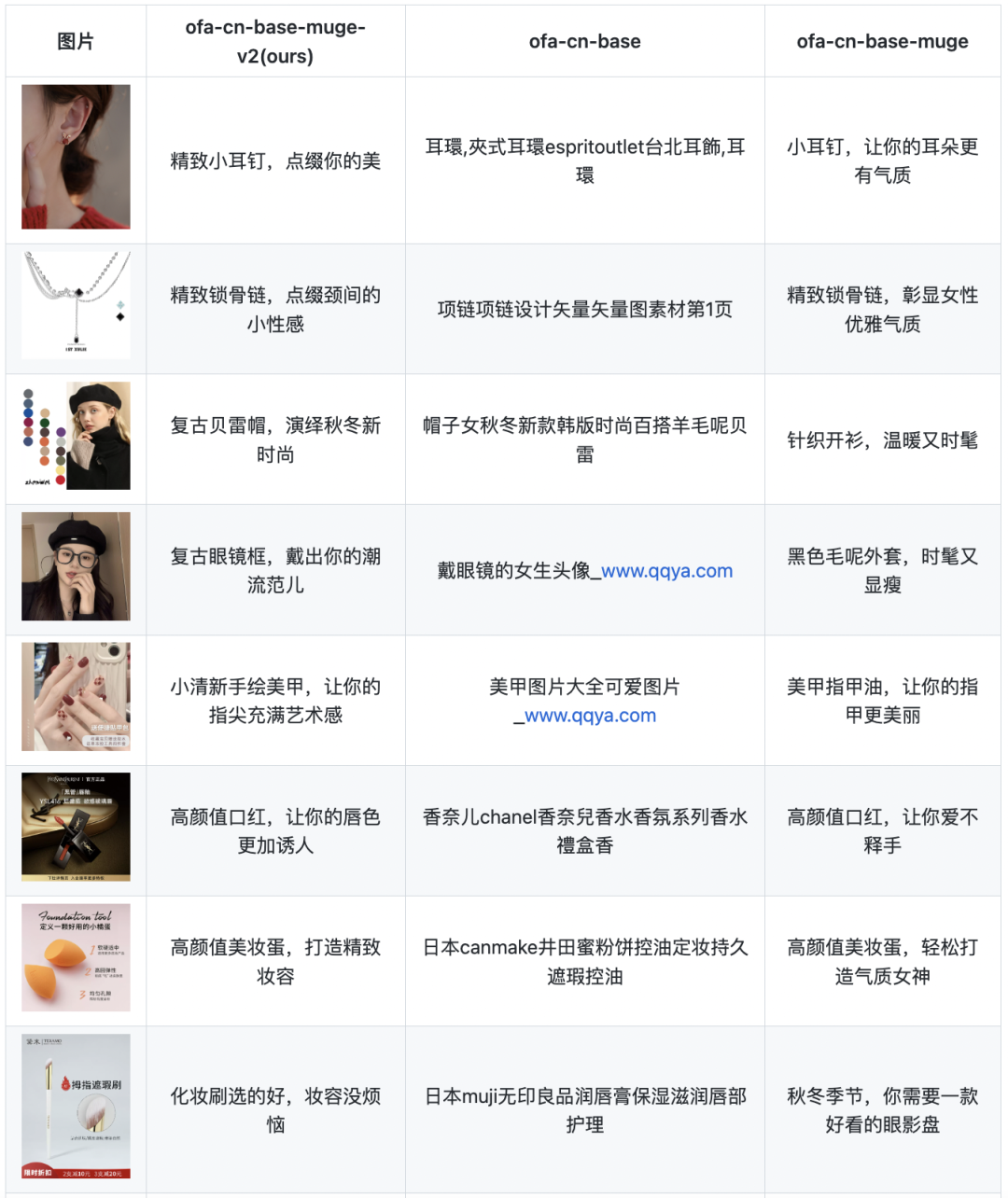
下列测试图片均为从电商网站中随机下载的,并且测试了不同模型权重的生成效果。
从生成效果来看,总结如下:
ofa-cn-base-muge是笔者将由官方fairseq版本的OFA-CN-Base-MUGE权重转换而来的,其生成效果非常不错。证明了fairseq权重转换为transformers权重的逻辑的有效性。
ofa-cn-base-muge-v2是笔者使用ofa-cn-base进行finetune得到的,其效果远远优于ofa-cn-base,并且与ofa-cn-base-muge旗鼓相当,证明了本项目的训练逻辑的有效性。


04
结语
在本文中,笔者分享了关于中文OFA的项目实践,实现了将fairseq版本的OFA权重转换为transformers权重,并且基于MUGE数据集进行了项目验证,在电商的Image Caption任务上取得了非常不错的效果。
就Image Caption任务而言,借助OFA模型强大的预训练能力,如果有足够丰富且高质量的域内图文对数据,例如电商领域的<图片,商品卖点文本>数据,能够训练得到一个高质量的卖点生成模型,在实际的应用场景中发挥作用。
笔者还分享了5个transformers版本的中文OFA权重,读者可以基于该预训练权重,在下游的多模态任务中进行finetune,相信可以取得非常不错的效果。

