
- 1SQL Server 常用函数_sql server 常见函数
- 2PyTorch、TensorFlow 和 NumPy三者之间的区别与联系是什么?_tensorflow和pytorch numpy
- 3基于51单片机的儿童安全座椅设计
- 4vue实现Element-ui省市区三级联动+市辖区修改_element-china-area-data json
- 5如何用人工智能高效选研究题目?
- 6Mybatis3.3.x技术内幕(十五):Mybatis之foreach批量insert,返回主键id列表(修复Mybatis返回null的bug)...
- 7(PYTHON)selenium+post请求批量获取小红书图片并备注_selenium 小红书
- 8html5电路模拟器,eda仿真软件
- 9助力工业产品质检,基于YOLOv5全系列参数模型【n/s/m/l/x】开发构建智能PCB电路板质检分析系统_yolo工业质检
- 10前后端分离CRUD_前后端分离列表遍历
【机器学习】Qwen2大模型原理、训练及推理部署实战_qwen2部署
赞
踩
目录

一、引言
刚刚写完【机器学习】Qwen1.5-14B-Chat大模型训练与推理实战 ,阿里Qwen就推出了Qwen2,相较于Qwen1.5中0.5B、1.8B、4B、7B、14B、32B、72B、110B等8个Dense模型以及1个14B(A2.7B)MoE模型共计9个模型,Qwen2包含了0.5B、1.5B、7B、57B-A14B和72B共计5个尺寸模型。从尺寸上来讲,最关键的就是推出了57B-A14B这个更大尺寸的MoE模型,有人问为什么删除了14B这个针对32G显存的常用尺寸,其实对于57B-A14B剪枝一下就可以得到。
二、模型简介
2.1 Qwen2 模型概述
Qwen2对比Qwen1.5:
- 模型尺寸:将Qwen2-7B和Qwen2-72B的模型尺寸有32K提升为128K

- GQA(分组查询注意力):在Qwen1.5系列中,只有32B和110B的模型使用了GQA。这一次,所有尺寸的模型都使用了GQA,提供GQA加速推理和降低显存占用

分组查询注意力 (Grouped Query Attention) 是一种在大型语言模型中的多查询注意力 (MQA) 和多头注意力 (MHA) 之间进行插值的方法,它的目标是在保持 MQA 速度的同时实现 MHA 的质量
- tie embedding:针对小模型,由于embedding参数量较大,使用了tie embedding的方法让输入和输出层共享参数,增加非embedding参数的占比
效果对比:
Qwen2-72B全方位围剿Llama3-70B,同时对比更大尺寸的Qwen1.5-110B也有很大提升,官方表示来自于“预训练数据及训练方法的优化”。

2.2 Qwen2 模型架构
Qwen2仍然是一个典型decoder-only的transformers大模型结构,主要包括文本输入层、embedding层、decoder层、输出层及损失函数

通过AutoModelForCausalLM查看Qwen1.5-7B-Chat和Qwen2-7B-Instruct的模型结构,对比config.json发现:


- 网络结构:无明显变化
- 核心网络Qwen2DecoderLayer层:由32层减少为28层(72B是80层)
- Q、K、V、O隐层尺寸:由4096减少为3584(72B是8192)
- attention heads:由32减少为28(72B是64)
- kv head:由32减少为4(72B是8)
- 滑动窗口(模型尺寸):由32768(32K)增长为131072(128K)(72B一样)
- 词表:由151936增长为152064(72B一样)
- intermediate_size(MLP交叉层):由11008增长为18944(72B是29568)
可以看到其中有的参数增加有的参数减少,猜想是:
- 减少的参数,并不会降低模型效果,反而能增加训练和推理效率,
- 增大的参数:比如MLP中的intermediate_size,参数越多,模型表达能力越明显。
三、训练与推理
3.1 Qwen2 模型训练
在【机器学习】Qwen1.5-14B-Chat大模型训练与推理实战 中,我们采用LLaMA-Factory的webui进行训练,今天我们换成命令行的方式,对于LLaMA-Factory框架的部署,可以参考我之前的文章:
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
该文在百度“LLaMA Factory 部署”词条排行第一:

