
- 1Windows下怎么启动MongoDB数据库,这里有详细教程_windows启动mongodb
- 2如何查看docker中有哪些容器_docker desktop里面的容器怎么看
- 3AI大模型探索之路-应用篇9:Langchain框架LangSmith模块-AI模型监控神器_tavily api key
- 42024春招实习生Tl&;面经(美团、字节、腾讯、米哈游)_字节面试要开屏幕共享吗
- 5【Python GUI篇】Python 基于tkinter的GUI编程_runtimeerror: too early to create dialog window: n
- 6Golang 中对 json 的优雅处理_golang json解析太蠢
- 7数据结构学习记录——什么是堆(优先队列、堆的概念、最大堆最小堆、优先队列的完全二叉树表示、堆的特性、堆的抽象数据类型描述)
- 8【算法题】判断一颗二叉树是否对称_给一个二叉树检查是否轴对称
- 9校招/社招-算法岗简历及面试经验分享_算法 简历
- 10简单通俗上手BFS(广度优先搜索)与DFS(深度优先搜索)_bfs和dfs内存占用
【FCOS】Anchor-Free:FCOS论文总结及一些细节_focos论文
赞
踩

论文: https://arxiv.org/abs/1904.01355.
Github:源码
一、概述
1.1 模型分类
一般来说,目标检测模型可以分为two-stage和one-stage,也可以分为Anchor-base和Anchor-Free,还有现在比较流行的Transformer类的模型,比如DETR。
two-stage模型:RCNN、Fast RCNN、Faster RCNN、Mask RCNN等;
one-stage模型:YOLO系列、SSD、RetinaNet等;
Anchor-base模型:Faster RCNN、SSD、YOLO V2及后续系列等;
Anchor-Free模型:YOLO V1、FCOS、CornerNet、CenterNet等;
Transformer类模型:DETR、Deformable DETR、DINO等。
1.2 Anchor-base模型缺点
虽然这些Anchor-base模型(基于Anchor设计)在当时都取得了比较好甚至SOTA的效果,但是作者指出了一些缺点:
1.Anchor的设计很重要,不管是size(大小)还是ratio(宽高比),因为Anchor的设计会影响模型的性能这就相当于多了非常重要的超参数。
2.即使经过了精心的设计,但是这些设计好的Anchor不具备通用性,也就是不同的数据集要设计不同的Anchor。
3.模型产生数万个Anchors,这些Anchors绝大部分都是负样本,就会造成正负样本不平衡(即使可以自己采样调整那也麻烦)。
4,正负样本的区分是通过Anchor与GT的IOU大小来判定的,各种IOU的计算繁琐。
1.3 motivation
动机:针对以上的一些缺点,加上FCNs类(全卷积网络)工作在实例分割上的成果,作者思考能不能学学语义分割的FCN做一个像素级别(以像素点来预测目标)的网络来实现目标检测。这些像素点也就是本文的Location。
1.4 一些思考,为什么Anchor的设计很重要?
其实,之前我一直没理解Anchor的实际意义,只觉得它是一个矩形框并且这么做确实有效。到底什么是Anchor?
以Faster RCNN为例,Anchor在论文中有三种size(边长):{128,256,512},每种size都有三种宽高比{0.5,1,2}.下图的矩形框就是Anchor,为什么要设计这些Anchor?就是因为我们不知道图片上哪些地方会有物体,所以要在图片上生成密密麻麻成千上万的Anchor,这样不管哪个区域有物体,我都有可能预测对。每生成一个Anchor就表示这个矩形框范围内可能会有物体,具体有没有让模型取判断。
也就是说我把一张图片分成了成千上万个不同大小不同比例的部分,喂给模型,最后让模型判断这个部分是不是物体,如果是那就再用回归部分的模型调整这部分(这个Anchor)的大小。
所以Anchor是相对于原图来说的,并不是在特征图上生成。Anchors其实就是相当于在RCNN中用selective search算法挑选出来的可能包含物体的区域(约2000个),只不过这些Anchors是我们人为设定的,并不是算法生成的。相当于我们认为这几千/万个Anchors都可能包含物体,而RPN的作用就是把真正包含物体的Anchors挑选出来即proposals。
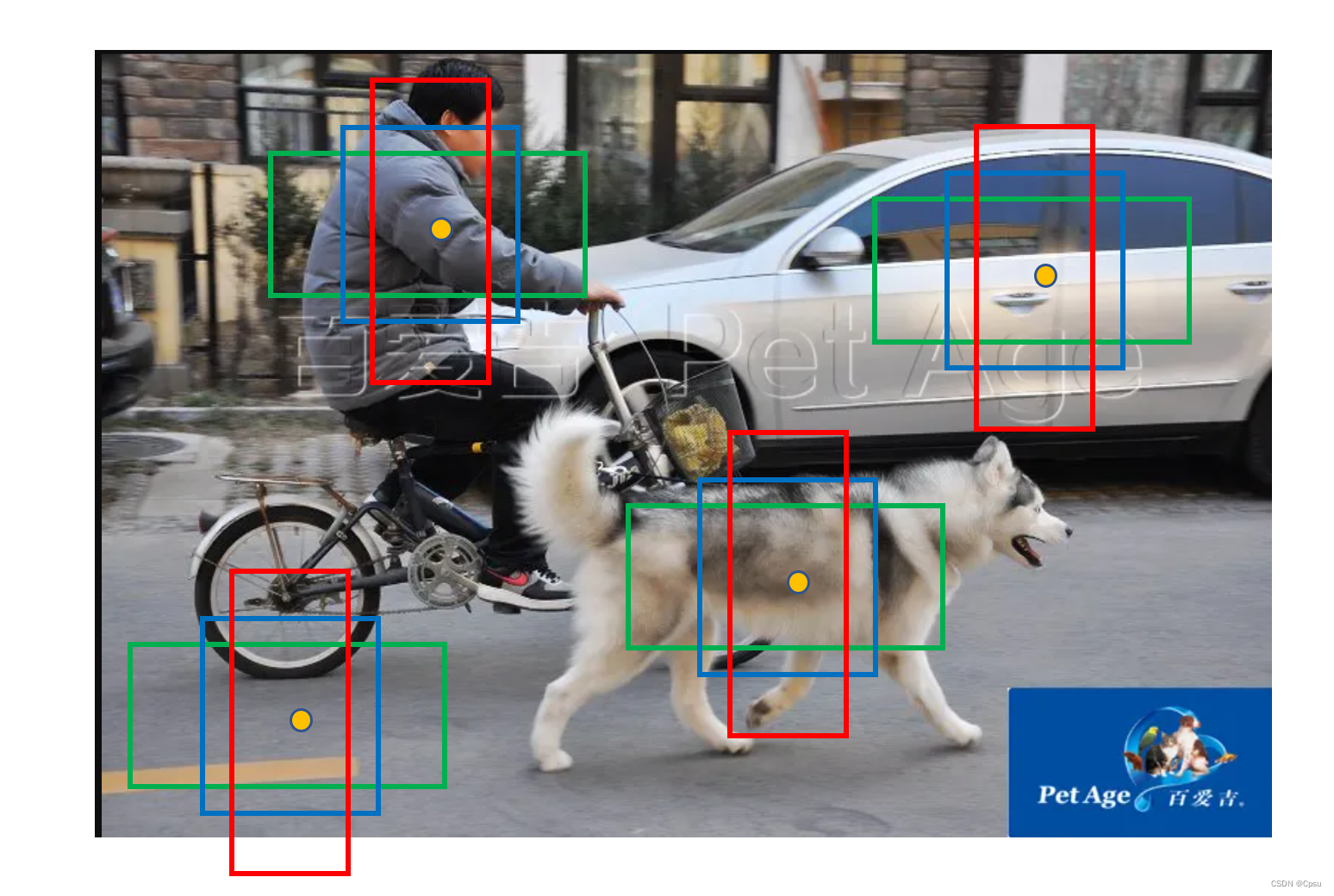
Anchor的设计很重要,比如上图中的汽车,它的GT box应该是很大的,如果用图上的三个大小的Anchor预测显然不合理。不仅大小不合适,在正负样本的选取的时候,一般要与GT的IOU大于0.7才能作为正样本,显然这些框的大小不可能达到,连一个正样本都找不到,更不用说去预测了。
所以Anchor的设计是很重要的,并且不同的数据集确实要设计不同的Anchor。