假设你已经基于上文部署了llama_factory的container,运行进入到container中
docker exec -it llama_factory bash在app/目录下建立run_train.sh。
- CUDA_VISIBLE_DEVICES=2 llamafactory-cli train \
- --stage sft \
- --do_train True \
- --model_name_or_path qwen/Qwen2-7B-Instruct \
- --finetuning_type lora \
- --template qwen \
- --flash_attn auto \
- --dataset_dir data \
- --dataset alpaca_zh \
- --cutoff_len 4096 \
- --learning_rate 5e-05 \
- --num_train_epochs 5.0 \
- --max_samples 100000 \
- --per_device_train_batch_size 4 \
- --gradient_accumulation_steps 4 \
- --lr_scheduler_type cosine \
- --max_grad_norm 1.0 \
- --logging_steps 10 \
- --save_steps 1000 \
- --warmup_steps 0 \
- --optim adamw_torch \
- --packing False \
- --report_to none \
- --output_dir saves/Qwen2-7B-Instruct/lora/train_2024-06-09-23-00 \
- --fp16 True \
- --lora_rank 32 \
- --lora_alpha 16 \
- --lora_dropout 0 \
- --lora_target q_proj,v_proj \
- --val_size 0.1 \
- --evaluation_strategy steps \
- --eval_steps 1000 \
- --per_device_eval_batch_size 2 \
- --load_best_model_at_end True \
- --plot_loss True
因为之前文章中重点讲的就是国内网络环境的LLaMA-Factory部署,核心就是采用modelscope模型源代替huggingface模型源,这里脚本启动后,就会自动从modelscope下载指定的模型,这里是"qwen/Qwen2-7B-Instruct",下载完后启动训练

训练数据可以通过LLaMA-Factory/data/dataset_info.json文件进行配置,格式参考data目录下的其他数据文件。 比如构建成类型LLaMA-Factory/data/alpaca_zh_demo.json的格式

在LLaMA-Factory/data/dataset_info.json中复制一份进行配置:

3.2 Qwen2 模型推理
Qwen2的官方文档中介绍了多种优化推理部署的方式,包括基于hf transformers、vllm、llama.cpp、Ollama以及AWQ、GPTQ、GGUF等量化方式,主要因为Qwen2开源的Qwen2-72B、Qwen1.5-110B,远大于GLM4、Baichuan等开源的10B量级小尺寸模型。需要考虑量化、分布式推理问题。今天重点介绍Qwen2-7B-Instruct在国内网络环境下的hf transformers推理测试,其他方法单开篇幅进行细致讲解。
呈上一份glm-4-9b-chat、qwen/Qwen2-7B-Instruct通用的极简代码:
- from modelscope import snapshot_download
- from transformers import AutoTokenizer, AutoModelForCausalLM
- #model_dir = snapshot_download('ZhipuAI/glm-4-9b-chat')
- model_dir = snapshot_download('qwen/Qwen2-7B-Instruct')
- #model_dir = snapshot_download('baichuan-inc/Baichuan2-13B-Chat')
- import torch
-
- device = "auto" # 也可以通过"coda:2"指定GPU
-
- tokenizer = AutoTokenizer.from_pretrained(model_dir,trust_remote_code=True)
- model = AutoModelForCausalLM.from_pretrained(model_dir,device_map=device,trust_remote_code=True)
- print(model)
-
- prompt = "介绍一下大语言模型"
- messages = [
- {"role": "system", "content": "你是一个智能助理."},
- {"role": "user", "content": prompt}
- ]
- text = tokenizer.apply_chat_template(
- messages,
- tokenize=False,
- add_generation_prompt=True
- )
- model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
-
-
- """
- gen_kwargs = {"max_length": 512, "do_sample": True, "top_k": 1}
- with torch.no_grad():
- outputs = model.generate(**model_inputs, **gen_kwargs)
- #print(tokenizer.decode(outputs[0],skip_special_tokens=True))
- outputs = outputs[:, model_inputs['input_ids'].shape[1]:] #切除system、user等对话前缀
- print(tokenizer.decode(outputs[0], skip_special_tokens=True))
- """
- generated_ids = model.generate(
- model_inputs.input_ids,
- max_new_tokens=512
- )
- generated_ids = [
- output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
- ]
-
- response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
- print(response)
该代码有几个特点:
- 网络:从modelscope下载模型文件,解决通过AutoModelForCausalLM模型头下载hf模型慢的问题
- 通用:适用于glm-4-9b-chat、qwen/Qwen2-7B-Instruct
apply_chat_template():注意!采用generate()替代旧方法中的chat()。这里使用了apply_chat_template()函数将消息转换为模型能够理解的格式。其中的add_generation_prompt参数用于在输入中添加生成提示,该提示指向<|im_start|>assistant\n。tokenizer.batch_decode():通过tokenizer.batch_decode()函数对响应进行解码。
运行结果:
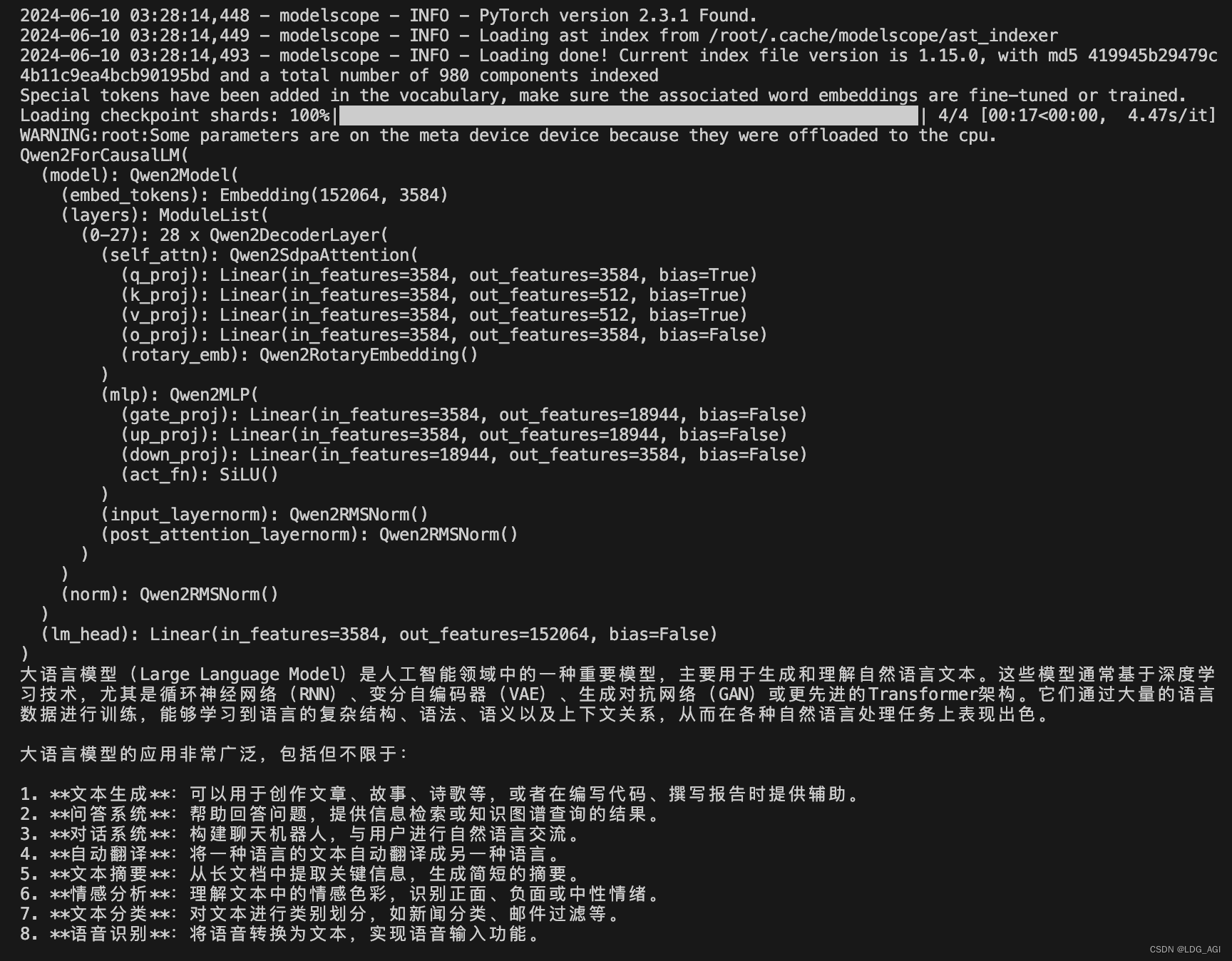
除了该极简代码,我针对网络环境对官方git提供的demo代码进行了改造:
cli_demo:
采用modelscope的AutoModelForCausalLM, AutoTokenizer模型头代替transformers对应的模型头,进行模型自动下载
- # Copyright (c) Alibaba Cloud.
- #
- # This source code is licensed under the license found in the
- # LICENSE file in the root directory of this source tree.
-
- """A simple command-line interactive chat demo."""
-
- import argparse
- import os
- import platform
- import shutil
- from copy import deepcopy
- from threading import Thread
-
-
- import torch
- from modelscope import AutoModelForCausalLM, AutoTokenizer
- from transformers import TextIteratorStreamer
- from transformers.trainer_utils import set_seed
-
- DEFAULT_CKPT_PATH = 'Qwen/Qwen2-7B-Instruct'
-
-
-
- _WELCOME_MSG = '''\
- Welcome to use Qwen2-Instruct model, type text to start chat, type :h to show command help.
- (欢迎使用 Qwen2-Instruct 模型,输入内容即可进行对话,:h 显示命令帮助。)
- Note: This demo is governed by the original license of Qwen2.
- We strongly advise users not to knowingly generate or allow others to knowingly generate harmful content, including hate speech, violence, pornography, deception, etc.
- (注:本演示受Qwen2的许可协议限制。我们强烈建议,用户不应传播及不应允许他人传播以下内容,包括但不限于仇恨言论、暴力、色情、欺诈相关的有害信息。)
- '''
- _HELP_MSG = '''\
- Commands:
- :help / :h Show this help message 显示帮助信息
- :exit / :quit / :q Exit the demo 退出Demo
- :clear / :cl Clear screen 清屏