二、网络结构
2.1 检测思路

在用backbone(比如ResNet)得到特征图后,把特征图的每个像素看成一个点location(x,y),把每个特征点 location(x,y) 通过公式映射到原图上(感受野的中心)。只要这个 location落在了某个GT box的范围内,那么这个点就被视为正样本,随后根据这个点预测4个坐标参数(l,t,r,b),分别代表 location到左边框、上边框、右边框、下边框的距离。根据这4个坐标参数和location相加即可得到目标框。如上图(左)所示,橘色点落在了GT box内所以视为正样本,预测4个坐标参数。
那自然会出现右图的情况,即某个location同时落在了两个GT box内(黄色和蓝色),那么这个location会被判定为面积更小的那个GT box(蓝色的矩形框)。这个点称之为模糊样本(ambiguous)。
2.2 网络结构
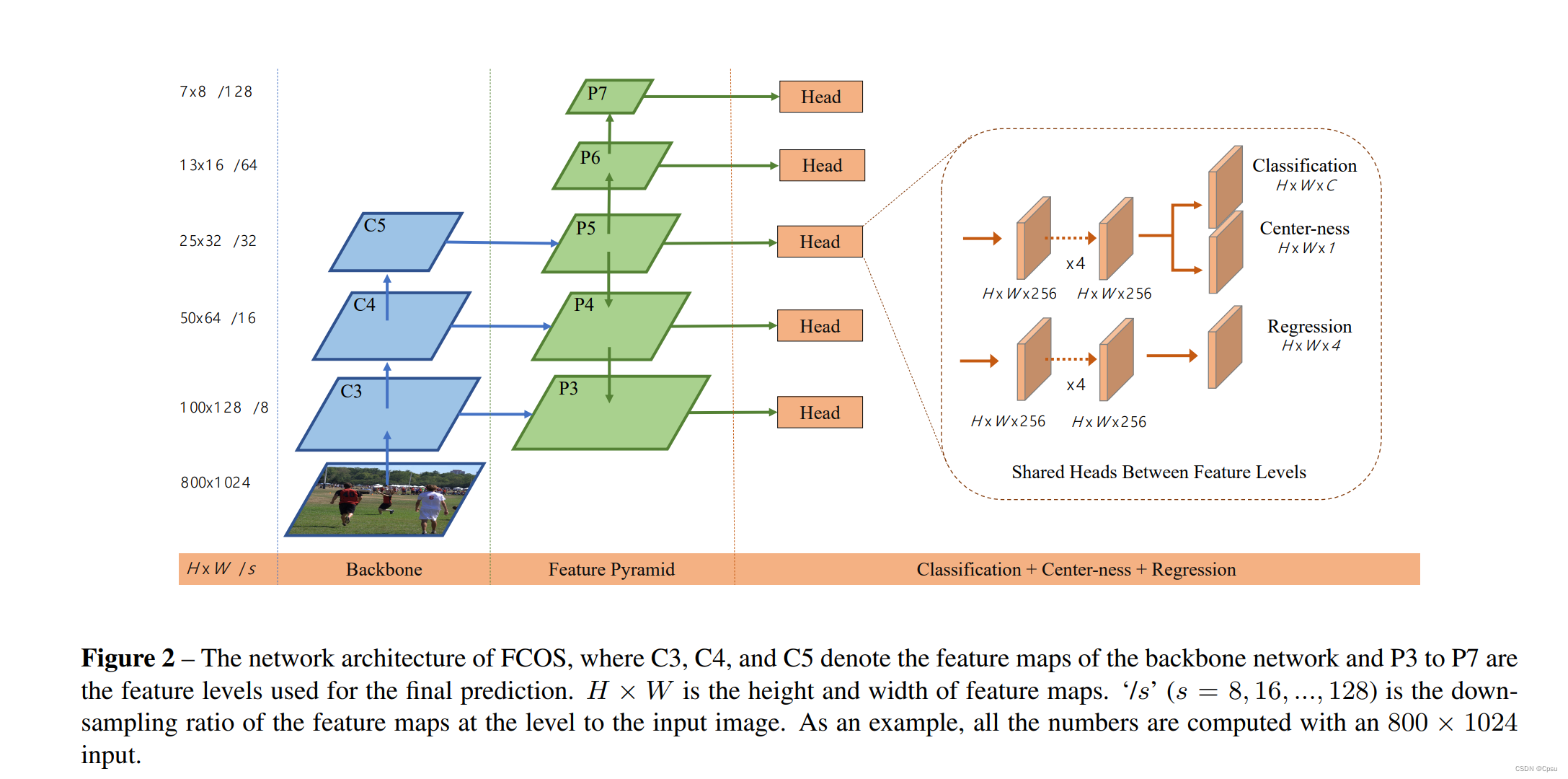
Backbone输出最后一层特征图后,经过FPN结构生成多层特征图。这里还根据FPN的P5再经过一个卷积层生成P6和P7。一共有5层特征图用于最后的预测。最后所有特征图共享一个预测头。预测头有三部分,一个classification用于分类,一个center-ness用于限制location的位置,一个regression用于预测4个回归参数。
三、细节
3.1 Center-ness