- :clear-history / :clh Clear history 清除对话历史
- :history / :his Show history 显示对话历史
- :seed Show current random seed 显示当前随机种子
- :seed <N> Set random seed to <N> 设置随机种子
- :conf Show current generation config 显示生成配置
- :conf <key>=<value> Change generation config 修改生成配置
- :reset-conf Reset generation config 重置生成配置
- '''
- _ALL_COMMAND_NAMES = [
- 'help', 'h', 'exit', 'quit', 'q', 'clear', 'cl', 'clear-history', 'clh', 'history', 'his',
- 'seed', 'conf', 'reset-conf',
- ]
-
-
- def _setup_readline():
- try:
- import readline
- except ImportError:
- return
-
- _matches = []
-
- def _completer(text, state):
- nonlocal _matches
-
- if state == 0:
- _matches = [cmd_name for cmd_name in _ALL_COMMAND_NAMES if cmd_name.startswith(text)]
- if 0 <= state < len(_matches):
- return _matches[state]
- return None
-
- readline.set_completer(_completer)
- readline.parse_and_bind('tab: complete')
-
-
- def _load_model_tokenizer(args):
- tokenizer = AutoTokenizer.from_pretrained(
- args.checkpoint_path, resume_download=True,
- )
-
- if args.cpu_only:
- device_map = "cpu"
- else:
- device_map = "auto"
-
- model = AutoModelForCausalLM.from_pretrained(
- args.checkpoint_path,
- torch_dtype="auto",
- device_map=device_map,
- resume_download=True,
- ).eval()
- model.generation_config.max_new_tokens = 2048 # For chat.
-
- return model, tokenizer
-
-
- def _gc():
- import gc
- gc.collect()
- if torch.cuda.is_available():
- torch.cuda.empty_cache()
-
-
- def _clear_screen():
- if platform.system() == "Windows":
- os.system("cls")
- else:
- os.system("clear")
-
-
- def _print_history(history):
- terminal_width = shutil.get_terminal_size()[0]
- print(f'History ({len(history)})'.center(terminal_width, '='))
- for index, (query, response) in enumerate(history):
- print(f'User[{index}]: {query}')
- print(f'QWen[{index}]: {response}')
- print('=' * terminal_width)
-
-
- def _get_input() -> str:
- while True:
- try:
- message = input('User> ').strip()
- except UnicodeDecodeError:
- print('[ERROR] Encoding error in input')
- continue
- except KeyboardInterrupt:
- exit(1)
- if message:
- return message
- print('[ERROR] Query is empty')
-
-
- def _chat_stream(model, tokenizer, query, history):
- conversation = [
- {'role': 'system', 'content': 'You are a helpful assistant.'},
- ]
- for query_h, response_h in history:
- conversation.append({'role': 'user', 'content': query_h})
- conversation.append({'role': 'assistant', 'content': response_h})
- conversation.append({'role': 'user', 'content': query})
- inputs = tokenizer.apply_chat_template(
- conversation,
- add_generation_prompt=True,
- return_tensors='pt',
- )
- inputs = inputs.to(model.device)
- streamer = TextIteratorStreamer(tokenizer=tokenizer, skip_prompt=True, timeout=60.0, skip_special_tokens=True)
- generation_kwargs = dict(
- input_ids=inputs,
- streamer=streamer,
- )
- thread = Thread(target=model.generate, kwargs=generation_kwargs)
- thread.start()
-
- for new_text in streamer:
- yield new_text
-
-
- def main():
- parser = argparse.ArgumentParser(
- description='QWen2-Instruct command-line interactive chat demo.')
- parser.add_argument("-c", "--checkpoint-path", type=str, default=DEFAULT_CKPT_PATH,
- help="Checkpoint name or path, default to %(default)r")
- parser.add_argument("-s", "--seed", type=int, default=1234, help="Random seed")
- parser.add_argument("--cpu-only", action="store_true", help="Run demo with CPU only")
- args = parser.parse_args()
-
- history, response = [], ''
-
- model, tokenizer = _load_model_tokenizer(args)
- orig_gen_config = deepcopy(model.generation_config)
-
- _setup_readline()
-
- _clear_screen()
- print(_WELCOME_MSG)
-
- seed = args.seed
-
- while True:
- query = _get_input()
-
- # Process commands.
- if query.startswith(':'):
- command_words = query[1:].strip().split()
- if not command_words:
- command = ''
- else:
- command = command_words[0]
-
- if command in ['exit', 'quit', 'q']:
- break
- elif command in ['clear', 'cl']:
- _clear_screen()
- print(_WELCOME_MSG)
- _gc()
- continue
- elif command in ['clear-history', 'clh']:
- print(f'[INFO] All {len(history)} history cleared')
- history.clear()
- _gc()
- continue
- elif command in ['help', 'h']:
- print(_HELP_MSG)
- continue
- elif command in ['history', 'his']:
- _print_history(history)
- continue
- elif command in ['seed']:
- if len(command_words) == 1:
- print(f'[INFO] Current random seed: {seed}')
- continue
- else:
- new_seed_s = command_words[1]
- try:
- new_seed = int(new_seed_s)
- except ValueError:
- print(f'[WARNING] Fail to change random seed: {new_seed_s!r} is not a valid number')
- else:
- print(f'[INFO] Random seed changed to {new_seed}')
- seed = new_seed
- continue
- elif command in ['conf']:
- if len(command_words) == 1:
- print(model.generation_config)
- else:
- for key_value_pairs_str in command_words[1:]:
- eq_idx = key_value_pairs_str.find('=')
- if eq_idx == -1:
- print('[WARNING] format: <key>=<value>')
- continue
- conf_key, conf_value_str = key_value_pairs_str[:eq_idx], key_value_pairs_str[eq_idx + 1:]
- try:
- conf_value = eval(conf_value_str)
- except Exception as e:
- print(e)
- continue
- else:
- print(f'[INFO] Change config: model.generation_config.{conf_key} = {conf_value}')
- setattr(model.generation_config, conf_key, conf_value)
- continue
- elif command in ['reset-conf']:
- print('[INFO] Reset generation config')
- model.generation_config = deepcopy(orig_gen_config)
- print(model.generation_config)
- continue
- else:
- # As normal query.
- pass
-
- # Run chat.
- set_seed(seed)
- _clear_screen()
- print(f"\nUser: {query}")
- print(f"\nQwen2-Instruct: ", end="")
- try:
- partial_text = ''
- for new_text in _chat_stream(model, tokenizer, query, history):
- print(new_text, end='', flush=True)
- partial_text += new_text
- response = partial_text
- print()
-
- except KeyboardInterrupt:
- print('[WARNING] Generation interrupted')
- continue
-
- history.append((query, response))
-
-
- if __name__ == "__main__":
- main()
web_demo.py:
同上,采用modelscope代替transformers饮用AutoModelForCausalLM, AutoTokenizer,解决模型下载问题
输入参数:加入-g,指定运行的GPU
- # Copyright (c) Alibaba Cloud.
- #
- # This source code is licensed under the license found in the
- # LICENSE file in the root directory of this source tree.
-
- """A simple web interactive chat demo based on gradio."""
-
- from argparse import ArgumentParser
- from threading import Thread
-
- import gradio as gr
- import torch
- from modelscope import AutoModelForCausalLM, AutoTokenizer
- from transformers import TextIteratorStreamer
-
- DEFAULT_CKPT_PATH = 'Qwen/Qwen2-7B-Instruct'
-
-
- def _get_args():
- parser = ArgumentParser()
- parser.add_argument("-c", "--checkpoint-path", type=str, default=DEFAULT_CKPT_PATH,
- help="Checkpoint name or path, default to %(default)r")
- parser.add_argument("--cpu-only", action="store_true", help="Run demo with CPU only")
-
- parser.add_argument("--share", action="store_true", default=False,
- help="Create a publicly shareable link for the interface.")