Center-ness 即中心度。Center-ness 分支的作用是为了抑制那些偏离物体中心的点生成的框。因为只要落在GT范围内的location就算正样本,所以如果loacation落在GT的边缘那么回归预测的效果就会很差。作者给出了计算中心度的公式。

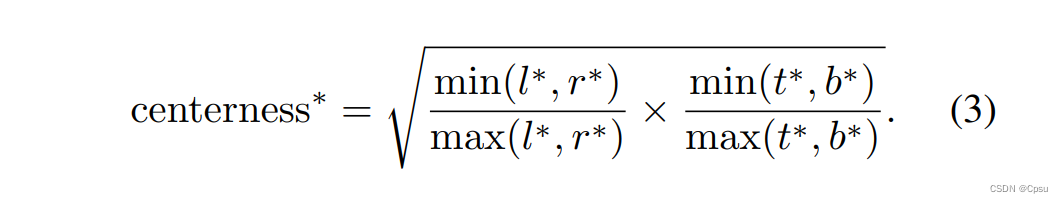
把上述公式可视化一下,可以看出,越靠近中心的点越亮也就是中心度的值越大。把Center-ness分支加进loss函数中,这样就可以尽量限制location落在GT的中心。

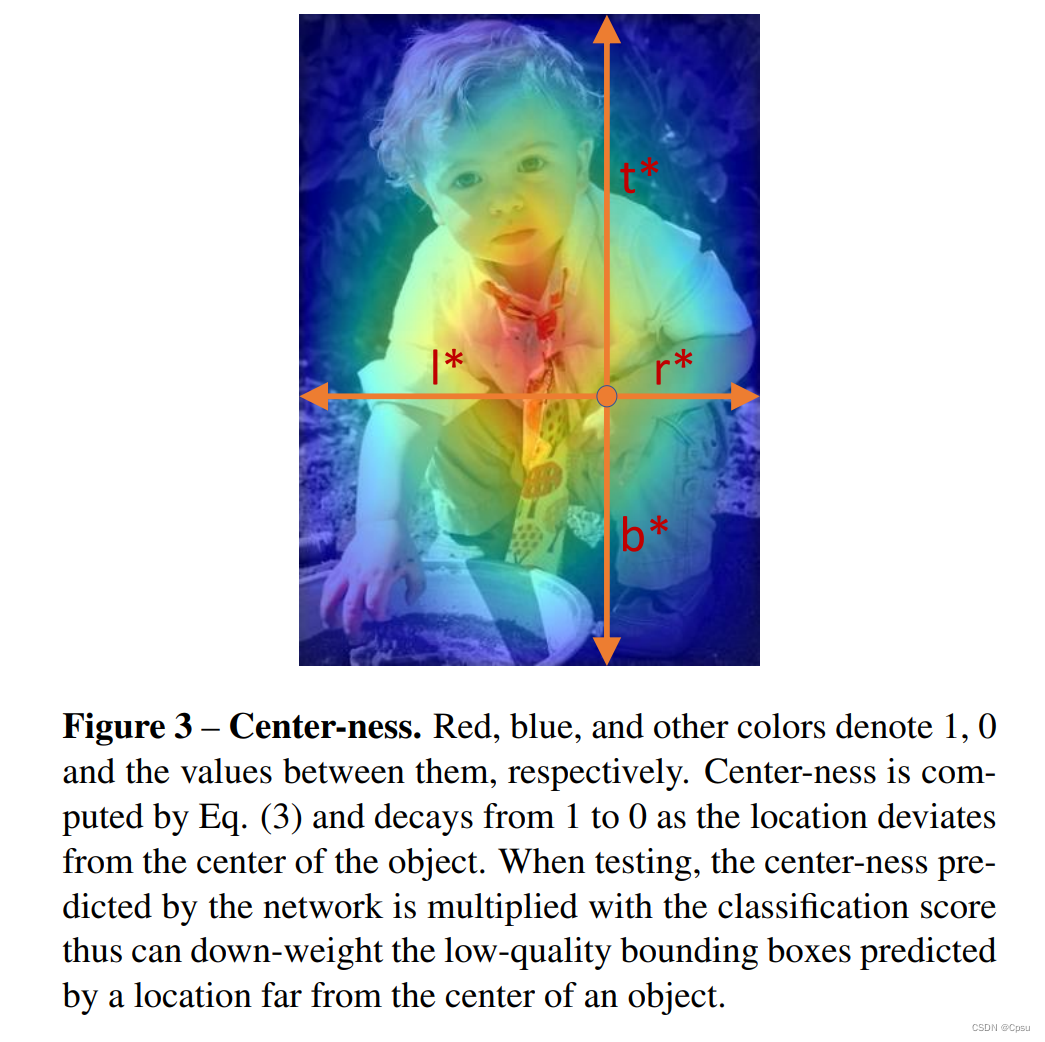
可以看到越靠近中心位置的颜色就越深,尽量限制location落在GT的中心。
可视化代码:
import cv2 import torch import numpy as np def calc_center_ness(bbox, s): l = bbox[:, 0]-s[:, 0] t = s[:, 1]-bbox[:, 1] r = s[:, 2]-bbox[:, 0] b = bbox[:, 1]-s[:, 3] # 计算center-ness center_ness = np.sqrt((np.minimum(l, r)/np.maximum(l, r)) * (np.minimum(t, b)/np.maximum(t, b))) return center_ness shifts_x = torch.arange(0, 100) shifts_y = torch.arange(0, 100) shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x) bbox1 = np.array(torch.stack((shift_y, shift_x), -1)).reshape(-1, 2) pred_ctr1 = np.array([[0, 100, 100, 0]]).repeat(100*100, axis=0) bbox2 = np.array(torch.stack((shift_x, shift_y), -1)).reshape(-1, 2) pred_ctr2 = np.array([[0, 100, 100, 0]]).repeat(100*100, axis=0) center_ness1 = calc_center_ness(bbox1, pred_ctr1) center_ness2 = calc_center_ness(bbox2, pred_ctr2) center_ness_norm1 = (center_ness1 - center_ness1.min()) / \ (center_ness1.max() - center_ness1.min()) center_ness_norm2 = (center_ness2 - center_ness2.min()) / \ (center_ness2.max() - center_ness2.min()) center_ness = center_ness_norm1 + center_ness_norm2 center_ness_norm = (center_ness - center_ness.min()) / \ (center_ness.max() - center_ness.min()) center_ness_gray = (center_ness_norm * 255).astype(np.uint8).reshape(100, 100) cv2.imshow('Center-ness', center_ness_gray) cv2.imwrite('saved_image.jpg', center_ness_gray) cv2.waitKey(0) cv2.destroyAllWindows()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
3.2 损失函数
首先是特征图上的点location(x,y) 如何映射到原图上:

这个公式会把location映射到靠近感受野中心的位置。
随后是regression分支预测的参数坐标:
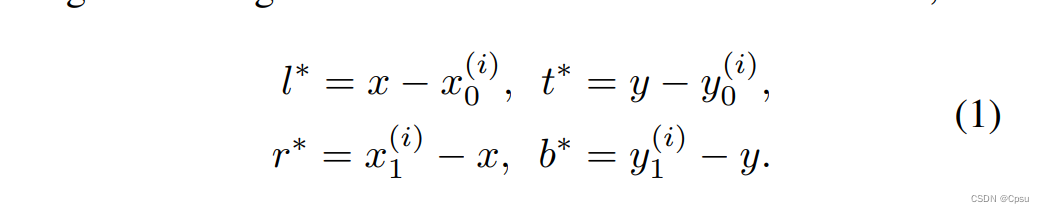
其中x、y是location的坐标,x0、y0、x1、y1是GT box的坐标,由左上角和右下角的坐标组成,并且GT box坐标是以图片左上角为原点计算的。
损失函数就是常见的分类损失加回归损失。只有正样本即落在GT box内的点才有回归损失:其中t表示一个四维向量即预测的坐标参数 (l,t,r,b)。这里其实还有一个Center-ness分支的BCE Loss,这里没有体现出来加上即可。
-注:由于这些参数坐标肯定要是正的,所以作者会取一个指数运算。