- parser.add_argument("--inbrowser", action="store_true", default=False,
- help="Automatically launch the interface in a new tab on the default browser.")
- parser.add_argument("--server-port", type=int, default=18003,
- help="Demo server port.")
- parser.add_argument("--server-name", type=str, default="127.0.0.1",
- help="Demo server name.")
- parser.add_argument("-g","--gpus",type=str,default="auto",help="set gpu numbers")
-
- args = parser.parse_args()
- return args
-
-
- def _load_model_tokenizer(args):
- tokenizer = AutoTokenizer.from_pretrained(
- args.checkpoint_path, resume_download=True,
- )
-
- if args.cpu_only:
- device_map = "cpu"
- elif args.gpus=="auto":
- device_map = args.gpus
- else:
- device_map = "cuda:"+args.gpus
-
- model = AutoModelForCausalLM.from_pretrained(
- args.checkpoint_path,
- torch_dtype="auto",
- device_map=device_map,
- resume_download=True,
- ).eval()
- model.generation_config.max_new_tokens = 2048 # For chat.
-
- return model, tokenizer
-
-
- def _chat_stream(model, tokenizer, query, history):
- conversation = [
- {'role': 'system', 'content': 'You are a helpful assistant.'},
- ]
- for query_h, response_h in history:
- conversation.append({'role': 'user', 'content': query_h})
- conversation.append({'role': 'assistant', 'content': response_h})
- conversation.append({'role': 'user', 'content': query})
- inputs = tokenizer.apply_chat_template(
- conversation,
- add_generation_prompt=True,
- return_tensors='pt',
- )
- inputs = inputs.to(model.device)
- streamer = TextIteratorStreamer(tokenizer=tokenizer, skip_prompt=True, timeout=60.0, skip_special_tokens=True)
- generation_kwargs = dict(
- input_ids=inputs,
- streamer=streamer,
- )
- thread = Thread(target=model.generate, kwargs=generation_kwargs)
- thread.start()
-
- for new_text in streamer:
- yield new_text
-
-
- def _gc():
- import gc
- gc.collect()
- if torch.cuda.is_available():
- torch.cuda.empty_cache()
-
-
- def _launch_demo(args, model, tokenizer):
-
- def predict(_query, _chatbot, _task_history):
- print(f"User: {_query}")
- _chatbot.append((_query, ""))
- full_response = ""
- response = ""
- for new_text in _chat_stream(model, tokenizer, _query, history=_task_history):
- response += new_text
- _chatbot[-1] = (_query, response)
-
- yield _chatbot
- full_response = response
-
- print(f"History: {_task_history}")
- _task_history.append((_query, full_response))
- print(f"Qwen2-Instruct: {full_response}")
-
- def regenerate(_chatbot, _task_history):
- if not _task_history:
- yield _chatbot
- return
- item = _task_history.pop(-1)
- _chatbot.pop(-1)
- yield from predict(item[0], _chatbot, _task_history)
-
- def reset_user_input():
- return gr.update(value="")
-
- def reset_state(_chatbot, _task_history):
- _task_history.clear()
- _chatbot.clear()
- _gc()
- return _chatbot
-
- with gr.Blocks() as demo:
- gr.Markdown("""\
- <p align="center"><img src="https://qianwen-res.oss-accelerate-overseas.aliyuncs.com/logo_qwen2.png" style="height: 80px"/><p>""")
- gr.Markdown("""<center><font size=8>Qwen2 Chat Bot</center>""")
- gr.Markdown(
- """\
- <center><font size=3>This WebUI is based on Qwen2-Instruct, developed by Alibaba Cloud. \
- (本WebUI基于Qwen2-Instruct打造,实现聊天机器人功能。)</center>""")
- gr.Markdown("""\
- <center><font size=4>
- Qwen2-7B-Instruct <a href="https://modelscope.cn/models/qwen/Qwen2-7B-Instruct/summary">声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/寸_铁/article/detail/776554推荐阅读
相关标签

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