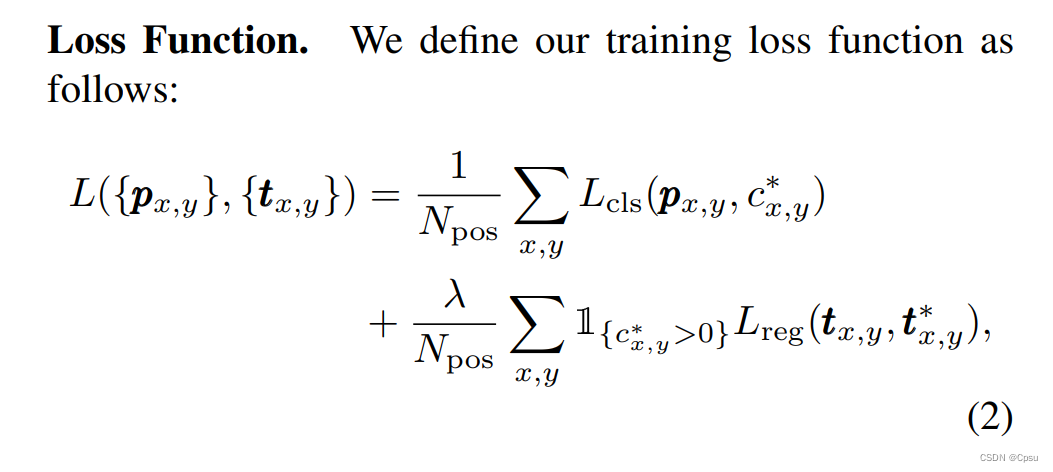
3.3 FPN的作用
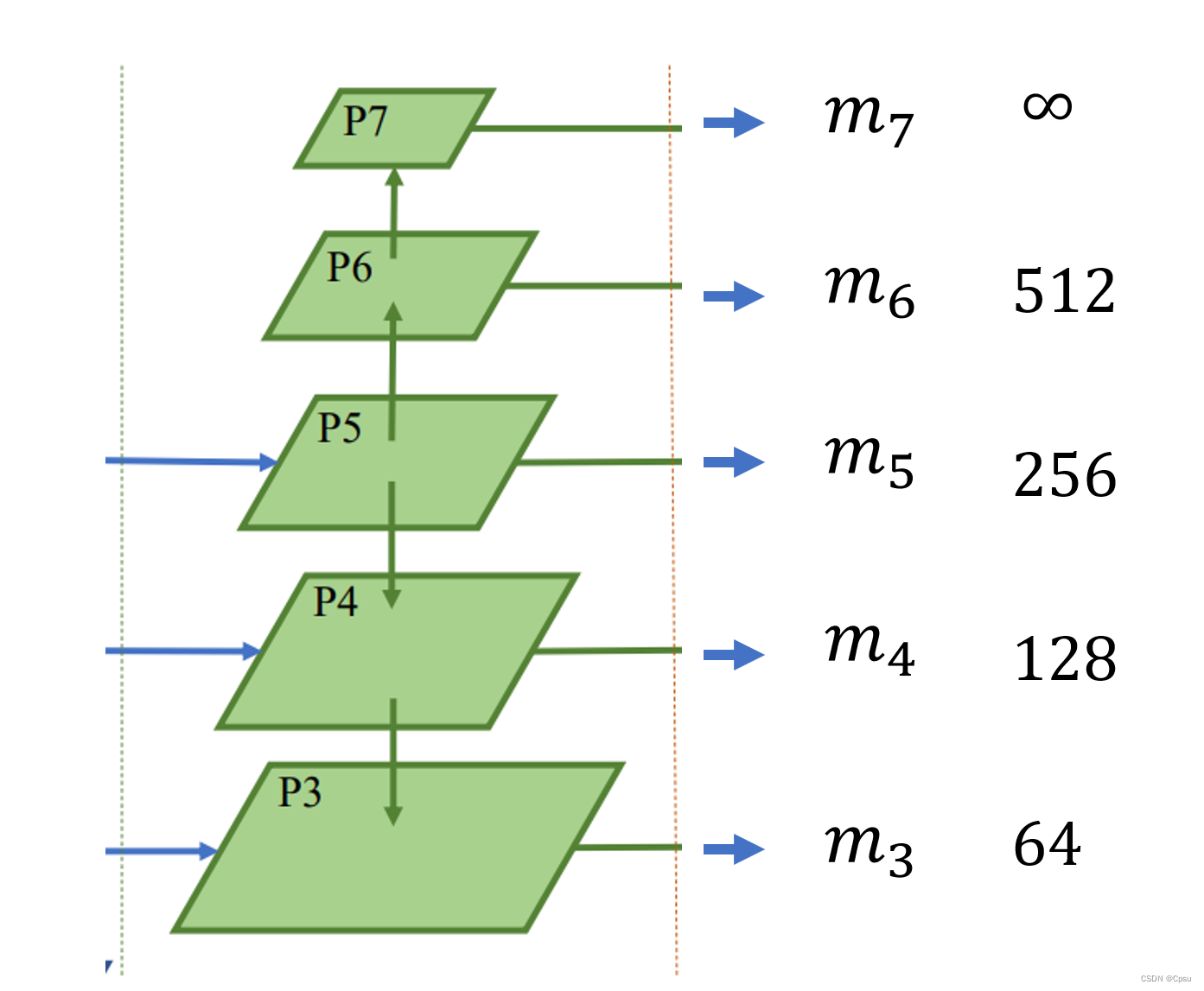
上面说了某个location同时落在了两个GT box内,那么这个location会被判定为面积更小的那个GT box。这个问题就是考FPN来解决的。由于FPN的存在,可以将多级feature map用于预测,不同层级的feature map有不同大小的感受野。往往深层的feature map感受野比较大,浅层的feature map感受野比较小。所以深层的feature map适合预测大物体,浅层的feature map适合预测小物体。
作者这里很巧妙的限制了每个层级的feature map能预测的坐标参数大小。每层的feature map预测出来的坐标参数如果:max(l,t,r,b)>mi 或者 max(l,t,r,b)<mi-1 那么这个点location就不是正样本而是负样本,即使location落在了GT box内。
比如特征层P5预测出了GT box内的一个location的4个参数坐标(l,t,r,b)为:(300,200,150,100),很明显最大值为300,超过了P5特征层对应的m5=256,所以这个location会被视为一个负样本即背景即使它落在GT box内。
同理如果4个参数坐标(l,t,r,b)为:(120,100,96,30),很明显最大值为120,小于P4特征层对应的m4=256,那么也会被视为负样本。
这样相当于给每层的feature map都分配了任务,尽量让不同层的feature map预测不同大小的物体。因为作者发现大部分重叠的物体都是大小不同的,这样即使location同时落在了两个GT box,不同的特征层可以负责预测对应大小的物体把两个物体都检测出来。极端情况下,那就把这个location判定为面积更小的那个GT box(蓝色的矩形框)。
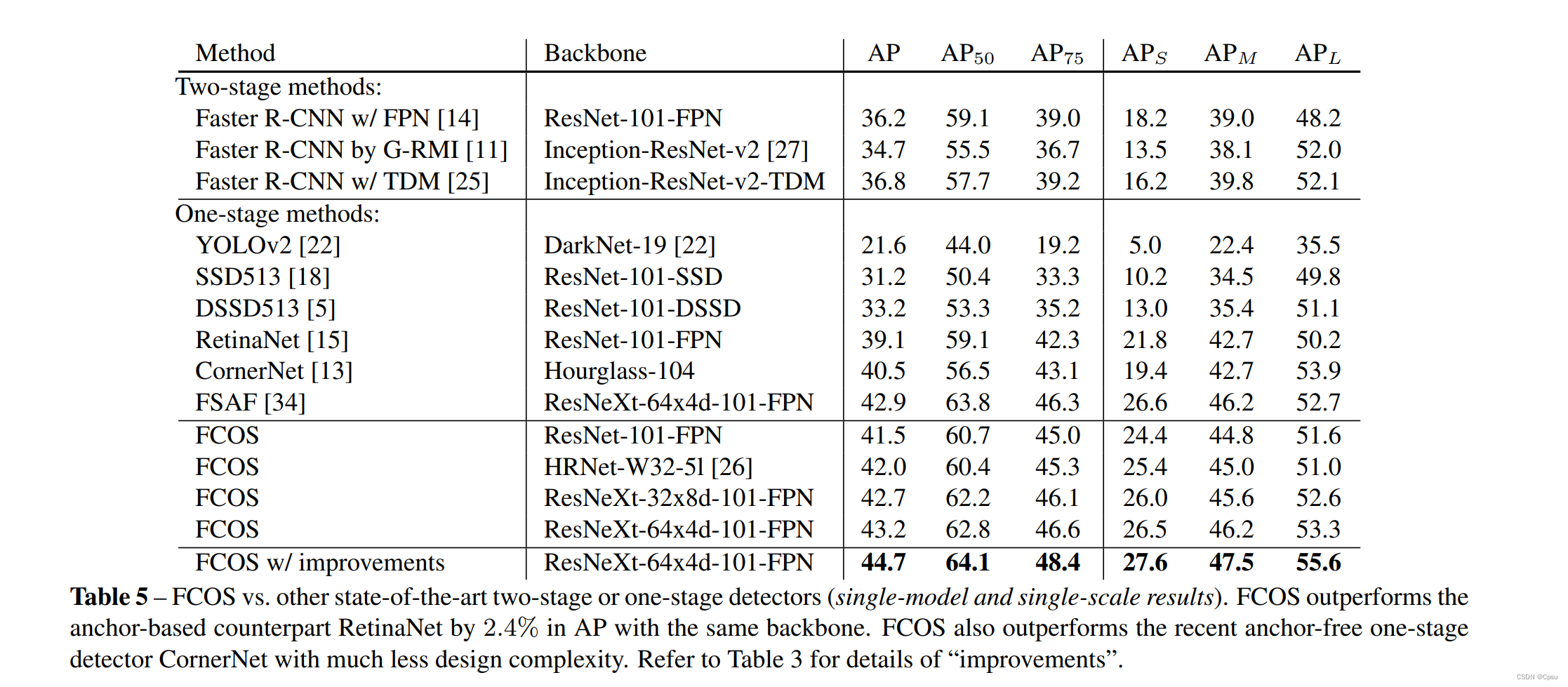
四、实验
五、优点
1.参考FCNs在实力分割的成果,在像素(点)级别上进行的目标检测,网络结构可以在其他比如语义分割任务上的复用。
2. Anchor-free,没有Anchor-base模型的缺点,不用设计各式各样的Anchors。
3.不用计算IOU等,可以节省显存消耗。
4.we encourage the community to rethink the necessity of anchor boxes in object detection, which are currently considered as the de facto standard for detection.-——Anchors是否真的必要?
5.We believe that this new method can be the new baseline for many instance-wise prediction problems.——新的baseline!
总结
Anchor-free确实简洁高效,把以前的Anchors变成像素级别,以一个点来预测坐标参数。整篇论文写的非常清晰详细,网络结构图一目了然,非常值得一读!

